

flyride
-
Posts
2,438 -
Joined
-
Last visited
-
Days Won
127
Everything posted by flyride
-
DSM 6.2 on ESXi 6,7, storage pool crashed (Raid5, ext4)
flyride replied to Rihc0's topic in The Noob Lounge
Work emergency took my idle time away, yay for the weekend. We have to model the array in sequence according to the table above. Only one of the six permutations will be successful, so it is important that we do not write to the array until we are sure that it is good. The following will create the array in the configuration of the first line of the table (note that we are root): # cat /etc/fstab # mdadm --stop /dev/md3 # mdadm -v --create --assume-clean -e1.2 -n5 -l5 /dev/md3 /dev/sdg3 /dev/sde3 /dev/sdf3 /dev/sdh3 missing -uff64862b:9edfe233:c498ea84:9d4b9ffd # cat /proc/mdstat # mount -o ro,noload /dev/md3 /volume1 I expect that all the commands will execute without error except the mount command. If the mount command succeeds, we may have found the correct sequence of drives in the array. If it fails, we need to investigate further before proceeding to the next sequence. Remember NOT to use any DSM UI features to edit the array, fix the System Partition, or make any other changes.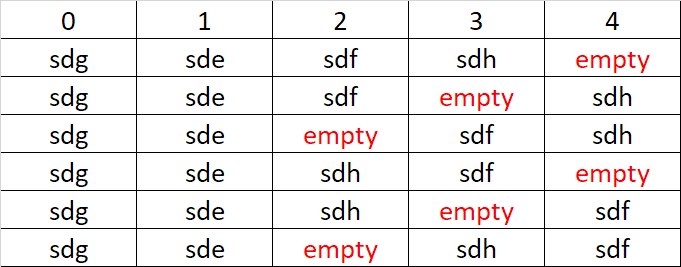
-
Drives out of order DSM 6.2.3 with LSI 9305-16i
flyride replied to Richard Hopton's topic in DSM 6.x
That is a normal message for the virtual SATA controller under ESXi. -
DSM 6.2 on ESXi 6,7, storage pool crashed (Raid5, ext4)
flyride replied to Rihc0's topic in The Noob Lounge
Haven't forgotten about this, just let me assemble the commands and I will provide a suggested plan to try the matrix of permutations shortly. -
Drives out of order DSM 6.2.3 with LSI 9305-16i
flyride replied to Richard Hopton's topic in DSM 6.x
It is, for grub it should be 0F. However, 18 in hex is correct to move the loader drive to position 24 -
Drives out of order DSM 6.2.3 with LSI 9305-16i
flyride replied to Richard Hopton's topic in DSM 6.x
The grub.cfg looks okay to me. But the HBA already uses more ports than the loader is configured by default (12 slots). So you will probably need to override MaxDisks and adjust the bitmaps defining the drive types (internalportcfg, usbportcfg, esataportcfg) in /etc.defaults/synoinfo.conf I think the inconsistent drive naming is characteristic of the driver. This is very difficult for technical support but DSM handles constantly changing disk assignments okay. You might find this thread illuminating: https://xpenology.com/forum/topic/27070-36-bay-nas-drives-starting-at-11-instead-of-1-103b-with-ds3617/?tab=comments#comment-138321 @IG-88 you advised on this type of HBA recently? Any further advice? -
I think your question is answered above, but I will also point out that Quicksync is upgraded from chip generation to generation. Your old chip does not have much of the functionality that might be required by Plex even if you could get the 918+ image to boot (which you cannot).
-
DSM 6.2 on ESXi 6,7, storage pool crashed (Raid5, ext4)
flyride replied to Rihc0's topic in The Noob Lounge
This is the step in the process where you must understand that your best chances for recovery are to send your disks to a forensic lab. It's expensive and there is no guarantee they can recover data, but once we start to try brute-force methods to overcome the corruption that has occurred on your disks, some of the information that a lab uses to figure out how to work will be overwritten and their job will become harder or impossible. Again, the issue is that three of your five disks are now missing array administrative information, and /dev/sdd doesn't even have a partition table. Because the information defining the order of those three disks is lost, we have to work through the six possible permutations and see if any of them result in the recovery of a filesystem. Logically, I recommend we omit /dev/sdd, because it is the most likely to be corrupted into the array partition. If we include it in the array and it has corrupted data, the array will be inaccessible. If we leave it out and the remaining disks are okay, the array will function due to parity redundancy. Here's a table of the different array member permutations that will need to be attempted for recovery: The process will be to manually override the array with each of these configurations, then attempt to access it in a read-only mode, and if successful, STOP. Don't reboot, don't click on any repair options in the DSM UI. Your best result will be to copy data off immediately. Once you have recovered as much data as possible, only then consider whether it makes sense to repair the array in place, or to delete and rebuild it. If you wish to proceed, please confirm whether you chose RAID5 or SHR when you created the array in DSM. Also is the filesystem ext4 or btrfs? EDIT: I now realize that you posted that information in the beginning. RAID5 over SHR makes this job easier - that's good. Unfortunately a data recovery like this is enhanced by btrfs over ext4, as btrfs would be able to detect corruption if the checksumming features were properly enabled on the filesystem. In any case, it is irrelevant for this recovery.
-
DSM 6.2 on ESXi 6,7, storage pool crashed (Raid5, ext4)
flyride replied to Rihc0's topic in The Noob Lounge
As you suggest, it seems like disk assignments have moved around since your first post. Again, a hardware raid will always use the port position to determine array member order, but mdraid does not because it maintains an on-drive superblock. In this second run, md knows that the drive assigned to /dev/sdg3 is array member 0, and /dev/sde3 is #1. We need four disks out of five to recover data from the array. There are two really big problems with the array at the moment. /dev/sdd doesn't seem to have a recognizable partition table at all, /dev/sdf and /dev/sdh have RAID partition structures but their superblocks are no longer intact. As mentioned before this is very likely to have occurred when the disks were introduced to a foreign controller and array structure. It is possible usable data still exists on the inaccessible disks. We still could try and start the array from sde/f/g/h but the data available doesn't tell us how to order sdf and sdh. Might you have any fdisk -l dumps from prior to the crash (or any other array information saved) so we can match the drive uuids to the array member positions? -
The two issues I have run into with NUT are 1) mapping the correct PCI port into the ups.conf, and 2) making sure the UPS doesn't timeout (as previously described) I stand corrected; I did run NUT on docker for awhile, but switched to a native Linux VM install in order to get more flexibility on ports. Here's the ups.conf from my install, and you can see the critical configuration items: [ups] driver = usbhid-ups port = /dev/bus/usb/001/003 pollinterval = 12 The port mapping will need to be correct for your system (the USB bus and port that the UPS is connected to - this seems well documented in the docker README), and the 12s interval is what worked for my CyberPower. If the timeouts are a problem, you may need to remove and replug the UPS into the USB port for it to be recognized. Also you may have to run the docker container as privileged in order to get direct access to the USB port.
-
Drives out of order DSM 6.2.3 with LSI 9305-16i
flyride replied to Richard Hopton's topic in DSM 6.x
Every controller that DSM can see will reserve slots. It enumerates the controllers based on PCIe slot number, lowest to highest. If the total number of reservations exceeds the number of slots then the ports are truncated. If you have extra/idle virtual controllers in your VM definition, it will create what you see here. A secondary issue is that DSM doesn't know how many ports are on a controller, so you may need to do some tweaking in grub.cfg to help it know how to arrange the controllers and ports. For baremetal this tends not to be an issue, but under ESXi where hardware is free, it comes into play more frequently. Here are the command directives that help manage this: https://xpenology.com/forum/topic/35937-configuring-sataportmap/?do=findComment&comment=172654 -
Disable HT you are using 8 real cores. Enable HT you are using 4 real cores + four hypertheads. 8 real cores beat 4C+4T any day. Change to DS3617xs and disable HT and you will use all 10 cores. Enable HT and you will use 8 real cores plus 8 hyperthreads. I would still pick the real cores over hyperthreads in this case.
-
Tutorial/Reference: 6.x Loaders and Platforms
flyride replied to flyride's topic in Tutorials and Guides
Run htop and you will see what your system is using graphically - this should alleviate any concern about conflicting kernel messages. -
DSM 6.2 on ESXi 6,7, storage pool crashed (Raid5, ext4)
flyride replied to Rihc0's topic in The Noob Lounge
# mdadm --examine /dev/sdg3 # mdadm --examine /dev/sdh3 -
DSM 6.2 on ESXi 6,7, storage pool crashed (Raid5, ext4)
flyride replied to Rihc0's topic in The Noob Lounge
Argh. We'll see. # mdadm --detail /dev/md3 # mdadm --examine /dev/sd[defgh]3 | egrep 'Event|/dev/sd' -
DSM 6.2 on ESXi 6,7, storage pool crashed (Raid5, ext4)
flyride replied to Rihc0's topic in The Noob Lounge
RAID5 on a hardware controller is going to use the full amount of the disk for the array. There probably is no metadata on the drives at all; it's usually on NVRAM in the controller. With a hardware controller RAID, the array member numbering will correspond to the physical ports on the controller. RAID5 on DSM is over a data partition (actually the third data partition) across all three drives. Each member has metadata information that explains how it fits into the array, and there is no guarantee they are in port order. There is no way to interchange between hardware raid and mdm, and it's incredibly likely that critical data structures have been corrupted by trying to do so. I think this is a basket case. -
Listen to my friend Drax here, he knows what is talking about! Sorry @IG-88 if I oversimplified too much for your preference!
-
Create an account on vmware.com and request a free license, not much more to it than that. You cannot use vcenter with it - only web management, and it has limits (I believe vmotion, vsan and serial port redirection are all locked out) including max # of cores and dies. But otherwise works great.
-
CIFS == SMB
-
You do know you can get a single-CPU license for ESXi for free, right?
-
I'd try booting on the drive that allows boot, then hot plugging the other two drives once it's up and running.
-
Diverging from the tutorials generally results in a lack of network connection. The screen you are displaying is normal - there is nothing else ever displayed there. If you want help troubleshooting please post specific loader, platform type, and DSM version and some details on your VM configuration, and you'll get some advice.
-
All three platforms are functional as virtual machines.
-
I have not found where the metadata is stored to try and manually edit. However, I can see where Synology would try very hard to limit access as the permutations and inter-snapshot dependencies that will occur with Copy On Write and snapshot replications are incredibly complex. Really there is no realistic expectation to relink jobs except in the most simple of circumstances, and one would have to just assume they were correct which would instantly lead to massive corruption if the filesystem states were not exact. I am sorry that I don't have better information about managing replication metadata. If you learn anything new about how it works, please post as I am very interested. Re: Spawning large replicas - I am referring to the ability to use an external disk to prime (start) a new replica rather than wait for it go over the wire. My data sets are also too large to wait for them to replicate over the Internet, and if I break them, I always have to carry a start-up copy to my remote NASes.
-
Look at the bottom of the screen "No UPS is connected" so it does not recognize your UPS reliably. I realize in the original post you show at least one screen shot where it is connected, but it is not connected now. It's offering to connect you to a network-based UPS information source, which you do not have. Some UPS's will time out if they are not polled on a fairly frequent basis (and more frequently than the default NUT value). I run an external NUT in Docker so I have more control over it, and there are options to reduce the polling time which solved a similar problem for my CyberPower UPS. I would guess you can edit some config files to do the same with Synology, but you'll have to dig into it and see where that might be defined.
-
If you delete the job you will orphan the target snapshot, as you say. If the crash resulted in the loss of snapshot jobs on the target, then probably something additional happened you are not reporting. Did you have to reinstall the Snapshot Replication package? Regardless, the metadata about your backup jobs was somehow lost due to reinstall. I have faced this issue many times in the past, and do not know of any way to correct it once metadata is lost. If the metadata is still intact at both source and target, then editing the replication job with new authentication will relink a broken pair in many cases. But I try very hard to protect the replication pair against problems and changes for the reasons you cite. To say it is not healthy for HDD's is a bit of misinformation, however. It's inconvenient, yes, but that is what HDD's are there to do. Also, if you are not using the external media option to spawn your large replicas, you should consider doing so.