

ThorGroup
-
Posts
47 -
Joined
-
Last visited
-
Days Won
27
Posts posted by ThorGroup
-
-
You cannot use VMM when DSM is running as a VM itself. Technically it's possible (you can enable that option in VMWare) but the performance of VM inside of VMM will be like running Windows Vista on Pentium 133Mhz.
-
 3
3
-
-
On 10/1/2021 at 9:15 PM, pocopico said:
@ThorGroup Some text files have been created on the extensions repository. I only have a question, how are the modules loaded ? How do you take care of the dependencies ? Should i also create a script for loading the modules ?
There's a script which takes care of that. Its template is present in redpill-load repo in include/loader-ext/target_exec.sh_ - it is filled-in with by the extension manager.
From the perspective of adding new drivers you should just add entries under kmods key like described in the documentation for devs and the target_exec script will take care of the rest (i.e. insmodding them etc).
There are no interextension dependencies (i.e. between multiple extensions). However, when you specify multiple .ko to load in kmods key they're loaded in that order. There's a mechanism to force extensions load order (extensions key in user_conf as described in dev docs for extensions) as a stop-gap. This should be rare however as drivers loading is for the most part asynchronous in linux anyway.
On 10/2/2021 at 6:48 PM, haydibe said:My current understanding is that an extension bundles one or more main driver and their dependencies. The "kmods" item in a recepie decleare the load order of the modules for this extension during boot.
If the dependencies are not supposed to be included in an extension, is there a mechanism in place to defince dependencies to other extensions? I assume this would require a dependency graph/tree detection, which I assume is highly messy or even imposible to archive with plain bash.
Spot on: dependency graph is needed for that. It would TECHNICALLY be possible in bash but oh boy... that's insane in a very wrong way
 Being serious we're planning and preparing for a rewrite of extension manager so that it can support dependencies properly. The current solution is a good-enough PoC to see if the idea will work. We designed it and brainstormed through multiple people to give the community a PoC which is functional (this is probably close to a 10th iteration of the design of extensions itself) but maybe not with all bells and whistles right away.
Being serious we're planning and preparing for a rewrite of extension manager so that it can support dependencies properly. The current solution is a good-enough PoC to see if the idea will work. We designed it and brainstormed through multiple people to give the community a PoC which is functional (this is probably close to a 10th iteration of the design of extensions itself) but maybe not with all bells and whistles right away.
From the perspective of time choosing bash on principle of "it doesn't require installation" was a mistake.
-
 2
2
-
-
With RP just add it to the synoinfo parameter in user_conf
")
In general you can add up to 4 ports with RP now as the LKM only supports mac1-mac4 syntax. There's a newer syntax called "macs" which accepts comma-separated values but its validation was more complex and we didn't add it yet (but there's a todo in the code).
-
 1
1
-
-
So a quick up-not-to-date
You guys are writing so many post and we're committed to reading all of them and responding where needed.
We promised to write something more last time but few of us had slightly unpredictable life events - given the fact we usually get together physically we encounter a small delay.
So, regarding the SAS issue: the sas-activator may be a flop. We tested it with SSDs and few spare HDDs which obviously weren't >2TB. It seems like the driver syno ships is ancient and while it does work it only runs using SAS2 (limit to 2TB is one of the symptoms). Don't we all love that ancient kernel?
Probably on systems with mpt3sas the situation isn't a problem.
As to the native SAS support and how it works: in short it's useless. The SAS support in syno is tied to just a few hardcoded models. Most of them support only external ports (via eboxes). Some, like in a few FS* products support internal ports. Unfortunately, this is completely useless as the OS checks for custom firmware, board names, responses etc. Is it possible to emulate that? Yes. Does it make sense? In our opinion not at all. With the community-provided drivers we can all be fully independent of the syno-provided .ko in the image. As the LKM supports SAS-to-SATA emulation for the purpose of syno APIs thinking it's a "SATA" device further investment into true SAS doesn't really make sense. To be clear here: there's no loss of functionality or anything. Many things in the kernel actually use the "SATA" type. It seems like syno intended it to be a true SATA but down the road changed it to really mean "a normal SCSI-based disk".
The reason why syno separates real SAS controllers is to offer .... hmm, a lot of hacks over their firmware and timing issues with LSI controllers. So in short emulating a true SAS type in syno will give us no benefits. Saying this we also, very cautiously, should probably make a recommendation: for anyone using a standard array of disks of 4-8 it's probably a better choice to go with a Marvell-based chip which works natively without drivers (and which syno uses as well). For bigger installations LSIs are still preferred (as they're cheap, work with low-cost used SAS drives, save on cabling etc etc).===============================================
And now a massive response stream to all questions
") On 10/3/2021 at 7:51 PM, pigr8 said:
On 10/3/2021 at 7:51 PM, pigr8 said:Running "load-builtin-sas.sh" for thethorgroup.sas-activator->on_boot Loading SAS controller(s) driver(s) Loading LSI SAS 6Gb driver from /lib/modules/mpt2sas.ko [ 2.111757] mpt2sas version 20.00.00.00 loaded [ 2.117289] mpt2sas0: 32 BIT PCI BUS DMA ADDRESSING SUPPORTED, total mem (2022888 kB) [ 2.191254] mpt2sas0: MSI-X vectors supported: 1, no of cores: 2, max_msix_vectors: -1 [ 2.193247] mpt2sas 0000:0b:00.0: irq 73 for MSI/MSI-X [ 2.195245] mpt2sas0-msix0: PCI-MSI-X enabled: IRQ 73 [ 2.195719] mpt2sas0: iomem(0x00000000fd3f0000), mapped(0xffffc90008180000), size(65536) [ 2.197125] mpt2sas0: ioport(0x0000000000005000), size(256) [ 2.308337] mpt2sas0: Allocated physical memory: size(4964 kB) [ 2.309771] mpt2sas0: Current Controller Queue Depth(3305), Max Controller Queue Depth(3432) [ 2.310989] mpt2sas0: Scatter Gather Elements per IO(128) [ 2.370223] mpt2sas0: LSISAS2008: FWVersion(16.00.00.00), ChipRevision(0x03), BiosVersion(00.00.00.00) [ 2.372036] mpt2sas0: Dell 6Gbps SAS HBA: Vendor(0x1000), Device(0x0072), SSVID(0x1028), SSDID(0x1F1C) [ 2.373611] mpt2sas0: Protocol=(Initiator,Target), Capabilities=(TLR,EEDP,Snapshot Buffer,Diag Trace Buffer,Task Set Full,NCQ) [ 2.376558] mpt2sas0: sending port enable !! [ 2.384638] mpt2sas0: host_add: handle(0x0001), sas_addr(0x590b11c027f7ff00), phys(8) [ 2.387142] mpt2sas0: detecting: handle(0x0009), sas_address(0x4433221100000000), phy(0) [ 2.388790] mpt2sas0: REPORT_LUNS: handle(0x0009), retries(0) [ 2.389874] mpt2sas0: TEST_UNIT_READY: handle(0x0009), lun(0) [ 2.396730] scsi 1:0:0:0: SATA: handle(0x0009), sas_addr(0x4433221100000000), phy(0), device_name(0x50014ee26320545e) [ 2.408946] mpt2sas0: detecting: handle(0x000b), sas_address(0x4433221101000000), phy(1) [ 2.410586] mpt2sas0: REPORT_LUNS: handle(0x000b), retries(0) [ 2.411748] mpt2sas0: TEST_UNIT_READY: handle(0x000b), lun(0) [ 2.422008] scsi 1:0:1:0: SATA: handle(0x000b), sas_addr(0x4433221101000000), phy(1), device_name(0x50014ee26320252f) [ 17.648369] mpt2sas0: detecting: handle(0x000a), sas_address(0x4433221102000000), phy(2) [ 17.651123] mpt2sas0: REPORT_LUNS: handle(0x000a), retries(0) [ 17.652856] mpt2sas0: TEST_UNIT_READY: handle(0x000a), lun(0) [ 17.662223] scsi 1:0:2:0: SATA: handle(0x000a), sas_addr(0x4433221102000000), phy(2), device_name(0x50014ee20ef68994) [ 32.723942] mpt2sas0: detecting: handle(0x000c), sas_address(0x4433221103000000), phy(3) [ 32.726898] mpt2sas0: REPORT_LUNS: handle(0x000c), retries(0) [ 32.728908] mpt2sas0: TEST_UNIT_READY: handle(0x000c), lun(0) [ 32.743439] scsi 1:0:3:0: SATA: handle(0x000c), sas_addr(0x4433221103000000), phy(3), device_name(0x50014ee20dcd759f) [ 47.822440] mpt2sas0: detecting: handle(0x000d), sas_address(0x4433221104000000), phy(4) [ 47.825418] mpt2sas0: REPORT_LUNS: handle(0x000d), retries(0) [ 47.833947] mpt2sas0: TEST_UNIT_READY: handle(0x000d), lun(0) [ 47.847305] scsi 1:0:4:0: SATA: handle(0x000d), sas_addr(0x4433221104000000), phy(4), device_name(0x50014ee2647a1448) [ 62.933161] mpt2sas0: detecting: handle(0x000e), sas_address(0x4433221105000000), phy(5) [ 62.936117] mpt2sas0: REPORT_LUNS: handle(0x000e), retries(0) [ 62.938119] mpt2sas0: TEST_UNIT_READY: handle(0x000e), lun(0) [ 62.947998] scsi 1:0:5:0: SATA: handle(0x000e), sas_addr(0x4433221105000000), phy(5), device_name(0x5000c5008c5e912d) [ 78.018894] mpt2sas0: detecting: handle(0x000f), sas_address(0x4433221106000000), phy(6) [ 78.028297] mpt2sas0: REPORT_LUNS: handle(0x000f), retries(0) [ 78.030129] mpt2sas0: TEST_UNIT_READY: handle(0x000f), lun(0) [ 78.039803] scsi 1:0:6:0: SATA: handle(0x000f), sas_addr(0x4433221106000000), phy(6), device_name(0x5002538e49b3b3ca) [ 93.110287] mpt2sas0: port enable: SUCCESSi can confirm that it works now with the stock v20.0 mpt2sas.ko from DSM v7.0.1, no need for the custom .ko from @pocopico , all drivers (7 in my case) show up as /dev/sd* and DSM wants to install itself (did not try to proceed but i guess it works).
still persist the problem that if the loader is on sata0:0 it reserves /dev/sda, so the first disk connected to the LSI shows up as /dev/sdb.That pesky /dev/sda may actually be a bug in the syno kernel. According to the IdxMap it should NOT present itself at the first spot grrr... we set it to map controller 1 to like 20 and it still used the first disk (and only the first) at /dev/sda. There may be a way to use remap of ports (another feature which syno uses extensively on their boards) to move it. It would actually explain why syno uses a long string of remaps (comically long, like 30-entries-long) instead of a map on some of their boards... as map seems to not work properly. We will play with it. Can you create an issue in the redpill-lkm repo, so we don't lose track of that?
It may also be a problem with magic index shifting... it looks like Jun's loader may have been fixing a bug in syno's remap code.On 10/3/2021 at 7:56 PM, pigr8 said:another minor issue using the sas-activator and stock v20.0 driver is that on bootup it's slow to load the drivers, for each one the serial spams this (example on the first port detection, seen as /dev/sdb on redpill but as /dev/sda on jun's loader):
[ 2.339686] scsi 1:0:1:0: Direct-Access WDC WD30EFRX-68EUZN0 0A82 PQ: 0 ANSI: 6 [ 2.341594] sd 1:0:0:0: [sdb] Write Protect is off [ 2.341789] scsi 1:0:1:0: SATA: handle(0x000b), sas_addr(0x4433221101000000), phy(1), device_name(0x50014ee26320252f) [ 2.341791] scsi 1:0:1:0: SATA: enclosure_logical_id(0x590b11c027f7ff00), slot(2) [ 2.341866] scsi 1:0:1:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) [ 2.342130] scsi 1:0:1:0: serial_number( WD-WCC4N0LDREV8) [ 2.342133] scsi 1:0:1:0: qdepth(32), tagged(1), simple(0), ordered(0), scsi_level(7), cmd_que(1) [ 2.347292] want_idx 1 index 2. delay and reget [ 2.351539] sd 1:0:0:0: [sdb] Mode Sense: 7f 00 10 08 [ 2.352633] sd 1:0:0:0: [sdb] Write cache: enabled, read cache: enabled, supports DPO and FUA [ 2.357909] sdb: sdb1 sdb2 sdb5 [ 2.365253] sd 1:0:0:0: [sdb] Attached SCSI disk [ 3.346388] want_idx 1 index 2 [ 3.347047] want_idx 1 index 2. delay and reget [ 4.349242] want_idx 1 index 2 [ 4.350358] want_idx 1 index 2. delay and reget [ 5.352080] want_idx 1 index 2 [ 5.352188] want_idx 1 index 2. delay and reget [ 6.354932] want_idx 1 index 2 [ 6.356676] want_idx 1 index 2. delay and reget [ 7.359783] want_idx 1 index 2 [ 7.359895] want_idx 1 index 2. delay and reget [ 8.361635] want_idx 1 index 2 [ 8.361747] want_idx 1 index 2. delay and reget [ 9.364484] want_idx 1 index 2 [ 9.366152] want_idx 1 index 2. delay and reget [ 10.369338] want_idx 1 index 2 [ 10.369958] want_idx 1 index 2. delay and reget [ 11.371201] want_idx 1 index 2 [ 11.371841] want_idx 1 index 2. delay and reget [ 12.374042] want_idx 1 index 2 [ 12.374712] want_idx 1 index 2. delay and reget [ 13.376895] want_idx 1 index 2 [ 13.377569] want_idx 1 index 2. delay and reget [ 14.537123] want_idx 1 index 2 [ 14.538402] want_idx 1 index 2. delay and reget [ 15.540697] want_idx 1 index 2 [ 15.541951] want_idx 1 index 2. delay and reget [ 16.544593] want_idx 1 index 2 [ 16.545475] want_idx 1 index 2. delay and reget [ 17.547442] want_idx 1 index 2edit 1: with @pocopico .ko it does not do that.
edit 2: another problem could be that with either stock mpt2sas.ko or the compiled one, disks larger than a 2tb wont show up as they should.
- disk 1 on lsi port 1, fdisk (/dev/sda with jun's loader)
Disk /dev/sda: 2.7 TiB, 3000592982016 bytes, 5860533168 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: 337DF73B-5685-46E1-9DA5-2960BA2BA3C8 Device Start End Sectors Size Type /dev/sda1 2048 4982527 4980480 2.4G Linux RAID /dev/sda2 4982528 9176831 4194304 2G Linux RAID /dev/sda5 9453280 5860326239 5850872960 2.7T Linux RAID- same disk 1 on lsi port 1, fdisk (/dev/sdb on redpill)
Disk /dev/sdb: 2048 GB, 2199023255040 bytes, 4294967295 sectors 267349 cylinders, 255 heads, 63 sectors/track Units: sectors of 1 * 512 = 512 bytes Device Boot StartCHS EndCHS StartLBA EndLBA Sectors Size Id Type /dev/sdb1 0,0,1 1023,254,63 1 4294967295 4294967295 2047G ee EFI GPT fdisk: device has more than 2^32 sectors, can't use all of themYup... exactly the problem as described at the beginning of the post. It was too easy to simply load their drivers. This lead us to write that summary on the top - it looks like anyone dependent on the LSI card will need to use a 3rd-party driver as the syno one is ancient and only uses SAS2 (and thus the limit).
On 10/3/2021 at 8:22 PM, Orphée said:@ThorGroup Regardiing Surveillance Station licences there is an online registering when you add your bought licence inside the app.
As online Synology services require real SN/Mac pair to work, you must have them real in order to buy/add new camera licence.
If I'm not mistaken, you even can "unregister"/"register" your bought licences from old NAS when you switch to a new one.
There is en offline procedure too if I remember correctly.
https://www.synology.com/en-global/products/Device_License_Pack
Edit : As SS works with its default 2 licences with generated SN on your current loaders.
I bet we would have the 8 default licences on DVA even with generated SN.
Real question is about AI features (like HW transcoding on DS918+ without real SN not working without a patch)
For us, to be honest, the main drive towards DVA are the native nVidia drivers. While they surely can be installed on other DS it would be just simply easier to install them from the pkg manager and call it a day. As for the surveillance station stuff (and photo station and similar) patching binaries isn't that good of an approach. This is because they're checksumed. Maybe not these but others are. In general changing any of the signed syno files in the OS is a slippery slope - it's better to make sure the OS thinks it's a real motherboard rather than modify the system to not check something. The more things we can emulate in the kernel the better as updates are unlikely to break them (as they would break real hardware as well).
On 10/3/2021 at 9:21 PM, T-REX-XP said:@ThorGroup, Here is a few things regarding the FAn control with PMU
I've tested the following way to set speed of the CPU FAN on 6.2.3
insmod hwmon-vid.ko insmod nct6775.kooptional install sensors(lm-sensors) via ipkg
Then the fan speed can be set like this:
#default value echo 5 > /sys/devices/platform/nct6775.656/hwmon/hwmon1/pwm2_enableHere is a few userful commands:
#find all pwm: find /sys/devices -type f -name "pwm*" #find beep /sys/devices/platform/nct6775.656/hwmon/hwmon1/beep_enable #enable /disable beep echo 0 > /sys/devices/platform/nct6775.656/hwmon/hwmon1/beep_enable | sensors | grep beepSo, the vPMU can use it for manipulating the CPU FAN speed.
But we need to resolve the following issues:
- build nct6775 for dsm 7.0 (I now that this module is one of the many modules for different IO chips on motherboard), let's start from it, then add an additional one
- build pcspeaker module
- implement vPMU to use software methods for manipulating the FAN speed
@pocopico, could you please build nct6775 module for 918 dsm 7.0 ?? Thanks.
I will prepare the RP extension for that module
Thanks in advance.
See, the issue is while we can surely control a fan from PMU it's completely different on every motherboard. Like they never did put any standards in - guys from lm-sensors are pulling their hairs out to handle all that. We don't have a good idea just yet how to make this good so that everyone can just define their way of controlling the fans but this is something we have on the list as "todo" (albeit low priority as usually people just set their CPU and case fans from the bios, with newer motherboards you can even upload/set fan curves in the BIOS/UEFI itself).
On 10/3/2021 at 9:45 PM, pigr8 said:done, hope they could track bugs and quirks better on gh.
Yes we do (even if slowly!)
GH is much easier to deal with simply because we can split multiple problems into "buckets" and easily ping people with that particular problem. Forum isn't really a good tool for that (but fantastic for a general discussion and support questions!).
On 10/3/2021 at 10:39 PM, Schyzo said:Tried to add modules from @pocopico(bnx2x and bnx2) with OSFMount after image was created, but no success, no network 😕
We have to include modules (*.ko) BEFORE image is created ?
.ko can be included using RP extension. You can find examples and documentation in the redpill-load repo. It will simply load .ko you list automatically. Built-in card in gen8 should work with these drivers.
On 10/3/2021 at 11:59 PM, luckcolors said:Hello @ThorGroup
I'm trying to run redpill for 6.2.3-25556 on proxmox.
Thank you for your work so far, the virtio network drivers are working perfectly and i've been able to connect to the DSM.

I was wondering if it's not yet supported using the virtio block/virtio SCSI drivers for speeding up disk access.
I suppose sata emulation would be fine for normal HDDs but for running an Nvme SSD cache it's going to be a bottleneck.
I know it's definetely not a must-be-done-now kinda issue for the beta release but would it be possible to add support for these kind of virtual drives?
There's two different virtio implementation that can be used:
- Virtio Block (1 pcie address per device)
- Virtio SCSI (1 pcie address per controller, many devices per controller)
The virtio SCSI one seems the most interesting since it claims "Standard device naming". Documentation: https://www.ovirt.org/develop/release-management/features/storage/virtio-scsi.html
If you think this is better reported in the virtio git issues. I'll move it there.
Edit 1:
Forgot to add:
They are not detected at all during the install wizard, i'm going to do more testing to confirm they aren't detected at all awell in pool creation.
Edit 2:
Well i was completely wrong DSM seems to detect them both at setup time and later.
It even updates the disks listing in realtime matching what i add or remove from proxmox.
I'm going to go touch grass now.
Earlier it wasn't doing either so i guess i had the wrong chipset? (current i440fx).
Edit 3:
The chipset wasn't it.
It's working aswell with Q35 now and the diskmap is shifted as others pointed out.I guess the problem solved itself or i was doing something wrong
I'm pretty sure earlier thought that i did run the VM multiple times with atleast one disk attached via virtio SCSI and the setup page complained that there where no disks available (i'm currently testing with 32GB virtual drives).
On any case. Thanks again for your work.
To give you more context for the "SATA" thing: it's stupid. It looks like a huge legacy part in the syno code. As we wrote above "SATA" is used in the syno kernel additions as kind of "anything SCSI-based which is not a USB drive, not iSCSI and not cache-NVMe". There's no performance penalty or anything. In face they themselves treat VirtIO as "SATA". Ultimately, the kernel doesn't care about their types at all. These are only there to guide the OS what to do and not do with these drives (e.g. don't make swap partition or create OS partitions on iSCSI). It's like with VirtIO ethernet driver: DSM will show a warning that the network is 10/100Mb [as it sees it as "unknown"] but will happily push gigabits of traffic through it.
As for the general advice if you use QEmu-based systems use Q35 unless you have a good damn reason for older chipset (e.g. Windows 98 VM or something along these lines). They keep the i440fx as the default as it's most compatible but in general Q35 is the one you should use for any modern OSes.
As for NVMe SSD: these are well... PCI-Ex devices. They go through a slightly different pathway. But again: kernel doesn't care really. There are mods for the OS to see non-syno drives as valid SSD cache. However, with some kernel tweaks we can probably get rid of these modifications (hint: if there isn't a GH ticker it will be appreciate in the redpill-lkm repository, so we have this on our radar).
On 10/4/2021 at 12:18 AM, urundai said:quick question: Per the loader documentation, one can remove vid and pid if they are using SATA based boot. Unfortunately, when I do that, my build fails with 'unbound parameter extra_cmdline('vid')'.
For now, I am still leaving vid/pid in there for my esxi but not sure why the build fails. Any thoughts?
pinging @haydibe here. The loader itself doesn't care [now] but probably the container config has some assumption somewhere. You can leave them, you can even set them to DEAD and BEEF - it will not cause any problems but a warning message during boot
When they're set but not needed they're only validated to the point of "is this a hex number".
On 10/4/2021 at 2:08 AM, pigr8 said:try not to add either sas-activator nor pocopico extension, add this in user config and rebuild redpill again and report the attempt
"synoinfo": { "supportsas": "yes" },[note to ANYONE doing supportsas=yes]
You shouldn't really do that. This activates syno-specific SAS support which will break a lot of things. This flag is horribly misleading and used in aaaaa looot of syno code. This is way more than just loading the driver. This is more of a "activate our hacks for broken LSI firmware we flashed ... and do these totally not-SAS things on this controller ... and when you are at that can you maybe also tell the controller to take over controlling some of the leds ... oh, and load the driver".
So folks, really, don't touch that option with a long pole - it's a trap. It would only be useful if full ebox emulation was present.On 10/4/2021 at 5:26 PM, 0ne1astK155 said:Can you apply a Github repo to update your script? Thx!
We're working with haydibe on integrating the container build into the redpill-repo itself
It just spun as a very cool project in this thread and it turns out it's actually great.On 10/4/2021 at 5:28 PM, Rebutia said:Hi WiteWulf, just a quick question, is it because of the change in DSM6/7 that we can no longer see console booting message like what we did in the DSM5 xpenology loader? No I am not urging anybody to include this nostalgic function, just curious, and it also seems to be easier for debugging.
Adding to what WiteWulf said here: yes, it's because of the kernel changes in ~v6.
From the Linux perspective it doesn't care where messages are sent - every printk() goes to /dev/console. Something has to actually handle the /dev/console however. This needs a driver. To see messages on the screen you need to have some sort of framebuffer/vga-like driver. By default every desktop distro will obviously include vga driver in the kernel, but in embedded systems it's rare to include it. Syno simply stripped it from the kernel build. GRUB renders the text and passes control to the kernel and kernel decides to not reset the screen nor display anything on it. It's as simple as that, that's why what GRUB leaves never disappears from the screen
We didn't try but probably if you use nV GPU for boot and then load nV drivers for transcoding the screen may turn simply black (or perhaps even disable the connected display?).
On 10/4/2021 at 9:35 PM, nemesis122 said:I have try a lot of loaders on my server builds with different loaders here is my experience:
DSM 918+ Pro: has Kernel 4.4 und with the correct config you have hardware decoding. cons: with VMM you cant install/ load other loaders 1.02b 1.03b or 1.04b there is no lan connection i dont know why i tried everyting with linux ubuntu or windows all is ok.
DSM 3615+ : pro is the most stable loader VMM works great also with loader 1.02b and 1.03 and 1.04 for virtualmaschines con: with 10Gbit you have only 500 MB read and write
DSM3617+ : pro this loader is very fast in DSM /it has the most read and write 10 gbit 700 - 800 Mb with raid 0 and 5 HDD and 1 SSD and VMM works great the same as 3615 but all is running super fast and smooth .
I have tested this loaders on gen8 with CPU 1240v2 1230v2 original Xeon and on a ASUS87iplus MB i hate this f**** Bios but with the 3617 loader MBR i have now installed my favorite system 3617xs 😍
So in short the best Loader at the moment is for me 1.03b with 3617 DSM 6.2 my config is always volume1 SSD for plex libary/ virtual Maschines / and and all apps / volume2 5x6tb is for the data.
918+ is out of question for 1240v2 as it doesn't have MOVBE instruction and 4.4 as built by syno requires it. Even if it "boots" things will start randomly crashing. The 3615 speed shouldn't be limited by the platform itself. With such speeds you may need to tweak kernel networking but this is honestly the same on syno as for any other Linux box.
We want to add 3617 but that hotplug issue is that annoying showstopper. As we were busy we didn't debug it much beyond what's said on GH. It's probably something stupidly small...On 10/5/2021 at 12:50 AM, Schyzo said:@OrphéeGod, it's seem more difficult than Proxmox ^^
Once the image created, I had tg3.ko in i386-pc and in x86_64-efi with OSFMount. Edited the grub.cfg with add "insmod tg3.ko" under "insmod gzio"
Save and copy the image.
But same problem, no network on the Proliant. I don't know what to do now. Maybe look Proxmox tutorial ? 😢
Edit : Trying with add libphy before t3g, testing in progress
Result : Same problem, no network 😢
It's more difficult because you're editing the image and making changes which will explode in the future. There's a reason why we automated that hard stuff into extensions
On 10/5/2021 at 2:01 AM, Mixpower said:I am trying to find out what is going wrong, so I'm using VSP on my Gen8 to check the output.
It says at the beginning that com0 can not be found is this a problem?
[ 2.256293] <redpill/runtime_config.c:187> Found platform definition for "DS3615xs" [ 2.258820] <redpill/runtime_config.c:198> Validating runtime config... [ 2.261028] <redpill/runtime_config.c:48> Configured boot device type to USB [ 2.263364] <redpill/runtime_config.c:207> Config validation resulted in OK [ 2.265755] <redpill/runtime_config.c:224> Runtime config populated [ 2.267810] <redpill/uart_fixer.c:72> Registering UART fixer shim [ 2.270015] <redpill/uart_swapper.c:410> Swapping ttyS1<=>ttyS0 started [ 2.272211] <redpill/override_symbol.c:257> Overriding uart_match_port() with uart_match_port_collector [redpill]()<ffffffffa0004290> [ 2.273728] <redpill/override_symbol.c:172> Saved uart_match_port() ptr <ffffffff813101d0> [ 2.273730] <redpill/memory_helper.c:18> Disabling memory protection for page(s) at ffffffff813101d0+12/1 (<<ffffffff81310000) [ 2.273859] <redpill/call_protected.c:84> Got addr ffffffff810303e0 for flush_tlb_all [ 2.273874] <redpill/override_sol.c:221> Obtaining lock for <uart_match_port+0x0/0x70/ffffffff813101d0> [ 2.273874] <redpill/override_symbol.c:182> Generating trampoline [ 2.273879] <redpill/override_symbol.c:188> Generated trampoline to uart_match_port_collector+0x0/0x60 [redpill]<ffffffffa0004290> for uart_match_port<ffffffff813101d0>: [ 2.273880] <redpill/override_symbol.c:221> Writing trampoline code to <ffffffff813101d0> [ 2.273880] <redpill/override_symbol.c:221> Released lock for <ffffffff813101d0> [ 2.273881] <redpill/memory_helper.c:34> Enabling memory protection for page(s) at ffffffff813101d0+12/1 (<<ffffffff81310000) [ 2.273893] <redpill/override_symbol.c:269> Successfully overrode uart_match_port() with trampoline to uart_match_port_collector+0x0/0x60 [redpill]<ffffffffa0004290> [ 2.275464] <redpill/call_protected.c:108> Got addr ffffffff813168b0 for serial8250_find_port [ 2.275465] <redpill/uart_swapper.c:113> Found ptr to line=0 iobase=0x2f8 irq=3 [ 2.275466] <redpill/uart_swapper.c:113> Found ptr to line=1 iobase=0x3f8 irq=4 [ 2.275467] <redpill/uart_swapper.c:113> Found ptr to line=2 iobase=0x3e8 irq=4 [ 2.275467] <redpill/uart_swapper.c:113> Found ptr to line=3 iobase=0x2e8 irq=3 [ 2.275468] <redpill/override_symbol.c:279> Restoring uart_match_port<ffffffff813101d0> to original code [ 2.275469] <redpill/memory_helper.c:18> Disabling memory protection for page(s) at ffffffff813101d0+12/1 (<<ffffffff81310000) [ 2.275479] <redpill/override_symbol.c:250> Obtaining lock for <uart_match_port+0x0/0x70/ffffffff813101d0> [ 2.275480] <redpill/override_symbol.c:250> Writing original code to <ffffffff813101d0> [ 2.275480] <redpill/override_symbol.c:250> Released lock for <ffffffff813101d0> [ 2.275481] <redpill/memory_helper.c:34> Enabling memory protection for page(s) at ffffffff813101d0+12/1 (<<ffffffff81310000) [ 2.275489] <redpill/override_symbol.c:287> Successfully restored original code of uart_match_port [ 2.275490] <redpill/override_symbol.c:145> FreeingS for uart_match_port [ 2.550824] <redpill/uart_swapper.c:425> Disabling preempt & locking console [ 2.553179] <redpill/uart_swapper.c:427> ======= OUTPUT ON THIS PORT WILL STOP AND CONTINUE ON ANOTHER ONE (swapping ttyS1 & ttyS0) ======= [ 2.557453] <redpill/uart_swapper.c:429> ### LAST MESSAGE BEFORE SWAP ON "OLD" PORT ttyS1<=>ttyS0
Also the output stops right here is there anything I can change about that?
Any help would be appreciated!
Don't you have COMs inverted in the RBSU?
Gen8 is such an amazing server but iLO... iLO was written past the Bellmer's curve (e.g. to enable PCI-passthrough you need RMRR hacks because HP decided to mess with it against the ACPI specs).On 10/5/2021 at 3:58 AM, Mixpower said:Thanks, I used that indeed!
I tried that and put it on com1 but when I ssh into iLO using putty and type VSP it always connects on com2 even when I disable VSP it still does that.
EDIT: Just found there is another setting in the BIOS for the port and now it works on com1! Looks like there is something wrong with my vid/pid settings I'll dig into it and report back.
EDIT2: It just does this over and over and over, tried different usb ports but it does not matter it keeps doing this, I checked the VID and PID again and there are correct anyone has a clue?
:: Mounting procfs ... [ OK ] :: Mounting tmpfs ... [ OK ] :: Mounting devtmpfs ... [FAILED] :: Mounting devpts ... [ OK ] :: Mounting sysfs ... [ OK ] [ 10.647880] sdu: sdu1 sdu2 sdu3 [ 10.667520] sd 7:0:0:0: [sdu] No Caching mode page found :: Loading modul[ 10.693251] sd 7:0:0:0: [sdu] Assuming drive cache: write through e sg[ 10.723056] sd 7:0:0:0: [sdu] Attached SCSI disk [ 15.738964] usb 3-1: USB disconnect, device number 2 [ 17.968475] usb 3-1: new full-speed USB device number 3 using uhci_hcd [ 18.156068] Got empty serial number. Generate serial number from product. [ 18.195263] <redpill/usb_boot_shim.c:75> Found new device <vid=03f0, pid=7029> - didn't match expected <vid=26bd, pid=9917> (prev_shimmed=1) [ 27.752685] usb 3-1: USB disconnect, device number 3 [ 29.982199] usb 3-1: new full-speed USB device number 4 using uhci_hcd [ 30.170009] Got empty serial number. Generate serial number from product. [ 30.209179] <redpill/usb_boot_shim.c:75> Found new device <vid=03f0, pid=7029> - didn't match expected <vid=26bd, pid=9917> (prev_shimmed=1) [ 39.766411] usb 3-1: USB disconnect, device number 4 [ 41.995925] usb 3-1: new full-speed USB device number 5 using uhci_hcd [ 42.183925] Got empty serial number. Generate serial number from product. [ 42.223078] <redpill/usb_boot_shim.c:75> Found new device <vid=03f0, pid=7029> - didn't match expected <vid=26bd, pid=9917> (prev_shimmed=1) [ 51.780135] usb 3-1: USB disconnect, device number 5 [ 54.009649] usb 3-1: new full-speed USB device number 6 using uhci_hcd [ 54.197887] Got empty serial number. Generate serial number from product. [ 54.236997] <redpill/usb_boot_shim.c:75> Found new device <vid=03f0, pid=7029> - didn't match expected <vid=26bd, pid=9917> (prev_shimmed=1) [ 63.793860] usb 3-1: USB disconnect, device number 6 [ 66.023374] usb 3-1: new full-speed USB device number 7 using uhci_hcd [ 66.210735] Got empty serial number. Generate serial number from product. [ 66.250919] <redpill/usb_boot_shim.c:75> Found new device <vid=03f0, pid=7029> - didn't match expected <vid=26bd, pid=9917> (prev_shimmed=1) [ 75.807584] usb 3-1: USB disconnect, device number 7 [ 78.037099] usb 3-1: new full-speed USB device number 8 using uhci_hcd [ 78.225662] Got empty serial number. Generate serial number from product. [ 78.264836] <redpill/usb_boot_shim.c:75> Found new device <vid=03f0, pid=7029> - didn't match expected <vid=26bd, pid=9917> (prev_shimmed=1) [ 87.821310] usb 3-1: USB disconnect, device number 8
If I unplug the usbdrive and plug it back in it does this but then goes back to the same again.
[ 198.784282] usb-storage 1-1.5:1.0: USB Mass Storage device detected [ 198.815397] scsi8 : usb-storage 1-1.5:1.0 [ 198.835055] <redpill/usb_boot_shim.c:91> Device <vid=26bd, pid=9917> shimmed to <vid=f400, pid=f400> [ 199.910770] scsi 8:0:0:0: Direct-Access USB DISK 2.0 PMAP PQ: 0 ANSI: 6 [ 199.954664] <redpill/scsi_notifier.c:65> Probing SCSI device using sd_probe_shim [ 199.990468] <redpill/scsi_notifier.c:77> Triggering SCSI_EVT_DEV_PROBING notifications [ 200.028866] <redpill/scsi_notifier.c:87> Calling original sd_probe() [ 200.060103] <redpill/scsi_notifier.c:91> Triggering SCSI_EVT_DEV_PROBED notifications - sd_probe() exit=0 [ 200.962090] sd 8:0:0:0: [synoboot] 15654912 512-byte logical blocks: (8.01 GB/7.46 GiB) [ 201.002757] sd 8:0:0:0: [synoboot] Write Protect is off [ 201.028251] sd 8:0:0:0: [synoboot] Mode Sense: 23 00 00 00 [ 201.058571] sd 8:0:0:0: [synoboot] No Caching mode page found [ 201.087422] sd 8:0:0:0: [synoboot] Assuming drive cache: write through [ 201.123769] sd 8:0:0:0: [synoboot] No Caching mode page found [ 201.151792] sd 8:0:0:0: [synoboot] Assuming drive cache: write through [ 201.206746] synoboot: synoboot1 synoboot2 synoboot3 [ 201.234149] sd 8:0:0:0: [synoboot] No Caching mode page found [ 201.262376] sd 8:0:0:0: [synoboot] Assuming drive cache: write through [ 201.294711] sd 8:0:0:0: [synoboot] Attached SCSI removable disk [ 207.958562] usb 3-1: USB disconnect, device number 18 [ 210.188074] usb 3-1: new full-speed USB device number 19 using uhci_hcd [ 210.376874] Got empty serial number. Generate serial number from product. [ 210.415992] <redpill/usb_boot_shim.c:75> Found new device <vid=03f0, pid=7029> - didn't match expected <vid=26bd, pid=9917> (prev_shimmed=1)
If it detects synoboot it's all good and it means it detected the stick properly. In other words your vid/pid combo is correct.
On 10/5/2021 at 1:32 PM, Tango38317 said:HI,
this days i have created a test nas V7.0.1-42218 (DS918+)
VM on Proxmox, V7.0-11
Boot from USB with args.
Machine Q35
CPU: KVM
UEFI Boot
Virtio NW
Virtio SCSI
Build and boot are successfull with one disk (Disk id 8? with 4 slots?)
i tried to add a second disk and add it to the SHR Volume for testing. But i cannot add this disk, because it does not meet the requirements (screenshot attached).
i tried to change from VirtiO SCSI to Virtio SCSI-Single. Does not change the issue, but i observed one thing:
When starting Vm with VirtIO SCSI and 2 Disk i see following messages in serial console, but not after changing to VirtIO SCSI Single.
[ 5.533294] sd 7:0:0:0: [synoboot] Attached SCSI disk [ 6.271152] want_idx 6 index 7 [ 6.271551] want_idx 6 index 7. delay and reget [ 7.272150] want_idx 6 index 7 [ 7.272549] want_idx 6 index 7. delay and reget [ 8.273154] want_idx 6 index 7 [ 8.273567] want_idx 6 index 7. delay and reget [ 9.274128] want_idx 6 index 7 [ 9.274574] want_idx 6 index 7. delay and reget [ 10.275084] want_idx 6 index 7 [ 10.275584] want_idx 6 index 7. delay and reget [ 11.276094] want_idx 6 index 7 [ 11.276645] want_idx 6 index 7. delay and reget [ 12.277102] want_idx 6 index 7 [ 12.277644] want_idx 6 index 7. delay and reget [ 13.278149] want_idx 6 index 7 [ 13.278689] want_idx 6 index 7. delay and reget [ 14.279161] want_idx 6 index 7 [ 14.279705] want_idx 6 index 7. delay and reget [ 15.280132] want_idx 6 index 7 [ 15.280661] want_idx 6 index 7. delay and reget [ 16.281095] want_idx 6 index 7 [ 16.281579] want_idx 6 index 7. delay and reget
is this a known behavior, or is there maybe some solution for this issue?
br
Chris
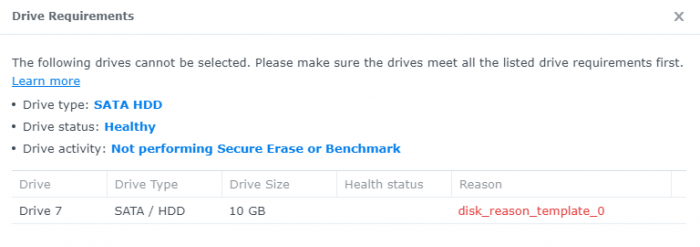
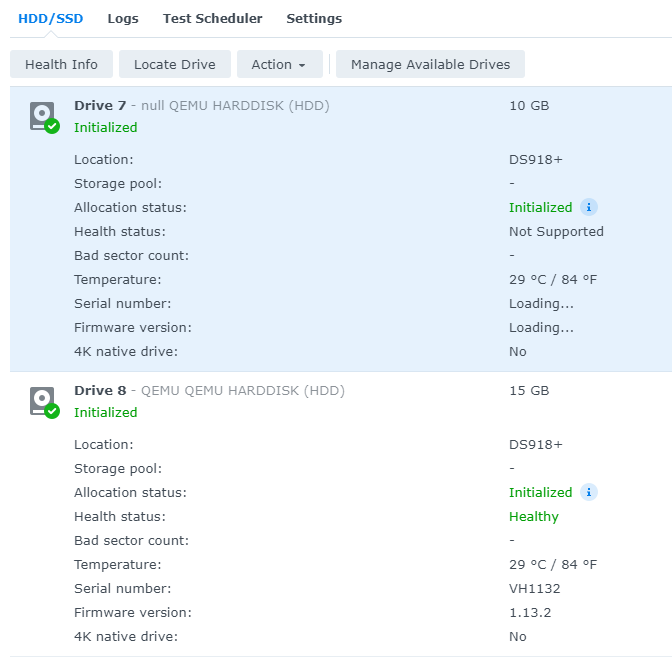
This is something new with these want_idx. Can you add it as an issue in the redpill-lkm repo? In general you shouldn't use the VirtIO SCSI Single.
On 10/5/2021 at 7:01 PM, Orphée said:I'm playing with DS918+ loader 6.2.4 on VMWare Workstation.
It works, I installed Moments to check face detection...
Do you know what it means ? :
This is a completely different issue related to security checks in the DSM photo itself. If you google search within xpenology.com you will find many mentions and discussion on patching that in the system. In short: a real S/N is needed to make validation happy without DSM patching.
On 10/5/2021 at 11:06 PM, Orphée said:For those who might use VMWare Workstation to do some tests.
Serial console from TCPIP is not available from GUI, and not officially supported.
But you can edit your .vmx file to add :
serial0.present = "TRUE" serial0.fileType = "network" serial0.fileName = "0.0.0.0:10021" serial0.network.endPoint = "server" serial0.startConnected = "TRUE"10021 or whatever suits you.
Then you can telnet to the serial port as usual.
Wait... are you saying this doesn't require the paid license but just a config edit?!
Also: there's a new bash tool in the loader repo called "always-telnet" - you may find it useful with working with VMWare serial ports.
On 10/6/2021 at 12:03 AM, WiteWulf said:Oh my word, that was ridiculously quick and easy! That's gonna make testing new images a whole lot simpler. I've now got a virtual 918+ running in VMware Fusion on my iMac
*edit* Wow, I've got to get my Gen8 migrated to ESXi, it's *so* much quicker to reboot, if nothing else!
Migrate it to Proxmox, it will be way less problematic,join the dark side ;]
ESXi + gen8 is an issue in a lot of places. VMWare dropped support for newer versions, there are weird memory leaks in newer versions etc. It's REALLY not a good platform for ESXi (not that we're biased against ESXi in general but that's another story ;)).
...if only Gen8 had 32GB RAM support. Oh, wait, it can support it but Intel forced HP to disable it.
On 10/6/2021 at 4:25 AM, DaveD said:I am currently running an HP Gen8 Microserver 16gb memory and E3-1265L V2 currently running as a baremetal XPenology server with Plex Server as the only app curently installed so is bare metal - ESXi or Proxmox the way I should be looking to go now with the new loader and V7 + versions as I seem to remember someone on here saying Proxmox was the way to go now ?
We use and recommend Proxmox [not just for RP] - open source, not limited in features, fast, supported and doesn't cut out hardware. The only problem on gen8 is PCI-Ex passthru due to RMRR but if you search on GitHub there are patches.
On 10/6/2021 at 4:27 AM, Orphée said:Just a tip about proxmox with HP Gen8 :
If you plan to use it with HBA passthrough, forget it, a bug make it impossible.
Whereas it works on ESXi.
The current patch does not work with Proxmox 7
https://github.com/kiler129/relax-intel-rmrr
Edit : maybe an option here :
Exactly that patch - we use this ourselves for long time and it's rock stable. ESXi does essentially the same thing - just ignore bogus RMRR from HP.
On 10/6/2021 at 4:19 PM, XAXISNL said:As long as there is no powerbutton module, I have used a workaround in Proxmox by using hookscripts.
When shutting down the VM from Proxmox, at the 'pre-stop phase' it SSH's into DSM and issues the 'shutdown now' command.
elsif ($phase eq 'pre-stop') { # Third phase 'pre-stop' will be executed before stopping the guest # via the API. Will not be executed if the guest is stopped from # within e.g., with a 'poweroff' print "$vmid will be stopped.\n"; print "Shutting down DSM\n"; system("ssh -T USERNAME\@xx\.xx\.xx\.xx 'sudo shutdown now'");Works great!
Ok, you surprised us here! Never heard of that before.
However, we need to check how full vmtools do that.
On 10/6/2021 at 4:39 PM, WiteWulf said:Yeah, we need to ideally wait for TTG to support 7.0.1, or as a bodge, for Jumkey to update their repo to support extensions.
In the [red hot] queue. At this point, as many people tested it, we can just merge it but we really want to look at the kernel in a disassembler and see if nothing changed and the automatic path is correct. We try to make sure what we publish is well tested
On 10/6/2021 at 5:53 PM, Orphée said:If you mean "stuck with DS3615xs loader because of missing CPU feature", yes, it seems ! 😅
Sadly Intel artificially limited that with efuses... like ECC on i5 and i7 and many other things.
On 10/6/2021 at 6:01 PM, abesus said:I already have locally updated sources for 918+ v 7.0.1 with support for extensions. The problem is, that TTG's extensions also needs to be updated to support 7.0.1 or someone has to fork them and modify...
edit: so I've decided to wait for official support for 7.0.1. Until that I will stay on my current 7.0.1. Good for me that it is stable
Extensions itself don't depend on the software version per-se. You can make an extension compatible with yet-unreleased version as during installation we query for the version which is being built and we don't care where the extension or version is coming from. The power of open-source.
On 10/6/2021 at 8:35 PM, WiteWulf said:I assume they used threads as opposed to cores in the table to cover hyperthreading CPUs. As I'm provisioning vCPUs in ESXi it makes no difference. I've assigned 8 cores/1 socket and it's making use of all 8 "CPUs" for Plex transcoding.
Now I wonder where we're at with hardware transcoding for Plex? I've never bothered looking into it before as my main hardware (HP Gen8) isn't capable...
Really the best HW transcoding with H265 support is an nVidia GPU. Something cheap and easy to get like P400. However, syno doesn't ship drivers for nV on systems other than their "AI" powered boxes for cameras.
On 10/6/2021 at 9:35 PM, scoobdriver said:LOL not sure what your use case is .. most my devices direct play content, so I very rarely need to transcode (...)
Great usecase for transcoding: watching movies on Oculus Quest in bed
Also, cheap streaming sticks often freeze or reboot on higher quality local rips of BRs. Some SDR TVs also reallllllyy don't like HDR content.
On 10/7/2021 at 12:21 AM, naoki66 said:#] Creating loader image at /opt/redpill-load/images/redpill-DS918+_7.0.1-42218_b1633537118.img... [ERR]
[!] Failed to copy /opt/redpill-load/build/1633537118/custom.gz to /opt/redpill-load/build/1633537118/img-mnt/part-1/custom.gz/usr/bin/cp: error writing '/opt/redpill-load/build/1633537118/img-mnt/part-1/custom.gz': No space left on device
It prompts that the disk space is not enough, do I need to modify the size of the boot file?You probably installed too many drivers or found a bug causing a loop somewhere. You shouldn't really go above the space allocated (~50MB) as this is plenty for drivers you need on a single platform.
On 10/7/2021 at 5:05 AM, psychoboi32 said:Thanks, It solved my issue
Jun's loader modify the values if we remember correctly. In general, we just pass them to the kernel as-is. There's a validation in the kernel itself but we don't do a validation during image build due to painfuliness of coding such things in bash.
In such cases just look at dmesg output when RP loads - it will say exactly what went wrong.21 hours ago, WiteWulf said:Is it assuming the first disk is synoboot, so not showing it?
The stupid thing is it should NOT be. Synoboot never appear as sda, it just looks like there's a bug in the syno code and despite them taking a different symbol (i.e. synoboot and not sdX) the counter for "used" letters is still incremented and not affected by their mapping. We need to find a good place to plug into that and fix it.
20 hours ago, pocopico said:I'm not very sure that DiskIdxMap is taken consideration, i need to further test. But in your case it makes sence to use something like
SataPortMap=<number of disks in controller 1><number of disks in controller 2><number of disks in controller 3>
e.g.
SataPortMap=188
It is used but doesn't always work as it should. You guys can also try playing with "sata_remap" or "ahci_remap" options. Their syntax is like: ahci_remap="0>16:16>0:1>17:17>1" and continues. Syno uses this a lot to rearrange ports. Don't forget about the "..." around that map. In JSON you have to escape it like \"
20 hours ago, pocopico said:Jun used a sata_remap variable to remap the disk numbering which does not exist in RP.
Found this : https://gugucomputing.wordpress.com/2018/11/11/experiment-on-sata_args-in-grub-cfg/
Yup, exactly what we wrote above
This isn't really RPs variable. These are remaps in the syno kernel. All of these "magic" options are defined in kernel/syno_bootargs.c and quite easy to understand.
16 hours ago, psychoboi32 said:Hello guys, with the help of @Orphée and @Comic Chang's repo , @pocopico driver I wrote a script which gives you Redpill image please change VID/PID/Mac/Serial no. accordingly
I tried in Linux VM
GUIDE:-
```nano takeredpill.sh```
add your PID/VID/MAC/SN in the beginning of the script
```chmod +x takeredpill.sh```
```sh takeredpill.sh````output folder have image
** this is early stage may be error happen don't worry please ping me
Sorry to be blunt but what you're doing in this script is very stupid (in a sense of code, not you as the author :)) and dangerous.
You're adding compilation options which we're almost sure you have no idea about. You've got an error with the new GCC about the PIE relocation/ASLR so you just changed the makefile for the LKM to use -fno-pie... sure, go for it! That's definitely why that error was stopping the build process so that -fno-pie can be simply added to the build line (/s).
We're strongly recommending a read of a post we put on page 55 which discusses some of the GCC stuff (which was discussed many times in this thread before). GCC isn't like Python or V8 - the version REALLY matters. Linux v3 will not build with >=5 for example. There are good reasons why kernel developers are extremely careful and have patches applied per GCC version in the code. The fact some code compiles is just at best 50% of the success with GCC.
Additionally, you're going against everything we recommended here. Really, this script is a collection of all "what not to do" we warned against in this thread:
- don't compile LKM or kernel bootstrap with GCC >4.9.2 (yet the script just YOLOs it)
- don't install random drivers loading 101 unneeded ones (and that's why we developed the extensions at all, but the script just adds a collection of drivers even if most people don't need them)
- configure user_config for yourself which you gonna keep for long time and which is semantically valid (yet the script just obliterates it with sed, not even a jq which was installed)
- read the docs & configurable options in commands (yet the script just does a forceful "mv" instead just using an option already provided for that)
- and as a desert: it will fail if your path has spaces in it.
To not be just grumpy and complain we will make a suggestion: utilize a docker image by @haydibe which works great and does things safely. It soon will be merged into the main repository as well.
Obviously, as the project is open-source and on top of that a full-blown GNU, we cannot stop you from using it. However trust us on that: we collectively wasted long weeks on dealing with pesky bugs where things weren't compiled exactly right and in a proper environment.
12 hours ago, scoobdriver said:Just a quick to those that have already got their LSI cards working on either baremetal os ESXi .
Happy to experiment , but if someone can save me the time
Do I also need to load mpt2sas extension for my card , if I have already added sas activator ext ? I was under the impression 3615XS already had this .ko that would be loaded ?
TTG quote "
A quick update (we will write more tomorrow): the native mpt2sas driver works but it's present only on 3615xs platform. To activate it and make it working properly without any hacks just add this small extension: https://github.com/RedPill-TTG/redpill-sas-activator
We also updated the kernel module to rewrite SAS => SATA ports so it should work with any off-the-shelf mpt2sas or mpt3sas driver."
Should I be adding supportsas="yes" to my synoinfo ? or is this not required as the kernel rewrites SATA -> SATA ?
See sad update on the top. Also, you should NOT use supportsas=yes as it does WAY more than just "adding SAS support". There are even more things associated with it (e.g. SASModel kernel boot option, which you shouldn't use either ;)).
12 hours ago, pigr8 said:mpt2sas.ko is already present on the ds3615xs, with the latest redpill there is a patch to fix names so you can use that .ko simply using supportsas=yes (this activates the load of that .ko on boot).
sas-activator just loads the same .ko without the need of supportsas=yes, it autodetects the LSI if present and load the correct .ko accordingly.
using the latest redpill with the patch probably breaks something in that .ko, so you could use the mpt2sas ext from @pocopico that is compiled in v14 (stock is v20) and does not have that break.
from my testing, you should test also and report.
We said that before but as a reminder if someone missed: don't add supportsas=yes. This doesn't do what it says it does sadly.
6 hours ago, fly said:I need a help on synoinfo.conf file in /etc/ and /etc.defaults folder.
after editing and saving the synoinfo.conf file in both dir and reboot the files were back in originele version does anyone know how that come? i need to change some parts there for testing but got no luck because it restore back to originel file 🙄.
with jun loader its works perfect by the way. i dont know if synology checks after reboot the files or somehow they are not letting to edit the file.
i am editing them as root and it saves it also even after few hours it shows ok without rebooting but to apply changes i must reboot.
Don't edit these files manually. You can set any options in these files by adding "synoinfo" section to your user_conf. There's an example in the repo. Any options you set will take priority over default ones. The automatic code takes care about figuring out which options to remove/add/modify and to do it in 4 different files across 2 environments.
57 minutes ago, karius said:make[1]: Leaving directory '/root/DS3615xs/bromolow/usr/local/x86_64-pc-linux-gnu/x86_64-pc-linux-gnu/sys-root/usr/lib/modules/DSM-7.0/build'
takeredpill.sh: 29: Syntax error: redirection unexpected
Hello
The above error occurs when running on ubuntu. Is there a solution?You should not use that script at all. Use the container recipes provided here by haybide.
-
5
-
Just now, pocopico said:
Please bear in mind that this will only work on DS3615 and not on 918. The 918 requires additional modules to be loaded prior loading any SAS modules otherwise you will fail to satisfy their dependencies.
/\ Yes, that definitely - as 3615xs has syno-built SAS modules the activator will install on 3615xs only (and the extension intentionally doesn't have a recipe for 918). However, with the LKM changes a standard unmodified mpt code should work properly.
-
1
-
-
A quick update (we will write more tomorrow): the native mpt2sas driver works but it's present only on 3615xs platform. To activate it and make it working properly without any hacks just add this small extension: https://github.com/RedPill-TTG/redpill-sas-activator
We also updated the kernel module to rewrite SAS => SATA ports so it should work with any off-the-shelf mpt2sas or mpt3sas driver.
-
7
-
1
-
-
Quick update:
Thanks to amazing reports from @WiteWulf the KP on 3615xs should be fixed now. For details see https://github.com/RedPill-TTG/redpill-lkm/issues/21#issuecomment-932690817
A different hard loockup seems to exist still but this shouldn't affect most of the people and judging by the last post in the issue it may not even be a bug but an over-reactive kernel protection mechanism.
====================================On 10/1/2021 at 2:54 PM, use-nas said:Is it possible to use IntelCPU Microcode ??
We don't see a reason why not. The kernel should load it automatically. We never played with microcode updates manually but DSM isn't special here.
On 10/1/2021 at 3:15 PM, coint_cho said:Was hoping for an answer to whether there’s any workarounds for old hardware, but since no harm in bumping, would like to ask ThorGroup if this is bypassable :D, disks work in 6.1.7 MBR modified by Genysys but not other images sadly.
Do you have two images where one is working on Q6600 and one is not? One of our devs may even have Q6600 on P5B Deluxe somewhere but it's a very old platform and we don't know if it still works after so many years
On 10/1/2021 at 3:27 PM, Orphée said:You really should give it a try.
It is rock stable, great UI, nice mobile app. nice motion detection features working just fine. can record on disk, send mails / SMS (with 3rd party service) alerts...
But only 2 camera in the free default license.
You must have a real SN/MAC to buy new license(s) on Amazon... There are quite expensive... and I think it is a bit risky, never know if one day Syno detect wrong device even with real SN/MAC... It then may break the licences bought earlier... (there is a Surveillance station c****ed floating around to enable 40 licences... but only for DSM 6.x)
With DVA3221 support, you give advanced IA features, 8 camera with default integrated licence... I'm really really waiting you on this 😚

That sounds REALLY good actually! We may try for a test installation observing 3D printers. We wonder how they actually detect what's a real S/N<=>MAC combo and what's not. We doubt it's calling to the outside API... because if it's that simple adding an emulation is probably pretty trivial. It's probably more a checksum than anything.
The DVA support is really held mostly by the S/N generation. Despite our efforts of searching around we weren't able to find how previous S/N generators were written (i.e. based on what information).
On 10/1/2021 at 4:01 PM, WowaDriver said:Sorry and its offtopic here, but do you tested the old c****** SSS package which the guys used on 6.2.3 with you restart task on DSM7? I think it could be possible to use, because it is a manuel installed package. So you should deinstall the standard SSS on DSM7 and give a try for the c****** one... In the past i tried it up with 6.2.3 it it worked perfectly for my with 9 cams.
I prefere SSS because you have the ability to use livecam, which is a kind of webcam recorder for you ios and ipados devices. So here i have to iPads in my house from which i can use the front cam for recording
FYI: no packages from v6 will really work on v7 without modification. They changed a lot, actually modernizing the package manager. Even simple things like Plex needed a new package for v7.
On 10/1/2021 at 4:45 PM, Orphée said:Yep, on Gen10+ you have to buy the daughter board, and buy the license somewere (Ebay & co...)
A real-life DLC.... the thing is what's the point of paying for a SERVER if you don't have any OOB management? That's probably why they release Gen10+ so quickly after Gen10 as people were still buying Gen 8.
On 10/2/2021 at 1:49 AM, T-REX-XP said:Also it seems to be the following repo should contains all available extensions in feature - https://github.com/RedPill-TTG/redpill-extensions. Like a marketplace or repository with a links. So it will be enough to define available extensions unique name inside extensions section in the config.
"extensions": [ "thethorgroup.virtio", "example_dev.example_extension" ]Yes, the final goal is to have the default be just the "dev.ext_name" installation but with always-available option to use manual URL. The repo has a simple format for now as we don't have a plan HOW it will be structured. However, we are definitely want to keep everything static to avoid having any active servers (more like apt/dpkg and unlike NPM).
Currently, the extension names are only mean to force the order of loading. 99% of the users will never use that key. We're currently messaging with @haydibe to see how to make extensions interface nice with containers.On 10/2/2021 at 6:10 AM, plarkass said:Att the end of the installation
1) Enable SSH and ssh into your DiskStation
2) Become root ( sudo -i )
3) Make a mount point ( mkdir -p /tmp/mountMe )
4) cd into /dev ( cd /dev )
5) mount synoboot1 to your mount point ( mount -t vfat synoboot1 /tmp/mountMe )
6) modify grub
7) Profit!
Remember that this method will RESET this setting when you update RP in the future. That's why we say to add this to the user_conf
For testing it's easier to press "e" in the GRUB menu to edit the entry, add params which you want to test, and then press Ctrl+x to boot modified entry.
10 hours ago, AnhLai said:Hi any one got issue that not all ram are usable? I have 8GB installed, but only 4GB usable
Are you sure you don't have some compatibility mode set in the BIOS? As 32bit has a limit to 4GB and there were hacks to extend that for OSes like Windows XP.
Look under things like "PAE", "Physical Address Extension" or a selector for OS type (some BIOSes have selector like DOS/Legacy/Other - usually picking Other disables all magic wizardy hacks).
10 hours ago, RedwinX said:Yeah sure, if I read and understand, have to make diskidxmap=0C00 (13th disk is redpill vmdk, and 1th for sas card) and SATAPORTMAP=18 (1 port for redpill and 8 for sas) but always only 7 disk of 8 on sas card
RP does not need [or shouldn't] the Jun's hack to "hide" the loader as the 13th disk as we set synoboot in kernel and that disk is never visible to the DSM UI. So calculate everything as if that disk was never there. Your first disk can certainly land at "/dev/sda" (in Jun's loader some platforms could never use sda but started from sdb).
8 hours ago, pigr8 said:OORRR..
one could move the redpill not on a sata controller but on a sas controller, let it boot from there and that gives the LSI the ability to set the drive as /dev/sda.
done.
but i dont know if it's supported by TTG doing this way

EDIT: nope, doing so no /dev/synoboot is created so install will fail @55%, if the system is installed it will boot fine but no clean install.
Depending on the platform the boot from SAS should work (typing from memory here). In general, we try to be pretty flexible as to what "SATA boot" is and make it "anything SCSI matching the size except USB".
7 hours ago, Orphée said:@pigr8 If you look my earlier posts, I faced the same issue with HBA LSI card, can't set it to /dev/sda. It seems DiskIdxMap is ignored. Whereas same conf with virtual SATA1 controller works.
and 2 posts after.
If you're running 3615xs there's also SasIdxMap
7 hours ago, ct85msi said:Offtopic, there were some questions why someone would want 10 Gbps networking...well Digi ISP (RCA-RDS) Romania announced new subscriptions for 10 and 2.5 GBps. 10 Gbps costs 10.11 EUR/11.72 USD(50 RON) and 2.5 Gbps costs 9.10 EUR/10.55 USD (45 RON). That is for FTTH , fiber to the home, no need for business subscription. So...I guess 10 Gbps is the new standard, or ar least 2.5 Gbps.
We need to push 10 Gbps cards compatibility.
<frantically checking housing prices in Romania>
5 hours ago, nemesis122 said:The best is in switzerland you can download nearly everything only russia is better there you can download and upload nearly everything🤣
Correction: you can do pretty much what you want on the internet from RU as long as you do it to countries which aren't Russia. Not getting political but there's a reason why a lot C&C servers for malware are ran in Russia.
4 hours ago, paro44 said:I use Win32DiskImager for writing .img-file to USB-drive. Easy to use, the drive is bootable.
The Gen8 has no Intel network card, right? Try it with an Intel card.
Gen8 has a broadcomm card. The driver, if someone compiles it, should work.
3 hours ago, buggy25200 said:Hello,
On virtualbox and DS918+ 7 and 7.1, I boot with no link up, it seems virtio has no effect on kernel > 4 and virtualbox, but it works on proxmox ! did you have this same observation ?
So I have tried using module made by @pocopicoe1000, and it works great ! Thx to you.
I also tried, your e1000 module 3.10.108 with ds3615xs, I do not know why ! Just I can ... so ... But it causes kernel panic on every boot.
I therefore allow myself to warn testers : be careful and try modules one by one to find the one that works and the one that doesn't, some modules will pose problem.
The KP should be fixed for the most part on 3615xs - see GH issue for details: https://github.com/RedPill-TTG/redpill-lkm/issues/21#issuecomment-932690817
As for the ethernet use VirtIO if you can [i.e. not on VMWare] as it's a paravirtualized interface [=low overhead/faster] and e1000e otherwise (doesn't need drivers). e1000 is a different card.-
1
-
3
-
-
3 minutes ago, shibby said:
Do someone have a luck with NVMe drive on DSM7.x? On 6.2.3 i used this "solution"
On 7.0.1 it wont work. Any modification of libsynonvme.so.1 file is ending on reinstalation DSM (detect as migratable system). Only M.2 Sata drives works.
Or maybe this is too early to talk about NVMe?
Look at the last post - somebody found a solution. It's just they hardcoded PCI ids for these
We never looked at NVMe cache ourselves but if needed something can probably be done in the kernel to make it work. Depending on how their library works (i.e. does it just check for these devices and use /dev or actually use PCI commands directly [probably not]) we can maybe just fake them.
-
1
-
-
15 hours ago, Amoureux said:
Extract drivers from jun's extra.lzma and use them?
Even if you forcefully insert them that's a bad idea - you can yolo things in user space but not in the kernel as userspace is guarded by the kernel and kernel is only guarded by a sparse memory managemnt unit checks
The kernel space has literally no memory protection per se (ok, there are small bits here and there but this is mostly bug-catching and not protection between drivers due to performance reasons). It's a PITA that kernel modules in Linux are specific to that exact version up to the t but that's a small price to pay for a great kernel. That decision was famously made in 1991 (if someone's interested google for Linux vs Minix and now-legendary exchange between Linus T and Minix author - it could be a hollywood movie).
This is why RedPill extensions system is VERY specific to the versions of modules so nobody accidentally even try loading wrong driver's version as this is much more dangerous on Linux than on Windows or macOS. Drivers on Linux are literally running on the same privilege level as the kernel itself. On macOS more and more are in userspace or are at least partially isolated. This is why nobody should experiment with e.g. SAS drivers on a drive with data which they care about [unless tested by many and confirmed working properly].
-
2
-
-
Rest of the answers starting from beginning of page 84 and ending on page 86.
========================================================================
On 9/29/2021 at 9:58 AM, flybird08 said:IG-88 said that the DS918 kernel has the capability of SAS module. But there is no actual measurement on my side. Maybe Jun's loader does extra work?
In addition, the SATA/AHCI controller may be a better choice on the DS918 before SAS can run perfectly. If you can compile ahci.ko, I will do more tests on SATA/AHCI controller. I also have a JMB585 controller.
We will love to be wrong here but to our knowledge 918+ kernel does not have SAS functionality. These symbols are present in the kernel code but guarded by "ifdef MY_ABC_HERE" which presumably depends on the model/SAS support option.
Eh... it is possible to emulate that. We know how technically. We can provide these symbols virtually in RP but it will require some digging to check what they should return. Since we don't care about REAL SAS support (as syno-supplied controllers have a custom firmware anyway) we can just shim them.
However, we see some success from @pocopico and @Orphée here so we will... wait for an extension maybe?
On 9/29/2021 at 3:48 PM, flybird08 said:@pocopicoI compiled the module of Jmicron jmb585 myself and encountered the same problem. Maybe Synology really changed the driver code. But I don't know how to make it work.☹️
THAT WE CAN FIX!
We can add that symbol if needed. We saw Jun replacing that symbol but we had no idea why. Famous last words: that should be easy.
On 9/29/2021 at 4:06 PM, Orphée said:Wow, did you guys see the list of "removed" things with DSM 7 ?
https://www.synology.com/en-global/releaseNote/DSM?model=DS3615xs
Be warned and take care of your settings before upgrade to DSM7...
36xx is rocky with v7 overall. We've lost two pools on a real DS - a complete ext4 crash. Surprisingly btrfs is more stable this time, but someone reported here data loss with btrfs as well.
However, there's a shell hack to forcefully just load USB device kernel modules. It's just they're through with supporting that probably.On 9/29/2021 at 4:37 PM, Aigor said:About Drivers, correct me if I'm wrong
There are basically "two types of drivers" one type is mandatory to install into some hardware, and others available after installation to support, for example, 10Gbit card and so on.
To make loader you need ONLY drivers that is suitable for booting and installing, for example, SaS controller, SATA, network card, usb, exotic chipset, so, i think, reduce the amount of them needed to boot and install, these are mandatory to have new system installed and, but i don't know, can be packed into loader for installing only, after, we can use spk via spksrc to pack needed drivers to support exotic hardware for example Fibre Channel cards ( my old project ) exotic network card and so on.
What do you think about it?
I wrote a pile of bullshit?
Yes, you are correct. We were thinking about that as well but decided against dividing drivers. There's no harm in loading all of them in pre-boot. On some of our servers (unrelated to DSM) we have 10Gb/s networking in initramfs to boot from them. We couldn't find an argument for splitting drivers to core and non-core besides size. Since loading a ramdisk layer seem to work up to ~430MB we don't think we will hit that limit any time soon.
We don't copy modules like Jun did - we just load them from memory to different memory. You don't need to unload and reload them on runtime. On hot-plug systems you may do that but syno doesn't do that themselves either and essentially loads drivers based on configs in preboot.On 9/29/2021 at 4:43 PM, pocopico said:If you extract the kernel with the extract script you find inside the redpill-loader you can extract the symbols. These libata symbols do not exist on 918. So in other words if we even get the sources we are out of luck forsome devices. I think that baremetal whitout matcing the official hardware is getting harder.So thats what happens when you are mixing synology compiled modules with standard kernel drivers. Modules are reffering to symbols that do not exist. This is what i've tried and seems to get the modules to load succesfully. Download the mpt3sas.ko from the repo again.
insmod scsi_transport_sas.ko
insmod libsas.ko
insmod raid_class.ko
insmod mpt3sas.kolsmod |grep -i mpt
mpt3sas 194218 0
raid_class 3508 1 mpt3sas
scsi_transport_sas 23996 2 mpt3sas,libsas
If the .ko is shipped within the PAT go for it and load it - at least we know it's compilled properly. It may still have missing symbols but see beginning of this post.
On 9/29/2021 at 4:43 PM, WiteWulf said:@Orphée Yeah, I imagine that's going to be a problem for lots of people. You running Domoticz/Home Assistant for IoT?
...and this is exactly why we run a Proxmox. A VM for DSM + a VM for stuff like HA, NUT, or Avahi. Trying to put it on a NAS is already tricky but I'm sure it will piss off a lot of real DS users as for most the NAS is their only server.
On 9/29/2021 at 6:26 PM, WiteWulf said:This is a known limitation. Booting from USB3.0 is not possible at this time.
Teeechincaaaaally speaking as long as the NUC is able to BOOT from the USB3.0 the RP shouldn't have a problem interacting with it as it loads all drivers, including USB3. The only issue may be the driver for the controller itself - if it's not supported by the native Linux xHCI driver you will need to add it as an extension.
On 9/29/2021 at 7:04 PM, Kaneske said:Since it seems to be „quite“ stable and also usable by many, and it’s already on 7.01 on the Syno Side…
…is there a way to post a to-do by step, or a summary, what and when to act for getting this incredible cool new loader done?
It seems hard for me to get things together.
THX
See the roadmap
[few posts from this account back]
We want to fix the SAS thing [which as we see guys are already figuring out here] and integrate container build into the load repo - then an instruction will be posted. We also want to solve that annoying crash/lockup issue with 3615xs as we cannot call it stable or even beta if every database crashes it within minutes-hours.
14 hours ago, WiteWulf said:@ThorGroup hey guys, sorry to '@' you on this, I know you're busy people, but I wonder if you'd been able to look at the kernel panic problems on DS3615xs? My system is now stable, but only with no docker containers running and Plex Media Server stopped. Starting PMS or a docker container results in a kernel panic anywhere between a few seconds or two to three minutes later. I'm happy to carry out any testing you suggest and feedback diagnostic output.
Yes, we're trying - the biggest issue, which is slightly funny, is that we have hard time reliably crashing it.
12 hours ago, pigr8 said:what about the 4 letter /dev/sdXXn? didnt thorgroup say that is not supported? i have a LSISAS2008 too, gonna try tomorrow and see if it works.
That isn't a problem - you just need to set SataDisk... params properly to move disks and it will fix itself.
See: https://xpenology.com/forum/topic/44285-proxmox-hba-passthrough-second-virtual-controller-not-detected/?do=findComment&comment=2043521 hour ago, shibby said:that`s true, but when we don`t know what is correct value for our bare metal, then this is the easiest way for testing. And another thing, we can compile RP for other users (who cannot compile RP himself) and they have to only modify grub.cfg for his configuration (vid, pid, mac, sataportmap). We did this in previous loader by Jun, so community know how to do this without any broke
With all due respect: looking at this thread we see many people don't know what to edit and what to put (e.g. randomly stuffing sata_pcislot or doing replacements of hwmon configuration parameters). Doing a quick "e" in grub and adding something which YOU know what it does is obviously something we do as well, however advising people to open images and edit grub.cfg isn't wise. A prime example are disk/controllers settings: you can spend days trying random values found all over the forum OR spend 15-20 minutes understanding what these values do and configure them per your system. Many people don't realize some values are specific to their own config.
Additional issue, which we repeated multiple times here, is sharing the loader image. It's a VERY bad idea. Read the first post in this thread: we didn't start RP. The original thread is gone, original repos are gone, ... there's a reason for that and it's not one you want to step into. Trust us on that: sharing precompiled images is a very bad idea. The kernel and modules are open source and under GPL - you can do literally whatever you want with them. However, the final image contains proprietary syno modules and their userland tools which are as far from open source as possible. Connect the dots here why we say to not share the full image and went into a huge effort of creating tools to build the image. It would be much easier to drop an .img or .vmdk and call it a day but the times changed.
========================================================================
Yay! We're done - it took some time Now we need to think about a great PM from @haydibe ^^
-
6
-
6
-
-
This post contains answers to questions up to beginning of page 84.
============================================================================
On 9/17/2021 at 8:55 PM, Orphée said:What does this container actually ?
appart from freezing my VM and running CPU at 100% ?
?
2 tries, 2nd one with high privileges
had to reset system
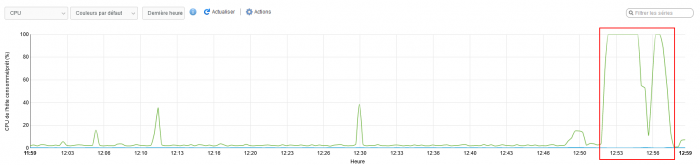
It's a holy grail to catch WHAT is actually causing that 100% spike when it happens. This is the clue of where the spinlock is taken but not released. Kernel points at influxdb and other DBs but we're sure it's not that. It's somewhere in the kernel itself.
On 9/17/2021 at 10:02 PM, gldl said:After each restart, the BIOS time is not accurate. 8 hours slower than the system time. What's the reason
This is perfectly correct. Windows uses local time in RTC and Linux uses UTC. The behavior of windows dates back to the MSDOS days. Linux actually follows ACPI specs. This is normal to see when you run any Linux on a PC as ancient RTC spec has no way of setting timezone. Just a small quirk - if you're not dualbooting windows you can just ignore that.
On 9/17/2021 at 10:11 PM, WiteWulf said:@Orphée @nemesis122 @pocopico @erkify @dodo-dk
You've all said you're seeing docker-related crashes on your systems. Some of you are on baremetal, some using proxmox or ESXi. Can you please confirm whether you are running 3615xs or 918 images?
The trend (as spotted by abesus) seems to be that 3615xs setups are crashing while 918 are not.
Please confirm and I'll log an issue on the redpill-lkm GitHub repo. It would also be handy to know exactly what CPU you have in your machines.
(Some other people also mentioned they're seeing docker-related crashes, but I know they're on either HP Gen8 or Gen7 baremetal, so I know they're using ds3615xs images)
That is a very important clue - it may be something related to vUART driver we wrote as it uses a LOT of spinlocks.
On 9/17/2021 at 10:15 PM, rdidier75 said:Hello,
I am on DS918+ Apollolake 7.01 (J3455-ITX - ASRock, with 8 drives) thanks to you !
Everything works perfectly expect poweron :

and no access to this tab :

Is it the same for you ?
Thanks.
Do you mean auto power on? This feature is not supported - we didn't emulate it. Do you rely on it? Do you use it? We can add it - as we explained in one of the updates we didn't bother adding it as it isn't easy and it's broken on many motherboards anyway.
If you will like to see that feature added please open issue on GitHub in the redpill-lkm repository.On 9/18/2021 at 1:51 AM, havast said:Here the working loader in VMDK format. I hope the masters will do a 3617xs version, i have a real sn / mac pair for that NAS. (I have a few real 918+ sn / mac pair too, but unfortunatelly my CPU is too old for that 😕
Hope i can find a soultion. I think its impossible to get a real 3615xs sn and mac
Please don't share the final image. Especially if the link points to any of your servers - the final image contains copyrighted material and may get you into troubles. We (and @WiteWulf below) explained it few times here already.
As for the 3617xs see the "mysteries.md" file in dsm-research repo on our GH - we aren't actively working on it right now for reasons described there. We probably come back to it when we have some spare time.On 9/18/2021 at 9:37 PM, haydibe said:Ah okay. Forget that I ever mention my observation regarding Ryzen cpus and old kernels
Ryzens + v3.10 is usually fixable by injecting newer microcode
But running a full ryzen bare metal with 3515xs.... why, just why?
On 9/20/2021 at 3:38 AM, WiteWulf said:If so it's not hanging, it's just there's no more output to the screen from that point as there's no frame buffer driver in the Synology kernel. Jun's bootloader used to put a message on screen to this effect, something that would be quite helpful in redpill, too, I think.
(...)
That's a good addition actually - it's simple to add that in GRUB
Can you add an issue in the redpill-load repo maybe?
On 9/20/2021 at 12:36 PM, datahunter said:RedPill is a great project !! I love it.
I think i hit a bug on the kernel module or dsm
Issure:
I running DS3615xs/6.2.4-25556 on Debian 10 with Qemu
The VM instance 's NIC has abnormal traffic.
Any materials i need to provide for debug ?
That isn't actually related to RP - you need to see on your router where the traffic is going, or try tcpdump on DSM itself to see where it sends/receives data.
On 9/20/2021 at 8:45 PM, Buny74 said:Hi guys,
I'm actually on baremetal with my G8 and i plan to update to DSM 7.0.1 but i'm actually on a 3617 base.
If i build for a 3615 will it be possible to update my server from a 3617 ?
Thanks
Yes, when we add 3617xs support you can just upgrade in-place. It will work like moving disks from one DS to another.
On 9/20/2021 at 9:01 PM, toyanucci said:The initial boot takes 10 minutes to load the kernel or does every boot take 10 minutes?
Boot shouldn't take that long - it should take under a minute really.
On 9/21/2021 at 5:15 AM, dodo-dk said:you can try to switch the cpu setting in Proxmox from kvm64 to haswell or something.
kvm64 don‘t work with facedetection on some systems.
kvm64 has many instructions disabled. Ideally when you can you should use host every time for any VM (no matter what it is in general if you're running something modern).
On 9/21/2021 at 4:17 PM, Orphée said:Did someone successfully updated from 6.2.4 to 6.2.4 update 2 ?
when I tried a week or two ago, update failed for me...
Edit :
Inside the update 2 PAT file, there is a flashupdate_6.2-25556-s2_all.deb
it contains :
We didn't look into that update but most likely just the flash updater has to be blocked overall (we blocked it based on other things but we didn't see an actual PAT to test it). Running it may just crash the machine.
On 9/21/2021 at 7:23 PM, Orphée said:You then have no SMART support inside DSM.
Whereas HBA passtrough (on 6.2.3) makes SMART work inside DSM. So real DSM monitoring in case a disk dies.
This is a great point actually. Even VMWare discourages from passing disks itself (and SMART is just one of many issues with passing a disk). Passing disks is bad on any hypervisor we saw as SMART is not proxied. It could be but there are security issues with that so no hypervisor does that.
On 9/21/2021 at 8:01 PM, nemesis122 said:my config looks like this but
{
"extra_cmdline": {
"pid": "0x0001",
"vid": "0x46f4",
"sn": "1330LWNXXXXXX",
"mac1": "001132XXXXXX",
"DiskIdxMap": "1000",
"SataPortMap": "4",
},
"synoinfo": {
"supportsystemperature": "no",
"supportsystempwarning": "no"
},
"ramdisk_copy": {}
}i need to add the second Networkdapater
mac 2 and netif2 are there some other parameters as we have a list ?
is this correct like this :
{
"extra_cmdline": {
"pid": "0x0001",
"vid": "0x46f4",
"sn": "1330LWNXXXXXX",
"mac1": "001132XXXXXX","mac2": "001133XXXXXX",
"netif_num": "2",
"DiskIdxMap": "1000",
"SataPortMap": "4",
},
"synoinfo": {
"supportsystemperature": "no",
"supportsystempwarning": "no"
},
"ramdisk_copy": {}
}thank you
Please, REMOVE supportsystemtemperature & supportsystemwarning. Actually to properly do that (since using that hack you actually damaged your OS) you should change them to "yes", boot once, and then remove them from your config.
On 9/22/2021 at 1:09 AM, stefauresi said:My internet connection = 8G
Switch mikrotik SFP+ 10G / with RJ45 ethernet moduleYes 10G it's necessary for me 😉
We are jealous ^^ Eastern Europe?
On 9/22/2021 at 1:24 AM, D.S said:I have experience on Aquantia (Qnap QXG-10G1T), I tried to put different version of driver (included compiled by myself) to the loader, but none of them is working. However, after installed DSM, just create a script and upload to "/usr/lib/modules-load.d/" then copy atlantic.ko to "/usr/lib/modules/", reboot and it will works. I attached the files if needed.
You can now pack it into an extension. Let us know in case of problems.
On 9/22/2021 at 2:31 PM, nemesis122 said:I have this Networkadapter Intel® Ethernet-Converged-Network-Adapter X520-DA2 please help me to add this driver to DSM 918+ Redpill Loader
How can i add this driver to the image or to the maschine ?
thank you
You can now use an extension and RP will load it automatically on boot.
On 9/22/2021 at 6:53 PM, pocopico said:while in ssh with root run
# depmod -a
# modprobe atlantic
verify module is loaded with
# lsmod |grep -i atlantic
If it didn't load do a
# insmod /usr/lib/modules/atlantic.ko and verify again.
If it doesnt load check dmesg output to see whats wrong
Syno doesn't have depmod and use forceful/static insmod rather than intelligent modprobe.
On 9/22/2021 at 9:21 PM, Lazy775 said:Hey, just compiled (and tried like, every redist online) RedPill and I'm stuck on 'starting kernel'.
This is the full output:
I get 0 output from serial port (I may have wired them incorrectly because I shoved a male connector to my board (also male)'s serial connector)
Is it like, BIOS specific setting in place or smtg?
*spec
LSI 9280-8i
Asrock J4105
Problem persists with and without HDD
Whoever made that.... has no idea about the loader. We're sorry for harsh words but you CANNOT - ABSOLUTELY CANNOT - SAY that a single bootable image supports "6.2.4 to 7.0.1". Each version requires a static kernel patch. You can boot with an incompatible kernel - sure - but this is a disaster and nobody should ever do that. Never ever.
On 9/22/2021 at 11:05 PM, nemesis122 said:Hi i have Asus 87iplus with 6 sata ports at the same controller when all hdd are connected i can install DSM 3615 redpill 7 but when not all HDD are connected i have the error message that 6 sata ports are disabled so i need the line in the grub.cfg sataports= 6 and i dont know exactly in which i have to write this line.
could you help me ?
menuentry 'RedPill DS3615xs v7.0.1-42214 RC (USB, Verbose)' {
savedefault
set root=(hd0,msdos1)
echo Loading Linux...
linux /zImage mac1=9C69Bxxxxxx netif_num=1 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=0 vid=0x0951 syno_hdd_detect=0 pid=0x1665 console=ttyS0,115200n8 elevator=elevator sn=14Bxxxxxxxxxxxx root=/dev/md0 earlyprintk loglevel=15 log_buf_len=32M syno_port_thaw=1 HddHotplug=0 withefi syno_hw_version=DS3615xs vender_format_version=2
echo Loading initramfs...
initrd /rd.gz
echo Starting kernel with USB boot
}You should NOT edit grub.cfg. If you want to change parameters you should use user_conf.json
On 9/23/2021 at 2:51 PM, jumkey said:Pseudocode for compression
final int SIGN_LENGTH = 64; // FIXME 可能是(4倍对齐 补00)的魔法值 final int MAGIC_LENGTH = 4; long length = filesize("rd.cpio"); cli>lzma -9 rd.cpio try (RandomAccessFile lzmaFile = new RandomAccessFile("rd.cpio.lzma", "rw")) { // add 00 and 64 byte 00 fake sign lzmaFile.setLength(((lzmaFile.length() + MAGIC_LENGTH - 1) / MAGIC_LENGTH) * MAGIC_LENGTH + SIGN_LENGTH); // rewrite lzma 8 byte uncompressed size from -1 to real size lzmaFile.seek(5); final ByteBuffer order = ByteBuffer.allocate(8).putLong(length).order(ByteOrder.LITTLE_ENDIAN); order.rewind(); lzmaFile.writeLong(order.getLong()); order.clear(); }
We love that!
We will definitely look at compressing images on v7 as it's annoying they're not.
On 9/23/2021 at 3:25 PM, helixzz said:Thanks, Piteball.
Really excited and can't wait to try out the new loader. I thought there is already some way to 'inject' driver file into the loader and DSM installer as well.
Then I will wait and also discover myself to see if I can help.
Now since the extensions are supported you can inject drivers
See the details in our last announcment post (scroll up - it should glow green as "popular").
On 9/23/2021 at 4:07 PM, dolbycat said:j4105 dsm7.0.1
During the power schedule function, auto power off works fine. But auto power on doesn't work.
As we wrote in the post above - the auto power on is not supported by design as we got frustrated that out of 6 motherboards we tested it worked only on one and only with max 2 scheduled events. If you rely on it we can add it - please add an issue to redpill-lkm repo. It will come with a disclaimer "it may not work" as auto-poweron on PCs is very finicky and we cannot do more than ask the BIOS (or rather the RTC chip) "pretty please set the schedule".
On 9/23/2021 at 7:00 PM, pocopico said:The rd.gz that exists on the loader + the zImage have to be the ones that are patched during the loader creation process. If you manually update using a pat file from Syno then you most probably will overwrite the rd.gz and zImage rendering your loader useless.
All the redpill magic happens in these two files. You need to put back the redpill patched ones and not the ones from the update2 pat.
Actually the update shouldn't override files on synoboot1 (as these are treate more like a ROM on real devices and serve as a backup boot in case the synoboot2 fails), but attempting to boot the kernel from version A with OS files from version B will not end well... ever.
On 9/23/2021 at 9:53 PM, WiteWulf said:Since moving to the latest redpill code (3474d9b) I'm finding my system less stable than it was before with respect to docker containers. My influxdb container would crash the system every time I started it, but the others I had were typically stable and non-problematic. I'm now seeing immediate kernel panics when starting a mysql container that previously didn't cause any problems.
I've gone back to a slightly older build (021ed51), and mysqld (operating as a database backend for librenms) starts and runs without problems.
This is sadly coincidental, as we didn't touch locks there
We're still debugging that. The most annoying thing is that it actually doesn't crash very reliably on our gen 8s. It does but rarely.
On 9/23/2021 at 10:33 PM, xPalito93 said:I started playing around with the redpill on two test rigs i have at work the last couple of days.
I have a HP AIO PC with a 6th gen I3 on it and two Sata drives.
I tried installing 918 on it on baremetal and everything works without any issues for now.
But today i started playing with ESXI 7.0 for the first time ever and i followed a tutorial posted a couple pages back.
It boots and i can find it on find.synology.com and it even detects two drives because it tells me it will erase the two drives connected.
But when i start the installation with the selected PAT file, it always stops at 56% and tells me the file is corrupt.
I tried creating the image with 0.9 and 0.10 and i tried DSM 7.0 & 7.0.1. I always get the same error.
Am i missing something? I never really worked with ESXI, i'm trying to learn as much as possible
The only thing i changed on the image is the Mac Address (i use a random mac adress like 123456abcdef) and i put the same address in the VM settings where you can select the network adapter. If i leave it on auto, it won't show up on the network.
PID and VID shouldn't matter right?
The other rig is an old fujitsu server which can only run 3615 but it won't detect any drives at all because of the LSI controller which is a known issue afaik.
You shouldn't use just any random MAC. There's many octets you can change but some have special meaning - just let ESXi (or whatever you use) generate it for you and put it in the user_conf. If you're just starting with virtualization we recommend Proxmox instead of ESXi for many reasons.
On 9/24/2021 at 1:04 AM, Aigor said:A question, when "official release" will be available, we should to make a new bootloader every time when a update will be available?
TECHNICALLY yes, but in practice we want to make it in-place. So you just run a docker command on the DSM itself which will build everything and instead of spitting out the image it will just update the /dev/synoboot in-place. At which point you can just update from the DSM panel and reboot.
We didn't develop an auto-patching-on-boot as if you use any custom drivers you have to change them anyway and things get complicated quickly. Seeing as syno doesn't release updates very often (ok, maybe except broken v7 releases) it's not that big of a problem. Our priority is on stability (yes, we know how it sounds with the crashing 3615xs now but trust us ;)) rather than having a thread where users cry that they updated, rebooted and now the system is not working at all. That shouldn't be possible. In the hackintosh community it works similarly if you do everything right: you cannot accidentally update to an incompatible release.On 9/24/2021 at 4:34 PM, stefauresi said:Hi,
Question, Intel X520-DA1 driver is include ? (82599ES Chip)If i buy an Synology E10G18-T2 , this card is natively recognize ?
Best regard
Check what they did rebrand
Of course if you use their official NIC it will work but there are many cards which are just supported. The easiest way is to check which chipset their NICs use and find a generic from Intel/HP/Dell/etc. Sometimes Intel one will run you $150 but if you search by chipset you will find the same things branded with HP for $50. Like we have a lot of HP 360T deployed as they're solid Intel 2x1G NICs and are laughably cheap (like $15).
On 9/24/2021 at 11:49 PM, ghtester said:Thanks again, this module can be load but leads to crash so I suppose it was compiled with generic kernel 3.10.108 sources. I tried that as well (and none of modules I needed was working) but as already confirmed by @ThorGroup, this is not a proper way (although maybe some drivers can work).
insmod ata_piix/ata_piix.ko
Killed
[91701.976157] WARNING: module 'ata_piix' built without retpoline-enabled compiler, may affect Spectre v2 mitigation
[91701.987932] ata_piix 0000:00:1f.5: version 2.13
[91701.993164] ata_piix 0000:00:1f.5: MAP [
[91701.997551] P0 -- P1 -- ]
[91702.151055] BUG: unable to handle kernel NULL pointer dereference at 000000000000001b
[91702.152013] IP: [<ffffffffa0edfdc7>] piix_init_one+0x527/0x8dd [ata_piix]
[91702.152013] PGD 78e74067 PUD 977a2067 PMD 0
[91702.152013] Oops: 0000 [#1] SMP
[91702.152013] Modules linked in: ata_piix(F+) fuse 8021q vhost_scsi(O) vhost(O) tcm_loop(O) iscsi_target_mod(O) target_core_ep(O) target_core_multi_file(O) target_core_file(O) target_core_iblock(O) target_core_mod(O) syno_extent_pool(PO) rodsp_ep(O) evdev(OF) button(OF) udf isofs loop synoacl_vfs(PO) btrfs zstd_decompress ecryptfs zstd_compress xxhash xor raid6_pq zram(C) glue_helper lrw gf128mul ablk_helper bromolow_synobios(PO) hid_generic usbhid hid usblp bnx2x(O) mdio mlx5_core(O) mlx4_en(O) mlx4_core(O) mlx_compat(O) qede(O) qed(O) atlantic_v2(O) atlantic(O) tn40xx(O) i40e(O) ixgbe(O) be2net(O) i2c_algo_bit igb(O) dca e1000e(O) sg dm_snapshot crc_itu_t crc_ccitt psnap p8022 llc zlib_deflate libcrc32c hfsplus md4 hmac sit tunnel4 ipv6 flashcache_syno(O) flashcache(O) syno_flashcache_control(O)
[91702.190422] dm_mod cryptd arc4 sha256_generic sha1_generic ecb aes_x86_64 authenc des_generic ansi_cprng cts md5 cbc cpufreq_powersave cpufreq_performance acpi_cpufreq mperf processor thermal_sys cpufreq_stats freq_table vxlan ip_tunnel etxhci_hcd usb_storage xhci_hcd uhci_hcd ehci_pci ehci_hcd usbcore usb_common redpill(OF) [last unloaded: bromolow_synobios]
[91702.190422] CPU: 0 PID: 10438 Comm: insmod Tainted: PF C O 3.10.108 #42214
[91702.190422] Hardware name: HP ProLiant ML110 G5/ProLiant ML110 G5, BIOS O15 10/25/2010
[91702.190422] task: ffff88009b585040 ti: ffff880071020000 task.ti: ffff880071020000
[91702.190422] RIP: 0010:[<ffffffffa0edfdc7>] [<ffffffffa0edfdc7>] piix_init_one+0x527/0x8dd [ata_piix]
[91702.190422] RSP: 0018:ffff880071023b98 EFLAGS: 00010206
[91702.190422] RAX: ffffffffa0ee26b0 RBX: ffff8800b9793000 RCX: ffff8800a8efea58
[91702.190422] RDX: ffffffffa0ee26b0 RSI: 0000000000000282 RDI: ffffffff819b7080
[91702.190422] RBP: 0000000000000000 R08: ffff880071020000 R09: 0020ee39e1f9050d
[91702.190422] R10: ffffffffffffffff R11: 0000000225c17d03 R12: 0000000030000002
[91702.190422] R13: ffff8800b9793098 R14: 0000000000000000 R15: ffff8800b9793098
[91702.190422] FS: 00007fcfc8b3b540(0000) GS:ffff8800bda00000(0000) knlGS:0000000000000000
[91702.190422] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
[91702.190422] CR2: 000000000000001b CR3: 0000000071e50000 CR4: 00000000000007f0
[91702.190422] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[91702.190422] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
[91702.190422] Stack:
[91702.190422] ffff880035e95358 ffffffffa0ee26a0 0000000000000000 00000003000000d0
[91702.190422] ffff020281121167 ffff8800a8efea58 ffff880071023bd8 ffff880071023c10
[91702.190422] 0000000030000002 0000000000000000 000000000000001f 0000000000000007
[91702.190422] Call Trace:
[91702.190422] [<ffffffff812b2f11>] ? pci_device_probe+0x71/0xb0
[91702.190422] [<ffffffff81326431>] ? driver_probe_device+0x81/0x3e0
[91702.190422] [<ffffffff8132684b>] ? __driver_attach+0x7b/0x80
[91702.190422] [<ffffffff813267d0>] ? __device_attach+0x40/0x40
[91702.190422] [<ffffffff8132458d>] ? bus_for_each_dev+0x5d/0x90
[91702.190422] [<ffffffff81325a68>] ? bus_add_driver+0x208/0x2a0
[91702.190422] [<ffffffffa0ee6000>] ? 0xffffffffa0ee5fff
[91702.190422] [<ffffffff81326e49>] ? driver_register+0x69/0x170
[91702.190422] [<ffffffffa0ee6000>] ? 0xffffffffa0ee5fff
[91702.190422] [<ffffffffa0ee601a>] ? piix_init+0x1a/0x29 [ata_piix]
[91702.190422] [<ffffffff810002ea>] ? do_one_initcall+0x2a/0x170
[91702.190422] [<ffffffff81095149>] ? load_module+0x1b89/0x2540
[91702.190422] [<ffffffff812a2cb0>] ? ddebug_proc_write+0xf0/0xf0
[91702.190422] [<ffffffff81095c9d>] ? SYSC_finit_module+0x7d/0xc0
[91702.190422] [<ffffffff814affbe>] ? system_call_fastpath+0x1c/0x21
[91702.190422] [<ffffffff814aff11>] ? system_call_after_swapgs+0xae/0x13f
[91702.190422] Code: 4c 8b 71 70 48 89 04 24 48 8b 00 48 8d 50 10 83 38 ff 74 40 48 83 c0 04 48 39 c2 75 f2 41 81 7d a4 86 80 20 29 0f 84 f9 01 00 00 <41> f6 46 1b 20 74 22 49 8b 85 d0 02 00 00 48 85 c0 74 16 49 8b
[91702.190422] RIP [<ffffffffa0edfdc7>] piix_init_one+0x527/0x8dd [ata_piix]
[91702.190422] RSP <ffff880071023b98>
[91702.190422] CR2: 000000000000001b
[91702.582086] ---[ end trace a9f85e2570baadf7 ]---I'll try to inject this driver to bootloader to see if it crashes there as well...
And also I'll try to run it on a proper hardware (tried on ML110G5 by mistake...)
Did you built it with old GCC? (like 4.9-old) You can't build modules for old kernels using new GCCs.
On 9/25/2021 at 6:28 AM, toyanucci said:Can someone recommend a compatible nic?
I waited all week for a HP NC360T to be delivered only to realize it's a pcie x4 and my j4105 motherboard only has a pcie x1 slot 😑
The onboard realtek nic should be compatible but for some reason it isn't working for me so I want to try using another nic.
Pro tip: NC360T works in x1 slot
You can either order a raiser from x1 to x4 or use a saw (no, we're not joking).
http://www.invisiblerobot.com/pcie_x1/ - you're trying this at your own risk but it does work and with 2x1Gb it shouldn't bottleneck.On 9/25/2021 at 9:50 AM, dateno1 said:redpill-tool-chain_x86_64_v0.11 Build Tested
6.2.4 is no warning or error but 7.0 has warning
usb.h warning is seemed easy to fix
Can you fix it at next version?
That warning is [sadly] normal as we don't have sources for the kernel.
On 9/25/2021 at 5:05 PM, haydibe said:Affirmative. Everything right on spot!
DSM6.2.4 builds use the kernel sources that are publicly available - thus the condition checks for the kernel sources beeing used is met and there is noreason to throw the warning.
From my perspective there is nothing wrong with the warning on DSM7 builds, as it's a constant reminder that we need to switch from toolkit-dev to the kernel sources as soon as they are publicly available. This warning is a functional warning, not a technical warning.
@dateno1 To "fix" this warning you just need to convince Synology to publish the DSM7 kernel sources 😃
That warning is there as we're using a struct which is... well... HOPEFULLY correct
If it's not we may be in trouble. There's a slim chance it's not but who know what they tinkered with? It's working, but we are scared of the SATA boot on 918+ because of that. As we [hope] most of us are adults here there may have been few too many adult beverages when someone said "but guys guys listen... what if we EMULATE USB WITH SATA!" ... and as crazy as it sounds this is how the SATA boot was born on 918+ but the warning is there to scare away anyone from trying something like that with another crazy idea. It's just the toolkit headers don't come with full headers but only public ones (which is EXACTLY to prevent module authors from exploiting private API of the kernel).
On 9/25/2021 at 5:09 PM, Patt92 said:Thanks for all the great work of all of you guys.
Got 7.0.1-42214 DS918+ running on KVM Virtualization (Qemu) on a Ryzen 5 Pro 4650G system.
For anyone struggling with it, I just used the toolkit for building the redpill image.
- DiskIdxMap 0C
- Redpill image on Sata 0:0 (Controller 0, Unit 0)
- HDDs on Sata Controller 2 (on 1 you can't find them)
- VID/PID should be irrelevant but I went for V: 0x46f4 and P: 0x0001
The VID/PID with SATA boot is completely irrelevant. We just flat-out ignore it completely. There's even a warning in dmesg (which can be safely ignored, it's just more for analyzing logs) that these parameters were completely ignored.
On 9/25/2021 at 10:51 PM, imdgg said:when i launch a container in Docker, the ds3615xs vm will crash
dsm version is 7.0.1
ds3615xs runs in esxi 6.7
cpu:E3 1265L v2
MB: DQ77KB
message.log:
2021-09-25T22:31:49+08:00 DS3615xs synofinderdb[12022]: synofinderdb.cpp:103 (main) synofinderdb tool desc: update synofinder.db 2021-09-25T22:31:50+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:31:55+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:32:00+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:32:25+08:00 DS3615xs synostgd-cache[5439]: SYSTEM: Last message 'cache_monitor.c:2074' repeated 6 times, suppressed by syslog-ng on DS3615xs 2021-09-25T22:32:25+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:32:30+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:32:35+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:33:00+08:00 DS3615xs synostgd-cache[5439]: SYSTEM: Last message 'cache_monitor.c:2074' repeated 6 times, suppressed by syslog-ng on DS3615xs 2021-09-25T22:33:00+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:33:05+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:33:10+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:33:35+08:00 DS3615xs synostgd-cache[5439]: SYSTEM: Last message 'cache_monitor.c:2074' repeated 6 times, suppressed by syslog-ng on DS3615xs 2021-09-25T22:33:35+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:33:40+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:33:45+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:34:10+08:00 DS3615xs synostgd-cache[5439]: SYSTEM: Last message 'cache_monitor.c:2074' repeated 6 times, suppressed by syslog-ng on DS3615xs 2021-09-25T22:34:10+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:34:15+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:34:20+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:34:45+08:00 DS3615xs synostgd-cache[5439]: SYSTEM: Last message 'cache_monitor.c:2074' repeated 6 times, suppressed by syslog-ng on DS3615xs 2021-09-25T22:34:45+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:34:50+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:34:55+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:35:20+08:00 DS3615xs synostgd-cache[5439]: SYSTEM: Last message 'cache_monitor.c:2074' repeated 6 times, suppressed by syslog-ng on DS3615xs 2021-09-25T22:35:20+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:35:25+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:35:30+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Can't support DS with cpu number (1) 2021-09-25T22:35:50+08:00 DS3615xs synostgd-cache[5439]: SYSTEM: Last message 'cache_monitor.c:2074' repeated 5 times, suppressed by syslog-ng on DS3615xs 2021-09-25T22:35:50+08:00 DS3615xs synostgd-cache[9725]: cache_monitor.c:2074 [Error] Reach cache monitor error message limitdocker.log
2021-09-25T22:31:49+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:49.988360829+08:00" level=warning msg="Your kernel does not support cgroup blkio throttle.read_bps_device" 2021-09-25T22:31:49+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:49.988541818+08:00" level=warning msg="Your kernel does not support cgroup blkio throttle.write_bps_device" 2021-09-25T22:31:49+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:49.988720078+08:00" level=warning msg="Your kernel does not support cgroup blkio throttle.read_iops_device" 2021-09-25T22:31:49+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:49.988899380+08:00" level=warning msg="Your kernel does not support cgroup blkio throttle.write_iops_device" 2021-09-25T22:31:49+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:49.989077648+08:00" level=warning msg="Unable to find pids cgroup in mounts" 2021-09-25T22:31:50+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:50.296260650+08:00" level=error msg="failed to load container mount" container=a6774be8f04dff2e4331042223aa75400a7cbd9844261d6e7556c7d7f0e00df7 error="mount does not exist" 2021-09-25T22:31:52+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:52.414314874+08:00" level=warning msg="Failed to delete conntrack state for 172.17.0.2: invalid argument" 2021-09-25T22:31:52+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:52.550692280+08:00" level=warning msg="Error (Unable to complete atomic operation, key modified) deleting object [endpoint 7e3883ed93a23971685b1e68b3b0b933e39822d49c155e8e1b530fbc3ce04e4f dffd96d61caa97732569427dcb32acfd4941374e389cbfde4d7db78b9f7f915f], retrying...." 2021-09-25T22:31:53+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:53.184749410+08:00" level=warning msg="Could not get operating system name: Error opening /usr/lib/os-release: open /usr/lib/os-release: no such file or directory" 2021-09-25T22:31:53+08:00 DS3615xs docker[11656]: time="2021-09-25T22:31:53.185005296+08:00" level=warning msg="Could not get operating system version: Error opening /usr/lib/os-release: open /usr/lib/os-release: no such file or directory"but ds918 is running stable in qnap Virtualization Station.
Something went bad... really really REALLY bad. But this is most likely the same annoying bug as with crashing influxdb and CPU soft lockup. See https://github.com/RedPill-TTG/redpill-lkm/issues/21
But also as @WiteWulf suggested DON'T use a single vCPU with one vCORE. Versions of DSM with >1 core assume in many places that the system has at least 2 cores. Don't ask us to comment on that Also you need at least 600MB ram (even if it technically runs on 512).
On 9/25/2021 at 11:21 PM, ilovepancakes said:+1 for this! Would be great to run Surveillance Station with all those deep learning features.
So many people praise Surveillance Station... maybe we should actually try it. Slightly OT but if you're using it (or anyone else): do you recommend it? We mostly use Ubiquity gear for that and it's ... OK, but not really stable.
On 9/26/2021 at 2:14 AM, WiteWulf said:Hi there, can you grab the serial console output from a crash before you roll take 7.0.1 off that Gen10? If you're not sure how, have a search of the forum for accessing the virtual serial port via iLO on the HP hardware, it's a common question.
Didn't they remove iLO from Gen10 and added as a separate purchase in Gen10+?
On 9/26/2021 at 3:08 AM, ct85msi said:root@Apollo:~# cat /sys/class/hwmon/hwmon0/device/hwmon/hwmon0/temp1_input 37000root@Apollo:/sys/class/hwmon/hwmon0# awk '{print $1/1000}' temp1_input 37Before the latest changes, I had the default temperature of 40 C, probably sensors were not working and it showed the default minimum temperature like all the genuine synologys.
With the latest changes to redpill, I have CPU temperatures of ~60 degrees C. I think it`s pretty hot for a idle NAS. In bios and other linux distrib it idled around 40-45 C. I don`t think the latest changes to redpill read the sensors temperature ok.
I think the 37 degrees C from the terminal is the correct temperature.

That temperature isn't real. We wrote about this in a previous post. Currently we sweep-emulate fake temps and voltages inside of the kernel module (to satisfy HWMON subsystem). What we have on our todo list is adding real CPU temp - other params cannot really be read natively as there's no single standard which one is which sensor (you read sensors and which sensor is what depends on mobo/bios/configuration of the bios/boot mode/etc).
On 9/26/2021 at 3:33 AM, paro44 said:I made a migration install on baremetal (Intel SS4200) and noticed some improvements to my first attempt some weeks ago.
I used the tool-chain v0.11 and bromolow 7.0 for DS3615xs. Maybe I made a mistake last time and filled vid/pid and not pid/vid (pay attention on that). DSM-install went smooth. This time I have all four internal disks accessable (on ICH7R chipset). Last time I could only see one hdd.
And now the Info-Center is filled and not empty anymore. I can see 2 cores and 2,2 GHz cpu speed, which could be the real data (I'm not sure, if I already changed the old celeron cpu to a core2duo 2,2 GHz, but I think I did). The cpu type is shown as i3-4130 which isn't correct (but for DS3615xs I think), but I can live with that 😀
Thanks again to all who help to make this working. I'm happy 'til now and will test further.
Edit: temperature is also shown at 60°C, but atm the storage pool is created. CPU load at 25%. Maybe it goes down when finished.
Temp is fake, cpu frequency is real, cpu model is.... whatever synology thinks it is
The cpu model is just cosmetics, doesn't really affect anything - just a pretty thing to show on spec sheet (and its not read from the real microcode but guessed by mfgBIOS based on different parameters). We randomize temperature and then hover around it.
On 9/27/2021 at 10:24 AM, imdgg said:when you see the boot menu,
choose SATA boot and press e to edit boot menu
add ‘DiskIdxMap=0c00 SataPortMap=1’ at the end of the boot args entry.
then press ctrl+x to boot
Don't edit manually the grub.cfg - add it to the user_conf in the extra_cmdline section.
On 9/27/2021 at 5:33 PM, Orphée said:We don't have any /dev/dri/ on DS3615xs and Facedetection works on DSM 6.2.4 and DSM7 on my HP Gen8 running with ESXi.
I just had to set core numbers to 2 (instead of 2vCPU / 1 core, I changed to 2vCPU / 2 cores)
Of course I have real SN/MAC.
(It also works with Jun's loader DSM 6.2.3 with same setup)
But not listed as compatible by Synology... lol
Be careful with setting multiple vCPUs - they tinkered with number of CPUs (not cores) in the kernel. It cannot be trusted to work properly on systems which ship with single CPU (i.e. all but some rack stations? do they even ship with 2 CPUs?).
On 9/27/2021 at 6:12 PM, andreika said:I found my error.
I put mac address in configuration with ":" symbols. Removing symbols fixed the problem.
Thank you for support!
Now it is working!!!
Yes, that's a quirk of the syno code itself - it doesn't care about lower/upper case but does care about : in the MAC. During boot RP actually errors-out with that on serial console as it verifies the MAC a bit (just length really).
On 9/27/2021 at 6:18 PM, sebg35 said:Just a quick reminder for myself (and maybe it can help other) for the next try :
When i start to upgrade my Gen10 plus (1 internal Sata with 4 disks 1,2,3,4) from 6.2.3 (Jun loader 3617xs) to 7.0.0 (Redpill) 3615xs :
- Only one disk was shown with id 13 ?
In order to get all 4 disks working i was needed to modify grub :
- Jun Loader 6.2.3 Grub :
Bold : present by default on Jun loader ?
set common_args_3617='syno_hdd_powerup_seq=0 HddHotplug=0 syno_hw_version=DS3617xs vender_format_version=2 console=ttyS0,115200n8 withefi elevator=elevator quiet syno_port_thaw=1'
set sata_args='sata_uid=1 sata_pcislot=5 synoboot_satadom=1 DiskIdxMap=0C SataPortMap=1 SasIdxMap=0'
- Redpill Loader 7.0.0 Grub :
Bold : Added
linux /zImage mac3=xx mac2=xx DiskIdxMap=00 mac1=xxmac4=xx netif_num=4 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=0 vid=xx syno_hdd_detect=0 pid=xx console=ttyS0,115200n8 elevator=elevator sn=xx root=/dev/md0 SataPortMap=1 SasIdxMap=0 sata_uid=1 sata_pcislot=5 earlyprintk loglevel=15 log_buf_len=32M syno_port_thaw=1 HddHotplug=0 withefi syno_hw_version=DS3615xs vender_format_version=2
Don't add random parameters like that. First of all, you should NOT edit grub.cfg but put your params in user_conf.json instead. Second for the disk parametrs see this great explanation: https://xpenology.com/forum/topic/44285-proxmox-hba-passthrough-second-virtual-controller-not-detected/?do=findComment&comment=204352
Third: do NOT add sata_uid or sata_pcislot - these are Jun's custom parameters which were never implemented but were left there. The difference is Jun's loader was removing them from cmdline so that DSM cannot see them - RP does not as we never used them. Making them visible to DSM shows the DSM clearly it's running on non-official hardware.
On 9/28/2021 at 3:36 AM, pocopico said:A few compiled modules for DS918+ (4.4.180+). Most network drivers have been tested and work
https://github.com/pocopico/4.4.180plus-modules
Can you make extensions out of those?
On 9/28/2021 at 5:55 PM, WiteWulf said:FWIW, this release (7.0.1-42218 with redpill-lkm 3474d9b) is very unstable for me. It's kernel panicking for Plex Media Server (which is essentially a big database) as well as my docker containers. I don't know if that's because of the move to 7.0.1-42218, or because I've also moved to 3474d9b again. I previously tried 3474d9b and found it very unstable on my system, so to went back to 021ed51, which crashed much less often.
I've disabled docker on my system now, but it's kernel panicking every few minutes as soon as Plex Media Server starts doing anything. Gonna have to try and build a 7.0.1-42218 image with that older redpill-lkm commit as this is completely unusable now.
So it seems PostgreSQL is the best for triggering that crash (DSM index, plex, music - all use PgSQL). Noted
On 9/28/2021 at 7:23 PM, D.S said:The SN & MAC are from real DS918+. I didn't see anything about the SN & MAC in /var/log/synofoto.log, and the information about the SN in /var/log/messages as below.
Message in /var/log/messages:
2021-09-28T18:30:52+08:00 XXXX-NAS kernel: [ 16.531414] Got empty serial number. Generate serial number from product.
2021-09-28T18:30:52+08:00 XXXX-NAS kernel: [ 16.665292] Got empty serial number. Generate serial number from product.
2021-09-28T18:30:52+08:00 XXXX-NAS kernel: [ 16.665295] drivers/usb/core/hub.c ( 2940) Same device found. Change serial to ffffffccfffffffbffffffcbfffffff0This is unrelated to syno - this is the kernel yelling at the manufacturer of your USB device which has no S/N (any USB device should have it... a lot don't ignore the USB spec). This will not break anything - it's just the kernel being pedantic.
On 9/28/2021 at 10:24 PM, Orphée said:Actually, just to "fix" words between SAS card and drives.
On my case, and I think on most of us, drives are SATA.
We have a LSI SAS HBA IT card, but with SAS to SATA cable
https://www.amazon.fr/CableDeconn-SFF-8087-Fanout-Wihout-Latch/dp/B00S7KU0VO/

I just want to be clear on this. for @ThorGroup
Disks are detected as SAS whereas there are SATA drives on SAS card.
Thanks
It's just semantics - SAS command set uses SCSI like SATA with some differences like how SMART is handled. The situation is similar with PCI and PCI-Express. The physical interface matters to the controller, to the OS it's abstracted under a single SCSI interface (yes, the same ancient SCSI) no matter if the physical disk is a SAS or SATA one. There are even breakout boards for SATA drivers allowing for dual-channel SAS connection (for redudancy).
On 9/28/2021 at 11:03 PM, flybird08 said:Bad news, neither seems to be included in the DS918+.
SAS and 918+ isn't something which will ever work natively. However, if we force DSM to see SAS as SATA.... that's a different story.
On 9/29/2021 at 1:17 AM, svenger87 said:I´m struggling with installing the PAT file. The Webassistant shows the PAT is corrupted.
System is a Intel NUC RTL 8111H card. Any hints whats wrong?Edit: Ah. I think i need to edit the SATA params in the grub.cfg.
Do NOT edit grub.cfg - edit user_conf.json
On 9/29/2021 at 1:46 AM, WiteWulf said:I think this may be on the way to fix that:
https://github.com/RedPill-TTG/redpill-boot-wait
(Lots of interesting new bits appeared on GitHub this afternoon)
We knew someone will catch our quick final tests with public repos
They were public before the post for probably total of 10 minutes.
On 9/29/2021 at 8:49 AM, flybird08 said:I don't think it is statically compiled into the DS918+ DSM kernel. When I mount, I can see the corresponding error prompt. This module is missing.
See
============================================================================
This post reached 50 quotes - we will continue in the next one.-
3
-
3
-
This post contains answers up to page 67.
======================================================
On 9/13/2021 at 3:38 AM, pocopico said:Line 285 in your case. /lib/modules is linked to /usr/lib/modules
.
insmod /lib/modules/xxx
You should use extensions now and NOT modify any files manually.
On 9/13/2021 at 2:23 PM, shibby said:1st) connect your drives in the order starting from SATA0 port.
2nd) add SataPortMap=4 to your config grub.cfg file. Set this vaule to corresponding to your number of hard drives
Please, do not modify the grub.cfg file. This isn't a supported method with RP and should not be used. You should add that option as an extra_cmdline in user_conf instead.
On 9/13/2021 at 2:39 PM, ct85msi said:Only this error in /var/log/messages :
2021-09-13T09:34:08+03:00 Apollo kernel: [246979.674416] md_error: sdd2 is being to be set faulty 2021-09-13T09:34:08+03:00 Apollo kernel: [246979.674710] raid1: Disk failure on sdd2, disabling device. Operation continuing on 3 devices 2021-09-13T09:37:30+03:00 Apollo synodisklatencyd[10373]: raid_uuid_get.c:81 Disk [/dev/sdd3] in RAID [/dev/md3] has no RAID superblock, ret=0 2021-09-13T09:37:30+03:00 Apollo synodisklatencyd[10373]: raid_uuid_get.c:81 Disk [/dev/sdd3] in RAID [/dev/md3] has no RAID superblock, ret=0 2021-09-13T09:37:37+03:00 Apollo synodisklatencyd[5770]: SYSTEM: Last message 'raid_uuid_get.c:81 D' repeated 1 times, suppressed by syslog-ng on Apolloand in dmesg:
[245399.816502] RTC time set to 2021-09-13 6:07:48 (UTC) [246979.674416] md_error: sdd2 is being to be set faulty [246979.674710] raid1: Disk failure on sdd2, disabling device. Operation continuing on 3 devices [246979.874503] RAID1 conf printout: [246979.874722] --- wd:3 rd:4 [246979.874954] disk 0, wo:0, o:1, dev:sda2 [246979.875301] disk 1, wo:0, o:1, dev:sdb2 [246979.875625] disk 2, wo:0, o:1, dev:sdc2 [246979.875956] disk 3, wo:1, o:0, dev:sdd2 [246979.941246] RAID1 conf printout: [246979.941435] --- wd:3 rd:4 [246979.941597] disk 0, wo:0, o:1, dev:sda2 [246979.941813] disk 1, wo:0, o:1, dev:sdb2 [246979.942028] disk 2, wo:0, o:1, dev:sdc2 [246980.681243] md: unbind<sdd2> [246980.687229] md: export_rdev(sdd2)
Meanwhile...the benchmark is stuck in this state, as the image attached.
Thank you for all of your work !
After I stop the test, the array is resyncing.

That is... strange. We're adding it to our internal list as the disk test shouldn't randomly crash the pool
On 9/13/2021 at 2:50 PM, coint_cho said:Was testing it on VMWare and now unfortunately it can't even get pass the pat installation screen and is just costantly stuck at 56% and fail with a message of saying file corrupted as usual. Works on Proxmox still but yeah.
This usually happens [on VMWare] when you use USB-boot and not SATA boot. VMWare doens't support USB boot unless you use a physical USB stick connected to a USB-2.0 port [as booting from 3.0 is not exactly working].
On 9/13/2021 at 2:57 PM, SachinD said:@ThorGroup My understanding is that for ESXi the vmdk is split into 2 files the raw data (Diskname-flat.vmdk) and the raw disk descriptor (Diskname.vmdk), whereas other products like VMWare Workstation have the descriptor followed by the disk data in a single vmdk file.. hope that helps.
The issue is actually both ESXi and other VMWare products internally support both. However, newer ESXis don't like just flat VMDKs for some reason. Even generating the descriptor it fails to boot half of the time when the image is not "blessed" by the VMWare's own tool.
On 9/13/2021 at 4:19 PM, Zardozlv said:Nope,I just tried and now I’m reinstalling my DSM😂.The new img is the same size as the old one.
FYI image will always be 128MB (unless we change the base) - you will only see a real change in size when you compress it with e.g. ZIP so it removes all the empty space in it.
On 9/13/2021 at 4:22 PM, WiteWulf said:1 - I'm writing with dd to /dev/rdiskX and absolutely do have to mark it as active afterwards. I've created loads of images now and every time there is no partition marked as active. This isn't a problem for most hardware, but the Gen8 (which as you've pointed out elsewhere is quite picky) *needs* to have the first partition marked as active to boot from it
2 - DSM 7.0.1-RC1 is running docker 20.10.3. This appears to be from February 2021, and only five patch levels behind current (20.10.8). To be clear: this problem only ever manifested with docker containers running influxdb, but across numerous versions of influxdb tried. Lots of Googling suggests no one else is experiencing problems like this, but I'm curious to know if anyone else here sees it.
Gen 8 is on our list to figure out fully as we have quite a few of them
On 9/13/2021 at 5:23 PM, blindspot said:Maybe is not related but this is how DSM is showing drives on the second controller on my bare metal ASRock N3700 and is working fine.

FYI: That is slightly playing with fire. Internally they assume (at leas in v6) that the disk will be 3 characters in a form of "sdX" unless we missed something. The fact it shows up in the GUI doesn't mean it works correctly. There is probably a reason why they don't sell units with >26 internal drive bays
On 9/13/2021 at 5:31 PM, ct85msi said:Just asking, this has nothing to do with xpenology/bootloader, right?
root@Apollo:~# tail -f /var/log/messages
2021-09-13T11:46:56+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:118 Fail to lockf() for scemd connector client.
2021-09-13T11:46:56+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:204 Fail to SYNOScemdConnectorClient() for scemd conncetor client
2021-09-13T11:46:56+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:118 Fail to lockf() for scemd connector client.
2021-09-13T11:46:56+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:204 Fail to SYNOScemdConnectorClient() for scemd conncetor client
2021-09-13T11:46:56+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:118 Fail to lockf() for scemd connector client.
2021-09-13T11:46:56+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:204 Fail to SYNOScemdConnectorClient() for scemd conncetor client
2021-09-13T12:02:01+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:118 Fail to lockf() for scemd connector client.
2021-09-13T12:02:01+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:204 Fail to SYNOScemdConnectorClient() for scemd conncetor client
2021-09-13T12:03:09+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:150 Fail to recvfrom() for scemd connector client.
2021-09-13T12:03:09+03:00 Apollo synosnmpcd[9578]: scemd_connector/scemd_connector.c:204 Fail to SYNOScemdConnectorClient() for scemd conncetor client
That randomly popsup even on real hardware. Sometimes threads of scemd crash/freeze and it tries for some time to recover them before killing and restarting. Nothing to worry about unless it happens constantly.
On 9/13/2021 at 5:45 PM, WiteWulf said:Okay, I figured out why DSM was showing two adapters with the same MAC address: I was declaring/assigning the MAC addresses in the wrong order in user_config.json
I originally had:
{ "extra_cmdline": { "pid": "0x1000", "vid": "0x090c", "sn": "xxxxLWNxxxxxx", "mac1": "xxxxxxxxxx75", "mac2": "xxxxxxxxxx74" }, "synoinfo": {}, "ramdisk_copy": {} }Which manifested as "mac2=xxxxxxxxxx74 mac1=xxxxxxxxxx75" in my grub.cfg. This resulted in DSM seeing two adapters with the same MAC address of xxxxxxxxxx75
Swapping them around to:
{ "extra_cmdline": { "pid": "0x1000", "vid": "0x090c", "sn": "xxxxLWNxxxxxx", "mac1": "xxxxxxxxxx74", "mac2": "xxxxxxxxxx75" }, "synoinfo": {}, "ramdisk_copy": {} }Gives me a grub.cfg with "mac2=xxxxxxxxxx75 mac1=xxxxxxxxxx74" and two NICs with the correct, different, MAC addresses in DSM. This is obviously to do with the order in which the kernel enumerates the NIC interfaces, and the MAC addresses have to be declared in a way that matches that order or linux/DSM gets confused.
Correction: it's not the Linux being confused but the mfgBIOS code. Linux doesn't care - this is why the network may appear to work. But syno services do care. Instead of using the API they went around it so when the MACs aren't in order some things try to use the normal API where others use the syno API... and this is what happens. We usually just boot with one random MAC defined and just "ip a" quickly to see how the kernel sees ethernets in that particular system.
On 9/13/2021 at 5:50 PM, Orphée said:So with latest loader with ESXi Smart patch. I'm not able to install DSM 7.0 anymore. It fails at 55%.
My json file :
Lot of errors like this in serial console :
Any time you see gpioerrors on 918+ it means the module didn't load at all. You should check dmesg. Now the problem shouldn't really exist as if RP fails to load it will deliberately panic the kernel with a detailed log to avoid such "wtf" situations.
On 9/13/2021 at 9:19 PM, p33ps said:Can someone paste here their VM Proxmox setup for a DS3615xs boot? I am having huge CPU issues when the Photos app starts their face recognition index process. It blocks the VM completely and I need to stop-start it. It never finishes the recognition process. This is the CPU and network status when it starts:
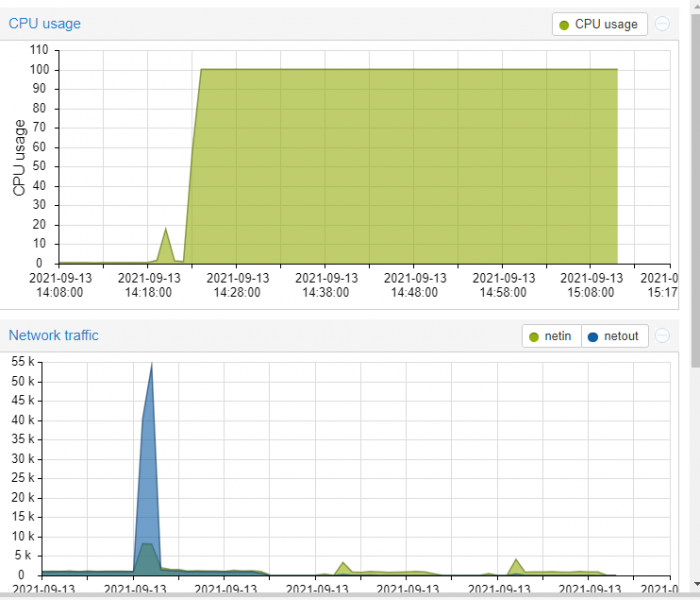
Current hardware setup is:
HP Proliant Microserver G8
16GB RAM
Xeon E3 1265l v2
1 x 1TB 870 SSD
3 x 12TB Seagate Exos X16
1 x 12TB Seagate IronWolf Pro
DSM 7.0.1 RC.
I've tested it with LVM and ZFS storage pool.
Thanks!
FYI this seems like the bug reported for the kernel crashing: https://github.com/RedPill-TTG/redpill-lkm/issues/21
That is extremely hard to debug as kernel lockup is essentially "welp, someone tried to take a spinlock but there's another spinlock running". The fact we cannot compile our own kernel, due to broken sources from syno, makes debugging this issue a nightmare. Take a drink for D3x - she's trying to find the issue for some time now. Preliminary testing shows that may not even be the issue with RP but with the kernel mods by syno itself.On 9/13/2021 at 10:05 PM, abesus said:The good information is that according to internet Xeon E3-1265L V4 has support for MOVBE. My problem was connected to intel iommu driver and I've resolved this issue by reconfiguring this driver. From now my DSM is stable and user_config.json looks like this (vid/pid/sn/mac are different of course
") )
)
It will (should) have impact only for virtual machines inside DSM which I don't have
Oh yes, iommu... that is sometimes tricky. In general IOMMU should be disabled unless you use VMs as it causes more problems even on standard Linux distros. Intel MMU implementation is very... very.... hacky. They improved a lot since 9th gen but older ones are often unstable. A lot of times installing a microcode update helps.
On 9/13/2021 at 11:30 PM, jumkey said:Try to implement loading extended kernel modules like extra.lzma
https://github.com/jumkey/redpill-load/commit/4ff6ffe72a479cbe3ef5a67ecad86441109edd1c
PS D:\redpill-load> tree .\custom\ /f /a D:\REDPILL-LOAD\CUSTOM | .gitkeep | \---lib +---firmware | \---4.4.180+ | \---i915 | bxt_dmc_ver1_07.bin | cnl_dmc_ver1_06.bin | glk_dmc_ver1_04.bin | kbl_dmc_ver1_01.bin | kbl_dmc_ver1_04.bin | skl_dmc_ver1_26.bin | skl_dmc_ver1_27.bin | +---modules | \---4.4.180+ | mpt3sas.ko | r8125.ko | raid_class.ko | rng-core.ko | scsi_transport_sas.ko | vmxnet3.ko | \---modules-load.d 70-disk-0000-mpt3sas.conf 70-extra-0000-r8125.conf 70-extra-0001-vmxnet3.conf 70-optional-0000-virtio-rng.conf PS D:\redpill-load> cat .\custom\lib\modules-load.d\70-optional-0000-virtio-rng.conf rng-core virtio-rng PS D:\redpill-load> cat ..\user_config-ds918.json { "extra_cmdline": { "vid": "0x46f4", "pid": "0x0001", "sn": "xxxxPDNxxxxxx", "mac1": "001132FFFFFD", "mac2": "001132FFFFFE", "netif_num": 2 }, "synoinfo": {}, "ramdisk_copy": { "lib/modules-load.d": "lib/modules-load.d/", "lib/modules/4.4.180+": "lib/modules/", "lib/firmware/4.4.180+": "lib/firmware/" } } PS D:\redpill-load>...and now we have extensions
We hope you like it as we see you play with drivers a lot.
On 9/14/2021 at 1:56 AM, pocopico said:Hi,
i got the same issue as you, it looks like redpill is failing at the time of the boot device shim and then i get no synoboot
[ 9.296466] <redpill/boot_device_shim.c:48> Registering boot device router shim
[ 9.297930] <redpill/native_sata_boot_shim.c:205> Registering native SATA DOM boot device shim
[ 9.298931] BUG: unable to handle kernel NULL pointer dereference at (null)
[ 9.300841] IP: [<ffffffffa0009663>] register_native_sata_boot_shim+0x33/0x1d0 [redpill]
[ 9.302811] PGD 137f9c067 PUD 137f9b067 PMD 0
[ 9.303770] Oops: 0000 [#1] SMP
[ 9.303944] Modules linked in: redpill(OF+)
[ 9.304117] CPU: 3 PID: 521 Comm: insmod Tainted: GF O 3.10.108 #42214
[ 9.304291] Hardware name: VMware, Inc. VMware Virtual Platform/440BX Desktop Reference Platform, BIOS 6.00 07/29/2019
[ 9.304465] task: ffff880137d68820 ti: ffff880135d4c000 task.ti: ffff880135d4c000
[ 9.314116] RIP: 0010:[<ffffffffa0009663>] [<ffffffffa0009663>] register_native_sata_boot_shim+0x33/0x1d0 [redpill]
That should be fixed now as @pocopico mentioned.
On 9/14/2021 at 11:31 AM, FiberInternetUser said:After updating to the latest loader from @ThorGroup for apollolake-7.0.1-42214 on bare metal. Getting the following continuous output from the serial console port after the login prompt.
Getting this notification from the USB Boot Thumbdrive.
We dialed down these debug messages. They're actually perfectly fine. That external storage warning is not and there's an issue on GH for this one as we recall correctly. It should be the same as this one: https://github.com/RedPill-TTG/redpill-load/issues/30
On 9/14/2021 at 2:21 PM, yanjun said:for example:
clone related driver form https://github.com/torvalds/linux/tree/master/drivers(But this is not a recommended practice. If the source of the group Synology GPL7.0 is released and the drivers you need are in the drivers folder, the best practice is to select the driver from the synology GPL source.)
cd drivers/net/ethernet/intel/ixgbe make CONFIG_IXGBE=m CROSS_COMPILE=/usr/local/x86_64-pc-linux-gnu/bin/x86_64-pc-linux-gnu- -C /usr/local/x86_64-pc-linux-gnu/x86_64-pc-linux-gnu/sys-root/usr/lib/modules/DSM-7.0/build/ M=`pwd` modulesnotice: CONFIG_IXGBE=m you need found the CONFIG_IXGBE string form Makefile in /drivers/net/ethernet/intel/ixgbe if you want to compile other drivers
See
On 9/14/2021 at 5:08 PM, ct85msi said:waiting for @chchia to merge redpill-ttg into master and recreate my usb boot stick.
https://github.com/chchia/redpill-load
When will 7.0.1-42214 be officially supported into the master branch ? @ThorGroup
Thank you!
L.E. Done, merged . Thank you chchia!
We have a limited set of hands and try to prioritize getting as many things correctly as we can on the current version. Adding v7.0.1 when we have v7.0 is trivial but adds another thing to test and potentially debug the issues if any. As we described in the roadmap we want to merge all new software releases. Going further we will merge them much faster when the major load we have is a new release and not 42 different things to check and patch + new version
We try to make this about quality and thus we don't blindly merge new releases either - we check every single kernel manually to see if nothing actually changed and don't just use autogenerated patches (as you know, any time you code something - like a generator - you will never trust it as an author ;)).On 9/14/2021 at 11:14 PM, dodo-dk said:I have the same problem with DSM 7.0.1 RC -> Bug CPU, see log.
With 6.2.x it works.
[ 260.026023] BUG: soft lockup - CPU#0 stuck for 41s! [synofoto-face-e:12009] [ 260.026023] Modules linked in: fuse 8021q vhost_scsi(O) vhost(O) tcm_loop(O) iscsi_target_mod(O) target_core_ep(O) target_core_multi_file(O) target_core_file(O) target_core_iblock(O) target_core_mod(O) syno_extent_pool(PO) rodsp_ep(O) udf isofs loop synoacl_vfs(PO) btrfs zstd_decompress ecryptfs zstd_compress xxhash xor raid6_pq zram(C) glue_helper lrw gf128mul ablk_helper bromolow_synobios(PO) hid_generic usbhid hid usblp bnx2x(O) mdio mlx5_core(O) mlx4_en(O) mlx4_core(O) mlx_compat(O) qede(O) qed(O) atlantic_v2(O) atlantic(O) tn40xx(O) i40e(O) ixgbe(O) be2net(O) i2c_algo_bit igb(O) dca e1000e(O) sg dm_snapshot crc_itu_t crc_ccitt psnap p8022 llc zlib_deflate libcrc32c hfsplus md4 hmac sit tunnel4 ipv6 flashcache_syno(O) flashcache(O) syno_flashcache_control(O) dm_mod cryptd arc4 sha256_generic sha1_generic ecb aes_x86_64 authenc des_generic ansi_cprng cts md5 cbc cpufreq_powersave cpufreq_performance mperf processor thermal_sys cpufreq_stats freq_table vxlan ip_tunnel virtio_scsi(OF) virtio_net(OF) virtio_blk(OF) virtio_pci(OF) virtio_ring(OF) virtio(OF) etxhci_hcd usb_storage xhci_hcd uhci_hcd ehci_pci ehci_hcd usbcore usb_common redpill(OF) [last unloaded: bromolow_synobios] [ 260.026023] CPU: 0 PID: 12009 Comm: synofoto-face-e Tainted: PF C O 3.10.108 #42214 [ 260.026023] Hardware name: QEMU Standard PC (Q35 + ICH9, 2009), BIOS rel-1.14.0-0-g155821a1990b-prebuilt.qemu.org 04/01/2014 [ 260.026023] task: ffff880048620040 ti: ffff880051fcc000 task.ti: ffff880051fcc000 [ 260.026023] RIP: 0010:[<ffffffff81090492>] [<ffffffff81090492>] smp_call_function_many+0x262/0x290 [ 260.026023] RSP: 0000:ffff880051fcfc68 EFLAGS: 00000202 [ 260.026023] RAX: ffff88007dd15cc8 RBX: 0000000000000000 RCX: 0000000000000002 [ 260.026023] RDX: ffff88007dd15cc8 RSI: 0000000000000008 RDI: 00000000000000ff [ 260.026023] RBP: ffff88007dd95cc8 R08: ffff88007dc139c8 R09: 0000000000000020 [ 260.026023] R10: 0000000000004f5c R11: 0000000000000000 R12: 0000000000000000 [ 260.026023] R13: 0000000000000000 R14: 0000000000000000 R15: ffffffff81893940 [ 260.026023] FS: 00007f6a7dffb700(0000) GS:ffff88007dc00000(0000) knlGS:0000000000000000 [ 260.026023] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 260.026023] CR2: 00007f6a22001048 CR3: 00000000486c0000 CR4: 00000000000006f0 [ 260.026023] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 260.026023] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400 [ 260.026023] Stack: [ 260.026023] ffff88007dc139c8 ffff88007dd93980 0000000181893940 0000000000013980 [ 260.026023] ffff88007a0c0400 ffff880051fcfcf8 ffff88007a0c06d8 00007f6a22001048 [ 260.026023] ffffea0000f97bc0 ffff88004747e008 ffffffff81030372 ffff88007a0c0400 [ 260.026023] Call Trace: [ 260.026023] [<ffffffff81030372>] ? flush_tlb_page+0x72/0x130 [ 260.026023] [<ffffffff81117572>] ? ptep_clear_flush+0x22/0x30 [ 260.026023] [<ffffffff81106a0d>] ? do_wp_page+0x2ad/0x8c0 [ 260.026023] [<ffffffff81107e6d>] ? handle_pte_fault+0x38d/0x9e0 [ 260.026023] [<ffffffff81108775>] ? handle_mm_fault+0x135/0x2e0 [ 260.026023] [<ffffffff814aba0a>] ? __do_page_fault+0x14a/0x500 [ 260.026023] [<ffffffff8128e94c>] ? rwsem_wake+0x3c/0x50 [ 260.026023] [<ffffffff81294ee7>] ? call_rwsem_wake+0x17/0x30 [ 260.026023] [<ffffffff814aff11>] ? system_call_after_swapgs+0xae/0x13f [ 260.026023] [<ffffffff814a8883>] ? error_swapgs+0xa4/0xba [ 260.026023] [<ffffffff814a8877>] ? error_swapgs+0x98/0xba [ 260.026023] [<ffffffff814a8883>] ? error_swapgs+0xa4/0xba [ 260.026023] [<ffffffff814a8877>] ? error_swapgs+0x98/0xba [ 260.026023] [<ffffffff814a8883>] ? error_swapgs+0xa4/0xba [ 260.026023] [<ffffffff814a8877>] ? error_swapgs+0x98/0xba [ 260.026023] [<ffffffff814a8883>] ? error_swapgs+0xa4/0xba [ 260.026023] [<ffffffff814a8877>] ? error_swapgs+0x98/0xba [ 260.026023] [<ffffffff814a8883>] ? error_swapgs+0xa4/0xba [ 260.026023] [<ffffffff814a8592>] ? page_fault+0x22/0x30 [ 260.026023] Code: 8d 81 00 89 c1 0f 8e 1e fe ff ff 48 98 48 8b 13 48 03 14 c5 e0 8d 8a 81 f6 42 20 01 48 89 d0 74 c8 0f 1f 84 00 00 00 00 00 f3 90 <f6> 40 20 01 75 f8 eb b6 66 0f 1f 44 00 00 48 89 ea 4c 89 fe 44
See https://github.com/RedPill-TTG/redpill-lkm/issues/21
On 9/14/2021 at 11:20 PM, ct85msi said:I too have the same behaviour. It sees the usb boot stick.
[ 919.179145] Initializing XFRM netlink socket [ 919.208029] Netfilter messages via NETLINK v0.30. [ 919.250782] audit: type=1325 audit(1631632358.130:13): table=nat family=2 entries=7 [ 919.263884] audit: type=1325 audit(1631632358.143:14): table=nat family=2 entries=11 [ 919.283309] audit: type=1325 audit(1631632358.162:15): table=filter family=2 entries=12 [ 919.391771] IPv6: ADDRCONF(NETDEV_UP): docker0: link is not ready [ 921.892097] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 921.892479] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 922.134939] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 922.135304] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 922.294586] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 922.294954] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 922.329003] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 922.329449] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 927.976524] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 927.976892] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 928.210894] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 928.211301] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 928.424925] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 928.425326] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 928.430552] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 928.430919] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 929.973230] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 929.973598] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 930.207479] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 930.207873] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 930.449786] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 930.450221] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 930.455797] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 930.456246] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 938.389994] audit_printk_skb: 84 callbacks suppressed [ 938.390268] audit: type=1123 audit(1631632377.270:44): pid=15145 uid=0 auid=4294967295 ses=4294967295 msg='cwd="/" cmd=7069686F6C652D46544C2074657374 terminal=? res=success' [ 945.354303] <redpill/smart_shim.c:794> Handling ioctl(0x128b) for /dev/sdq [ 945.354684] <redpill/smart_shim.c:809> sd_ioctl(0x128b) - not a hooked ioctl, noop [ 945.398283] <redpill/smart_shim.c:794> Handling ioctl(0x128b) for /dev/sdq [ 945.398665] <redpill/smart_shim.c:809> sd_ioctl(0x128b) - not a hooked ioctl, noop [ 945.646231] <redpill/smart_shim.c:794> Handling ioctl(0x128b) for /dev/sdq [ 945.646619] <redpill/smart_shim.c:809> sd_ioctl(0x128b) - not a hooked ioctl, noop [ 945.649615] <redpill/smart_shim.c:794> Handling ioctl(0x128b) for /dev/sdq [ 945.649980] <redpill/smart_shim.c:809> sd_ioctl(0x128b) - not a hooked ioctl, noop [ 945.839342] <redpill/smart_shim.c:794> Handling ioctl(0x5331) for /dev/sdq [ 945.839709] <redpill/smart_shim.c:809> sd_ioctl(0x5331) - not a hooked ioctl, noop [ 945.845348] <redpill/smart_shim.c:794> Handling ioctl(0x5331) for /dev/sdq [ 945.845716] <redpill/smart_shim.c:809> sd_ioctl(0x5331) - not a hooked ioctl, noop [ 946.061469] <redpill/smart_shim.c:794> Handling ioctl(0x5331) for /dev/sdq [ 946.061834] <redpill/smart_shim.c:809> sd_ioctl(0x5331) - not a hooked ioctl, noop [ 952.472659] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 952.473047] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 952.639016] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 952.639381] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 952.723082] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 952.723448] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 952.728590] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 952.729015] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 953.209624] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 953.210028] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 953.391592] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 953.391989] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 953.608714] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 953.609107] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 953.618258] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 953.618626] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 962.993685] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 962.994052] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 962.999312] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 962.999702] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 963.003186] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 963.003600] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 963.004214] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 963.004628] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 965.265597] <redpill/smart_shim.c:794> Handling ioctl(0x128b) for /dev/sdq [ 965.265963] <redpill/smart_shim.c:809> sd_ioctl(0x128b) - not a hooked ioctl, noop [ 965.289347] <redpill/smart_shim.c:794> Handling ioctl(0x128b) for /dev/sdq [ 965.289730] <redpill/smart_shim.c:809> sd_ioctl(0x128b) - not a hooked ioctl, noop
We know it's an issue create by you but we're leaving a link to have trace here: https://github.com/RedPill-TTG/redpill-load/issues/30
Thank you for creating this is an issue so we can track it easier
On 9/14/2021 at 11:22 PM, scoobdriver said:*edit it was @pocopico I was meant to quote not Witewulf. apologies
It was Bromolow , I found them thank you (search not working for tg3, but tg3.ko works
)
So I need to insmod libphy.ko and tg3.ko .
do you know can I unpack rd.qz with 7z in windows (after mounting first partition of the .img file)
then add the modules .
then add insmod lines (any issue with waiting for libphy.ko to load first )
repack rd.qz with 7z
Now you can use extensions instead of tinkering with rd.
On 9/15/2021 at 12:35 AM, pocopico said:Try this and see if it works for you. Its for 3615 v7.0.1. Extract and rename to rd.gz on first partition if you are booting with legacy bios or second if you are booting with EFI.
- I have added inetd start by default (telnet will work as soon as you get ip from DHCP for troubleshooting)
- modules : tg3, mptsas, mpt3sas, vmxnet3.ko, libphy.ko
Of course there is another way to load extra modules but i havent had the time to try yet.
Do you feel comfortable publishing these modules as extensions?
Also, there's an issue for the telnet. We think it can be made an extension as well: https://github.com/RedPill-TTG/redpill-load/issues/31=On 9/15/2021 at 2:17 AM, matyyy said:Anyone have idea why when i install mariadb on DSM 7.0.1 my server get freeze? CPU 100% load and timeout 😕 (in docker and in synology package) - newest kernel RedPill and ESXI.
https://github.com/RedPill-TTG/redpill-lkm/issues/21
On 9/15/2021 at 2:20 AM, ct85msi said:I think 7.0.1 has more under the hood changes than 7.0 or more under the hood bugs. Thinking to revert to 6.2.4-25556 and apply update 2 to mitigate Synology-SA-21:22 DSM but leaves still vulnerable to Synology-SA-21:25. 21:25 isn`t that important, only local users can exploit the vulnerability.
v7 is a huge beta... on 36**xs we will call it an alpha., and we're not talking about RP+v7 but overall v7. In our production environment no [real syno] devices are running v7 as the real gain is minuscule in comparison to alllll the bugs (some potentially causing data loss) which are there. Give it 6-8 months at least.
On 9/15/2021 at 5:02 AM, haydibe said:... this kind of makes me wonder if I should release the toolchain loader with just the ttg repos in the global_settings.json, and let everyone add their own repos for everything custom. Afterall the global_settings.json is designed to support that szenario.
The issue here is that if we recommend to users to use random forks where everyone changes random things it will be really impossible to support in any way from our end. This will end up with "oh, I used this fork mixed with that which changed 10 scripts and it's broken - why?"
Not that we want to discourage forking in any way but we already see a flow of issue from forks where users are confused and create issue that modules are not being copied where this was hacked around in one of the forks.
Thank you for stripping the custom forks from the image - we think the forks are great for tinkering by developers but when users try to use them without any knowledge of what they really it's a recipe for a fire in a forest. This was nicely shown by the quick supportsystemtemperature hack which breaks more than it fixes. We already see people putting toolchain version in their signatures which shows us they don't understand that the actual toolchain doesn't affect how the loader works and that it's only used to create the build environment.On 9/15/2021 at 6:54 AM, psychoboi32 said:@ThorGroup Is there any way to get S.M.A.R.T data when you hdd passthrough as scsi i passed through hdd which connected on LSI SaS it worked like expected but showing qemu drive and wrong temp because adding LSI sas driver will might work but idk i failed many times

recently switched my main nas to this yes i have backup don’t worry trying what we can archive if we don’t have working drivers in future
trying what we can archive if we don’t have working drivers in future
dsm 7.0.1
edit :- we can have smart data on proxmox webui ok that is other side
edit :- serial is spamming “generating fake smart”
[ 269.267949] sd_ioctl(HDIO_DRIVE_CMD ; ATA_CMD_ID_ATA) failed with error=-22, attempting to emulate something[ 269.269528] Generating completely fake ATA IDENTITY[ 269.271472] Handling ioctl(0x30d) for /dev/sdl[ 269.272409] sd_ioctl(0x30d) - not a hooked ioctl, noop[ 269.273462] Handling ioctl(0x31f) for /dev/sdl[ 269.274459] sd_ioctl(HDIO_DRIVE_CMD ; ATA_CMD_ID_ATA) failed with error=-22, attempting to emulate something[ 269.276229] Generating completely fake ATA IDENTITY[ 273.120359] Handling ioctl(0x31f) for /dev/sdh[ 273.121174] Got SMART *command* - looking for feature=0xd0[ 273.122451] Generating fake SMART values[ 275.790673] Handling ioctl(0x30d) for /dev/sdh[ 275.791803] sd_ioctl(0x30d) - not a hooked ioctl, noop[ 275.792771] Handling ioctl(0x31f) for /dev/sdh[ 275.793646] sd_ioctl(HDIO_DRIVE_CMD ; ATA_CMD_ID_ATA) failed with error=-22, attempting to emulate something[ 275.795185] Generating completely fake ATA IDENTITY[ 275.797133] Handling ioctl(0x30d) for /dev/sdi[ 275.797975] sd_ioctl(0x30d) - not a hooked ioctl, noop[ 275.798938] Handling ioctl(0x31f) for /dev/sdi
Sent from my iPhone using Tapatalk"Generating completely fake SMART" means that DSM asked for SMART data using ATAPI interface and your LSI rejected that request and so that RP stepped in and provided something fake to make the DSM use the disk at all. Theoretically it would be possible for RP to ask the SAS controller for the SMART using the SAS way and translate that information but this isn't a simple project. There are at least 6 different ways of asking for SMART. Three of them (!) are incorporated in parts (!!) into ATA/ATAPI. Of course SAS went a different direction and has way different ways of requesting and reporting SMART. It's a mess. With native syno SAS support their controllers seem to support ATAPI on SAS (probably custom firmware) and this is why on real hardware it "just works".
Feel free to put an issue on GitHub in the redpill-lkm repo so we don't forget. However, we're certain it wouldn't be implemented very soon (but most definitely we would love to have that feature).On 9/15/2021 at 6:57 PM, WiteWulf said:No, it's weird, someone else (@altas?) contacted me with exactly the same problem. Mine "just works" and continues to output to the vsp, it even offers me a login prompt. I'm running with Advanced iLO license on my system (only cost me £10 on eBay) which also allows for virtual boot media.
Just to be clear, to access the console, I:
- ssh to the ilo, ie. 'ssh Administrator@diskstation-ilo'
- from the </>hpiLO-> prompt I issue the 'vsp' command to launch the virtual serial port
- I don't login if all I want to see is console output
% ssh Administrator@diskstation-ilo Administrator@diskstation-ilo's password: User:Administrator logged-in to diskstation-ilo.osx.ninja(192.168.1.11 / FE80::D2BF:9CFF:FE45:F58A) iLO Advanced 2.78 at Apr 28 2021 Server Name: diskstation-iLO Server Power: On </>hpiLO-> vsp Virtual Serial Port Active: COM1 Starting virtual serial port. Press 'ESC (' to return to the CLI Session. Password: [ 6968.613699] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 6968.614727] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 6968.614728] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 6968.616323] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 6968.616324] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 6968.617563] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 6968.617564] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 6968.859345] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop
As for the iLO 4 Advanced there's a beta key which happens to work on retail version. We don't know how legal is to use it but if you google it you can find it for free. Did they leve it on purpose? Is it some sort of an engineering key? Who knows. Most likely these keys for few bucks on ebay are these resold beta keys.
On 9/15/2021 at 7:01 PM, WiteWulf said:@scoobdriver @altas I've just had a grep through /var/log/synobootup.log on my system and can't see any reference to 'redpill/uart_swapper', which seems to be the culprit for you two.
Here's the code, see if you can figure out what's going on:
https://github.com/RedPill-TTG/redpill-lkm/blob/master/internal/uart/uart_swapper.c
It seems to be a module written to "fix" behaviour in some kernels that erroneously swaps the console output to an alternate tty by swapping it back again. For some reason this is being called unnecessarily on your systems, and swapping the console output away from your active, functioning virtual tty. FYI, I'm running a bromolow 7.0.1-RC1 42214 image.
I don't know why this is happening for you, or why it's not happening for me. Closer inspection of the code (or explanation from @ThorGroup) may help.
The swap has to be done 100% of the time on 3615xs. The only time when you would want to leave it swapped is if you did swap them in your BIOS (i.e. set first serial port to 0x2F8 instead of 0x3F8).
On 9/15/2021 at 7:32 PM, scoobdriver said:Thank you for your rd.gz with the .ko's for the Gen8 onboard NIC ..
on bare metal this boots, and I am able to see the machine on the network and reach the Web assistant .
At this moment it is not seeing my HDD , (on a HBA card flashed IT )
not sure if I need to modify the DiskIdxMap values or SataPortMap (I did with Juns)
However I am seeing these and other args / parameters not been recognised and been ignored as per the serial output below (Iv'e removed my real Mac and Serial)
is anybody else seeing this ?
[ 2.150381] Freeing initrd memory: 34164k freed [ 2.156393] redpill: module verification failed: signature and/or required key missing - tainting kernel [ 2.159947] <redpill/redpill_main.c:44> ================================================================================================ [ 2.164332] <redpill/redpill_main.c:45> RedPill v0.5-git-021ed51 loading... [ 2.167431] <redpill/call_protected.c:55> Got addr ffffffff8119d370 for cmdline_proc_show [ 2.170194] <redpill/cmdline_delegate.c:322> Cmdline count: 410 [ 2.172284] <redpill/cmdline_delegate.c:389> Cmdline: BOOT_IMAGE=/zImage mac2=001122334455 DiskIdxMap=0C00 mac1=001122334456 netif_num=1 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=0 vid=0x058f syno_hdd_detect=0 pid=0x6387 console=ttyS0,115200n8 sata_pcislot=5 elevator=elevator sn=1560LWN004120 root=/dev/md0 SataPortMap=8 earlyprintk loglevel=15 log_buf_len=32M syno_port_thaw=1 HddHotplug=0 withefi syno_hw_version=DS3615xs vender_format_version=2 [ 2.172284] [ 2.186333] <redpill/cmdline_delegate.c:401> Param #0: |BOOT_IMAGE=/zImage| [ 2.188639] <redpill/cmdline_delegate.c:296> Option "BOOT_IMAGE=/zImage" not recognized - ignoring [ 2.191645] <redpill/cmdline_delegate.c:401> Param #1: |mac2=001122334455| [ 2.193899] <redpill/cmdline_delegate.c:284> Set MAC #1: 001122334455 [ 2.195989] <redpill/cmdline_delegate.c:401> Param #2: |DiskIdxMap=0C00| [ 2.198210] <redpill/cmdline_delegate.c:296> Option "DiskIdxMap=0C00" not recognized - ignoring [ 2.201164] <redpill/cmdline_delegate.c:401> Param #3: |mac1=001122334456| [ 2.203441] <redpill/cmdline_delegate.c:284> Set MAC #2: 001122334456 [ 2.205575] <redpill/cmdline_delegate.c:401> Param #4: |netif_num=1| [ 2.207673] <redpill/cmdline_delegate.c:239> Declared network ifaces # as 1 [ 2.209984] <redpill/cmdline_delegate.c:401> Param #5: |earlycon=uart8250,io,0x3f8,115200n8| [ 2.212866] <redpill/cmdline_delegate.c:296> Option "earlycon=uart8250,io,0x3f8,115200n8" not recognized - ignoring [ 2.216276] <redpill/cmdline_delegate.c:401> Param #6: |syno_hdd_powerup_seq=0| [ 2.218675] <redpill/cmdlinelegate.c:296> Option "syno_hdd_powerup_seq=0" not recognized - ignoring [ 2.322084] <redpill/cmdline_delegate.c:401> Param #7: |vid=0x058f| [ 2.324158] <redpill/cmdline_delegate.c:108> VID override: 0x058f [ 2.326209] <redpill/cmdline_delegate.c:401> Param #8: |syno_hdd_detect=0| [ 2.328484] <redpill/cmdline_delegate.c:296> Option "syno_hdd_detect=0" not recognized - ignoring [ 2.331519] <redpill/cmdline_delegate.c:401> Param #9: |pid=0x6387| [ 2.333548] <redpill/cmdline_delegate.c:142> PID override: 0x6387 [ 2.335521] <redpill/cmdline_delegate.c:401> Param #10: |console=ttyS0,115200n8| [ 2.337920] <redpill/cmdline_delegate.c:296> Option "console=ttyS0,115200n8" not recognized - ignoring [ 2.341013] <redpill/cmdline_delegate.c:401> Param #11: |sata_pcislot=5| [ 2.343186] <redpill/cmdline_delegate.c:296> Option "sata_pcislot=5" not recognized - ignoring [ 2.345976] <redpill/cmdline_delegate.c:401> Param #12: |elevator=elevator| [ 2.348211] <redpill/cmdline_delegate.c:296> Option "elevator=elevator" not recognized - ignoring [ 2.351154] <redpill/cmdline_delegate.c:401> Param #13: |sn=1560LWN004120| [ 2.353394] <redpill/cmdline_delegate.c:45> S/N set to: 1560LWN004120 [ 2.355481] <redpill/cmdline_delegate.c:401> Param #14: |root=/dev/md0|
You can modify these values in the config if you need to move drives around. Don't modify them blindly - you need to understand it
On 9/15/2021 at 7:34 PM, scoobdriver said:Wonder if it is this line which seems like it is been ignored along with other parameters
[ 2.335521] <redpill/cmdline_delegate.c:401> Param #10: |console=ttyS0,115200n8|
[ 2.337920] <redpill/cmdline_delegate.c:296> Option "console=ttyS0,115200n8" not recognized - ignoring
That ignore message means the RP ignored it as it doens't need to do anything with it. The kernel itself interprets that properly and configures the serial port. The issue is on 3615xs syno swapped ttyS0 and ttyS1, so if you type ttyS0 to the kernel it will really start sending data to a physically soldered port ttyS1 on the motherboard.
On 9/15/2021 at 8:10 PM, Aigor said:Forgive me if i'm dumb, if i would build loader for 7.01 for HP Gen8 Microserver, how should i do?
Can i perform direct upgrade in place without lost config and data?
Should i backup, perform new installation and restore?
Which process should be better with balance between data integrity and less operation?
many thanks
You can swap the loader image and boot - then it will prompt you for PAT and just migrate as normal. But as others said: you should always have a backup as RAID is not a backup. Even if you run a ZFS on an official system for iX you should do a backup
We are amazed by r/DataHoarders and their backups of 4-digit number of TBs....you do have a backup, right.... right?....right?
On 9/16/2021 at 1:20 AM, spikexp31 said:Heya Redpill Community,
I am following your progress and this is truly amazing. I am really excited to test DSM 7+ on my Gen8 running ESXI 7.02 for now.
Unfortunately, I don't have enough skills to compile a loader within docker, as I don't clearly understand the entire process (shame for an IT guy), so i will wait when first release will arrive.
There will be a clear instruction with the beta - stay tuned.
On 9/16/2021 at 2:28 AM, WiteWulf said:For some reason, since updating to the latest redpill version (Monday 13th of September), I can no longer mount /dev/synoboot1 in my running server. I'm absolutely certain I did this recently to edit the grub.cfg and update the MAC addresses in there, but I get the following now:
bash-4.4# mount /dev/synoboot1 /mnt/synoboot1 mount: /mnt/synoboot1: wrong fs type, bad option, bad superblock on /dev/synoboot1, missing codepage or helper program, or other error.It's not the end of the world, but it was handy being able to edit the bootloader stick when it was still plugged in inside the server and just reboot it for changes, rather than having to take it out and edit it in another machine.
Am I doing something wrong?
FWIW, disk still thinks the device is valid:
bash-4.4# fdisk /dev/synoboot Welcome to fdisk (util-linux 2.33.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): p Disk /dev/synoboot: 14.9 GiB, 16018046976 bytes, 31285248 sectors Disk model: USB Flash Drive Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0xf110ee87 Device Boot Start End Sectors Size Id Type /dev/synoboot1 * 2048 100351 98304 48M 83 Linux /dev/synoboot2 100352 253951 153600 75M 83 Linux /dev/synoboot3 253952 262143 8192 4M 83 LinuxThis is an annoying "feature" of syno you've discovered few posts after
The reason why it works from dev is that they implemented that security feature rather poorly. Normally to disable it you need to do "echo 1 >/proc/sys/kernel/syno_install_flag" and then you can mount /dev/synoboot freely. Keep in mind (or rather others reading it as you seem to know what you are doing) you should NOT edit ANY files in the image manually.
On 9/16/2021 at 5:07 AM, Kouill said:Works on hp microserver gen8 baremetal with onboard nic
bromolow-7.0.1-42214
I used the tg3.ko from
Extract the rd.gz, put the *.ko on \usr\lib\modules
Add insmod in linuxrc.syno.impl like this :
insmod /lib/modules/libphy.ko
insmod /lib/modules/tg3.ko
Repack rd.gz
And make the first partion active on the sd card
Thanks
Please, use the extension mechanism instead since we have it now.
On 9/16/2021 at 8:08 AM, Ermite said:Installed bromolow-7.0.1-42214 to my HP N54L.
I was used Jun's Loader 1.03b (DSM 6.2.3) and all HDD fully migrated with no error. (only keep my data, drop before config)
and it work well, but some part is not work.
1. Info Center - General tab is blank.
2. USB UPS cannot work. I'm using APC UPS, it worked with 6.2.3.
General tab is fixed for some time now (hwmon emulation).
On 9/16/2021 at 10:22 AM, D.S said:I just compiled the driver but haven't tested yet. You may need to load crc-itu-t.ko first.
Can you publish the driver as an extension instead?
On 9/16/2021 at 4:05 PM, WiteWulf said:Yeah, that'll definitely be it.
At this point I'd like to take the opportunity to thank @ThorGroup for the excellent quality of their code commenting, it's really very professional and makes figuring out stuff like this much easier.
We always try - all of us work/worked in development professionally and we realize how hard is to work with "clever" code. YOU know how it works when you wrote it. A week later neither you nor your friends know what's going on and everybody starts avoiding that part of the code like fire... after a year or two you have the same functionality implemented 5x by 10 different people and nobody knows what's going on. With RP we try to avoid that. It's nice that someone sees that effort.
On 9/16/2021 at 4:29 PM, Orphée said:Hi guys!
I need some explanation about Proxmox passtrough / SMART vs ESXi...
I'm using ESXi and never played with Proxmox.
Refering to my current issue with ESXi : https://github.com/RedPill-TTG/redpill-lkm/issues/19
I'm using ESXi 7.0 with a LSI 9211-8i IT SAS card.
As VMWare dropped this card support with 7.x it can't work on VMWare directly (So can't use RDM unless I revert back to esxi 6.7). But until now, with Jun's loader. I'm able to passtrough PCI the card directly to the Xpenology VM and it works totally fine.
But with Redpill loader, until @ThorGroup maybe find a workaround, I would like to know how Proxmox with these type of cards.
Is Proxmox able to give the disk with SMART data working in Xpenology without a full passtrough like ESXi ?
With ESXi 6.7 I was able to give disks to VM as RDM, but SMART then was KO. The only way to make SMART work always were to passtrough the whole LSI card directly to VM.
Thanks for your explanations
Edit : By the way, did someone try to give disk to redpill loader with RDM on ESXi ? does it work ? (I can't test)
The only way to get SMART working is to pass the whole HBA device. In theory QEmu and others could proxy and filter SMART commands per drive but there's too great surface for attacks and weird behaviors for QEmu/VMWare to do it. You have to remember that "SMART" is really a combination of multiple unofficial ATA commands which were glued together by different manufactures. Then ATAPI tried to codify them and we got a ... huge mess held with several rolls of duct tape. This is why we have to step around a lot of undefined behaviors (like optional log directory SMART command which breaks DSM if it's not supported... but it's officially optional but someone assumed it's always there as modern drives support it).
On 9/16/2021 at 7:38 PM, WiteWulf said:So, after doing some googling, it seems Synology have dropped support for ALL USB devices other than storage in DSM 7. This is causing problems for lots of people with USB TV tuners, DACs, WiFi, serial ports, zigbee interfaces, Bluetooth, printers, you name it.
https://mariushosting.com/synology-how-to-add-usb-support-on-dsm-7/
Are they... serious? Sharing a printer is one of the few nice features people actually use on NASes. It seems like a great candidate for an RP extension to run that script on boot
Maybe you will like to contribute and create such one so it's an easy install?
On 9/16/2021 at 8:22 PM, pocopico said:Hi, I really doubt that they will fit inside the loader image as the ramdisk at least for MBR cannot exceed certain size. But whats the purpose of nvidia drivers in xpenology ?
There are guides how to install NVidia drivers directly from spk from synology. This is the way to really do it. They offer them for their "AI" survivalence station model.
On 9/16/2021 at 11:25 PM, Orphée said:Did someone try Synology Photo on DSM 7 ?
is it something expected ? :
Edit : It seems to happen when I upload a picture with Firefox browser. does not happen with Chromium...
This is actually a bug in canvas on FF with to strict privacy settings. We saw that somewhere else outside of DSM. We tried to search for that but no luck. All in all that's not a bug in DSM but in FF. There are canvas security settings in FF - if you make them more permissive for DSM address it should work.
On 9/17/2021 at 12:26 PM, jumkey said:for inetd create /usr/syno/etc/rc.d/J00inetd.sh
no need patch /etc/rc
or open http://IP:5000/webman/start_telnet.cgi
We think now it can be automated by an extension - let us know.
On 9/17/2021 at 12:58 PM, nemesis122 said:I can confirm that i have the same Gen8 reboots sometimes and again randomly so in this case i think htis kernel panic.
for the issue with the blank system info i add this line and is working
sed -i 's/supportsystemperature="yes"/supportsystemperature="no"/g' /etc.defaults/synoinfo.conf
sed -i 's/supportsystempwarning="yes"/supportsystempwarning="no"/g' /etc.defaults/synoinfo.conf
information for this line are here
https://gist.github.com/Izumiko/26b8f221af16b99ddad0bdffa90d4329
For anyone who finds this: please, don't do it. We explained in the previous update post that a HWMON emulation was needed instead as putting these lines in.
On 9/17/2021 at 2:49 PM, shibby said:yesterday i tried upgrade my primary bare metal Xpenology from 6.2.3 to 7.0.1. The problem is that i have two sata controllers:
1st) on board, 2x HDD and 1x SSD M.2 - those drives are detected
2nd) miniPCIE to 2x SATA port, 1x HDD, 1x SATA SSD - those drives are NOT detected

All 3x HDD has been used as SHR.
I tried figure out which kernel module is used by second controller. I found this:
sda/sdb/sdc are on first controller:
sdd/sde are on a second
but i cannot find pcieport module ("lsmod | grep pcie" return empty result)
in dmesq i found only:
About ASM1061 i found this patch
and probably this is it:
Can someone help me to compile "module?" this this patch? The problem is that ahci is build in kernel (not as module) but ata_generic probably is also required. I don`t know, how is this working on 6.2.3 ( i have added extra drivers by IG-88)
This is a standard AHCI controller. It should work out of the box - you're probably missing a proper Sata config extra_cmdline params and the drives connected to it "land" outside of the zone DSM scans.
On 9/17/2021 at 3:10 PM, dreamtek said:Get another error,sad@haydibe
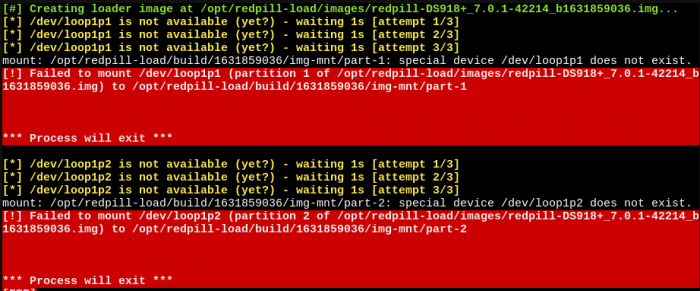
It seems like something wrong with the loop device
But when i use fdisk,it showed that the loopn* is there!
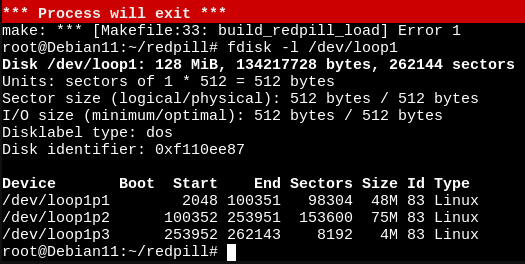
This is fixed now - it's was a race condition between partscan in linux and loop attachement.
On 9/17/2021 at 3:41 PM, WiteWulf said:Yeah, good point, only had one coffee so far today and hadn't thought of that
I'll add it next time I do a boot stick rebuild.
Of course it would be nice if the redpill shim could actually allow access to the monitoring hardware in the server and provide the temperature stats. I would have thought DSM was simply calling lm-sensors, but those tools don't appear to be on the system 🤔
There's a plan to support real sensors and "emulate" values by reading them from sensors modules but emulating fake ones was an easier starting point than translating lm-sensors to syno-HWMON. You can still install lm-sensors or any other monitoring tools you like and monitor everything. It's not like syno API is accessible outside of CPU temp and HDD temps.... sadly. At least on non-syno hardware you have an option to use Linux tools - on real ones people are annoyed that they can't. At least we now know /proc entry can be read by a custom script if needed. There are many threads on syno form askim them for some monitoring beyond CPU temp.
On 9/17/2021 at 4:16 PM, altas said:it is not asp its vsp to start the Serial output on SSH.
in the grub file i set console=ttyS1,115200n8 or ttyS0,115200n8
You should NOT change console parameter. This will break many things (DSM has secuyrity features checking for that parameter; RP assumes that it's at the platform-correct value etc.).
On 9/17/2021 at 5:00 PM, mcdull said:I guess we should open another thread for helping others to use the loader and to leave this thread for development needs.
now this thread is flooding with operational issue.
We think the ship has sailed
We will open a new thread with the beta release (which only really misses SAS and container support if we remember our own roadmap correctly). This topic will be probably closed and we will get a new one strictly for dev with maybe some moderators help to keep the stuff seprated
On 9/17/2021 at 5:15 PM, spv4u1975 said:Hey all
I've can build fine thanks to the info on here but can someone advise how I build a 918 build it is always the 3615xs that gets created.
I know I would love a DVA version build to get AI CCTV running with the 6 licences and Nvidia, Is this on the roadmap/possible?
Thanks for al the hard work
DVA is on our roadmap for another reason - official NVidia drivers. The "AI" survivalence station is something which we personally have no interest in, but it will be there anyway if DVA is emulated.
On 9/17/2021 at 8:09 PM, WiteWulf said:@Orphée I'm not seeing excessive CPU usage on my baremetal install, fwiw. Can you have a look at the output of 'top' and see what process(es) are responsible?
That excessive usage of CPU is actually a missed spinlock somewhere. The kernel doesn't monitor them in any way when debugging is disabled - it will "spin" [i.e. use all CPU cycles on a given core] forever if not unlocked. It's done that way in kernel as spinlocks usually last microseconds (so using other locks would waste even more CPU). When the lock is forgotten/lost somewhere a "deadlock" scenario arises. It will be detected only after some timeout and ideally when another lock tries to execute on the same CPU. It's very hard to debug that over all.
======================================================
Answers will continue in a separate post, as this post cites maximum number of 50 posts
-
3
-
4
-
-
On 9/13/2021 at 11:57 AM, yanjun said:
Unfortunately, for LSI drivers, such as mptsas3, I have tried many times to use the 25426branch kernel code of 918 to compile, and errors will be reported when the driver is loaded (the specific error content I mentioned in the above post) and the system cannot be correct. Start, and jumkey uses the mpt3sas source code of 4.4.180 released by the Linux open source community to compile the mpt3sas driver, which can be loaded correctly and recognize the hard disk, so if for data security considerations, should we wait until Qunhui releases the 41890 kernel source code?
Finally we've got some time to respond to the questions. We will try to respond to as many as possible so stay tight
=======Why there's a problem with compiling drivers when syno didn't publish kernel sources?
This is going to be a separate post addressing "why you cannot randomly grab drivers and compile them" so we can link to it. Let us explain where's the problem, this applies to many questions really.
There are few major issue with compiling drivers against a different sources. The three major ones are:
1) Versioning of syno kernel's is broken due to backporting
2) Drivers modification
3) Kernel <=> driver modification
4) Data structures missing in toolchains for in-tree driversNow let us explain each one of them separately and why this is an issue. There's a lot to unpack here. First lets address few terms which are used in kernel development:
- "in-tree" = code which exists within the source of the kernel; in terms of drivers it means you will find it under "drivers/" (e.g. in drivers/scsi/mpt2sas)
- "vanilla kernel" = source of the kernel which is the official version from kernel.org
- "kernel headers" = .h files present in the toolchain. These are NOT all kernel's .h files but only a subset of public API kernel provides. You will find these under "include" or in the syno toolchain. What's important they DO NOT contain private interaction between modules. That's why if e.g. mpt3sas driver wants something from mpt2sas you cannot use toolchain to compile mpt3sas and you NEED full sources.
- "upstream it" = make your custom patch for the kernel and get it accepted into the normal kernel sources
1) Versioning & backporting
Syno, like many other companies, take the kernel and modify it in house. This is something which kernel devs don't really like but since it's an open-source project everyone can. However, after some time these companies realize they want new features from new kernel but cannot get them as their modifications no longer apply to a new version. What they do is "backporting". They grab their e.g. 3.10.108 which was modified to oblivion, then download the e.g. 3.19.0 and check commits which add features they want. They get that commit and apply to their 3.10.108 making it 3.10.109. This is incorrect and broken. But that't not the biggest problem.
In case you don't see it: this poses a HUGE problem for using drivers from the vanilla kernel. Often times if you take a driver from vanilla 3.10 you will realize that suddenly doesn't work at all... as in fact they previously lifted a newer one from 3.20 and stuffed it in 3.10. Good luck loading such driver and using it.
For that reason alone you CANNOT use vanilla kernel code as you don't know which version of the code has to be used. Sure, there are ways to figure this out, but the only sane approach is to use the source provided by syno. In case of small-ish bumps in kernel it's usually safe to get e.g. driver from kernel from 3.10.105 and fake the version compiling for 3.10.108 hoping not much changed.2) Drivers modification
Syno modifies in-tree drivers directly. To be honest they have no way around it as they apply vendor-specific hacks for e.g. timing bugs in certain chips. They should upstream it but... that's a different story and it's not as easy as it seems. Depending on WHAT was changed in the driver sometimes you can use kernel from a different kernel version. How do you know it's safe? Well... it's hard. If you don't have the sources for the new kernel (since if you did you wouldn't bother lifting the driver from an older version) you cannot know if the data structures changed. If they did you're pretty much toasted.
Languages like C or ASM (or hardware in general) doesn't have magical way of discovering sizes of things. Everything is based on static assignment (ok, not everything, but lets make a simplification here). This means if syno decided to add a field to a struct [it's like an object] in mpt3sas driver and that field was added to a struct used ONLY in mpt3sas driver you can probably load the old driver and be fine. However, if they added a new argument to a "public" function (function used outside of the mpt3sas driver) or a new field to a struct used externally from the mpt3sas driver things may APPEAR to work. Every time such function is called or struct is used more and more memory and/or stack gets corrupted. Eventually you will crash something very badly and you will be lucky if that was at least the driver and not something unrelated which was just in the same area. In kernel there's virtually no protections of one piece of code breaking memory of the other. There are small protection for the kernel CODE itself and some sensitive areas but it's not like in the user space where one process trying to write into memory of another process will simply be killed - in the kernel you just corrupt the memory silently.
3) Kernel <=> driver interactions
Scrolling through the questions we saw that some of you load drivers and see missing symbols. Well, this is the effect of 2). When they modify the drivers they often add their own hooks by just placing a f... gSynoFoo() call somewhere in the driver. Honestly we think it's very sloppy but it is how it is. The issue here is two-fold:- if you compile a driver from vanilla kernel you will not have these calls so things may look correctly... but these calls were placed there for a reason and other things exepect them to happen. Sometimes the issue may be really small like performance drop or hibernation not working correctly. Sometimes you may step into a data loss with a certain controller which syno fixed in their kernel after getting a possible fix from the manufacturer... you don't know.
- if you try to add e.g. SAS to a non-SAS model things break badly. This is because it's not as simple as flipping the flag in synoinfo. By doing so you're telling the DSM "this model supports SAS". But the issue here is that models which REALLY support SAS have A LOT of code which is compiled only and only when the kernel config option for SAS was enabled. This config option being disabled literally REMOVED a bunch of code from many places when they compiled the kernel without SAS support. That's also the reason why getting SATA boon on 918+ was so challenging as the SATA-DOM code is literally removed on 918+. Bottom line is don't try to activate functions which depend on the kernel features being present. You can tweak number of disks, supported number of cameras and other user-land features but not re-enable features which are partially kernel and partially userland. It's like trying to pump diesel fuel into gasoline car after drilling a larger hole to fit the bigger diesel nozzle into the tank.
There's no straightforward way to KNOW if the feature you want to activate has a kernel component. However, going through ALL options in synoconfigs/KConfig.* files will give anybody an idea what sort of things can or cannot be activated. In general anything involving in-kernel drivers is a no-no (e.g. iGPU acceleration will not work on 3615xs most likely but NVidia GPU probably will).
4) Data structures missing in toolchains for in-tree drivers
You cannot get the code of a in-tree driver and compile it against the toolchain. This is because in-kernel drivers have access to many more things and link internal kernel files. Should they? Most likely no. However, the kernel is
30 YEARS OLD codebase and only recently they started to encapsulate drivers from using internal things. In most cases it's better to stick to the hardware which is officially supported.
We have v7 sources for geminilake which we took some hints from (e.g. about synobios structures). If there's a particular driver we can look and compare with v6. However, if there's anyone who has experience with drivers (@IG-88?) we can share the archive in a PM as syno pulled it from SF. Why they did pull it? It's possible it contains code from e.g. broadcomm which is under an NDA and should never be published as it's not GPL.-
3
-
2
-
We think it should be 1 driver = 1 extension. This way you install driver for your ethernet, driver for your GPU, and a driver for your USB 3 chipset. This will also let us do another cool thing down the road: provide a small image which will boot on your hardware, scan it (essentially grab vids & pids), and suggest a platform and drivers needed to make it work. VID & PID info are embedded in the drivers on linux anyway so it's easy to extract. If you pack many drivers in one package you can easily run into conflicts and load way too much. Jun's loader loaded a ton... literally all modules. In a system with just extra.lzma to get virtio we see 178 kernel modules - mptsas, mpt2sas, mp3sas, vmxnet, megaraid... and many many more which have nothing to do with the platform.
Of course, naturally some drivers will have multiple kernel extensions as it makes no sense to separate them. For example VirtIO is technically like 5 drivers but we never saw anyone using just VirtIO-SCSI but not load VirtIO-NET. With some HBAs it may also make sense to make a bundle containing like 3 drivers for LSI cards. But definitely bundling e.g. VirtIO and LSI woudln't make sense. It's a delicate balance
Same for CPU governor: for example we don't need it at all as we either want performance on a bare metal server-server or run it under a VM. This is why we didn't want to bundle it as many folks will not use it. To be honest the concept of power management on Linux is slightly foreign for all of us as we either lazily use Dells supported by Ubuntu or run Linux on servers which don't really care about PM.
-
2
-
1
-
-
3 hours ago, haydibe said:
I noticed the cached pat files fpr apollolake are re-downloading from redpill-load's build-loader.sh, but this time the `+` character is replaced with a `p` character in the output filename. Thus `ds918+_25556.pat` became `ds918p_25556.pat`. Who ever is affected can simply replace the + in the filenames with a p and prevent the files from beeing re-downloaded again.
Additionaly I tested jumkey's apollolake-7.0.1-42218, which is not yet alligned with the recent changes in redpill-load.
I must admit, this one went over my head
I was going to check how `build-loader.sh` calls `ext-manager.sh` and then simply add an array to declare plugins in the toolchain builders global_config.json and execute the command for each element before executing the loader build.
Update: the ext-manager.sh syntax is straight forward, no need to check how build-loader.sh uses it. Though, I have to find a clever way to pass in an array, even though docker doesn't support to use arrays as environment variables.
About the change with + => p is essentially keeping with the same translation layer as in the kernel so the models are named in the exact same way (and that we don't have special characters in file paths ;)).
As for the calling in docker we were thinking about something even simpler. Since we're playing with interactive interface it will be nice if users can just run the command in the container instead of editing a file. This is why ext-manager.sh script self-manages files based on commands. So that the author of an extension can just say "just call add [URL]" and call it a day. The "extensions" in the user config is something which we normally don't expect to be used as we wrote in the docs. This is only for a case where user has some interdependent extensions (e.g. you need to load thunderbolt driver first to then load RAID enclosure driver). The bundled-exts is even rarer of an occasion - this file defines extensions which are integral parts of the loader as we want to extract the LKM into an extension to make things simpler (similarly how we extracted VirtIO).
So to give you an example how we think it can work:
$ docker run -d --name rp -t ..... $ docker exec rp extension add 'https://.....' The output of ext-manager.sh add 'https://.....' $ docker exec rp build foo bar The output of build-loader.sh foo bar $ docker exec rp extension info test_dev.test_ext The output of ext-manager.sh info test_dev.test_ext
It's actually simple - just symlink the .sh to /usr/local/bin/extension and /usr/local/bin/build. That way the docker just proxies the commands and we don't double the docs. It will also be simpler overall as we then have a unified interface. This also helps with one change which we have already planned: the add command for now accepts URLs but want it to accept URLs, names, and aliases. This way a user will be able to do "extension add trusted-dev.hp-222". As we mentioned in the previous post with time we want to also add (probably automatically) detection of VIDs & PIDs to the extensions so you will be able to essentially do "extension add fff1:fefe" and get the driver you need.
When we get something sensible (i.e. not bash) we can also help users with settings manager where they can simply do "docker exec user-set vid 1234" ... "docker exec user-set mac1 00ff....".
WDYT?
3 hours ago, svenger87 said:No luck. Also with the boot-wait plugin.
Do you have file /.no_synoboot? If so then check dmesg to diagnose WHY the synoboot is not appearing.
-
1
-
1
-
-
Hello!
TL;DR: We've developed a new loader for v6.2.4/v7+ which contains a way to install custom extensions/drivers/mods. We're looking for feedback of the extension manager & kindly asking for drivers to be made compatible with it.First of all, let us thank you guys for all the driver packages you were always preparing - we used them ourselves. As some of you may be aware we are developing a new loader called RedPill. There's a long thread in the developer's section of the forum:
Today we've added a long-awaited functionality of custom drivers. We've chosen to go with a more modular approach rather than offering a clone of Jun's loader functionality of extra.lzma archive. Our solution relies on a simple extension manager which is responsible for downloading and packing drivers automatically. This lets users install only the drivers they need while also mixing-and-matching multiple ones. With "extra.lzma" the limitation was that users either had to build their own packages or choose between having the HBA driver or VirtIO driver... that, in our opinion, was a poor experience. Additionally, the new format allows you to keep a single git repository containing both the metadata for RedPill extension manager and the build environment you use to compile drivers.
We would like to collect your opinion on the new extension manager we created and ask you to port your drivers to the new format. We prepared two documents:
- https://github.com/RedPill-TTG/redpill-load/blob/master/docs/extensions-overview.md (summary of what the extension manager is capable of and how to use it manually)
- https://github.com/RedPill-TTG/redpill-load/blob/master/docs/extensions-for-devs.md (document intended for people creating extensions/compiling drivers detailing the architecture)
In addition, we published two packages, which can serve as an example:
- https://github.com/RedPill-TTG/redpill-virtio (VirtIO driver)
- https://github.com/RedPill-TTG/redpill-boot-wait (shell-only package; this will be similar to how e.g. a CPU governor mod can be implemented)
There's currently no central way to discover packages but is it planned. For now we're simply collecting links to indexes in a separate git repo - https://github.com/RedPill-TTG/redpill-extensions - you can just toss a link there from the GitHub web UI without cloning the repo.What do you all think?
special cc @IG-88
p.s. We didn't post this in the driver's extensions subforum as this topic isn't intended for users. When some drivers are built and the official beta version of RedPill is published we will create a separate thread there.
-
6
-
8
-
- Popular Post
Did anyone said drivers?
You said you wanted drivers - we are delivering on the promise to find a way to get them to you.
Today's release brings, what we believe is, a huge update to the RedPill as a project, and we hope to the community and the ecosystem around it as a whole.
TL;DR
We're introducing a decentralized extension manager into the RedPill project which is able to automate drivers installation. If you're a user, and we didn't screw up badly, just update to the newest release and nothing should change just yet. Soon you can expect your custom drivers to be added with a single command.
Wait, did you just built... a package manager?!
Yes, yes we did. In short after reviewing multiple solutions like ipkg nothing fit the bill with what we actually needed. The distribution of drivers and shell hacks is a pretty unique use-case. We needed to make it work in the minimal initramfs environment. It is not as crazy as it may sound, but the planning for that move was ongoing for quite some time. We mentioned it here and there in passing, that was part of the reason why we discouraged from just blindly stuffing drivers into the core ramdisk and hacking the scripts as we sort of knew what's coming soon However, as you probably realized by now we try to underpromise to avoid disappointment.
Lessons learned from the history & other projects
Previously used loader by the community (Jun's loader) used a system of a single ramdisk-like "extra.lzma" archive. This method, while worked, lacked flexibility and required hand-assembly by the packers. As we observed this lead to multiple versions of the whole loader image floating around - some with VirtIO, some with ethernet drivers, some with SAS HBA drivers, some with VirtIO **and** SAS HBA... Additionally, while reporting problems on the forum people usually reported whether they "used extra.lzma" which without the context was limited in information. In addition, to add extra functionality beyond kernel modules, a custom hacks had to be developed.The extension management shipping with the "redpill-load" hopes to alleviate the pain of packing and managing all extensions and mods. During the design process we took inspiration from both the Xpenology and Hackintosh communities, attempting to bring what's best. We set the following objectives while developing the current version:
-
as simple and as automated as possible for users
- in practice users need only a single "add" command and a URL to add an extension
- updates are checked any time a user builds a new image
- updates are offered not only on per-platform basis but extension can be updated for the currently existing platform (however, this still requires image rebuilt)
- if no interdependent extensions are installed users don't need to do a thing as by default all added extensions are added to the image
- no more manually sharing zips over Mega or in attachments needed
-
easy for developers/packers
- the most basic extension requires 3 files: index file, recipe file, and the file which is delivered
- JSON configs were organized such that it's easy to maintain a repo with multiple versions of them (more on that in the documentation for developers - see below for a separate thread)
- the structure is designed for maximum reusability and extension
-
error-proof
- most errors are meant to be self-fixable (even if user caused them)
- when an error is displayed it tries to offer a reason and a possible way to fix it (like in `git`)
- all extensions offer multiple links pointing users to the correct place (do they have a problem with USING the extension? or maybe they have a problem with it being unstable? or maybe they want to see the forum thread where they can ask the author questions? => it's all supported)
- the code will prevent users from creating an image with a newer version of OS if extensions they rely on are not updated (as what's the point of updating to a new OS release if your ethernet driver doesn't work yet?)
-
flexible in nature
- at first, we jotted the idea as delivering kernel extensions/drivers, but we quickly realized it's not enough
- the current (early) version allows for pretty much any customization of the OS before it's booted with custom scripts (e.g. changing CPU governor)
- current implementation is more a PoC (that's why it's a messy shell script monstrosity), but with feedback can be eventually built to a much higher standard; more on that below
-
decentralized
- we don't want to exert any control or force anyone to do anything: this is our goal from the beginning
- the extension manager is designed to be not only open-source but open in nature. We deliberately don't offer any centralized repository and simply rely on community and the trust within it to offer a quality contribution
- the system is fully anonymous: we don't collect any statistics, nothing is sent to any of endpoints controlled by us
We need the community support!
This is a calling for developers & packers which normally provided drivers in the extra.lzma format to also consider providing drivers in a form of RedPill extensions. We hope we don't ask too much here but we know without your support and hard work plenty of things would never be possible. We certainly don't have the manpower to provide drivers for all network cards, HBAs, GPUs and other things people use.
To filter-out the noise we created a separate thread to discuss the extensions manager and get suggestions from the developers itself:We created a separate thread to let people compiling drivers & preparing hacks get notifications of a lesser volume than here.
Currently available packages
As a proof-of-concept we didn't create just a throwaway example extension which isn't actually usable. Instead, we extracted the VirtIO driver into a package: https://github.com/RedPill-TTG/redpill-virtio
In addition, we added a small new package which is shell-only (hint: someone can easily base the CPU governor package on it ;)) which blocks the boot process until /dev/synoboot is ready and is more useful in leaving a log as this seems to be one of the most popular problem users are facing. See https://github.com/RedPill-TTG/redpill-boot-wait for details.Both packages mentioned above are autoinstalled. In the future the VirtIO package will be optional (as it does nothing on e.g. ESXi or bare metal).
The RedPill LKM will be an extension itself in some time as well (but for now we didn't want to break the @haydibe docker and forking scenarios until we have a good solution for that).
The future
The current extension manager is conceptually an MVP and can be used. It provides the basic functionality expected from a package manager and delivers the most important thing: drivers. However, this is definitely not its final form. Our goal now was to get it to the usable state and ensure the format of packages will not need to be changed (putting burden on people providing drivers) but rather enhanced as needed.-
The current biggest hurdle is the fact the package manager is written in bash, along with the loader generator.
- We're already prototyping a much better solution
- The end goal is to have a user simply start a docker image on any OS (whether it's Linux, macOS, Windows, or... DSM itself) with a single command and get a web interface where the loader can be generated, updated, and customized (similarly to how you do in the Hackintosh community).
-
Packages discoverability
- While the packages are (and will be) decentralized we are already thinking about a better discoverability of packages
- Ideally we want to model a [much simpler yet similar] system to npmjs or packagist but server straight from a github repository anonymously and safely
- Discoverability will let us provide a small bootable image which can simply scan the hardware and tell you which packages you need and if maybe some hardware is not supported at all
-
Currently we're simply collecting links to indexes - https://github.com/RedPill-TTG/redpill-extensions - some form of static generator with a list will come later
So, what do you guys think?
//parts of this post were incorporated into the documentation in the redpill-load repository - if you're reading this after some time it's better if you head to the repository directly and see the documentation there as things probably have changed: https://github.com/RedPill-TTG/redpill-load
=========================Yes, we promised to respond to all the posts - we will
That last week was unusually busy - we will try to be better about that.
=========================
Note to @haydibe: we tried not to break the docker toolchain - can you triple-test?
We also left a separate env variable called MRP_SRC_NAME which is used instead of "./ext-manager.sh" when displaying any help/error messages in the extension manager. You may want to replace it with docker command so users aren't confused.
-
4
-
19
-
- Popular Post
Update time! 💊
This week the updates are going to be less exciting but nonetheless very important, and the first point talks about that in more details.
THE BUILD HAS CHANGED - READ ME
We're putting this as the first and in red so people see it. The LKM build now requires a version to be specified. We know this will break the @haydibe toolchain but we're sure he will fix it quickly as this is a small change. For reasons why read further.Also, if you used a hack to "fix" the Info Center on 3515xs make sure to read "Hardware monitoring emulation" section carefully.
A roadmap
Lets first address why this week is less exciting: we spent most of the time testing various scenarios and tracking hidden-yet-missed bugs. This is most likely the second to last round of updates before we release a beta version. The beta version can be used in a day-to-day testing and should be free of dangerous crashes (ok, maybe except that strange kernel lookup - we're looking into it). In the beta some features may still be missing but overall we're already testing a few instances and it's looking good
We don't have an official roadmap as someone here asked. However, this is the rough list of things we want to address in that order:
- Custom drivers support*: there's a hack discussed here to add drivers to a ramdisk. However, this isn't a sustainable solution for many reasons. Mainly the reason is a very limited size. The current ramdisk, especially on systems without compression, is almost at the limit and on slower systems can crash with even a few megabytes more added to it. This seems to be especially unstable on v7 Linux v4 kernel. The solution we're working on will simply include modules on the partition which are loaded in pre-boot and copied to the main OS partition on boot. Naturally from the perspective of the user it will involve simply adding a line to user_conf and dropping a file in "custom". For people digging deeper it will be also much easier as this involves no repacking: simply mount the partition and drop more files in and they will be copied 1:1 and loaded as needed.
- Full SAS support*: while cheap HBA cards are great and something we actually will recommend for home builds (as they're cheap, stable, and offer 4-6 ports), LSI is king for bigger arrays. We want to make sure these are working as intended making both DSM and Linux happy (which isn't easy in v7 ;)).
- UEFI support*: there are board which cannot boot in legacy mode. We want to fully test this and offer an official UEFI support in the RedPill.
- Add support for newest revisions of the OS to 918+ and 3615xs*
-
Step-by-step instruction*/**: essentially we want you guys to help us test not only the code but also a guide It will be published alongisde the beta version. We will prepare it in a form of a GH page so that we can easily incorporate feedback (as we cannot edit posts after ~1h). After we resolve problems with it we will go ahead and publish an RC version on the main forum so that it becomes an official version released for usage by less experienced folks who still want to poke around the OS.
- Integrate build process into the main repository**: @haydibe is doing an AMAZING job here and we cannot thank him enough. As we discussed with him before we want to incorporate the docker directly into the redpill-load repo and enable LKM builds on GH, so that everything is automated and synchronized as soon as we publish an update.
- Small fixes: add native support for CPU governor, fix CPU detection to match the model (as some things on v7 react strangely if the CPU doesn't match the model), fix various internal code-smells in the kernel code
- Add support for GPU acceleration: in short we want to explore adding platform like DVA3221
-
AMD support: let's just say we aren't fans of Intel recently We want to add a model which natively supports AMD CPUs
- Work on making mfgBIOS LEDs/buzzers/hwmon stuff more real or at least publish an interface which can be used by others to add an arduino or similar.
Things marked with * are aimed to be done by the beta release. Things marked with ** we are HOPING to get done before the beta but we cannot promise
Fixed I/O scheduler not found errors
Many people reported these, and we finally found some time to look at them. Fixing them should fix the disk scheduling and improve performance in some scenarios. All in all you shouldn't ever see them from now on.Commit: https://github.com/RedPill-TTG/redpill-lkm/commit/aaa5847c589b84783471f9a600eeb12fbf2dc31c
Hardware monitoring emulation
One of the big features boosted by syno in v7 is central monitoring. However, with that it looks like in v7 the hardware monitoring and things around that has changed a lot from v6. In short v6 allowed for things being out of whack here and there with the hardware sensors while v7 assumes all sensors are in order... and when they're not things break unexpectedly. For example that bug with General tab not loading in Info Center was just a tip of an iceberg. It was just a symptom of a MUCH MUCH bigger issue. If you do "cat /run/hwmon/*" on a DSM loaded with Jun's loader you will get:# cat /run/hwmon/* { "CPU_Temperature": { } }
This isn't going to fly on v7. The Info Center is just the beginning of problems. High scemd usage at times was also caused by the lack of hwmon emulation (which again, wasn't strictly needed on v6). After painstakingly analyzing the synobios.h from the kernel and toolchains while also scratching our heads at how one of the drivers for ADT chip (fan controller on a real DS) was modified we think we've nailed it:
# cat /run/hwmon/* { "CPU_Temperature": { "CPU_0": "61", "CPU_1": "61" } } { "System_Fan_Speed_RPM": { "fan1_rpm": "997", "fan2_rpm": "986" } } { "System_Thermal_Sensor": { "Remote1": "34", "Local": "32", "Remote2": "34" } } { "System_Voltage_Sensor": { "VCC": "11787", "VPP": "1014", "V33": "3418", "V5": "5161", "V12": "11721" } }
The output above comes from a 3615xs instance. On 918+ you will see only CPU_Temperature and hdd backplane status as physically 918+ does not monitor anything else. You can read more about that in the new document in the research repo: https://github.com/RedPill-TTG/dsm-research/blob/master/quirks/hwmon.md
All values above are fully emulated as on a VM we have no way of reading them and on a real hardware the only standardized one which we can pass along is the CPU temp (as voltages and thermal sensors vary widely between motherboards). We have a "todo" to make CPU temperature real on bare metal.The ugly part, which forced us to change the LKM build to require major version of the OS to be specified, is that syno changed so many things between v6 and v7 that they forgot to make proper headers. As you can see in the https://github.com/RedPill-TTG/dsm-research/blob/master/quirks/mfgbios.md document they just like that moved two fields in the middle of the struct. You never ever do that. Not without at least some ifdef (which they did for other things). The issue is that change we've found is not present in all toolchains, it's not documented anywhere and we discovered it by accident by comparing files. There's really no sane way to detect that (we've tried really hard). This is why we were forced to add (ugly) requirement for v6/v7 to be specified while building the kernel module. If we find a saner way we will go back and make it automatic again.
With the hwmon being emulated there are two VERY important things:
- you CANNOT disable "supportsystemperature" and "supportsystempwarning"! The hack someone posted here with sed - https://gist.github.com/Izumiko/26b8f221af16b99ddad0bdffa90d4329 - should NOT be used. We cannot stress this enough. Anyone who used it and keeps the installation MUST put "supportsystemperature: yes" and "supportsystempwarning: yes" into user_config at least for a single boot. This is because these values (with =no) are now baked into your OS partition and you MUST fix them to the default "yes". As the loader script doesn't have them specified anywhere it will not touch them anymore.
- you CANNOT disable ADT support. This comes back way to the Jun's loader and deleting "supportadt7490" on 3615xs. If you're not installing from scratch on a new disk but playing with the same on you MUST put "supportadt7490: yes" to your user_config at least for one boot.
Commits:
- https://github.com/RedPill-TTG/redpill-lkm/commit/72cb5c3620711bcabcfe6e1c67ebfbeca6f7e6bf (mfgBIOS structures v6/v7 changes)
- https://github.com/RedPill-TTG/redpill-lkm/commit/16adab519d6c4cc604e3fb680fb041e8ddd2167e (HWMON definitions)
- https://github.com/RedPill-TTG/redpill-lkm/commit/7d95ce2ec7d35493227196be58bbd2c7ca2704f8 (HW capabilities emulation)
- https://github.com/RedPill-TTG/redpill-lkm/commit/014f70e7127abdf28b47fe58f35086296b5d78ca (HWMON emulation)
- https://github.com/RedPill-TTG/redpill-load/commit/78c7bf9f903a73d51013a859f590c09ee835f8e7 (remove legacy ADT hack)
Fix RTC power-on bug
On 918+ the scemd complained about auto power-on setting failing. Now this is fixed and scemd no longer triggers an internal error state. This was happening when OS was sending an empty schedule.Commit: https://github.com/RedPill-TTG/redpill-lkm/commit/80a2879aae23d611228c8791b35e237bfa0ec7a8
Add support for emulated SMART log directory
This is an internal change in the SMART emulation layer. Syno uses slightly out-of-spec approach (again, hello v7 mess) and assumes all disks implement one of the ATAPI functionalities which is actually optional. This may actually cause some real disks to fail as well on a real v7 so they will probably eventually fix it themselves. For the time being we did it in RP.Commit: https://github.com/RedPill-TTG/redpill-lkm/commit/278ee99a4dcb8fb8f025915118e7df93824e9bfc
------------------------------------------------------------------------
Today's update is rather short as HWMON layer took us a ton of time to properly research and figure out how to actually do it. There were literally 5 different implementation until we got it right. That being said the forum deleted our responses to comments which we were typing here so we will write them again... but probably tomorrow morning. We will try to sit together tomorrow morning (ok, developer's morning ;)) and write responses again.
@WiteWulf Can you try deleting the line with "register_pmu_shim" from redpill_main.c (in init_(void) function) and rebuilding the kernel module? You can then use inject_rp_ko.sh (lkm repo) script to inject it into an existing loader image or rebuild the image. With that you shouldn't have PMU emulation anymore (so the instance can be killed in ~24-48h) but we can see if it's kernel panicking.
-
11
-
13
-
New release update! 💊
This is the biggest release to date and ESXi users will be especially happy to see it!
SATA boot support for 918+ (and others)
Remember how we said it's nearly impossible to add SATA boot support for 918+ as the kernel physically lacks the code to support SATA DOM on that platform? Well, we've said NEARLY impossible as we had an idea but didn't want to disappoint anyone if it failed. It didn't.With this release we're introducing a SATA boot support for platforms which natively lack the support for it. This is mainly aimed towards hypervisors without emulated USB support (looking at you ESXi). How it works is rather crazy: we're taking the SATA drive and masking it as a USB drive just for a short while to fool the SCSI driver into giving the drive a correct type (but not long enough to cause problem with reading the data). We weren't sure if this can even work or how good it will work. It turns out it does work, and it looks to be stable.
However, due to the nature of this code we're only recommending (at least for now) using it when there's no other way to boot. A physical USB flash drive passed through to a VM will be a better choice. Keep in mind this does not apply to native SATA DOM (e.g. on 3615) - this one is as stable, if not even more, than USB. You can easily distinguish which mode is used by looking at boot parameter "synoboot_satadom": native DOM will be synoboot_satadom=1 while this emulated one will be enabled with "synoboot_satadom=2". Technically you can actually use this emulated mode on platforms supporting native SATA DOM (not that there's a reason).
For details see the following commits:
- https://github.com/RedPill-TTG/redpill-lkm/commit/de5099c01564e5193860f51f448702d2fa165df5 (main module code)
- https://github.com/RedPill-TTG/redpill-lkm/commit/1a3039f3b030b4351b23ba4e909e6232d9a58228 (refactored SATA DOM shim)
- https://github.com/RedPill-TTG/redpill-lkm/commit/061b3e643d4bca663f24fb3dee397ecb77d8e44c (naming change to avoid confussion)
- https://github.com/RedPill-TTG/redpill-load/commit/15feb4b6e8651d77be19d18b936e8aba780520ab (redpill load support for SATA on 918+)
Disk SMART emulator
One of the biggest issues reported was the inability to create pools on ESXi (or any VMWare products). This bug was traced on GH as well: https://github.com/RedPill-TTG/redpill-lkm/issues/14 . There were multiple theories and the community stepped up and came up with workarounds. However, this state wasn't sustainable for a long time so we went digging.Oh boy. v7 made a lot of changes in how disks are handled. One of the biggest changes is that now all drives used by the system in pools must support SMART (and actually multiple parts of it). Without that things will break horribly, even if a workaround is used to create a pool. The pools creation worked on Proxmox only because QEmu actually emulates a minimal (but sufficient for basic operation) SMART support for all its virtual drives.
With this release we implemented a full-blown emulated support for SMART on any drive which doesn't support it. The module makes everything glow green and report no problems. Even the health tab and automatic SMART tests will not cause any problems and appear as they were really executed. Obviously the emulated SMART has no diagnostic value and the drive should be monitored externally. The SMART emulation goes beyond being useful under ESXi. We've identified three main scenarios where the SMART data is/can be missing:
- running under ESXi (it doesn't support SMART at all)
- running VirtIO disks connected to SCSI ports (see below)
- using RAID cards which don't work in a real HBA mode
With the commit https://github.com/RedPill-TTG/redpill-lkm/commit/d032ac48c00f78b11516f2f2112970bc51bf68be out of the way we can officially confirm full support for ESXi. We didn't close the issue on GH yet awaiting feedback.
Added support for SCSI VirtIO
..and there's more disk updates in this release!Proxmox (and all other VirtIO-enabled hypervisors like QEmu, libvirt [used in e.g. unRAID], or VirtualBox) allow the drives to be passed as either SATA or SCSI. There are technical differences between them. However, the main one while actually using it is that you can add up to 6 SATA devices (0-5) while SCSI allows for up to 31 (0-30).
This release adds the support for VirtIO SCSI drives. This includes SMART emulation described above as well, as QEmu doesn't provide SMART for non-SATA devices. As SATA devices ultimately use SCSI protocol and share the vast majority of the protocol we simply convince the OS to treat VirtIO SCSI drives as they were SATA. This isn't really a hack. The official syno kernel does the same thing BUT only for "NEXTKVMX64" platform (VDSM?). We simply retrofitted that feature to work on all platforms. You can also use an SCSI drive for booting and mix SATA & SCSI disks as well.
The core functionality can be found in the commit: https://github.com/RedPill-TTG/redpill-lkm/commit/2ce06db3ef69b6ea28c49754c101fd0832abec04
SCSI drives monitoring subsystem
This is more of a dev-only functionality, but lies in the core of all the features described above. In short, Linux kernel contains a mechanism for publishing and subscribing to events. Unfortunately it's a rather new and niche subsystem. The SCSI driver, as one of the oldest parts of the Linux kernel, doesn't support the notifications. In order to react to new drives being connected to the system we developed an extension for the SCSI driver adding that functionality. We will probably pursue upstreaming of these changes, so one day they can land in the kernel natively.For details see the following commits:
- https://github.com/RedPill-TTG/redpill-lkm/commit/098bae23fe21ccd495e57b846539704899fda639 (add the notification subsystem)
- https://github.com/RedPill-TTG/redpill-lkm/commit/ccc58c0883c3f0cc8a8599918cc0d5cd9491f678 (extract common SCSI functionality to a submodule)
Multiple build modes & hiding from the system
The previous version of the module was always built in the dev mode. In addition to being heavy at whooping 4MB, due to the debugging information included, it also contained extensive logging and multiple exported symbols. With this release made substantial progress in hiding the module from the OS.Now the module can be built in three different modes:
- dev: all debug symbols are included, standard debug messages are printed. This is essentially the current mode as it is. It's still the default one when running make without parameters
- test: module is stripped from debug symbols and displays only warnings, errors, critical and BUG messages. This means the output is significantly reduced while still allowing to catch problems occurring. This is the recommended mode to run on test installations. However, when reporting bugs we will prefer to get the output from the dev build as it contains much more information of what lead to the bug.
- prod: module is fully stripped from debug symbols, contains absolutely no logging, and in addition it makes an effort to hide itself from the OS. It will not be visible in the lsmod, it will not publish its symbols in /proc/kallsyms and once loaded it cannot be unloaded. If it crashes in this state the stack trace will point to an anonymous kernel address rather than to a loaded module.
For details see the following commits:
- https://github.com/RedPill-TTG/redpill-lkm/commit/960ade5ea759105954afa5fcb0bfc15e31e51656 (logging is stealth-dependent)
- https://github.com/RedPill-TTG/redpill-lkm/commit/41f11eee29191bea475120e94dae9a5938592e23 (hide module in stealth mode)
- https://github.com/RedPill-TTG/redpill-lkm/commit/5da6629cc5afad983a9d31a041c109cae4c705ea (raw printing disabled in stealth)
- https://github.com/RedPill-TTG/redpill-lkm/commit/04865d444f4cb79877f4527ba3e757583a5634a6 (multiple build modes)
- https://github.com/RedPill-TTG/redpill-lkm/commit/690c92ab60321e12ad9024a6b91b2c8ce29b19e0 (remove identifying information from module file)
Why the correct compiler is so important?
We had a discussion here some time ago about using different GCC versions and playing with different configurations. We've got a tangible example now, which made our blood boil for a good whole day. The code which is native to the kernel triggered a bug in the GCC itself: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=63567In short this problem wasn't present in earlier versions of the GCC, but it is affecting GCC >4 and <5. This is a serious problem as the module is written with C99 in mind and the bug occurs when code is compiled in any mode besides C89. Well, normally you would upgrade your GCC. However, Linux <3.18 will NOT compile even with GCC 5.0 - the absolute latest one is 4.9.x.
The workaround we've used was to extract the offending piece of code to a separate compilation unit compiled in C89 mode where rest of the code is still being compiled in [sane] C99 mode.We're leaving this story as a warning how compiler version can have big effects on even code which is written in a clean manner. In the C world, despite so many years of advancements, there are still monsters in the closet like that
--------------------------------------------------------------------------------------------------------
Assorted smaller changes & fixes we've made:
Fix RTC scheduling crash
When auto power-on scheduling was modified in any way the action triggered on platforms with no native RTC support (e.g. 918+) was causing a soft-crash in the RTC proxy. It was reported in https://github.com/RedPill-TTG/redpill-lkm/issues/17 and fixed in https://github.com/RedPill-TTG/redpill-lkm/commit/29637db757d8ad0240e161136db814d5bfd31c33Fix SATA DOM shimming on older HDDs
Some older HDDs (and possibly some real SATA DOMs) don't implement so-called CAP16 command used to query the capacity. Due to a bug in our capacity estimation code the CAP10 fallback wasn't triggered for disks without CAP16 support. Now this is fixed and capacity should be detected for all drives properly.
Related commit: https://github.com/RedPill-TTG/redpill-lkm/commit/524690549cb7cad96de50cc350a9e13f520f53faFix execve() debugging crashes
Did you know that Linux launches few thousand binaries every time it boots? We didn't either. Enabling (a very noisy yet helpful) execve() debug mode caused some crashes. It was really about edge cases in arguments parsing. As we are working with the code remembering the Linux code from 1992 some things slip through the cracks. With the commit https://github.com/RedPill-TTG/redpill-lkm/commit/1a6665bc71f7a73b02a3c150aad746d359caf9a4 the debugger shouldn't cause crashes. If you experience it let us know via an issue.GCC warnings are now gone
To avoid confession (which was reported here and on GH) while making the code overall better we went ahead and fixed all GCC warnings. One of the main ones was the validate_nets cropping up on all platforms: https://github.com/RedPill-TTG/redpill-lkm/commit/0a91024b5ed4e51382015d098f0c4ed04417700fTransition to new override symbol is complete
As mentioned in the previous post new, more stable and faster, override symbol logic has been implemented. Now it's used across the board. Old method has been completely removed. In the process we've also found a rare set of circumstances where the override could fail completely and crash the kernel. This has been fix as well.For details see the following commits:
- https://github.com/RedPill-TTG/redpill-lkm/commit/bca616c134b6ad95f92b0caf6ff2481356c5cbc7
- https://github.com/RedPill-TTG/redpill-lkm/commit/b08f6a8c932abce00349ff4e152593be1072b565
- https://github.com/RedPill-TTG/redpill-lkm/commit/479d0050e6a0aad33b7aed54f53a244ae00ff244
- https://github.com/RedPill-TTG/redpill-lkm/commit/9ed56540fd2cdf7d0be531709810cde3ab07fea1
More consistent logging
To make debugging & reporting from users easier we unified how each shim/submodule reports its state. This also serves as a general clean-up of these logs.For details see the following commits:
- https://github.com/RedPill-TTG/redpill-lkm/commit/c110c8baf11b1e286f3ba9501d10ed63f7c2e5b1
- https://github.com/RedPill-TTG/redpill-lkm/commit/4b164c3500ecfd82e9480e67327e66a0b38be1c0
- https://github.com/RedPill-TTG/redpill-lkm/commit/8154a28872a9e3fca3ef9b985bc5a9f07e3d5f94
- https://github.com/RedPill-TTG/redpill-lkm/commit/e42a0e6c3beebf0d8da71cef42e0db1001927deb
Build env. improvements
- We've validated and enabled concurrent build for the LKM. Concurrent builds speed up the build times of the kernel module drastically. Commit: https://github.com/RedPill-TTG/redpill-lkm/commit/363f6d4d6459f05f7b49c0e72c8e4e3dddf5690e
- VMDKs are build in addition to raw images in the mass build script, see: https://github.com/RedPill-TTG/redpill-load/commit/24894ae306648353e71214839e0aac8317e05816 - the only issue here is that these VMDKs doesn't seem to be recognized natively by ESXi (at least not 7.0.2) and require one extra command on the ESXi itself. If anyone knows the solution working on Linux we will be glad to hear it. Due to the closed-source nature of ESXi we have no idea why ESXi dislikes perfectly valid VMDKs here. Oddly enough they work perfectly in other VMWare products. Go figure.
- The attach/mount race condition which randomly cropped up for some people (e.g. https://github.com/RedPill-TTG/redpill-load/issues/10 ) started happening on one of our member's machines as well. The underlying issue is simply the timing: losetup on linux does NOT wait for the partitions scan, so it's possible that the mount command executes after /dev/loopX has been created but before the kernel had a chance to scan partitions. This issue, funny enough, usually happens when listening to music in Spotify. The fix was dead-simple: https://github.com/RedPill-TTG/redpill-load/commit/cecf8416ee0219f534b976e0879bf7e2923827f7
- CLion should be happy again with the code - we've fixed special UAPI include path (https://github.com/RedPill-TTG/redpill-lkm/commit/4b5905039815647508ae7e0305715f1b0bfff923 ) as well as duplicated defs (https://github.com/RedPill-TTG/redpill-lkm/commit/8347a4116217191e31711e72d7d849464e348064 )
-
15
-
This post contains responses to questions from mid-page 47 only and was split due to forum's limitations. To see release updates jump to a post on the bottom of page 55:
----------------------------------------------
On 9/9/2021 at 3:46 AM, djvas335 said:Check post from pocopico on page 41 on how to compile
Link to kernel sources
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/snapshot/linux-3.10.108.tar.gz
DO NOT use vanilla kernel sources to build modules for the DSM unless you know what you're getting into. We cannot stop you of course but you should know it's like playing with fire over a tank of gasoline.
Let us explain. Syno, despite the version number attached in the kernel, modifies source heavily. So their 4.4.123 can be anything. They back port a lot of things, they break the ABI by modifying structs in the middle etc... original/vanilla kernel sources are mostly useless in dealing with DSM. Building a module against them and loading it is like playing a russian roulette - it may work sometimes but you never know what's going to happen tomorrow. This is especially crazy if you try to build your HBA driver (i.e. you're trusting your data to a driver built with incompatible sources... one shifted struct and you can lose all your data on all disks pretty easily).
If you wanna play with something not important like network card and you check the kernel source for that module in the previous syno GPL releases and confirm it wasn't modified you can try. But again, this is a very risky endeavour.
On 9/9/2021 at 5:34 AM, pocopico said:Just for testing purposes, It looks that it is possible to install 918+ 7.0.1 in vmware. Steps include linking the detected SATA loader to /dev/synoboot like that :
# ln -s /dev/sdXX /dev/synoboot
# ln -s /dev/sdXX1 /dev/synoboot1
# ln -s /dev/sdXX2 /dev/synoboot2
# ln -s /dev/sdXX3 /dev/synoboot3
where sdXX is your loader vmdk disk whose disk name can be found running :
# fdisk -l
Once you have it installed there will be no need to fake it again as md raid devices are discovered and mounted during boot and are not related to the loader. Anyway you may relink using the same commands.
*** edit : you need to relink after boot, I will do some more testing
Again, wait for developers to release a final version before installing on your production systems.
This is an old hack which should never be used for v7. New version of the RP solves the problem on ESXi. This hack is a very very very bad idea on v7. There are some new self-destruction routines which check that. DO NOT symlink synoboot, DO NOT use mknod to fake it. This MUST be done through the kernel. You can ignore all warnings we made but please, don't ignore this one.
On 9/9/2021 at 6:59 AM, hannibal1969 said:Anybody has a step by step tutorial? Found it very clear instructions.
The link you posted is actually a quite good summary for macOS
On 9/9/2021 at 10:36 AM, Franks4fingers said:I am still plagued with the issue of hitting 56% and then the install bombing out with the error message of:
Failed to Install DSM.
Failed to install the file. The file is probably corrupted.
I have tried a different USB key and changed over the PID and VID accordingly to see if that made a difference but no joy.
Does it make a difference if I choose UEFI boot or Legacy Boot within the BIOS?
Are there any other specific BIOS settings that could be causing the continual failure and could be worth changing?
When I now try the install it comes up with my original NAS being migratable which I presume is due to finding a partial install from the failures at 55%. This particular desktop machine that I am using as a test bed doesn't have anything installed already so I am trying to do a brand new clean install using the DSM 7.01RC from the Synology DL Center. I will wipe the partition on the HDD so it looks like a new disk and try again.
Any pointers would be appreciated as this is doing my melon in.
Cheers
You should use BIOS boot rather than EFI if possible. Also, 7.0.1 is not supported yet. Check the log over serial console. For the PAT they're always left in cache folder so you don't need to re-download them from syno.
On 9/9/2021 at 10:52 AM, ghtester said:'they should' is absolute correct but they don't care much about it for years... They'll do it sometimes but it'll take some (and usually a quite long) time...
...and this is painful. They ignore GPL left and right. They recently posted sources for v7.... and pulled them after like an hour. There's a question posted on their forum on SF and they're not responding.
On 9/9/2021 at 1:02 PM, dogbig said:Faces cannot be enabled
Are any files missing?Faces detection isn't working as it requires a REAL serial number (or someone to patch the new binary, this is outside of the scope of the loader).
On 9/9/2021 at 1:16 PM, Franks4fingers said:Using putty I am able to telnet to the diskstation and I am prompted for a username and password.
Anyone know what the default is for telnet?
Login is always root:[empty password] for preboot environment. Later on when the system boots this obviously doesn't work for security reasons.
On 9/9/2021 at 5:34 PM, MastaG said:That didn't work for me.
I believe it's something like this:
mkdir rd cd rd xz -dc < ../rd.gz | cpio -idmv (add drivers) find . 2>/dev/null | cpio -o -c -R root:root | xz -9 --format=lzma > ../rd.new.gz cd ../ rm -Rf rd mv rd.gz rd.old.gz mv rd.new.gz rd.gzStill I can't seem to get any network interfaces.
Also the tg3.ko and libphy.ko where not inside the rd.gz archive.. while I did add it to the config.json file...
The iLO VSP console only print up to the point where it says:
[ 2.167768] <redpill/uart_swapper.c:428> ### LAST MESSAGE BEFORE SWAP ON "OLD" PORT ttyS1<=>ttyS0
From that point on I'm blind...
The format of packing depends on the version. Check dsm-research repo under ramdisk document as syno broke the kernel. In general, the rd.gz shouldn't be tinkered with manually without proper knowledge.
On 9/9/2021 at 10:29 PM, flyride said:That is what FixSynoboot is intended to correct (and does exactly what you show above)
https://xpenology.com/forum/topic/28183-running-623-on-esxi-synoboot-is-broken-fix-available/
Synoboot devices are not required after install, until you want to do an upgrade. The loader storage is always modified by an upgrade. I realize that is getting ahead of things with regard to RedPill, but that's how it works.
As we mentioned above FixSynoboot is not part of the RP for a good reason. Synoboot is actually being checked in v7 after DSM is booted.
On 9/10/2021 at 2:58 AM, ct85msi said:Found a bug, when I run the integrated benchmark tool on any disk, from Storage Manager, the raid array is corrupted. The benchmark never finishes and when I stop it, the array will resync.
20253.145546] md_error: sdd2 is being to be set faulty [20253.145836] raid1: Disk failure on sdd2, disabling device. Operation continuing on 3 devices [20253.182475] RAID1 conf printout: [20253.182659] --- wd:3 rd:16 [20253.182815] disk 0, wo:0, o:1, dev:sda2 [20253.183027] disk 1, wo:0, o:1, dev:sdb2 [20253.183239] disk 2, wo:0, o:1, dev:sdc2 [20253.183466] disk 3, wo:1, o:0, dev:sdd2 [20253.188464] RAID1 conf printout: [20253.188648] --- wd:3 rd:16 [20253.188804] disk 0, wo:0, o:1, dev:sda2 [20253.189016] disk 1, wo:0, o:1, dev:sdb2 [20253.189227] disk 2, wo:0, o:1, dev:sdc2 [20254.150881] md: unbind<sdd2> [20254.161450] md: export_rdev(sdd2) [21149.167214] md: bind<sdd2> [21149.196351] RAID1 conf printout: [21149.196559] --- wd:3 rd:16 [21149.196714] disk 0, wo:0, o:1, dev:sda2 [21149.196925] disk 1, wo:0, o:1, dev:sdb2 [21149.197136] disk 2, wo:0, o:1, dev:sdc2 [21149.197347] disk 3, wo:1, o:1, dev:sdd2 [21149.197912] md: md1: current auto_remap = 0 [21149.198229] md: recovery of RAID array md1 [21149.198487] md: minimum _guaranteed_ speed: 10000 KB/sec/disk. [21149.198804] md: using maximum available idle IO bandwidth (but not more than 600000 KB/sec) for recovery. [21149.199308] md: using 128k window, over a total of 2097088k. [21229.131072] perf interrupt took too long (2510 > 2500), lowering kernel.perf_event_max_sample_rate to 50000 [21232.348680] md: md1: recovery done. [21232.363216] md: md1: current auto_remap = 0 [21232.396664] RAID1 conf printout: [21232.396863] --- wd:4 rd:16 [21232.397018] disk 0, wo:0, o:1, dev:sda2 [21232.397229] disk 1, wo:0, o:1, dev:sdb2 [21232.397440] disk 2, wo:0, o:1, dev:sdc2 [21232.397691] disk 3, wo:0, o:1, dev:sdd2
Are there any other errors during the benchmark? In dmesg or /var/log/messages?
On 9/10/2021 at 3:01 AM, jhoughten said:Also, it seems like the maxdrives and internalportcfg settings in /etc/synoinfo.conf keep reverting to their original settings.
I have made the change in /etc/synoinfo.conf and /etc.defaults/synoinfo.conf.
The usbportcfg setting is retained, but the others revert back to maxdrives=16 and internalportcfg=0xffff
You should not edit these files by hand... user_config.json contains a provisioning for this and the documentation explains why you cannot edit these files like that (TL;DR: dsm overrides them and they need to be fixed on every reboot, it is done automatically by RP).
On 9/10/2021 at 3:03 AM, flyride said:I believe Jun's loader patches these on each boot. This may need to be added to RedPill.
Small correction: RedPill supports it from the beginning - it is described in the documentation in the redpill-load repository.
On 9/10/2021 at 6:30 AM, flyride said:SataPortMap, DiskIdxMap, etc are not in /etc/synoinfo.conf, it's part of options passed to the Linux kernel via grub, i.e. it's just assembling the argument string from the options you provide. I don't think that particular RedPill provisioning option will help with /etc/synoinfo.conf parameters.
Just to be clear, /etc.defaults/synoinfo.conf is copied to /etc/synoinfo.conf each boot. And some of the /etc.defaults/synoinfo.conf parameters are "reset" by DSM on upgrades or on each boot, hence the Jun loader patch.
Again, this is also supported and documented. It's the "extra_cmdline" parameter in user_config.json which ensures options are placed in all kernel boot cmdlines/params and if needed override some default ones etc.
On 9/10/2021 at 7:06 AM, flyride said:Got it, so maybe it does actually modify the DSM file... I didn't look that closely before.
Unlikely that maxdisks=32 will work and will probably be overridden by DSM as it starts. I think 24 is the practical maximum.
To our knowledge the absolute max is 26 as DSM doesn't support /dev/sdaa /dev/sdab /dev/sdac etc. naming. Since there's only 26 letters you can only use 26 disks. Their eboxes work differently and that's how on a real DS you can get >26 drives.
On 9/10/2021 at 7:19 AM, jhoughten said:However DSM interprets that value is beyond me. With Jun's loader on DSM 6.2.3, maxdisks=6, but the storage manager shows 5 used slots and 5 available slots.
It must be some combination of the maxdisks and the internalportcfg settings.
These new settings on 7.0 have storage manager showing disks 1, 17 and 18. Disk 17 is the loader USB device, even though I do have synoboot, synoboot1, and synoboot2 in the /dev directory.
This is related to the Map parameters. Jun's loader used a hack to "hide" the loader image - RP doesn't need it. You need to configure mapping properly. This is a good description on how it works:
On 9/10/2021 at 11:19 AM, mcdull said:AFAIK, the valid mac is just needed to be input to the grub, but the actual hardware mac dose not matter, can you confirm?
I used it under proxmox so I acutally put the valid mac into virtual machine as well.
It actually does matter for some things - with invalid MAC the DHCP sometimes doesn't work. That's why it must match. You can try specifying that you have 2 network interfaces and putting your real MAC into one and the one matching S/N into the other.
If you're using proxmox however you can put that MAC in the virtual network interface on proxmox and that way you will have a matching boot setting with the actual card MAC. This is actually something we do as we have many VMs on many hosts to boot the kernel but just one user_config.
On 9/10/2021 at 2:06 PM, ressof said:Hi
Im trying to install DSM 7.01 apollolake 918+ on ESXI.
When running fdisk before installing PAT file I get this:
Disk /dev/sda: 120 GB, 128849018880 bytes, 251658240 sectors 15665 cylinders, 255 heads, 63 sectors/track Units: sectors of 1 * 512 = 512 bytes Disk /dev/sda doesn't contain a valid partition table Disk /dev/synoboot: 128 MB, 134217728 bytes, 262144 sectors 1008 cylinders, 5 heads, 52 sectors/track Units: sectors of 1 * 512 = 512 bytes Device Boot StartCHS EndCHS StartLBA EndLBA Sectors Size Id Type /dev/synoboot1 0,32,33 6,62,56 2048 100351 98304 48.0M 83 Linux Partition 1 has different physical/logical start (non-Linux?): phys=(0,32,33) logical=(7,4,21) Partition 1 has different physical/logical end: phys=(6,62,56) logical=(385,4,44) /dev/synoboot2 6,62,57 15,205,62 100352 253951 153600 75.0M 83 Linux Partition 2 has different physical/logical start (non-Linux?): phys=(6,62,57) logical=(385,4,45) Partition 2 has different physical/logical end: phys=(15,205,62) logical=(976,3,36) /dev/synoboot3 15,205,63 16,81,1 253952 262143 8192 4096K 83 Linux Partition 3 has different physical/logical start (non-Linux?): phys=(15,205,63) logical=(976,3,37) Partition 3 has different physical/logical end: phys=(16,81,1) logical=(1008,1,12)and the logs when trying to install the PAT file from serial console
[ 183.720933] <redpill/rtc_proxy.c:37> MfgCompatTime raw data: sec=20 min=3 hr=6 wkd=5 day=10 mth=8 yr=121 [ 183.723631] <redpill/rtc_proxy.c:95> Writing BCD-based RTC [ 183.724954] RTC time set to 2021-09-10 6:03:20 (UTC) [ 186.800143] md: bind<sda1> [ 186.801637] md/raid1:md0: active with 1 out of 16 mirrors [ 186.802992] md0: detected capacity change from 0 to 2549940224 [ 189.811875] md: bind<sda2> [ 189.813208] md/raid1:md1: active with 1 out of 16 mirrors [ 189.814563] md1: detected capacity change from 0 to 2147418112 [ 190.198325] EXT4-fs (md0): couldn't mount as ext3 due to feature incompatibilities [ 190.209674] EXT4-fs (md0): mounted filesystem with ordered data mode. Opts: (null) [ 190.240130] <redpill/rtc_proxy.c:222> Got an invalid call to rtc_proxy_set_auto_power_on [ 190.246693] EXT4-fs (md0): couldn't mount as ext3 due to feature incompatibilities [ 190.257611] EXT4-fs (md0): mounted filesystem with ordered data mode. Opts: (null) [ 190.272865] EXT4-fs (md0): couldn't mount as ext3 due to feature incompatibilities [ 190.283741] EXT4-fs (md0): mounted filesystem with ordered data mode. Opts: (null) [ 196.595667] ext2: synoboot2 mounted, process=updater [ 196.599505] synoboot2 unmounted, process=updater [ 196.607208] ext2: synoboot2 mounted, process=updater [ 196.609221] synoboot2 unmounted, process=updater [ 196.616749] ext2: synoboot2 mounted, process=updater [ 196.619137] synoboot2 unmounted, process=updater [ 196.625799] ext2: synoboot2 mounted, process=updater [ 198.179513] synoboot2 unmounted, process=updater [ 203.191011] ext2: synoboot2 mounted, process=updater [ 203.250955] synoboot2 unmounted, process=updater [ 203.261041] ext2: synoboot1 mounted, process=updater [ 203.265540] vfat: synoboot1 mounted, process=updater [ 203.268169] FAT-fs (synoboot1): Volume was not properly unmounted. Some data may be corrupt. Please run fsck.
Can this be fixed?
Regenerate loader image. It is corrupted according to the last error message. Keep in mind we don't support 7.0.1 yet.
While these errors don't look fatal having a broken filesystem is another complication which may cause problems (and FAT is very prone to being damaged... to the point that syno itself keeps two copies).
On 9/10/2021 at 5:03 PM, Polanskiman said:Oh boy, have I been sleeping!!!. I got some serious reading to do.
Haha, nice to see an admin here. It's just 55 pages
On 9/10/2021 at 5:58 PM, pocopico said:Right after that, the system is supposed to extract the ramdisk. The issue can be that you have a big or corrupted rd.gz.
I noticed that only the uncompressed image gets extracted successfully on some systems for some reason
***edit : and the reason is explained on the loader Documentation for developers :
https://github.com/RedPill-TTG/redpill-load/blob/master/FOR_DEVS.md
There's a detailed description of the problem in the ramdisk document in dsm-research repository. TL;DR: syno broke the kernel routines for decompression... [a minute of silence as we don't want to swear in public].
This is the reason why we advise against using versions needing editing of the image by hand. RD.gz compression type is just one of the stupid little quirks to take care of - we automate that to not think about that ourselves.On 9/10/2021 at 6:09 PM, pocopico said:@ThorGroup @jumkey Should/could someone create a compiled module repository in GH ? This way we can offload this thread from module requests
We deliberately didn't do this as we explained before in this thread. Current release is intended for developers and should not be used by regular users which aren't able to run a bash script. We will provide a precompiled modules when (very soon at this point ;)) the project reaches at least a beta state. One person was even nice enough to provide a PR on GH to automate the build (THANKS!).
The overwhelming number of posts in this thread are from people who downloaded a random image and started modifying configs inside it without even reading the documentation. When we ask for any logs there's usually silence which doesn't help us solve the underlying issue.
On 9/10/2021 at 10:45 PM, abesus said:Hi,
I've question: Is such log normal or is something bad in my system:
Yes, that's normal - if you didn't physically do "rmmod apollolake_synobios" you're good. This is a debug message which is very helpful if a kernel panic happens right after "synobios: unload". mfgBIOS module doesn't handle being unloaded manually.
On 9/10/2021 at 11:22 PM, p33ps said:Could you please be more specific about this?
Add it to the extra_cmdline in user_config.json and rebuild the loader image.
On 9/11/2021 at 12:22 AM, stigma86 said:Hi everyone.
I'm a satisfied user, but I was thinking of trying DMS 7.
My Mobo is the Asrock J4005B-ITX + 2x4GB 2400 RAM + WD Purple 2TB HDD+ etc HW's and my System is DMS 6.2.3 (918+, Loader 1.04B loader, Pendrive)I will be using a new Pendrive and HDD because if the installation will be fail, I can restore the current system(DMS 6.2.3)
I'm reading the topic, and I have some questions:
- This is a developer loader: Google Drive link => this is a good link or I'm a noob😀
This is a ,,step by step codex"?
- Download the loader
- mount OFSmount and replace the SN (918+) PID and VID
- Download the latest path file : 918+ => DSM 7.0.1 (Version: 7.0.1-42214)
- I continue the installation on the web interface and install the 7.01 image, that I'm writingNo, this isn't any official build. If you want to try playing with it you should use the official loader builder (with or without @haydibe docker). However, keep in mind that as of right now the loader is still in the alpha stage (however, beta will be coming soon with precompiled binaries of the module).
Sharing full loader images is something which will get people into troubles (as we explained before).
On 9/11/2021 at 2:48 AM, haydibe said:Let's say I share the reservation that things might become ugly to maintain and new problems might be introduced.
I must admit I am not realy keen to spend time on research about what would needed to be done.
Personaly I prefer to wait for the official redpill implementation as well
THANK YOU!!
This is exactly the message we're trying to send - there are hacks, we can load custom drivers, we do that on dev machines, we also do other weird things like restoring snapshots with memory and taking them mid-load or using hardware breakpoints... but this isn't something which a non-kernel developer should ever try. It's like playing with fire. However, ultimately we want a robust solution which does work for most/all of the cases instead of hacking the ramdisk and modifying files to do an insmod... and what if you put a driver which is slightly too large? (ramdisk has a strict limit). Well, the kernel is gonna boot with a partial ramdisk and everything will start collapsing with random errors. This is a nightmare to debug... ask us how we know
We're all for PRs and other contributions. We will definitely incorporate the improvement from posts here (e.g. the temperature breaking general tab) but it's way harder when other users start to (often unaware and confused) use other mods posted as attachments here and begin reporting bugs as RP bugs. Your docker image is always nicely documented and robust contributing to a great value here. However, some other mods* asking people to mount images and edit menu entries for grub ends up in broken installations as it skips the whole process and all the checks left in place for a reason.
There are very good reasons why we're not sharing complete images and why we spend many many many hours developing the generator. The RP started in a different thread, its code was shared in different GH repos, the initial work wasn't done by us... and it's now unavailable. Full loader images contain way more than the GPL kernel. They contain syno's proprietary and copyrighted binaries. Distributing them is... problematic at best.
*for the record here: nothing personal against anybody, we don't even remember nicknames half of the time as there are so many posts. We don't mind if someone publishes a modified version. It's just that it's incredibly hard for us to support modifications which are published as binaries with no instructions, a PR, and directly contradict the process we develop for building images. We love contributions, we run RP as an open-source initiative for a reason! We only try to limit confussion of less experienced folks
On 9/11/2021 at 6:07 AM, icaroscherma said:Do you guys plan to work on a DS920+ release instead of 918+? Or it's just too much work?
I'm asking because I figured that DS Video won't work with HWA transcoding for hevc because it's based off the 918+ (Intel UHD500 - j3355/j3455, not UHD600 - j4105/j4125), so the DS Video authentication doesn't even check for hardware acceleration on hevc.
It would be a nice update from my baremetal jun's DSM6.2.3 918+ to a DSM7 920+. ❤️
We're thinking about looking at one of the nvidia-based ones as they support both nvidia and intel quick sync. Especially that on an AMD system you can get something like Quadro P200 for cheap and have 7 streams of HVEC with little CPU usage.
On 9/11/2021 at 8:43 AM, mcdull said:I bet an AMD variant first will bring more benefit. I vote for 1621+
This is one of our big things - with AMD being so affordable and so powerful now... it will be great to have support for it. The biggest roadblock are S/N generation methods. The generators we've seen from the community support 3615/918/3617.
Is there any description on how these S/N are generated? How these values were discovered?
On 9/12/2021 at 12:16 AM, buggy25200 said:Hello,
I have a misunderstanding on how to get a .bsp patch for DSM 7.0.1 rc,
This is what i did:1) Extract zimage with the extract-vmlinux
2) Patch vmlinuz with patch-ramdisk-check.php#php patch-ramdisk-check.php vmlinuz vmlinuz.1 Generating patch for vmlinuz Found .rodata at 81 60 00 00 in vmlinuz Found "3ramdisk corrupt" at ff fd bd 0f in vmlinuz LE arg addr: 0ebd6d81 Found pritk arg @ ff cc 62 2b Found printk MOV @ ff cc 62 28 OK - patching 7417 (JZ) to eb17 (JMP) @ 13394470 Patched 2 bytes in memory Saving stream to vmlinuz.1 ... DONE!
3) Then patch vmlinuz.1 with patch-boot_params-check.php
php patch-boot_params-check.php vmlinuz.1 vmlinuz.2 Generating patch for vmlinuz.1 Found .init.text at ff cc 30 00 in vmlinuz.1 Looking for f() candidates... Analyzing f() candidate @ ff cf 0e 78 [?] Found possible f() @ ff cf 0e 78 [+] Found LOCK-OR#0 sequence @ ff cf 0f c2 => f0 80 0d 36 84 22 00 01 [RIP+(dec)15832056] [+] Found LOCK-OR#1 sequence @ ff cf 10 18 => f0 80 0d e0 83 22 00 02 [RIP+(dec)15832056] [+] Found LOCK-OR#2 sequence @ ff cf 10 56 => f0 80 0d a2 83 22 00 04 [RIP+(dec)15832056] [+] Found LOCK-OR#3 sequence @ ff cf 10 69 => f0 80 0d 8f 83 22 00 08 [RIP+(dec)15832056] [+] All 4 LOCK-OR PTR offsets equal - match found! Patching OR to AND @ file offset (dec)13569988 Patching OR to AND @ file offset (dec)13570074 Patching OR to AND @ file offset (dec)13570136 Patching OR to AND @ file offset (dec)13570155 Saving stream to vmlinuz.2 ... DONE!ls -l vmlinuz.2 -rw-r--r-- 1 root root 14174320 11 sept. 17:54 vmlinuz.24)
bsdiff vmlinuz vmlinuz.2 patch_sort.bsp ls -l patch_sort.bsp -rw-r--r-- 1 root root 180 11 sept. 17:58 patch_sort.bspI don't understand why my bsp file is much smaller than the one you made
ls -l zImage-001-3615xs-42214-ramdisk-and-header.bsp -rwxr-x--- 1 jim root 164235 3 sept. 19:10 zImage-001-3615xs-42214-ramdisk-and-header.bspCan you explain steps I am missing ?
Thank you all of you for this great work !
The redpill-load has a mode where you can repack the kernel and let it continue. The resulting bsp can be bigger or smaller depending on the compression results (as the bsdiff should be run on compressed image). As long as it's a proper diff the size doesn't matter here. The REAL changes are just a few bytes - the resulting bsp is bigger than that due to compression and bsdiff header.
For details as to how to "be guided" to build a new platform look at variables on the top of build-loader.sh file. You need to set BRP_LINUX_PATCH_METHOD=repack and few others (set this one - it will tell you which ones are missing) and then try to build an image of a platform which has no .bsp file. It will go up to the kernel patching, stop and let you patch the kernel. Then you restart the same process and it will detect patched kernel and recompress it etc. In the end it will leave these two compressed files for you to bsdiff
We want to have proper docs for this but it's all about time and number of hands
8 hours ago, pocopico said:There are two things that come in mind :
1. 10Gb driver is not loaded correctly
2. /etc/synoinfo.conf does not have the support_10g=y
log in with ssh and verify the above
Does it even matter what DSM shows in the settings for network speed? For VirtIO it shows Unknown or 10/100 while everything is working at few Gb/s. We will simply try iperf3 test and check if the speed is really <=1Gb/s between DSM and some other host and then try to tinker with it. If it's >1Gb/s it doesn't matter if the panel shows 10/100/1000 as this isn't really read directly from the interface or driver.
1 hour ago, jumkey said:sorry but l didn't find best way to change cp /efi/. /efi
Hm, can you describe what you've changed to make the EFI working? (sorry if you did and we've missed it in the sea of posts) We don't want to unnecessarily duplicate the work if you made it already
We think it just needs the new template image for the GRUB which supports EFI boot as the syno-specific files are copied anyway (whether GRUB supports EFI boot or not).1 hour ago, maxhartung said:No, the laptop doesn't have serial console (HP Elitebook 840 G2). I will try to find a way to attach a serial console in some way. Thank you.
Hm, that can be tricky then as AFAIK syno kernel doesn't support serial over USB. Are you able to see it connecting to the network at all? (e.g. on your router's DHCP leases/clients table).
48 minutes ago, cferra said:@ThorGroup I will gladly donate an LSI sas2 HBA if necessary. Feel free to PM me here or on chat.
Thank you for the offer
We have a few LSI cards but currently none of them is in any of the servers which we can play with. It just happens that for pure HBA we usually use cheap SATA cards and not good LSI controllers (as they need flashing in IT mode and not all of them play nice with SMART etc).
28 minutes ago, p3t3 said:have a question, dsm 6.2.4 loader can support 6.2.4-25556 update 1 and 2?
Good question. Can you try unpacking the update PAT (use tar -xvf FILE.pat) and seeing if there's a different zImage inside? If there isn't you're good to go to just update.
-
2
-
3
-
-
Continuation of questions starting from mid-page 37 (forum doesn't allow for more than 50 quotes per post):
On 9/4/2021 at 7:27 AM, jumkey said:change CONFIG_SYNO_SAS_DEVICE_PREFIX="sas" to CONFIG_SYNO_SAS_DEVICE_PREFIX="sd"? if you want?
root@vultr:~/build/linux-4.4.x-apollolake-25426# grep -r 'SYNO_SAS_DEVICE_PREFIX' ./ ./synoconfigs/broadwellntbap:CONFIG_SYNO_SAS_DEVICE_PREFIX="sas" ./synoconfigs/Kconfig.devices:config SYNO_SAS_DEVICE_PREFIX ./synoconfigs/broadwellnk:CONFIG_SYNO_SAS_DEVICE_PREFIX="sas" ./synoconfigs/broadwellntb:CONFIG_SYNO_SAS_DEVICE_PREFIX="sas" ./synoconfigs/coffeelake:CONFIG_SYNO_SAS_DEVICE_PREFIX="sas" ./synoconfigs/purley:CONFIG_SYNO_SAS_DEVICE_PREFIX="sas" ./drivers/scsi/sd.c: error = syno_sd_format_numeric_disk_name(CONFIG_SYNO_SAS_DEVICE_PREFIX, synoidx, gd->disk_name, DISK_NAME_LEN); ./drivers/scsi/sd.c: error = syno_sd_format_numeric_disk_name(CONFIG_SYNO_SAS_DEVICE_PREFIX, synoidx, gd->disk_name, DISK_NAME_LEN); root@vultr:~/build/linux-4.4.x-apollolake-25426#
You cannot change that - that will require rebuilding of the kernel which isn't possible (as syno doesn't share compilable sources of the kernel).
On 9/4/2021 at 4:39 PM, pocopico said:
what if you create links of the eg /dev/sas1 to /dev/sda with # ln -s /dev/sas1 /dev/sdaYou theoretically can use mknod but this causes problems with v7 (synoboot used to be done this way on 918+). Stay tuned: we will figure this out
On 9/4/2021 at 10:27 PM, haydibe said:So it is not just the drive order that is irrelevant, but it's also the device path (and thus the controller type) that is irrevant.
I was aware of the first part, but not of the second.
Good to know
Yeah, Linux and md doesn't care - only the DSM has some hardcoded assumptions for paths which we need to emulate
On 9/4/2021 at 10:46 PM, pkdick1 said:Hello, thank you very much for this file. May I ask you a question ?: I have myself an Asrock J4150-ITX, do you think that using you image, I will be able to migrate from DSM 6.23 to DSM 7.01 ? I also thought that it was also necessary to put a legit serial nember to make the baremetal XPENOLOGY device working: could you give me your point about this ?
I admit that I start to long a bit about this wonderful development, so I am close to take the risk to use you image...
Thank you in advance,
You don't need a real S/N to run it. Some services (e.g. faces detection in photos) need it but rest of the things don't. What's important is not using the same S/N for multiple people because sooner than later they will start blacklisting them.
On 9/4/2021 at 10:59 PM, maxhartung said:In order to work on ESXI what changes are required ?
Today's update should make ESXi working. [will be posted on GH after we finish writing all of the posts]
On 9/5/2021 at 12:12 AM, Drones said:I'm trying this solution, but no luck.
How i can change PID&VID on ready-made image (post tocinillo2)?
I think my problem is with wrong PID&VID.
Do not use ready-made images. You don't know what's in them nor we can help with those. Additionally, posting them here is a substantial risk as, unlike the generator, full images contain copyrighted materials which cannot be distributed legally. We will not go into details but the RP project started in a different thread... with different repos... by a different author... none of that is accessible anymore. Add 2 and 2 yourself.
On 9/5/2021 at 12:14 AM, haydibe said:Incorporated the addition from @taiziccf for chchia's apollolake-7.0.1-42214, and added @jumkey's bromolow-7.0.1-42214 from his develop branch.
You guys are moving at an incredible pace
redpill-tool-chain_x86_64_v0.6.1.zip 7.47 kB · 133 downloads
We only see a one big problem here - an EFI is being added on the side but nobody opens a PR for it. Instead, there are random zips flying around. Nothing against you (your help with docker is amazing!). However, soon we will not be able to help with issues as some of them stem from people running a modified version grabbed from an attachment...
On 9/5/2021 at 4:27 AM, mcdull said:After using the 7.0.1RC (918) on proxmox, I got quite a lot of call trace in log, and the system is very slow. Anyone experiencing the same?
[ 2160.666146] INFO: task kworker/u8:4:14489 blocked for more than 120 seconds. [ 2160.668620] Tainted: P OE 4.4.180+ #42214 [ 2160.670135] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 2160.671611] kworker/u8:4 D ffff8802613a3850 0 14489 2 0x00000000 [ 2160.672895] Workqueue: writeback wb_workfn (flush-btrfs-2) [ 2160.674311] ffff8802613a3850 00000000812c380a ffffffff818114c0 ffff8800367b6600 [ 2160.675579] 0000000000000000 ffff88027dc16300 7fffffffffffffff ffffffff81576880 [ 2160.676493] ffff8802613a3970 ffff8802613a3860 ffffffff81576126 ffff8802613a38d8 [ 2160.677916] Call Trace: [ 2160.678311] [<ffffffff81576880>] ? bit_wait+0x60/0x60 [ 2160.679061] [<ffffffff81576126>] schedule+0x26/0x70 [ 2160.679679] [<ffffffff81578cfe>] schedule_timeout+0x16e/0x280 [ 2160.680306] [<ffffffff810b836a>] ? ktime_get+0x3a/0xa0 [ 2160.682031] [<ffffffff81576880>] ? bit_wait+0x60/0x60 [ 2160.682702] [<ffffffff81575871>] io_schedule_timeout+0xa1/0x110 [ 2160.683374] [<ffffffff81576896>] bit_wait_io+0x16/0x60 [ 2160.683942] [<ffffffff8157663e>] __wait_on_bit_lock+0x4e/0xd0 [ 2160.684637] [<ffffffff8113124b>] __lock_page+0xab/0xb0 [ 2160.685314] [<ffffffff8108e850>] ? prepare_to_wait_event+0x100/0x100 [ 2160.685922] [<ffffffffa08c150d>] extent_write_cache_pages.isra.46.constprop.68+0x34d/0x480 [btrfs] [ 2160.686800] [<ffffffff8108e351>] ? __wake_up+0x41/0x50 [ 2160.687517] [<ffffffff81082c15>] ? update_curr+0xa5/0x130 [ 2160.688139] [<ffffffffa08c28bb>] extent_writepages+0x4b/0x60 [btrfs] [ 2160.688829] [<ffffffffa08a00b0>] ? btrfs_submit_direct+0x940/0x940 [btrfs] [ 2160.689620] [<ffffffffa089c8b6>] btrfs_writepages+0x26/0x30 [btrfs] [ 2160.690432] [<ffffffff8113ea7b>] do_writepages+0x2b/0x80 [ 2160.690986] [<ffffffffa08bd876>] ? clear_state_bit+0x156/0x1e0 [btrfs] [ 2160.691691] [<ffffffff811c34aa>] __writeback_single_inode+0x4a/0x380 [ 2160.692445] [<ffffffff811c3c69>] writeback_sb_inodes+0x1b9/0x530 [ 2160.693183] [<ffffffff811c4044>] __writeback_inodes_wb+0x64/0xb0 [ 2160.693901] [<ffffffff811c434a>] wb_writeback+0x22a/0x310 [ 2160.694571] [<ffffffff811c49f2>] wb_workfn+0x162/0x360 [ 2160.695197] [<ffffffff81073ceb>] worker_run_work+0x9b/0xe0 [ 2160.695860] [<ffffffff811c4890>] ? inode_wait_for_writeback+0x30/0x30 [ 2160.696723] [<ffffffff8106b2e3>] process_one_work+0x1e3/0x4f0 [ 2160.697559] [<ffffffff8106b61e>] worker_thread+0x2e/0x4b0 [ 2160.698251] [<ffffffff8106b5f0>] ? process_one_work+0x4f0/0x4f0 [ 2160.698850] [<ffffffff810700f5>] kthread+0xd5/0xf0 [ 2160.699369] [<ffffffff81070020>] ? kthread_worker_fn+0x160/0x160 [ 2160.699981] [<ffffffff81579fef>] ret_from_fork+0x3f/0x80 [ 2160.700547] [<ffffffff81070020>] ? kthread_worker_fn+0x160/0x160 [ 2160.701382] INFO: task SYNO.API.Auth.T:16585 blocked for more than 120 seconds. [ 2160.702204] Tainted: P OE 4.4.180+ #42214 [ 2160.702807] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 2160.703679] SYNO.API.Auth.T D ffff880235643c50 0 16585 10537 0x00000000 [ 2160.704476] ffff880235643c50 000000008182ed60 ffff880274970000 ffff8802643b8cc0 [ 2160.705284] ffff88025e54d760 ffff8802643b8cc0 ffff88025e54d764 00000000ffffffff [ 2160.706104] ffff88025e54d768 ffff880235643c60 ffffffff81576126 ffff880235643c70 [ 2160.706929] Call Trace: [ 2160.707196] [<ffffffff81576126>] schedule+0x26/0x70 [ 2160.707682] [<ffffffff815763b9>] schedule_preempt_disabled+0x9/0x10 [ 2160.708367] [<ffffffff81577b6c>] __mutex_lock_slowpath+0x8c/0x100 [ 2160.709101] [<ffffffff8119add9>] ? lookup_fast+0xc9/0x320 [ 2160.709633] [<ffffffff81577bf2>] mutex_lock+0x12/0x30 [ 2160.710157] [<ffffffff8119c8fb>] walk_component+0x21b/0x330 [ 2160.710773] [<ffffffff8119db24>] path_lookupat+0xb4/0x230 [ 2160.711384] [<ffffffff811a2d0a>] filename_lookup+0x9a/0x100 [ 2160.711974] [<ffffffff8117ca4d>] ? kmem_cache_alloc_trace+0x13d/0x150 [ 2160.712665] [<ffffffff811a2a23>] ? getname_flags+0x53/0x190 [ 2160.713253] [<ffffffff811a2e23>] user_path_at_empty+0x33/0x40 [ 2160.713815] [<ffffffff8118b0ff>] SyS_access+0x8f/0x2a0 [ 2160.714307] [<ffffffff81579c4a>] entry_SYSCALL_64_fastpath+0x1e/0x8e [ 2160.714866] INFO: task synoappnotify:16640 blocked for more than 120 seconds. [ 2160.715496] Tainted: P OE 4.4.180+ #42214 [ 2160.715977] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 2160.716882] synoappnotify D ffff880035693c60 0 16640 1 0x00000004 [ 2160.717741] ffff880035693c60 000000008119a7e5 ffffffff818114c0 ffff8802732ccc80 [ 2160.718576] ffff88025e54d760 ffff8802732ccc80 ffff88025e54d764 00000000ffffffff [ 2160.719414] ffff88025e54d768 ffff880035693c70 ffffffff81576126 ffff880035693c80 [ 2160.720268] Call Trace: [ 2160.720550] [<ffffffff81576126>] schedule+0x26/0x70 [ 2160.721168] [<ffffffff815763b9>] schedule_preempt_disabled+0x9/0x10 [ 2160.721904] [<ffffffff81577b6c>] __mutex_lock_slowpath+0x8c/0x100 [ 2160.722627] [<ffffffff81577bf2>] mutex_lock+0x12/0x30 [ 2160.723246] [<ffffffff811a0614>] path_openat+0x444/0x1a40 [ 2160.723882] [<ffffffff811e458a>] ? flock_lock_inode+0xda/0x280 [ 2160.724579] [<ffffffff811e47ee>] ? locks_remove_flock+0xbe/0xc0 [ 2160.725298] [<ffffffff811a390e>] do_filp_open+0x7e/0xc0 [ 2160.725897] [<ffffffff811ab2b1>] ? dput.part.25+0x91/0x200 [ 2160.726549] [<ffffffff811b1c6b>] ? __alloc_fd+0x3b/0x170 [ 2160.727187] [<ffffffff81189b4f>] do_sys_open+0x1af/0x240 [ 2160.727715] [<ffffffff8118bf3f>] SyS_openat+0xf/0x20 [ 2160.728242] [<ffffffff81579c4a>] entry_SYSCALL_64_fastpath+0x1e/0x8e [ 2160.728924] INFO: task SYNO.API.Auth.T:19202 blocked for more than 120 seconds. [ 2160.729745] Tainted: P OE 4.4.180+ #42214 [ 2160.730348] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. [ 2160.731201] SYNO.API.Auth.T D ffff880231103c50 0 19202 10537 0x00000000 [ 2160.731980] ffff880231103c50 000000008182ed60 ffffffff818114c0 ffff88026c4f3300 [ 2160.732827] ffff88025e54d760 ffff88026c4f3300 ffff88025e54d764 00000000ffffffff [ 2160.733753] ffff88025e54d768 ffff880231103c60 ffffffff81576126 ffff880231103c70 [ 2160.734605] Call Trace: [ 2160.734819] [<ffffffff81576126>] schedule+0x26/0x70 [ 2160.735273] [<ffffffff815763b9>] schedule_preempt_disabled+0x9/0x10 [ 2160.735812] [<ffffffff81577b6c>] __mutex_lock_slowpath+0x8c/0x100 [ 2160.736580] [<ffffffff8119add9>] ? lookup_fast+0xc9/0x320 [ 2160.737218] [<ffffffff81577bf2>] mutex_lock+0x12/0x30 [ 2160.737791] [<ffffffff8119c8fb>] walk_component+0x21b/0x330 [ 2160.738406] [<ffffffff8119db24>] path_lookupat+0xb4/0x230 [ 2160.738980] [<ffffffff811a2d0a>] filename_lookup+0x9a/0x100 [ 2160.739615] [<ffffffff8117ca4d>] ? kmem_cache_alloc_trace+0x13d/0x150 [ 2160.740399] [<ffffffff811a2a23>] ? getname_flags+0x53/0x190 [ 2160.741083] [<ffffffff811a2e23>] user_path_at_empty+0x33/0x40 [ 2160.741734] [<ffffffff8118b0ff>] SyS_access+0x8f/0x2a0 [ 2160.742330] [<ffffffff81579c4a>] entry_SYSCALL_64_fastpath+0x1e/0x8e [ 2180.147079] <redpill/pmu_shim.c:324> Got 1 bytes from PMU: reason=1 hex={2d} ascii="-" [ 2180.297936] <redpill/pmu_shim.c:324> Got 1 bytes from PMU: reason=1 hex={75} ascii="u" [ 2180.298917] <redpill/pmu_shim.c:253> Executing cmd OUT_FAN_HEALTH_ON handler cmd_shim_noop+0x0/0x2d [redpill] [ 2180.298917] <redpill/pmu_shim.c:42> vPMU received OUT_FAN_HEALTH_ON using 1 bytes - NOOP
Do you have details how you triggered that error? We didn't look into 7.0.1 yet.
On 9/5/2021 at 5:44 AM, matyyy said:This is my first post on the forum so it would be appropriate to say hello! Hello XPenlogy!
Great job RedPill - I was able to get DSM 7.0 running on an HP Microserver Gen 8 in EXSI - the problem was only with the disk but the solution from https://github.com/RedPill-TTG/redpill-lkm/issues/14 helped. The only thing left is the pesky message that the disk needs attention, does anyone have a solution for that?
It should be working with the new release today
[will be posted on GH soon after we finish all posts]
On 9/5/2021 at 10:40 AM, volitation said:How does DS918+ support SATA boot like DS3615xs?
It does now - today's update adds this.
On 9/5/2021 at 3:18 PM, progressives said:@haydibe what is error msg?
WARNING: Symbol version dump /opt/redpill-lkm/kernel-bromolow-6.2.4-25556/Module.symvers
is missing; modules will have no dependencies and modversions.That is perfectly normal when compiling modules against kernel sources which weren't compiled in that directory. In essence, it means that the kernel cannot determine dependencies between multiple modules (which is important for e.g. distributing a driver for Ubuntu, but here it doesn't matter at all).
On 9/5/2021 at 4:37 PM, titoum said:i started the latest docker and great works as usual
")
wondering why i get this warning:
/opt/redpill-lkm/config/runtime_config.c:168:47: warning: passing argument 2 of 'validate_nets' discards 'const' qualifier from pointer target type valid &= validate_nets(config->netif_num, config->macs); ^ /opt/redpill-lkm/config/runtime_config.c:80:20: note: expected 'char (**)[13]' but argument is of type 'char (* const*)[13]' static inline bool validate_nets(const unsigned short if_num, mac_address *macs[MAX_NET_IFACES]) ^for the following user_config (obfuscated value of course but i kept the length of it
)
Using user_config.json: { "extra_cmdline": { "pid": "XXXXXX", "vid": "XXXXXX", "sn": "-", "mac1": "000000000000", "mac2": "000000000000" }, "synoinfo": {}, "ramdisk_copy": {} }Fixed in today's release - that warning is actually an old GCC artifact but we worked around it with a slightly different syntax.
On 9/5/2021 at 8:22 PM, Rikk said:Hello to all,
I am trying to test the loader on my current hardware and I am stuck to a stupid step : my system didn't find the USB key to boot on it. With the previous setup (Jun's loader with 3615xs model, 6.2.3 DSM) it was working well.
My hardware is :
Gen8 HP microserver with Xeon E3-1220L CPU update
6Gb of RAM
I am using le last env (redpill-tool-chain_x86_64_v0.7.2) to build the image with MAC OS big sur platform., and docker installed.
My bromolow_user_config.json:
content is (xx and yy are replacing real values and pid/vid are the one from my USB key😞
{
"extra_cmdline": {
"pid": "0xFFF7",
"vid": "0x203A",
"sn": "yyyyyyyyyyyyy",
"mac1": "xxxxxxxxxxxx"
},
"synoinfo": {},
"ramdisk_copy": {}
}Commands to build the image:
cd ~/Desktop/redpill-tool-chain_x86_64_v0.7.2
sudo chmod 777 redpill_tool_chain.shsh ./redpill_tool_chain.sh build bromolow-7.0.1-42214
sh ./redpill_tool_chain.sh auto bromolow-7.0.1-42214
The image is written on USB key with BalenaEtcher
Did I am missing something ?
Help will be appreciate.
Thanks !
Rikk
Try the port INSIDE of the case. HPE bios on microserver is strange sometimes.
On 9/5/2021 at 10:35 PM, pkdick1 said:One last question: I need to updated the PID/VID of my USB stick in order to be recognized during install. What about the serial number and the mac address you put in you grub.cfg file ? Are they mandatory for the install ? (I know that the serial number is necessary for DS Video to use hardward transcoding, but what about the mac address?).
Thank you very much for your answers.
S/N must be unique (can be generated but must be unique); MAC is needed for DHCP. You should not edit the grub config manually.
On 9/6/2021 at 4:19 AM, maxhartung said:My Proxmox install seem broken for some reason:
I uploaded the img file to via web browser (local home -> ISO Images)
/var/lib/vz/template/iso/image.img
But when I try to start the VM:
kvm:  -device qemu-xhci,addr=0x18 -drive id=synoboot,file=/var/lib/vz/template/iso/image.img,if=none,format=raw -device usb-storage,id=synoboot,drive=synoboot,bootindex=5:
Could not open ' -device qemu-xhci,addr=0x18 -drive id=synoboot,file=/var/lib/vz/template/iso/image.img,if=none,format=raw -device usb-storage,id=synoboot,drive=synoboot,bootindex=5': No such file or directory
I checked the file via shell and it's there.
This is the args in the conf:
args: -device 'qemu-xhci,addr=0x18' -drive 'id=synoboot,file=/var/lib/vz/template/iso/image.img,if=none,format=raw' -device 'usb-storage,id=synoboot,drive=synoboot,bootindex=5'
root@home:~# ls /var/lib/vz/template/iso/
image.img
root@home:~#Config:
args: -device 'qemu-xhci,addr=0x18' -drive 'id=synoboot,file=/var/lib/vz/template/iso/image.img,if=none,format=raw' -device 'usb-storage,id=synoboot,drive=synoboot,bootindex=5'
balloon: 0
boot: order=sata0;net0
cores: 2
machine: q35
memory: 4096
name: DSM
net0: virtio=F2:9D:7D:2E:7E:61,bridge=vmbr0
numa: 0
ostype: l26
sata0: local-lvm:vm-100-disk-0,size=120G
scsihw: virtio-scsi-pci
smbios1: uuid=27d90b08-fa4c-4b43-85fc-f40200747f72
sockets: 1
vmgenid: 6e85c112-295e-4432-b661-7f91af624a80You need to put it as a disk image, not an ISO image. These are quite different - that's one. Second you have a syntax error somewhewre but the forum replaced bunch of characters. You need to post in a code block tag so the forum doesn't replace anything.
On 9/6/2021 at 4:53 PM, mcdull said:I tried 3615 image in my old qnap. But it does not boot properly.
In GRUB> whenever I press enter, it will reboot by itself.
What CPU do you have? If it just hard-reboots it means the CPU just crashed, which usually means that it doesn't support some instructions.
On 9/6/2021 at 7:39 PM, WiteWulf said:FYI, if you need to set the partition as active on your USB stick and you're using macOS, it's non-obvious how to do this. Here's a howto:
https://hackintoshmumbai.com/how-to-set-up-your-partition-active-using-fdisk-in-mac-os-x/
If you dd the raw image (dd if=file.img of=/dev/rdiskX => make sure you sure rdisk and not disk) you don't need to manually modify the partition. Before you do that you should check the disk with diskutil list to get the number and unmount all existing partitions using diskutil unmount (not eject from the Finder).
On 9/6/2021 at 10:26 PM, pocopico said:To extract :
mkdir rd
cd rd
cat ../rd.gz | cpio -idm
To repack the rd, in rd directory :
find | cpio -o -H newc > ../rd.gz.new
This is actually posted in the research repo. However, we strongly advise against manually tinkering with the rd.gz file - the loader generator can copy files where needed.
On 9/6/2021 at 10:34 PM, pocopico said:Not very difficult ..
In order to compile your modules for 3.10.108 download standard kernel sources :
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/snapshot/linux-3.10.108.tar.gz
or just clone latest stable and
# git checkout v3.10.108
copy the .config from the bromolow/apollolake sources to the folder you have the kernel sources that you downloaded, make menuconfig and select the modules you want to compile and the end run make modules.
Pay attention to the module dependencies (run modinfo xxx.ko ) as you might need modules to be loaded before that. e.g. module tg3.ko (tigon) depends on libphy.ko, so you need to first load libphy.ko and then tg3.ko. Not all modules have dependencies, but some do.
It's better to compile modules against synology's source published on sourceforge as they modify structs. Building against vanilla kernel sources may have catastrophic consequences, especially if you're trying to build some driver.
On 9/6/2021 at 11:12 PM, pocopico said:@Orphée One problem that is not yet solved or released by @ThorGroup , is that we don’t have a solution for adding the extra modules in one batch like with Jun loader.
I’am assuming though that for most installations, adding few required kernel modules in rd could be possible. You can also start telnetd at boot to help troubleshoot sata port errors or anything that even fails to start installation.
Lines to add in rd.gz on /etc/rc line 321 could be :
echo "Starting early telnetd for troubleshooting "
/sbin/inetd
if [ `ps -ef |grep -i inetd |grep sbin | wc -l` -eq 1 ] ; then
echo "Inetd has started succesfully"
fi
We're working on a solution for drivers. This is currently what's stopping us from formally calling it a beta
On 9/7/2021 at 2:30 AM, abesus said:Hi everyone,
Ive successfully built and use loader for 980+. Unfortunatelly, I'm using Xeon E3-1265L V4 and there were many errors in system logs. System was hanging-up every few hours. It looks like DS918+ is using some new CPU/GPU instructions that are missing in my old xeon.
After that I've tried DS3615xs loader. DSM 7.0 is in beta stage so I've tried 6.2.4. Everything is working great except moments. How can I find valid SN/MAC combination for ds3615xs?
Seba
Yes.... Intel decided to add a single instruction (MOVBE) to only the Atom line... then a few years later they've added it to the Xeons. Go figure... that's why 918+ requires a newer CPU with MOVBE support. If you search for "MOVBE intel cpu" you will find many topics not related to xpenology as this is a much bigger problem.
As for the SN/MAC: the mac needs to match your real ethernet adaptor. As for the S/N you can google "xpenology s/n generator" and there are tools prepared by the community.
On 9/7/2021 at 2:15 PM, titoum said:is there a way to get the info when it fails at 56% ?
all is going smooth until the installation start and stop at that steps :s
thx
You need to use a serial console on your hypervisor, login as root:[no password] and check the /var/log/messages - it will say what went wrong somewhere on the bottom.
On 9/7/2021 at 2:42 PM, abesus said:So in my case, software for DS918+ should work on my CPU. That would be great (I've working set of SN and MAC)
Did you check /var/log/messages? I've got a lot logs like:
kernel: DMAR: DRHD: handling fault status reg 3
kernel: DMAR: [DMA Read] Request device [some numbers] fault addr some address...
I can't remember exactly but if it can be helpful I can build loader again and check.
Did you try updating the BIOS? We've seen such errors on Debian on an Asus motherboard and updating the BIOS solved the issue.
On 9/7/2021 at 3:19 PM, Null said:Why is my control center blank
That is a bug in the DSM itself (JS error on the page...). It happens on a real hardware as well... albeit not always hmmm. However the only broken page is the Info Center => General.
On 9/7/2021 at 4:19 PM, jumkey said:from https://gist.github.com/Izumiko/26b8f221af16b99ddad0bdffa90d4329
"synoinfo": { "supportsystemperature": "no", "supportsystempwarning": "no" },Yay! A nice fix
We will add this to the main loader generator.
On 9/7/2021 at 5:05 PM, sirdrug said:(...)
[ 127.785579] md1: detected capacity change from 0 to 2147418112
[ 128.446373] EXT4-fs (md0): couldn't mount as ext3 due to feature incompatibilities
[ 128.466030] EXT4-fs (md0): mounted filesystem with ordered data mode. Opts: (null)
[ 128.554349] <redpill/rtc_proxy.c:222> Got an invalid call to rtc_proxy_set_auto_power_on
[ 128.559532] EXT4-fs (md0): couldn't mount as ext3 due to feature incompatibilities
[ 128.578612] EXT4-fs (md0): mounted filesystem with ordered data mode. Opts: (null)These errors are normal. If you look at them just below it the array is mounted. It jus first tries one thing, failes, and then tries another thing and succeeds.
On 9/7/2021 at 5:20 PM, nemesis122 said:Has anyone the loader for Bromolow 3615 and can upload for me ?
thank you
You can generate it with the loader generator. Please, do not use premade images.
On 9/7/2021 at 5:21 PM, sirdrug said:In /var/log/messages
Sep 7 09:13:13 updater: updater.c:7045 ==== Start flash update ====
Sep 7 09:13:13 updater: updater.c:7049 This is X86 platform
Sep 7 09:13:13 updater: boot/boot_lock.c(228): failed to mount boot device /dev/synoboot2 /tmp/bootmnt (errno:2)
Sep 7 09:13:13 updater: updater.c:6510 Failed to mount boot partition
Sep 7 09:13:13 updater: updater.c:3134 No need to reset reason for v.42214
Sep 7 09:13:13 updater: updater.c:7652 Failed to accomplish the update! (errno = 21)
Sep 7 09:13:13 install.cgi: ninstaller.c:1546 Executing [/tmpData/upd@te/updater -v /tmpData > /dev/null 2>&1] error[21]
Sep 7 09:13:15 install.cgi: ninstaller.c:123 Mount partion /dev/md0 /tmpRoot
Sep 7 09:13:15 install.cgi: ninstaller.c:1515 Moving updater for configuration upgrade...cmd=[/bin/mv -f /tmpData/upd@te/updater /tmpRoot/.updater > /dev/null 2>&1]
Sep 7 09:13:15 install.cgi: ninstaller.c:152 umount partition /tmpRoot
Sep 7 09:13:15 install.cgi: ErrFHOSTCleanPatchDirFile: After updating /tmpData/upd@te...cmd=[/bin/rm -rf /tmpData/upd@te > /dev/null 2>&1]
Sep 7 09:13:15 install.cgi: ErrFHOSTCleanPatchDirFile: Remove /tmpData/upd@te.pat...
Sep 7 09:13:15 install.cgi: ErrFHOSTDoUpgrade(1794): child process failed, retv=-21
Sep 7 09:13:15 install.cgi: ninstaller.c:1811(ErrFHOSTDoUpgrade) err=[-1]
Sep 7 09:13:15 install.cgi: ninstaller.c:1815(ErrFHOSTDoUpgrade) retv=[-21]
Sep 7 09:13:15 install.cgi: install.c:409 Upgrade by the manual patch fail.
Sep 7 09:13:15 install.cgi: install.c:678 Upgrade by the uploaded patch /tmpData/@autoupdate/upload.pat fail.any ideas?
Your vid/pid combination is most likely invalid, or you connected the usb flash drive to a USB3 port. Try doing "dmesg | grep usb_boot_shim" - it will tell you what drives it saw and if any was shimmed as boot disk.
On 9/7/2021 at 5:22 PM, WiteWulf said:I had a couple more odd reboots of my system this morning. They always seem to occur shortly after a reboot. I'd restarted the system after updating firmware on the iLO card in my system, and the server rebooted almost immediately after it had booted into DSM (I think it managed about 3 minutes uptime), then rebooted again shortly afterwards. Looking in /var/log/messages for entries just before it reboots each time there's nothing that stands out, other than that it's typically doing stuff you'd expect after the system had just rebooted: starting docker containers and registering certificates for a couple of webhosts I have on the server
Are you sure your RAM is ok? Are you running ECC there? Check the iLO log as well. Try disabling HPET as well.
On 9/7/2021 at 5:46 PM, WiteWulf said:Question: I have an HP NC360T PCIe NIC card in my system. I'm only using one interface, so have only declared one of them in my user_config.json. Is this a problem?
I notice in Control Panel in DSM that two interfaces are detected, and both have the same MAC address (the one I declared for the interface that I'm actually using). Likewise, running 'ifconfig' from the cli reports two interfaces with the same MAC address. I know that an OSI 7-layer network stack shouldn't have an issue with multiple interfaces on a system having the same MAC address (it's standard on Sun machines, for example), but will DSM complain about this?
Next time I rebuild the boot stick I'll be sure to declare both interfaces, but am just curious for now.
You should define both. DSM is... hacky... in terms of ethernet interfaces. All of them should be accounted for with different MAC addresses.
On 9/7/2021 at 6:34 PM, Franks4fingers said:I have tried this using both UEFI and Legacy boot from within the BIOS and get the same issue. Does anyone have any tips to get past this point?
Are you able to connect to the machine using a serial port?
On 9/7/2021 at 6:49 PM, Franks4fingers said:That line in my grub.cfg file is as follows:
linux /zImage netif_num=1 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=1 syno_hdd_detect=0 elevator=elevator root=/dev/md0 loglevel=15 log_buf_len=32M mac1=123456789012 vid=0x0781 pid=0x5572 console=ttyS0,115200n8 sn=xxxxxxxxxxxxx earlyprintk syno_port_thaw=1 HddHotplug=0 withefi syno_hw_version=DS918+ vender_format_version=2
Did you add the DiskIdxMap= SataPortMap= SasIdxMap= values to the end of that line?
Also, how did you derive what the SataPortMap value needed to be?
Cheers for the help.
Please add them to your user config under extra_cmdline and rebuild the loader image.
On 9/7/2021 at 8:51 PM, nemesis122 said:Maybe its releated to this and you need 3615 Bromolow
Correct, this table still applies. This is due to how syno builds their kernels and how Intel artificially limits instruction sets on some CPUs [fun fact, some older Xeons have the MOVBE in the microcode but it's disabled]
On 9/7/2021 at 8:57 PM, shibby said:
i have 4-gen CPU (Haswell). I can install DS918+ 6.2.3 (jun). I can install DS918+ 7.0.1 on fresh HDD using redpill. I can even upgrade from 6.2.3 (jun) to 6.2.4 (redpill) using DS918+ image.But i can`t upgrade from 6.2.3/6.2.4 to 7.x 😕
So what exactly fails with the upgrade? Are you able to recover the log?
On 9/7/2021 at 10:05 PM, MastaG said:Trying to build and run it on my HP Gen8.
I first built redpill.ko using redpill-lkm, that was quite easy.
For the record I used gcc 4.9.2 to build it.
Using redpill-load I created the following user_config.json:
{ "extra_cmdline": { "vid": "0x0951", "pid": "0x1665", "sn": "xxx", "mac1": "xxx", "mac2": "xxx" } }I copied redpill.ko from repill-lkm to: ext/rp-lkm/redpill-linux-v3.10.108.ko
And finally: sudo ./build-loader.sh 'DS3615xs' '7.0-41222'
The image is successfully created, but the first partition doesn't have the bootabled flag:
fdisk -l ./redpill-DS3615xs_7.0-41222_b1631017171.img Schijf ./redpill-DS3615xs_7.0-41222_b1631017171.img: 128 MiB, 134217728 bytes, 262144 sectoren Eenheid: sectoren van 1 * 512 = 512 bytes Sectorgrootte (logisch/fysiek): 512 bytes / 512 bytes In-/uitvoergrootte (minimaal/optimaal): 512 bytes / 512 bytes Schijflabeltype: dos Schijf-ID: 0xf110ee87 Apparaat Op. Begin Einde Sectoren Grootte ID Type ./redpill-DS3615xs_7.0-41222_b1631017171.img1 2048 100351 98304 48M 83 Linux ./redpill-DS3615xs_7.0-41222_b1631017171.img2 100352 253951 153600 75M 83 Linux ./redpill-DS3615xs_7.0-41222_b1631017171.img3 253952 262143 8192 4M 83 LinuxSo I used fdisk on the image to set the first partition "active", so it can actually boot on legacy systems.
The developers should fix this I guess.
After writing it to USB it does seem to try and boot, but it just shows: Booting the kernel.
It hangs for like 20 or 30 seconds, then it reboots. (see screenshot).
Any ideas?
In order to see any logs you must attach a serial/COM port. Syno kernel doesn't support VGA output (so as soon as the grub passes the control to the kernel nothing is passed to the GPU).
On 9/7/2021 at 10:27 PM, MastaG said:Yeah it's annoying that the kernel doesn't print any console output tot the iLO console either.
I've tried adding console=tty0 console=tt1, console=ttyS1 etc.. no dice.
It just sits there and reboots all the time
If you boot with ttyS0 iLO should be able to access that port. When you log in to the iLO using ssh (use the same credentials as for the web) there's a virtual serial port emulator (vsp command IIRC from memory). Connect to it before booting and you should start seeing messages right after the screen says "Booting the kernel".
On 9/7/2021 at 10:42 PM, sirdrug said:I updated my synology, but I still can't change the serial number to a valid one, who can tell me where else to change it?
You can put it in your user_config.json and it should work... how did you get that S/N?
On 9/7/2021 at 10:55 PM, MastaG said:So I got a little further.
I've now build the redpill.ko kernel module using the toolchain stated here: https://github.com/RedPill-TTG/redpill-lkm/pull/16/commits/b3f263c65198d94014f60f52f58bc6be00d1d8f8#
So basically:
make LINUX_SRC=~/.toolchain/bromolow-DSM-7.0-toolkit/build CROSS_COMPILE=~/.toolchain/bromolow-DSM-7.0-toolchain/x86_64-pc-linux-gnu/bin/x86_64-pc-linux-gnu-
and also:
strip -S redpill.ko
Now using the redpill.ko built by the DSM 7.0 toolchain (and stripped) my Microserver Gen8 doesn't reboot any longer.
It now just sits there at the "Booting the kernel." screen.
However I can't see any DHCP being requested and I still don't have any console output.
Any ideas?
Do not use strip on kernel modules - there are many problems with that. Some options will strip e.g. modinfo which will make the module useless for the kernel.
On 9/7/2021 at 11:06 PM, WiteWulf said:Oh, that's cool, didn't realise that! That opens up the possibility of getting a better/additional HBA to go in there at some point...
Yes, the built-in card was broken only for a short while. 6.2.3 restored the driver. We didn't test if v7 removed it again (hopefully not).
On 9/7/2021 at 11:33 PM, imdgg said:1.open ssh service
2.connect to your dsm
3.mount boot partion. Just like this: mount /dev/vda1 /mnt #my device is /dev/vda1
4.vim /mnt/boot/grub/grub.cfg , search "sn",change the serial number
my dsm 7.0.1 runs on qnap 453b-mini
If your loader is at /dev/vda1 then something is very wrong... it shouldn't be. It should be at /dev/synobootN. Editing the grub.cfg manually is not (and will not be) supported.
On 9/8/2021 at 1:03 AM, nemesis122 said:Which VID and PID i have to set when i load/install in VMM VirtualmaschineManager ?
VMM doesn't allow for virtual USB drive. You need to use SATA boot. However, if you're using VMM you should probably install the official VDSM image.
On 9/8/2021 at 2:57 AM, MastaG said:Thanks bro,
That would be great 👍
If you can confirmed the internal NIC isn't supported any longer, then perhaps you can share your card with us.
I guess it's a small price to pay to have the latest DSM working
NC360T is a good and solid card, even outside of the DSM ecosystem. It's a HP product but it's cheap and readily available (even new). We have probably 30+ of these cards in different servers.
On 9/8/2021 at 11:45 AM, Franks4fingers said:Do you have the link for the .pat file that you used for the fresh install?
After you build the loader the correct PAT file will be in the "cache" folder. You don't need to download it manually from syno.
On 9/8/2021 at 3:58 PM, titoum said:may be @ThorGroup could enhance first topic with some extra info ?
link to latest version of haydibe docker image ?
how to get ride of the blank info center
sudo su - root sed -i 's/supportsystemperature="yes"/supportsystemperature="no"/g' /etc.defaults/synoinfo.conf sed -i 's/supportsystempwarning="yes"/supportsystempwarning="no"/g' /etc.defaults/synoinfo.confacpi throttle
sudo su - root vi /usr/local/etc/rc.d/S99Powersaving.sh and insert according to number of core Script-content: #!/bin/sh echo powersave > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor echo powersave > /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor echo powersave > /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor echo powersave > /sys/devices/system/cpu/cpu3/cpufreq/scaling_governor chmod +x /usr/local/etc/rc.d/S99Powersaving.sh sh /usr/local/etc/rc.d/S99Powersaving.shWe will like to but we don't have permissions to edit old posts
Who should we contact on the form regarding that?
On 9/8/2021 at 4:12 PM, p33ps said:Synology says that the "face detection" feature which is implemented in lower versions (<7.0) for Moments app is different that the new one, which needs higher hardware to run smoothly. I hope not to affect to xpenology newer versions, but my current experience with 7.0 is quite bad. It consumes too many resources and does not detect any face after hours.
v7 should be considered a beta (even if syno says it's stable) on any hardware, including that sold by synology. There are nasty bugs in it unrelated to xpenology.
On 9/8/2021 at 4:16 PM, WiteWulf said:I made some progress with the spontaneous reboots I've been seeing since migrating to 6.2.4 but spun it off into a separate topic as it's not entirely relevant to this thread:
That smells like an ancient docker version in the DSM itself... we saw this before and they fixed the issue after like 6-7 months. It may be the case again.
On 9/8/2021 at 7:48 PM, tossp said:The kernel keeps reporting this information. What action should I take?
[80085.526427] <redpill/rtc_proxy.c:226> Mocking auto-power SET on RTC [80085.532878] BUG: unable to handle kernel NULL pointer dereference at (null) [80085.540936] IP: [<ffffffff812fd1e6>] memcpy_erms+0x6/0x10 [80085.546473] PGD 363fb9067 PUD 3d1d07067 PMD 0 [80085.551076] Oops: 0000 [#713] SMP [80085.554569] Modules linked in: fuse nfnetlink pci_stub vfio_pci vfio_virqfd vfio_iommu_type1 vfio vhost_net(O) kvm_intel kvm irqbypass xt_ipvs ip_vs_rr ip_vs xt_mark br_netfilter bridge stp aufs macvlan veth xt_addrtype tun cmac ctr ccm ipt_MASQUERADE xt_REDIRECT nf_nat_masquerade_ipv4 xt_nat nf_nat_redirect xt_policy xfrm6_mode_transport xfrm4_mode_transport xfrm6_mode_tunnel xfrm4_mode_tunnel xfrm6_mode_beet xfrm4_mode_beet deflate authencesn ipcomp6 ipcomp xfrm6_tunnel xfrm4_tunnel tunnel6 esp6 esp4 ah6 ah4 xfrm_ipcomp af_key xfrm_user xfrm_algo l2tp_ppp l2tp_core ppp_deflate bsd_comp ppp_mppe echainiv xt_TCPMSS iptable_mangle pppox ppp_async ppp_generic slhc 8021q vhost_scsi(O) vhost(O) tcm_loop(O) iscsi_target_mod(O) target_core_user(O) target_core_ep(O) target_core_multi_file(O) target_core_file(O) [80085.628492] target_core_iblock(O) target_core_mod(O) syno_extent_pool(PO) rodsp_ep(O) udf isofs loop nfsv3 nfs quota_v2 quota_tree synoacl_vfs(PO) iptable_nat nf_nat_ipv4 nf_nat raid456 async_raid6_recov async_memcpy async_pq async_xor async_tx xt_conntrack xt_mac xt_geoip(O) compat_xtables(O) nf_conntrack_ipv6 ip6table_filter ip6_tables xt_recent xt_iprange xt_limit xt_state xt_tcpudp xt_multiport xt_LOG nf_conntrack_ipv4 nf_defrag_ipv4 iptable_filter ip_tables x_tables nfsd btrfs ecryptfs zstd_decompress zstd_compress xxhash xor raid6_pq lockd grace rpcsec_gss_krb5 auth_rpcgss sunrpc aesni_intel glue_helper lrw gf128mul ablk_helper apollolake_synobios(PO) hid_generic usbhid hid usblp i915 drm_kms_helper syscopyarea sysfillrect sysimgblt fb_sys_fops cfbfillrect cfbcopyarea cfbimgblt drm drm_panel_orientation_quirks [80085.702288] iosf_mbi fb fbdev video backlight button uhci_hcd ehci_pci ehci_hcd r8168(O) i2c_algo_bit openvswitch gre nf_defrag_ipv6 nf_conntrack igb(O) e1000e(O) sg dm_snapshot dm_bufio crc_itu_t crc_ccitt psnap p8022 llc hfsplus md4 hmac sit tunnel4 ipv6 flashcache_syno(O) flashcache(O) syno_flashcache_control(O) dm_mod arc4 crc32c_intel cryptd sha256_generic ecb aes_x86_64 authenc des_generic ansi_cprng cts md5 cbc cpufreq_powersave cpufreq_performance acpi_cpufreq processor cpufreq_stats vxlan ip6_udp_tunnel udp_tunnel zram ip_tunnel etxhci_hcd usb_storage xhci_pci xhci_hcd usbcore usb_common redpill(OE) [last unloaded: apollolake_synobios] [80085.760520] CPU: 3 PID: 4856 Comm: scemd Tainted: P D OE 4.4.180+ #42214 [80085.768258] Hardware name: System manufacturer System Product Name/B150M-PLUS, BIOS 3806 05/18/2018 [80085.777496] task: ffff88004055d280 ti: ffff88012a65c000 task.ti: ffff88012a65c000 [80085.785166] RIP: 0010:[<ffffffff812fd1e6>] [<ffffffff812fd1e6>] memcpy_erms+0x6/0x10 [80085.793225] RSP: 0018:ffff88012a65fbb0 EFLAGS: 00010246 [80085.798660] RAX: ffff88012a65fbf0 RBX: ffffffffffffffff RCX: 0000000000000134 [80085.805956] RDX: 0000000000000134 RSI: 0000000000000000 RDI: ffff88012a65fbf0 [80085.813252] RBP: ffff88012a65fbc0 R08: 000000000000000a R09: 00000000000085d6 [80085.820550] R10: 0000000000000005 R11: ffffffff819fe16d R12: ffff88012a65fbf0 [80085.827831] R13: ffff8800abd51a40 R14: ffff88042027c048 R15: ffff8800abd51a40 [80085.835135] FS: 00007f5fe7413700(0000) GS:ffff880433d80000(0000) knlGS:0000000000000000 [80085.843377] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [80085.849279] CR2: 0000000000000000 CR3: 0000000104946000 CR4: 00000000003606f0 [80085.856569] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [80085.863891] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [80085.871196] Stack: [80085.873241] ffffffffa000875c 00007f5fe7412320 ffff88012a65fe88 ffffffffa06a452c [80085.880894] ffff88012a65fc68 ffff88012a65fc60 ffff88012a65fcf0 0000000000000001 [80085.888512] 0000000100000001 00000000007f1700 0000000000000000 0000000000000000 [80085.896131] Call Trace: [80085.898639] [<ffffffffa000875c>] ? rtc_proxy_set_auto_power_on+0x70/0x76 [redpill] [80085.906437] [<ffffffffa06a452c>] synobios_ioctl+0x54c/0x1e50 [apollolake_synobios] [80085.914252] [<ffffffff81131bd9>] ? unlock_page+0x59/0x60 [80085.919748] [<ffffffff8115e837>] ? do_wp_page+0x287/0x650 [80085.925356] [<ffffffff8121ecf9>] ? ext4_getattr+0x19/0x90 [80085.930980] [<ffffffff81194a20>] ? cp_new_stat+0x110/0x120 [80085.936674] [<ffffffff811a70d2>] do_vfs_ioctl+0x4d2/0x960 [80085.942248] [<ffffffff811a7601>] SyS_ioctl+0xa1/0xb0 [80085.947395] [<ffffffff81579c4a>] entry_SYSCALL_64_fastpath+0x1e/0x8e [80085.953945] Code: 90 90 90 90 90 eb 1e 0f 1f 00 48 89 f8 48 89 d1 48 c1 e9 03 83 e2 07 f3 48 a5 89 d1 f3 a4 c3 66 0f 1f 44 00 00 48 89 f8 48 89 d1 <f3> a4 c3 0f 1f 80 00 00 00 00 48 89 f8 48 83 fa 20 72 7e 40 38 [80085.974293] RIP [<ffffffff812fd1e6>] memcpy_erms+0x6/0x10 [80085.979909] RSP <ffff88012a65fbb0> [80085.983480] CR2: 0000000000000000 [80085.986852] ---[ end trace 487f34b257519703 ]---
Fixed in the new release (bug in memory handling).
On 9/8/2021 at 8:49 PM, mcdull said:seems 918 is in many way better than 3615
It's a shame that Intel artificially limited MOVBE instruction to Atoms and then enabled it again only in new Xeons. That's actually the only reason why 918+ doesn't work on older CPUs.
On 9/8/2021 at 9:09 PM, abesus said:Hello again.
I've got question: how can I add additional param to kernel. I want to pass intel_iommu=off.
Is user_config.json a good place for that?
Yes, add them as key:value pairs to "extra_cmdline" key in your user_config.json
On 9/9/2021 at 12:39 AM, MastaG said:any idea where I can get the patched kernel sources for linux-3.10.108 used in 7.0.1-42214 ?
the toolchain only contains the pre-compiled kernel headers, not the full source...You can't get them - syno didn't publish them yet... the only way to compile modules is to do it with their toolchain sources.
--------------------------------------------------------
[to be continued in a next post due to forum limits]
-
3
-
9
-
-
Today we will break the tradition a bit and respond to all questions first. Since the forum has a limit of 50 quoted posts we have to split our response into multiple posts
The last post will be with the actual code updates so if you're reading it and not seeing a post with updates - just wait - we're writing as you're reading this.
------------------------------------------
On 8/29/2021 at 4:21 PM, coint_cho said:Oh I've rechecked my config and somehow it automatically reverted back to e1000 for some reason.. changed it to e1000e and I'm getting an IP and currently have installed DiskStation on it, but right now another road block unfortunately.
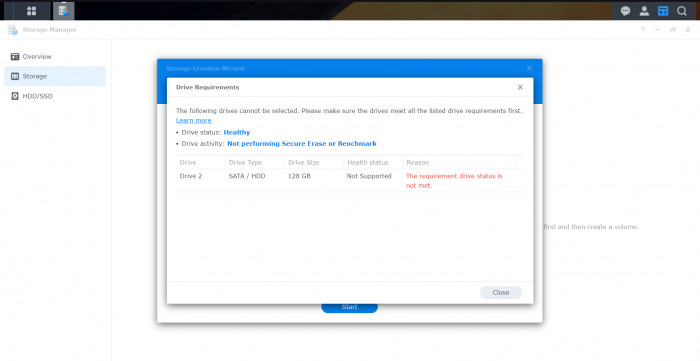
I've seen other people with the same issues here so.. it's a 128GB SATA disk mounted in VMWare.
It's fixed in the today's relese
[will be up on GH after the update post]
On 8/29/2021 at 4:25 PM, haydibe said:@ThorGroup thank you once again for the update and adressing all issues that come up!
Would you mind to provide some insights about where `"DiskIdxMap": "0C", "SataPortMap": "1", "SasIdxMap": "0"` actualy are ment to be configured in the user_config.json? According the redpill-load README.md it should be a k/v structure specified in "synoinfo". Though so far everyone seems to add them in "extra_cmdline".
Is this the intended usage?... "synoinfo": { "DiskIdxMap": "OC", "SataPortMap": "1", "SasIdxMap": "0" }, ...
Afterall, those parameters are not only usefull for those that use sata_dom boot, but also for those that use the usb boot and want to bring order into the drive ordering.
Note: I believe SasIdxMap is not required if no sas controller is passed into the vm, on the other side it doesn't seem to make any harm.
The difference between synoinfo and cmdline is subtle but important. The synoinfo defines the properties of the platform and is mainly used to configure the DSM itself (e.g. how many drives it sees in the UI, does it allow for creation of the SHR etc). These settings can often be changed and everything will work. For example some models don't support VMM not because it wouldn't run but because running anything besides a hello world on it will exhaust all the resources. Cmdline parameters in the other hand configure the kernel directly. Changing them to something inappropriate can often lead to the sysem not booting at all or not seeing disks or not being able to get an IP address from DHCP (e.g. when you set a wrong MAC).
The DiskIdxMap, SataPortMap, and SasIdxMap are all cmdline parameters. Putting them in the synoinfo section will produce no results. They must be put in cmdline as they're read by the SCSI driver in the kernel. There's no connection between synoinfo and cmdline reading routines at all. As for how to configure them that short thread explains this very well:
Setting SasIdxMap does nothing if you have no SAS controller. These options are internally stored in variables inside of the kernel but only used when the actual drive is connected to a given controller. Without that they have no effect.
On 8/29/2021 at 4:57 PM, gadreel said:@ThorGroup as always thanks for taking the time to reply to all those posts and assist all of us.
Now that the loader works for most (maybe all) users in order to make testing easier and efficient I have a stupid question to ask. When you add new commits to your repositories and we generate the new bootloader with haydbibe's docker solution in order to test properly do we have to format the disks/delete and recreate the virtio sata disks and start the installation procedure all over again or just boot with the newly generated bootloader from the previous installation and if it works then all is good?
You only need to replace the boot image. In fact internally we simply have a drive in proxmox with "sata0: file=/our/data/store/image.img". We just replace the file and restart the VM to boot from a new one. Due to some QEmu peculiarities it's recommended to shut down the VM, wait few seconds, and start it again (as restart SOMETIMES may not read the full image again for some unknown reasons).
On 8/29/2021 at 5:48 PM, coint_cho said:Ok, after a few trial and errors, currently I've identified that DS918+ can't be booted and installed since the bootloader will be counted in DiskStation together and it will format that vdk as well(DS918+ only has USB boot option), while the DS3615XS can be booted from both USB/SATA(Storage doesn't work and will only show not compatible unfortunately), selecting booting from SATA doesn't prompt me to format my bootloader vdk image, anyone knows any workaround for this? (I'm using VMWare Workstation 16). However, it can be booted from USB and installed in Proxmox with no issues(Referring to DS918+ Apollo Lake).
The 918+ now has an experimental SATA support
On 8/29/2021 at 6:34 PM, dodo-dk said:I have read the q35 is better than i440fx. So I switch to q35 but with that, the boot takes longer and my Volume2 is crashed.
I doesn't found all Harddrives. I have one Virtual and 5 Passtrough Disks. I have switched back to i440fx and all works, thanks god, Volume2 is back.
Do I need mapping or something with the q35 settings?
As haydibe mentioned you need to configure the mapping. Q35 is better because it's a newer platform + supports things like PCI-Ex passthrough. Once you configure the proper DiskIdxMap and SataPortMap it will see all disks (and the array will not be crashed as it will not see disks as missing).
This whole problem exists because disks beyond 26th are starting to be named e.g. /dev/sdaa, /dev/sdab, /dev/sdac... and this schema is not supported by the OS. To our knowledge there are no devices from syno with >26 disks without a SAS controller.
On 8/29/2021 at 9:37 PM, haydibe said:Actualy I have never seen a QEMU XML. Haven't sumbled accross it on Proxmox so far, no such files are location in /etc or /lib.
I have yet to understand if Proxmox allows that level of configuration for storage.
Update: seems Unraid uses libvirt as a wrapper arround QEMU/KVM. Proxmox directly instructs QEMU/KVM (Warning: do not try to intall libvirt on Proxmox, it might break your installation!).
These XMLs are a standardized way to use libvirt. Proxmox went its own way as both were developed kind of in the same time. Additionally, what most of the people don't know, configuration "files" in proxmox aren't files - they're stored in a synchronized SQLite database and just presented as a filesystem
This allows for efficient cluster synchronization.
On 8/29/2021 at 9:45 PM, gadreel said:Thanks for replying. I will leave it as is if it will not cause any issues...
Because if I remember correct maybe I read something somewhere (I could be very wrong) that DS918+ cannot take more than 12 drives, but maybe that has nothing to do with those numbers.
We didn't try ourselves but you can attempt to set synoinfo "maxdisks" parameter beyond 16. Theoretically it should be able to host 26 drives if mapping in cmdline is set properly.
On 8/30/2021 at 12:15 AM, T-REX-XP said:@ThorGroupDo you have an example how to use the PMU emulation?? Any examples ?? Thanks in advance.
As I saw, now all communication with PMU will be mirrored to /dev/ttyS1 so we can easily find the output of the PMU when some sort of FAN or beep settings has been changed in the DSM settings. For example Fan speed set to Quite mode
[ 2250.254824] <redpill/pmu_shim.c:324> Got 1 bytes from PMU: reason=1 hex={2d} ascii="-" [ 2250.476426] <redpill/pmu_shim.c:324> Got 1 bytes from PMU: reason=1 hex={6b} ascii="k" [ 2250.493676] <redpill/pmu_shim.c:249> Unknown 1 byte PMU command with signature hex="6b" ascii="k"
It give us the possibility to connect Arduino and try to build the our own PMU with hardware copy button))
That's the goal - we want to provide an interface which simply sends commands to an arduino-like device which can serve that. The fan control is... strange. It seems to always send "k" no matter what. There is probably something we've missed (or maybe it goes through the mfgBIOS ioctl? either way both outputs need to be combined).
On 8/30/2021 at 12:50 AM, yanjun said:@ThorGroup I put the full logs of my boot stage.
In addition, this hba card works normally on Jun’s 1.04b loader, and the bios type is OVMF (UEFI). I know this does not mean it is a redpill problem, it may also be a compatibility problem between SEABIOS and HBA card, but so far, I don't know how to solve it
That could be an issue with the card being seen as a proper SAS device. After quickly asking around none of have any free LSI card running in a server to test but we will look into it. Can you put a GH issue in the kernel module repo? It probably needs a small kick similar to VirtIO SCSI - currently as you see the SCSI driver attempts to add a disk with a "/dev/" name (literally empty name) which should and will fail. The problem lies somewhere in the syno modifications to the SCSI driver.
On 8/30/2021 at 12:56 AM, tocinillo2 said:@ThorGroupthanks for the update! My request about uefi support it's not about performance, it' because a lot of apollolake and apollolake refresh mainboards doesn't support legacy boot (or CSM) like J4105, J4125, J5040, J5005 and new models.
Again, thanks for this fanstatic work!
That is a good point. We will take this into consideration then and offer a hybrid-boot version supporting BIOS and EFI in a single image, with the default recommendation of a BIOS boot.
On 8/30/2021 at 2:50 AM, mcdull said:I have some issue in migrating.
I do have some images with facial recognition when old version in Jun's loader still works. But now it is must not work with DSM7 (I uses AMD cpu) and no GPU at all.
Now the synology photos keep telling me that its trying to migrate from old photos and moments app, and keep waiting the 30000+ photos to complete.
Any suggestions for me?
Someone mentioned the problem with facial recognition & v7. There should be a separate thread for that as this is an issue with the photo app and its checking of S/N (it has to be a real one or the binary of photo app must be patched). This is out of scope of the loader part
On 8/30/2021 at 6:01 AM, apriliars3 said:I have the same issue. Any idea that how can fix it? I test it with VMWare.
See the next post with updates - now ESXi is supported with SMART emulation.
On 8/30/2021 at 1:59 PM, scoobdriver said:do you know if there are any models which support Sata DoM and HW transcoding please?
With this update you can use 918+ [will be on GH after the update post below]. We are looking into one of the models with native support for nVidia GPUs so that transcoding can work with either Intel QS or NVENC. While there are hacks to run the nVidia driver on other platforms its cumbersome and possibly unstable (as, putting it mildly, nV drivers are .... picky). We want to go that route as people with AMD cannot use Intel QS and cards like Quadro P200 are cheap, low power (peak of like 25-30W), and have plenty of enc/dec power (IIRC 7 streams at once).
On 8/30/2021 at 4:44 PM, hoangminh88 said:I checked: We can use Balena Atcher to burn USB
Yes, on Windows it's a pretty good tool. On macOS or Linux the dd is the simplest and already present in the system
On 8/30/2021 at 4:49 PM, scoobdriver said:Wish I could try it , but I'm using ESXi and there is no Sata Dom support , so It won't load . (So using 3615+ DSM 7.0 beta )
Does DS918+ 7.0 have the i915.ko ?
Now [will be on GH after the update post below] the support for ESXi & SATA boot on 918+ so you should be good to go.
On 8/30/2021 at 5:40 PM, Orphée said:What we actually do is qemu-img on Linux + vmkfstools - ESXi is very picky as to VMDKs. Older versions worked great but ESXi 6 and 7 often refuse to properly use VMDKs created by something else than VMWare products. This is why "vmkfstools -i input.vmdk output.vmkd -d thin" works and actually makes an image which works properly with VMWare.
On 8/30/2021 at 5:43 PM, psychoboi32 said:
please play with it i tried several times but it not loaded by any means even i installed esxi on spare disk to get it working end result is same not loaded
edit :- you got loaded wow i didn’t get that far means i want to make image which preloads that so i didn’t add any drive just lsi sas card and drives not detected at all
Sent from my iPhone using TapatalkAh, yes... it seems like new syno SCSI driver sees the disks as SAS instead of SATA. You have to play with SasIdxMap then... or we can add a small patch like with VirtIO SCSI to make sure they're treated like SATA. However, DSM should theoretically handle it just fine for data disks (but not for the boot disk). Once we get a free LSI to test we will look into that. Can you post an issue on GH in the kernel module repo?
On 8/30/2021 at 5:53 PM, Orphée said:I tried under ubuntu VM but it failed for me... the converted vmdk was not working. Whereas V2V converter did the job.
If you use ESXi try doing "vmkfstools -i input.vmdk output.vmkd -d thin" on the ESXi box after qemu-img - for some weird reason newer versions of ESXi refuse to even see a normal VMDK if it wasn't made by their tools...
On 8/30/2021 at 6:05 PM, pocopico said:Hi,
the same happens for virtual disks as well but this workaround works fine for now
https://github.com/RedPill-TTG/redpill-lkm/issues/14#issuecomment-903683483
Now, with SMART emulation, that workaround is no longer needed
A new release will be posted on GH as soon as we finish fighing with the forum edit to post all posts.
On 8/30/2021 at 11:30 PM, jforts said:Hi, I try the redpill-loader with baremetal, I cannot access to any serial port, how to access the console from a monitor and keyboard?
Because the screen froze at Booting the kernel...
The issue with baremetal is that you cannot see any output or console if you don't have a serial port. The syno kernel is built without VGA support, so you only see the output from preboot as kernel simply doesn't initialize GPU (so it's not really frozen per se but just not initialized after GRUB passes the control to the kernel).
On 8/31/2021 at 5:12 AM, Amoureux said:@ThorGroup I have some errors after install DSM7.0 on my hardware.
[ 2.574597] redpill: module verification failed: signature and/or required key missing - tainting kernel [ 3.243540] <redpill/override_symbol.c:404> Failed to locate vaddr for sys_call_table using kallsyms - falling back to memory search [ 7.654945] intel-lpss: probe of 0001:00:16.0 failed with error -22 [ 7.661824] intel-lpss: probe of 0001:00:18.0 failed with error -22 [ 7.668735] intel-lpss: probe of 0001:00:19.0 failed with error -22 [ 7.675644] intel-lpss: probe of 0001:00:19.2 failed with error -22 [ 16.797306] ahci: probe of 0001:01:00.0 failed with error -22 [ 16.803420] ahci: probe of 0001:00:12.0 failed with error -22 [ 17.338180] xhci_hcd 0001:00:15.0: init 0001:00:15.0 fail, -16 [ 17.344410] xhci_hcd: probe of 0001:00:15.0 failed with error -16 [ 17.755953] <redpill/bios_shim.c:207> Symbol #29 in mfgBIOS "apollolake_synobios" {synobios_record_scsi_error_event}<ffffffffa00ba480> [ 17.794780] <redpill/bios_shim.c:207> Symbol #32 in mfgBIOS "apollolake_synobios" {synobios_disk_reset_fail_report}<ffffffffa00ba580> [ 17.832428] <redpill/bios_shim.c:207> Symbol #35 in mfgBIOS "apollolake_synobios" {synobios_sata_error_report}<ffffffffa00ba690> [ 17.891199] <redpill/bios_shim.c:207> Symbol #39 in mfgBIOS "apollolake_synobios" {synobios_error_fs_btrfs_event}<ffffffffa00ba7e0> [ 17.903689] <redpill/bios_shim.c:207> Symbol #40 in mfgBIOS "apollolake_synobios" {synobios_error_fs_event}<ffffffffa00ba830> [ 17.952685] <redpill/bios_shim.c:207> Symbol #44 in mfgBIOS "apollolake_synobios" {synobios_error_oom_event}<ffffffffa00baa50> [ 18.418432] <redpill/bios_shim.c:207> Symbol #83 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c4800> [ 18.535314] <redpill/bios_shim.c:207> Symbol #93 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c4c40> [ 18.647725] <redpill/bios_shim.c:207> Symbol #103 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c5080> [ 18.761576] <redpill/bios_shim.c:207> Symbol #113 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c54c0> [ 18.881884] <redpill/bios_shim.c:207> Symbol #123 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c5900> [ 18.995030] <redpill/bios_shim.c:207> Symbol #133 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c5d40> [ 19.112728] <redpill/bios_shim.c:207> Symbol #143 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c6180> [ 19.226639] <redpill/bios_shim.c:207> Symbol #153 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c65c0> [ 19.339744] <redpill/bios_shim.c:207> Symbol #163 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa00c6a20> [ 20.754211] usb 1-12: device descriptor read/64, error -71 [ 20.979213] usb 1-12: device descriptor read/64, error -71 [ 21.336220] usb 1-12: device descriptor read/64, error -71 [ 21.570232] usb 1-12: device descriptor read/64, error -71 [ 22.743253] usb 1-12: device not accepting address 6, error -71 [ 23.293258] usb 1-12: device not accepting address 7, error -71 [ 32.515336] systemd[1]: Cannot add dependency job for unit SynoLedBrightness.service, ignoring: Unit SynoLedBrightness.service is masked. [ 32.528516] systemd[1]: Cannot add dependency job for unit pkg-install-high-priority-builtin.service, ignoring: Unit pkg-install-high-priority-builtin.service failed to load: No such file or directory. [ 32.547485] systemd[1]: Cannot add dependency job for unit pkg-install-low-priority-builtin.service, ignoring: Unit pkg-install-low-priority-builtin.service failed to load: No such file or directory. [ 34.688838] igb: probe of 0001:02:00.0 failed with error -5 [ 34.694790] igb: probe of 0001:03:00.0 failed with error -5 [ 35.247539] i915 0000:00:02.0: Direct firmware load for i915/kbl_dmc_ver1_04.bin failed with error -2 [ 35.257396] i915 0000:00:02.0: Falling back to user helper [ 36.132828] <redpill/bios_shim.c:207> Symbol #29 in mfgBIOS "apollolake_synobios" {synobios_record_scsi_error_event}<ffffffffa064b480> [ 36.171822] <redpill/bios_shim.c:207> Symbol #32 in mfgBIOS "apollolake_synobios" {synobios_disk_reset_fail_report}<ffffffffa064b580> [ 36.209524] <redpill/bios_shim.c:207> Symbol #35 in mfgBIOS "apollolake_synobios" {synobios_sata_error_report}<ffffffffa064b690> [ 36.261526] <redpill/bios_shim.c:207> Symbol #39 in mfgBIOS "apollolake_synobios" {synobios_error_fs_btrfs_event}<ffffffffa064b7e0> [ 36.274110] <redpill/bios_shim.c:207> Symbol #40 in mfgBIOS "apollolake_synobios" {synobios_error_fs_event}<ffffffffa064b830> [ 36.323244] <redpill/bios_shim.c:207> Symbol #44 in mfgBIOS "apollolake_synobios" {synobios_error_oom_event}<ffffffffa064ba50> [ 36.778878] <redpill/bios_shim.c:207> Symbol #83 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa0655800> [ 36.891358] <redpill/bios_shim.c:207> Symbol #93 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa0655c40> [ 37.004279] <redpill/bios_shim.c:207> Symbol #103 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa0656080> [ 37.118604] <redpill/bios_shim.c:207> Symbol #113 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa06564c0> [ 37.232185] <redpill/bios_shim.c:207> Symbol #123 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa0656900> [ 37.345777] <redpill/bios_shim.c:207> Symbol #133 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa0656d40> [ 37.459209] <redpill/bios_shim.c:207> Symbol #143 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa0657180> [ 37.573346] <redpill/bios_shim.c:207> Symbol #153 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa06575c0> [ 37.687032] <redpill/bios_shim.c:207> Symbol #163 in mfgBIOS "apollolake_synobios" {fan_fail}<ffffffffa0657a20> [ 42.673054] i915 0000:00:02.0: Failed to load DMC firmware i915/kbl_dmc_ver1_04.bin. Disabling runtime power management.
These errors are perfectly normal. The one about syscall table relates to the kernel not exporting the symbol and RP having to manually scan the memory for it. Rest of the errors about USB and GPU are there because we're faking existence of a hardware which doesn't really exists, so drivers are trying to initialize it and realize it's not there (but the OS still thinks it's there - working or not ;)).
On 8/31/2021 at 6:13 AM, maxhartung said:For Proxmox what is the recommended platform ? Also SATA vs USB boot ?
Q35 for platform. As for USB vs SATA it doesn't really matter. SATA is easier to configure as you can do it from the GUI, while virtual USB requires editing of the VM config from the terminal (the officially support that, just the GUI is not there).
On 8/31/2021 at 5:49 PM, maxhartung said:I don't think so. I will try to install Proxmox again on my laptop and see if I can get this running. For Proxmox I think I need the SATA mappings.
Proxmox:
I get file is corrupted...
I used these config
{
"extra_cmdline": {
"pid": "0x1666",
"vid": "0x0951",
"sn": "REMOVED",
"mac1": "0687940FE75F"
},
"synoinfo": {
"DiskIdxMap": "OC",
"SataPortMap": "1",
"SasIdxMap": "0"
},
"ramdisk_copy": {}
}
Options you put in synoinfo belong in extra_cmdline. Besides, that if you're getting a file corrupted error on proxmox try shutting down the VM with "Stop", wait few second, start it again. If it still doesn't work you probably have a corrupted file (which we saw happening here a few times) - just regenerate the loader again.
On 8/31/2021 at 9:02 PM, taiziccf said:why do you need all these SATA port mapping if you are using proxmox????
If you're running QEmu-based virtualization (e.g. Proxmox or VirtualBox) set vid to 0x46f4 and pid to 0x0001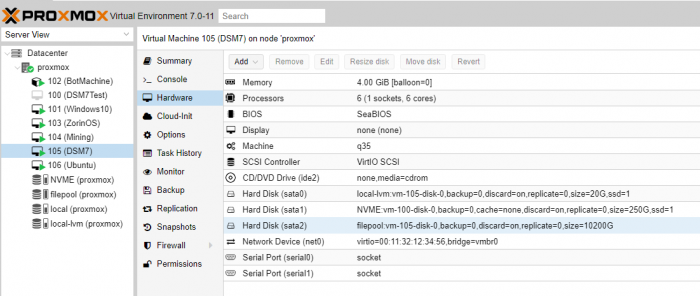
Syno kernel doesn't enumerate disks starting from /dev/sda, so you first disk lands on like 7th position. If you don't care and you don't have a lot of disks you don't have to confiure the mapping. As for the vid/pid these are needed when you're booting from a virtual USB drive on Proxmox (and 0x46f4/ 0x0001 are just the ids which QEmu hardcoded in their source).
On 8/31/2021 at 10:24 PM, maxhartung said:Just to clarify. These settings are for Proxmox, right ? For PID/VID should I use the one from my USB stick or these ones:
If you're running QEmu-based virtualization (e.g. Proxmox or VirtualBox) set vid to 0x46f4 and pid to 0x0001 ?
Curently, I am using the ones from USB like in the picture (attached)
If you're using a real/physical USB drive you need to pass its parameters. In your case vid/pid is 0930/6545 (proxmox shows it in the dropdown).
On 9/1/2021 at 4:37 AM, tocinillo2 said:I'm able to boot DS918+ with UEFI in my J4125 perfectly, detects it and I can start installation process without problem....but the install stop at 99%
Any ideas?
Baremetal
Isn't 99% a reboot? What happens after reboot?
On 9/1/2021 at 6:02 AM, jarugut said:I'm creating a new bootloader for DS3615 6.2.4 with the last github content, for my sorprise I've received the following error.
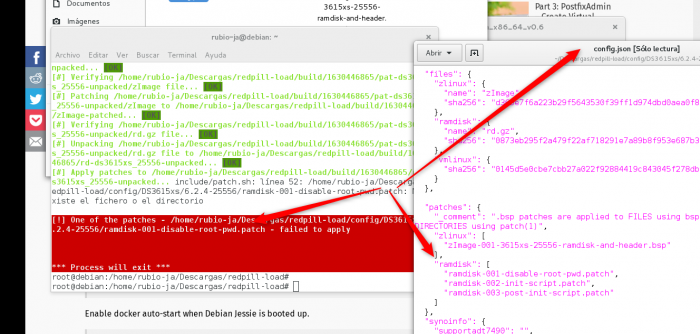
It seems like in the config.json file is configured to apply different patch but the original file not exist anymore.
Is this correct? I can copy the original file from other old copy from my computer but I prefer to ask before do it!
Hm, files seems to be correct in the repos. You can try scrapping both pulls and re-pulling both repos. Previously we used symlinks which was a nightmare. It looks like you still have an old file with symlinks-based approach (and you stepped into an issue with them).
On 9/1/2021 at 7:23 PM, maxhartung said:For one SATA Controller and one disk, there is some mapping to be done ?
Nope, it's just your drive will be shown in a semi-random place and not as a 1st one. The mapping really makes a difference only when you have like 8-9 drives and you go beyond the limit (since it will start with 1st hdd at like 7th position). The disk map is more of a "cherry on the top" so it looks properly in the UI.
On 9/1/2021 at 8:53 PM, gadreel said:@jumkey do you know why the loader does not work if you update to 7.0.1 from DSM? It requires re-patching or something?
Yes, it requires a new kernel patch for new version as offsets change. We were tinkering with making it an automatic patcher but it's still a risk after every version. With the rate of changes in new DSM versions now we're not sure if developing an auto-patching in the preboot makes sense as likely with new version something else has to be updated aswell.
On 9/1/2021 at 9:07 PM, dodo-dk said:@jumkey
I´m not a Windows User but thank you for your work.
How to generate the bsp file?
I have changed the config.json and changed to the "NEW" init patch. IMG Build works but with old BSP (41222) it reboots when it wants to load the Kernel.
DS3615 7.0.1-42214
You absolutely can never ever use old bsp files on a different version of the file. bsp file is like a diff but binary and using it on a different version causes random bytes to be patches in the kernel image. New bsp file can usually be generated by using php scripts from the tools folder. However, for normal use we don't expect non-developers to be doing this as you should blindly generate a bsp and call it a day - there are some checks to verify in a disassembler. The fact that a patch is generated doesn't mean it will work properly.
On 9/1/2021 at 9:26 PM, kennysino said:could you pls post the loader image here?thanks
We will strongly advise to never post full loaders, especially not on the forum if we want it to exist. The loader image contains proprietary syno code and cannot be distributed in any shape or form without risking a copyright strike. This is why we developed a tool to build a loader as the tool doesn't contain any proprietary code and the kernel patches are for a GPL kernel so...
On 9/1/2021 at 11:06 PM, gadreel said:If it was not clear what jumkey said, if you look into red-pill loader repo you will find inside the config folder that bsp file.
Currently the bsp file for 7.0.1 is not there. Either ThorGroup has to update the repo or build it yourself if you know how to...
As Jumkey mentioned in his post, everything it's in the ThorGroup repos how to do all that.
The tools are all there
If you run the loader in patch mode without the bsp it will ask you to patch the kernel and rebuild everything. It will even leave the files so you can simply call bsdiff on two files and call it a day. There's a partial documentation for that in the load repo.
We didn't touch 7.0.1 as we were busy with the code but we don't expect any problems with 7.0.1 - it simply needs a new binary patch file.On 9/2/2021 at 4:19 AM, jarugut said:Hi after copy the patches files on the correct folders inside the last github repo and execute the original procedure to generate the bootloader I've received the following error.
Somebody do you knows the possible reason?
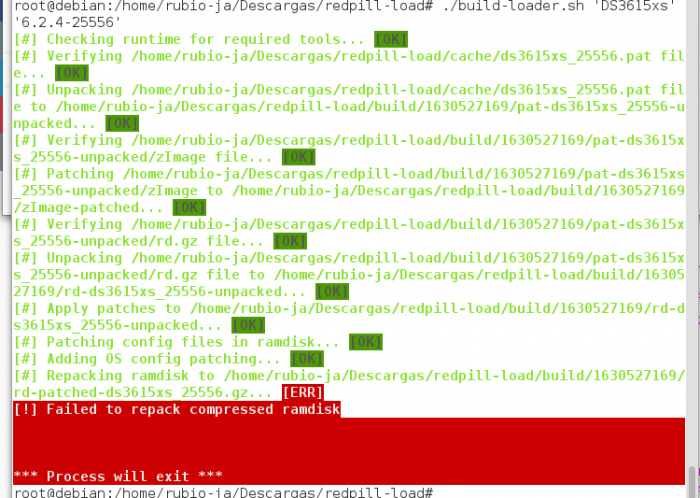
Can you try with debug mode enabled? (add BRP_DEBUG=1 before the command so it becomes BRP_DEBUG=1 ./build_loader....). It will print much more information why it couldn't repack the ramdisk.
On 9/2/2021 at 11:27 AM, jforts said:Okay, I managed to telnet into baremetal, notice that my SATA Controller is able to detect by RedPill.
The stuck at error 55% is due to there is no /dev/synoboot2. Anyone face this problem before?
It doesn't see your bootloader source. Are you using USB or SATA? If it's USB you probably set a wrong VID/PID or connected the USB to a USB3 port (which most of the time will not work due to drivers issues, as 3.0 is a very complex spiderweb in comparison to 2.0).
On 9/2/2021 at 12:00 PM, jforts said:I formatted another USB facing the same result. May I know how to make sure the USB is loaded correctly?
I also notice another error:
Jan 1 00:00:35 raidtool: disk/disk_port_to_container.c:38 Unknown diskType Jan 1 00:00:35 raidtool: partition_path_enum.c:29 Failed to parsing device: name Jan 1 00:00:35 raidtool: external/external_disk_port_check.c:158 expected sdx or /dev/sdx, not ram, not match any port type Jan 1 00:00:35 raidtool: disk/disk_port_to_container.c:38 Unknown diskTypeIs it my USB does not mapped??
That is actually unrelated. This is something which happens all the time, including on real DS hw. The "sdx" refers to like /dev/sdX or /dev/sd<anythingHere>, not the actual sdx drive. You can check the dmesg log. Do "dmesg | grep usb_boot_shim" and it will show you what it saw and if it was shimmed, or maybe the usb stick disconnected or something else.
On 9/2/2021 at 3:10 PM, pocopico said:@jumkey @ThorGroup Could/should we add telnetd at the initrd patch to enable telnet by default for troubleshooting ? Normaly the install will start telnetd right after an installation failure but there are cases where in bare metal this will not happen. E.g. error with the sata mapping
That should actually be automatic and built-in into syno scripting. If it doesn't work can you post an issue in the GH loader generator repo, so we can look at it? Maybe it changed in v7.
On 9/2/2021 at 3:33 PM, maxhartung said:I have the same issue with 1 SATA port with EliteBook 840 G2 (PCIe/M2 slot disabled from BIOS, anyway didn't make a difference if enabled). The mapping didn't help
{
"extra_cmdline": {
"pid": "0x1666",
"vid": "0x0951",
"sn": "XXXXXXXX",
"mac1": "fc3fdb87064f"
},
"synoinfo": {
"DiskIdxMap": "00",
"SataPortMap": "1",
"SasIdxMap": "0"
},
"ramdisk_copy": {}
}
USB drive:
Product ID: 0x1666
Vendor ID: 0x0951 (Kingston Technology Company)
The *Map parameters should be in extra_cmdline. We explained this in details in a response to below.
On 9/2/2021 at 10:29 PM, maxhartung said:Yes, it does, it works out of the box, without any patches required. Just the PID/VID and is ready to go. There is any documentation regarding how mapping should be done ?
What each of the options means ? Someone stated here that should be inside extra_cmd_line section instead of synoinfo, what is the right way ?
I need 1 controller with 1 or 2 ports.
On 9/2/2021 at 10:39 PM, WiteWulf said:Hi folks, I've been sitting and patiently keeping up with this thread since shortly after it started, keenly aware that this is in early development stages, not beta, not intended for use with production data and only for people who know how to compile, test and feedback, etc. 😀
I set up a build environment and successfully compiled everything a week or so ago, but didn't want to test it out yet as the vast majority of talk on here seems to be around virtualised installs, but I'm running bare metal on an HP Gen8 Microserver, upgraded with an Intel Xeon E3-1265L 2.50GHz 4-Core (Ivy Bridge).
Has anyone successfully used RedPill on a baremetal Microserver?
Is RedPill intending to support baremetal, or just virtualisation platforms?
If I need to migrate my install to esxi I'm gonna need a big HDD to back up all my data first 😬
If you're planning to migrate it's better to use Proxmox, ESPECIALLY on microserver. We actually have quite a few of these little cute boxes. If you want to migrate you can leave harddrives as-is and just boot the proxmox out of a SATA drive (you can use the ODD port, it should be on the side of the motherboard and IIRC it's blue and supports only 1.5Gb/s transfer speed). We will be playing with bare metal but it's currently about the drivers. However, gen 8 should work as the ethernet drivers are already included in the DSM.
That being said bare metal support is planned as well
On 9/2/2021 at 11:34 PM, jhoughten said:The thing about the extra_cmd_line is that it just adds that stuff to the linux /zimage command that starts.
You can actually edit this without rebuilding the image.
When the GRUB screen comes up, you can hit the e key to edit the command.
I added DiskIdxMap=00 SataPortMap=1 SasIdxMap=0 to the end of the command - after syno_port_thaw=1
Yup, this is exactly how we test things. If you want to edit the loader and you're on linux you can do "losetup -pF image.img" and do a "mount /dev/loop0p1 /mnt" - then you have a normal grub config file in /mnt. The loader generator does the same thing really. Since it's in bash and with a lot of comments you can take a peek how it does things pretty easily.
On 9/3/2021 at 12:08 AM, WiteWulf said:To be honest, I think it's time I bit the bullet and went virtual. I've been running xpenology for years now and have lost count of the number of problems I've had caused by running baremetal
It's really just the time involved in backing everything up, rebuilding the machine, then restoring data that's holding me back. It's just so much simpler to do an in-place upgrade when it works, and not have to reconfigure all the services (mainly Plex) that are running on it.
Some of our folks needed a LOT of convincing to go VM... some are still grumpy about that. But the technology went really far and virtualization nowadays is way less problematic than bare metal, while also being very efficient in terms of performance. But as we said before ESXi is probably not the greatest choice - Proxmox works much better. If you have any questions regarding it on microserver feel free to ping us: these are amazing machines to this day. Some of ours run with 10 disks
[for uninitated: by default they have 4 slots]
On 9/3/2021 at 1:21 AM, Aigor said:I'v lost some updates, there is some recap to know "state of the art" of bootloader?
ThanksHm, we don't have a centralized place with list of things which are working/not. However, if something isn't an issue on GH it's probably working as we try to add issue we find there as well. Currently, after today's updates [one of my colleagues is writting that post as I'm answering questsions], we can say it's a beta-which-we-don't-call-a-beta
On 9/3/2021 at 1:24 AM, pigr8 said:ok figured out, but the disks connected to the mpt2sas are detected as sas -_- so dsm refuses to use them 😕
DiskStation> insmod /usr/lib/modules/mpt2sas.ko [ 36.102592] mpt2sas version 20.00.00.00 loaded [ 36.104746] scsi0 : Fusion MPT SAS Host [ 36.106132] I/O scheduler elevator not found [ 36.109234] mpt2sas0: 64 BIT PCI BUS DMA ADDRESSING SUPPORTED, total mem (4022016 kB) [ 36.183709] mpt2sas0: MSI-X vectors supported: 1, no of cores: 4, max_msix_vectors: -1 [ 36.188214] mpt2sas 0000:13:00.0: irq 73 for MSI/MSI-X [ 36.195944] mpt2sas0-msix0: PCI-MSI-X enabled: IRQ 73 [ 36.197702] mpt2sas0: iomem(0x00000000fd3f0000), mapped(0xffffc90008540000), size(65536) [ 36.200643] mpt2sas0: ioport(0x0000000000006000), size(256) [ 36.324504] mpt2sas0: Allocated physical memory: size(7445 kB) [ 36.326292] mpt2sas0: Current Controller Queue Depth(3305), Max Controller Queue Depth(3432) [ 36.329512] mpt2sas0: Scatter Gather Elements per IO(128) [ 36.390490] mpt2sas0: LSISAS2008: FWVersion(16.00.00.00), ChipRevision(0x03), BiosVersion(00.00.00.00) [ 36.395798] mpt2sas0: Dell 6Gbps SAS HBA: Vendor(0x1000), Device(0x0072), SSVID(0x1028), SSDID(0x1F1C) [ 36.399919] mpt2sas0: Protocol=(Initiator,Target), Capabilities=(TLR,EEDP,Snapshot Buffer,Diag Trace Buffer,Task Set Full,NCQ) [ 36.405305] mpt2sas0: sending port enable !! [ 36.411397] mpt2sas0: host_add: handle(0x0001), sas_addr(0x590b11c027f7ff00), phys(8) [ 36.417293] mpt2sas0: detecting: handle(0x000d), sas_address(0x4433221104000000), phy(4) [ 36.419977] mpt2sas0: REPORT_LUNS: handle(0x000d), retries(0) [ 36.422124] mpt2sas0: TEST_UNIT_READY: handle(0x000d), lun(0) [ 36.425202] I/O scheduler elevator not found [ 36.427956] I/O scheduler elevator not found [ 36.431578] scsi 0:0:0:0: Direct-Access WDC WD20PURZ-85GU6Y0 0A80 PQ: 0 ANSI: 6 [ 36.435117] scsi 0:0:0:0: SATA: handle(0x000d), sas_addr(0x4433221104000000), phy(4), device_name(0x50014ee20f84b83c) [ 36.438294] scsi 0:0:0:0: SATA: enclosure_logical_id(0x590b11c027f7ff00), slot(7) [ 36.441957] scsi 0:0:0:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) [ 36.445386] scsi 0:0:0:0: serial_number( WD-WCC4M6XXDE3R) [ 36.447318] scsi 0:0:0:0: qdepth(32), tagged(1), simple(0), ordered(0), scsi_level(7), cmd_que(1) [ 36.450226] <redpill/sata_boot_shim.c:305> Probing SCSI device using sd_probe_shim [ 36.453332] <redpill/sata_boot_shim.c:307> sd_probe_shim: new SCSI device connected - it's not a SATA disk, ignoring [ 36.456873] <redpill/sata_boot_shim.c:321> Handing over probing from sd_probe_shim to sd_probe [ 36.459910] sd 0:0:0:0: Attached scsi generic sg0 type 0 [ 36.463739] sd 0:0:0:0: [sas1] 3907029168 512-byte logical blocks: (2.00 TB/1.81 TiB) [ 36.466779] sd 0:0:0:0: [sas1] 4096-byte physical blocks [ 36.474036] sd 0:0:0:0: [sas1] Write Protect is off [ 36.474739] mpt2sas0: port enable: SUCCESS [ 36.477888] sd 0:0:0:0: [sas1] Mode Sense: 7f 00 10 08 DiskStation> [ 36.482099] sd 0:0:0:0: [sas1] Write cache: enabled, read cache: enabled, supports DPO and FUA [ 36.505347] sas1: p1 p2 p3 p4 [ 36.515222] sd 0:0:0:0: [sas1] Attached SCSI disk
It will be a problem with booting from SAS but isn't DSM seeing them as data disks? Which LSI card are you running? Can you put an issue on GH in the kernel module repo for this, so we don't forget?
On 9/3/2021 at 1:26 AM, Dreadnought said:or Parallels, what I am using.
Is Parallels also lacking SMART? It should work with the new release from today. We didn't test specifically on Parallels but the code we wrote isn't specific to ESXi (and it even works with a IDE => SATA adapter which we tested for fun).
On 9/3/2021 at 7:21 AM, maxhartung said:Thanks a lot for these tips. Unfortunately still not working:
Tried: DiskIdxMap=00 SataPortMap=4 -> We have detected errors on the hard drives 1,3,4
Tried: DiskIdxMap=00 SataPortMap=3 -> We have detected errors on the hard drives 1,3
Tried: DiskIdxMap=00 SataPortMap=2 -> We have detected errors on the hard drives 1
Tried: DiskIdxMap=00 SataPortMap=1 -> No drives detected
Tried: DiskIdxMap=00 SataPortMap=0 -> not loading/no network
Tried: DiskIdxMap=00 SataPortMap=1 SasIdxMap=0 -> No drives detected
Tried: DiskIdxMap=00 SataPortMap=2 SasIdxMap=0 -> We have detected errors on the hard drives 1
Tried: DiskIdxMap=01 SataPortMap=1 -> No drives detected
Tried: DiskIdxMap=01 SataPortMap=2 -> We have detected errors on the hard drives 2
Do you have a serial console by any chance? If so can you post the full dmesg output?
On 9/3/2021 at 4:06 PM, Aigor said:Do this method works with other drivers? I'm thinking to network card's driver other then intel
Yes, you can add any driver like that really. You may need to modify the patch for init file to do an insmod. It's not a solution for a long-term and easy-to-use loader but if we use it to add an ethernet driver as well.
On 9/3/2021 at 4:10 PM, sebg35 said:Preview For messages :
Sep 3 07:48:26 raidtool: external/external_disk_port_check.c:158 expected sdx or /dev/sdx, not ram, not match any port type [...] Sep 3 07:48:25 synodiskport: external/external_disk_port_check.c:158 expected sdx or /dev/sdx, not md, not match any port type Sep 3 07:48:26 raidtool: space_error_log.c:47 SpaceCommand:command="/sbin/mdadm --zero-superblock /dev/sda1" Error="" Sep 3 07:48:26 raidtool: raid_internal_lib.c:90 [Info] Clean RAID superblock on '/dev/sda1' Sep 3 07:48:26 kernel: [ 727.226044] md1: detected capacity change from 2147418112 to 0 Sep 3 07:48:26 kernel: [ 727.226759] md: md1: set sda2 to auto_remap [0] Sep 3 07:48:26 kernel: [ 727.227301] md: md1 stopped. Sep 3 07:48:26 kernel: [ 727.227656] md: unbind<sda2 [...] Sep 3 07:57:25 updater: updater.c:3211 orgBuildNumber = 41890, newBuildNumber=41890 Sep 3 07:57:25 updater: util/updater_util.cpp:86 fail to read company in /tmpRoot//etc.defaults/synoinfo.conf Sep 3 07:57:25 updater: updater.c:7029 ==== Start flash update ==== Sep 3 07:57:25 updater: updater.c:7033 This is X86 platform Sep 3 07:57:25 updater: boot/boot_lock.c(228): failed to mount boot device /dev/synoboot2 /tmp/bootmnt (errno:2) Sep 3 07:57:25 updater: updater.c:6494 Failed to mount boot partition Sep 3 07:57:25 updater: updater.c:3118 No need to reset reason for v.41890 Sep 3 07:57:25 updater: updater.c:7636 Failed to accomplish the update! (errno = 21) Sep 3 07:57:25 install.cgi: ninstaller.c:1546 Executing [/tmpData/upd@te/updater -v /tmpData > /dev/null 2>&1] error[21] Sep 3 07:57:27 install.cgi: ninstaller.c:123 Mount partion /dev/md0 /tmpRoot Sep 3 07:57:27 install.cgi: ninstaller.c:1515 Moving updater for configuration upgrade...cmd=[/bin/mv -f /tmpData/upd@te/updater /tmpRoot/.updater > /dev/null 2>&1] Sep 3 07:57:27 install.cgi: ninstaller.c:152 umount partition /tmpRoot Sep 3 07:57:27 install.cgi: ErrFHOSTCleanPatchDirFile: After updating /tmpData/upd@te...cmd=[/bin/rm -rf /tmpData/upd@te > /dev/null 2>&1] Sep 3 07:57:27 install.cgi: ErrFHOSTCleanPatchDirFile: Remove /tmpData/upd@te.pat... Sep 3 07:57:27 install.cgi: ErrFHOSTDoUpgrade(1794): child process failed, retv=-21 Sep 3 07:57:27 install.cgi: ninstaller.c:1811(ErrFHOSTDoUpgrade) err=[-1] Sep 3 07:57:27 install.cgi: ninstaller.c:1815(ErrFHOSTDoUpgrade) retv=[-21] Sep 3 07:57:27 install.cgi: install.c:409 Upgrade by the manual patch fail. Sep 3 07:57:27 install.cgi: install.c:678 Upgrade by the uploaded patch /tmpData/@autoupdate/upload.pat fail. Jan 1 00:00:00 install.cgi: ninstaller.c:152 umount partition /tmpData
Your problem lies in lack of /dev/synoboot. Previously if you were using ESXi and you had to use a physical USB flash drive. Since this release you can experiment with SATA boot. Your log shows you've booted with USB boot but you have no usb drives in your system.
On 9/3/2021 at 11:00 PM, WiteWulf said:The problem is that when the Gen8 boots it completely ignores the USB stick the redpill image on it and attempts to netboot. [...] I just can't figure out why the Gen8 is refusing to boot from it.
Try booting from the port INSIDE of the microserver. Some of the ports on the microserver are finicky for booting as HPE BIOS is strange at times.
On 9/4/2021 at 12:44 AM, WiteWulf said:*edit* this is an interesting thread on the topic, although few years (and ESXi revisions) old now:
https://homeservershow.com/forums/topic/14778-esxi-65-ahci-bad-write-performance/
ESXi doens't play well with older hardware. Proxmox will be a better choice here
On 9/4/2021 at 4:06 AM, haydibe said:Oh boy🙄 This will leave plenty of fun for LSI9211 owner that want to migrate from (jun's) 6.2.3 to (redpill) 7.0. Must be a behavior of the mpt2sas driver itself - almost looks like they change from /dev/sd? to /dev/sas? at one point and the new drivers happen to be created from sources after that change? Afaik Bromolow DSM6.2.3 uses 3.10.105. and the change logs of https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/ChangeLog-3.10.106, https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/ChangeLog-3.10.107 or https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/ChangeLog-3.10.108 (which is what the bromolow DSM7.0 kernel sources base on) indicate nothing that would point to such a change (or anything helpfull).. But what caused the different detection then?
I expect lvm/mdam raids to identify the drives belong to an array by device path (/dev/sd?) and not by the physical controller they are attached to - thus a switch from /dev/sd? to /dev/sas? will result in a broken array?! I hope I realy got this wrong and some sort of magic that relies on disk-uuid, serialnumber or whatever is used to self-heal the situation.
They (syno) heavily modify the drivers and the kernel. The array will be fine if the DSM will be able to recognize the SAS devices as the arrays are recognized and built using metadata on disks itself. Where the devices are doesn't matter for the raid subsystem, only the DSM tools care. On a normal Linux box you can have the drive be under /dev/test123 and it will work
This is why you should never clone 1:1 disk with arrays on the same system which mounts them.
-------
to be continued in the next post due to forum limits
-
4
-
5
-
-
It has been over a week but we're not slowing down!
PMU emulation is here
This was the biggest feature we were working on, which involved fixing many things around to actually make it stable. The current implementation keeps all the data internally. None of the requests sent by the actual OS needed to be responded to directly, as we shimmed mfgBIOS. However, the interface allows for a very easy plug-in of any hardware-based emulation of the PMU to emulate LEDs etc. The important part here this was one of the bigger roadblocks to make the implementation stable and actually know what the OS is asking for. The PMU emulation appears to be stable from our testing but we are sure you guys will find something quickly
The PMU shim was enabled in https://github.com/RedPill-TTG/redpill-lkm/commit/23578eb
Driver watching subsystem
Since we've changed how the LKM is loaded to make sure we shim everything as quickly as possible it introduced a lot of race conditions. This bit us severely during PMU testing and actually delayed this post & update by a few days. The new driver watching subsystem allows for a quick and easy drivers watching so that we actually load things AS SOON as drivers are initialized by the system (but not earlier).See the following commits for details:
- https://github.com/RedPill-TTG/redpill-lkm/commit/a34a54b
- https://github.com/RedPill-TTG/redpill-lkm/commit/3f90ee3
Refactor symbols override
We were getting reports about execve() shim being unreliable (e.g. in this issue: https://github.com/RedPill-TTG/redpill-lkm/issues/3 ). However, even thou we patched the problem the underlying issue was still there and the problem was cropping up in other places as well. This took as quite literally close to 100h to track and fix.The previous implementation which we inherited had a critical bug - it wasn't handling the memory barriers & unlocking properly. To be fair, we cannot blame anyone here as the Linux kernel is lying a bit. The thing is the kernel developers over the years try to make harder and harder to modify (or in their, very correct, view damage) the running kernel. The previous implementation (unintentionally) relied on x86 CR0 which is a per-core flag completely disabling memory protection. This didn't allow for flexible memory management (limiting performance of original calls), forced preemption disabling (i.e. kernel couldn't reschedule tasks flexibly), and others. Normally, the kernel contains an API called set_memory_rw/set_memory_ro, which was actually called from the previous implementation. However, these calls did nothing to the kernel memory as somewhere before v3.0 (~2.6, we didn't check precisely) the kernel introduced a forceful kernel region protection. This means that the kernel SILENTLY removed the R/W flag from our requests.... we solved that by using the low-level page table API directly. By itself that wasn't difficult to implement. But to find the core of the problem, that was occurring randomly and required a full reboot every time we wanted to test the change, frustrated us greatly. But we are here for fun so we did it
Along the new change we reworked the API to make memory management there easier (=less buggy). The new implementation is not yet used everywhere yet. Currently, the driver watcher (used for vUART and in consequence for PMU shim) is the first test bed. However, we are confident enough that we went ahead and closed the execve() issue.
See this commit for details: https://github.com/RedPill-TTG/redpill-lkm/commit/140250a
Rework UART swapper [3615xs]
Anyone who tried to use the serial console on 3615 saw that annoying "-" added every letter entered. Sadly that was a symptom of a bigger issue. We saw these reports in multiple issued (e.g. https://github.com/RedPill-TTG/redpill-load/issues/6 ). Annoyingly the method used was also buggy which was shown in https://github.com/RedPill-TTG/redpill-lkm/issues/10 - now all the problems are gone. The console on devices with swapped UARTs (e.g. 3615xs) works perfectly on any software.See these commits for details:
- https://github.com/RedPill-TTG/redpill-lkm/commit/22d4019
- https://github.com/RedPill-TTG/redpill-lkm/commit/601c7e9
======================================
Smaller changesLinux v4 & FIFO changes
Linux v4 (or actually Linux v3.13+ to be precise) introduced annoying changes in the FIFO handling by changing the API. This was also responsible for warnings logged during build for 918+ platform. Now it all should be fixed.See the commit for details: https://github.com/RedPill-TTG/redpill-lkm/commit/4427b74
Fix Linux v4 [918+] IRQ scheduling
This is small-yet-important fix. It will make sure the vUART is stable on Linux v4 and doesn't cause kernel warning regarding scheduler.See this commit for details: https://github.com/RedPill-TTG/redpill-lkm/commit/0891902
GRUB now supports serial console
Following what Jun's loader had and what is actually very useful while playing on systems like QNAP and other bare-metal ones without GPU (or with GPU capable of using an ancient VGA only ;)).See the commit: https://github.com/RedPill-TTG/redpill-load/commit/72360ef
More docs
We've added more details about mfgBIOS ioctls and PMU itself. Most (but not all) commands are actually somewhat documented in the SDK with vague constants.See these commits:
- https://github.com/RedPill-TTG/dsm-research/commit/f713373
- https://github.com/RedPill-TTG/dsm-research/commit/5c6db49
==================================================================================================Now we will try to reply to as many comments as possible
On 8/20/2021 at 2:38 AM, scoobdriver said:Just add the ARG's DiskIdxMap=1000 SataPortMap=4 to your boot parameters if you want to use a different Sata Controller for the Data Disk in ESXi .
I've done this on Esxi 6.7 with redpilll DSM7 bromolow ,
The Data Disk then shows up as Disk 1 , and you don't see the synoboot disk .
I added the redpill.vmdk to Sata 0:0 , and the data disk to 1:0
It images and boots..
(spoiler, I'm not able to create a volume with it, as it states incompatible )
That shouldn't actually be required. Any number of controllers (up to 26 drives total) should work properly as long as an expander is not used (as these aren't supported by DSM kernel).
On 8/20/2021 at 2:40 AM, psychoboi32 said:0080 10000072 b e001 fe5a0004 0 fe500004 0 0 fe200000 100 10000 0 40000 0 0 100000 mpt3sas
I am heading in patching DSDT, may be that will give me something i want.
I thought same may be sata is conflicting so I remove all sata device use USB for booting and LSI-sas-2008 card as it is but no device found from log I can't BTRFS something because these have connected drives which in SHR (Don't worry I already backed my important stuff). but from log it is not loading my pcie card that what I felt so DSDT is my guess hope you guide me
edit 1:- reading docs gives me idea jun using shimming method
so here it is but I can understand DSDT (used and patch in hackintosh) but this is totally new this output if this help anyone that will be great anyone wants DSDT from jun loader you can PM me0080 10000072 b e001 fe5a0004 0 fe500004 0 0 fe200000 100 10000 0 40000 0 0 100000 mpt3sasJun's loader does not use DSDT patching. It actually monkey-patches routines in the kernel which are responsible for listing devices to the userland. RP takes a different approach by emulating a separate PCI bridge (the vPCI submodule). Messing with DSDT is... messy. It can be done as the hackintosh community is doing that but then it requires separate patches for every platform or their automation. Since we have an open-source kernel (more or less) it's easier to patch it there.
On 8/20/2021 at 2:58 AM, T-REX-XP said:@ThorGroup, is it possible to map internal ssd as hdd, that is available for installer? There are a lot of single board pc with embedded ssd. It will be a good chance use them as energy efficiency solutions or portable nas. I have one os them, so I can provide any logs, etc...
Thanks.
Why would you do that? If you're doing bare metal the DSM is perfectly fine with using an SSD. Emulating SSD as HDD can actually be destructive to the SSD as the OS will not know that the underlying storage is a flash media.
If you want to use the internal SSD/flash storage as the install media you surely can. If it's a SATA-based one just boot with SATA support. If it's USB just take the vid/pid and put it into the config.On 8/20/2021 at 3:05 AM, T-REX-XP said:For example, atomic pi, latte panda, chuwi larchbox, etc... no name intel based pc from aliexpress.
In such cases, as long as they're x86_64 based (not just 32 bit like some older atoms), it should work on bare metal.
On 8/20/2021 at 7:46 AM, Orphée said:I'm using the following VMDK file (the one from Jun's loader) to load synoboot.img :
# Disk DescriptorFile version=1 CID=9fb45bdb parentCID=ffffffff createType="vmfs" # Extent description RW 102400 VMFS "synoboot.img" # The Disk Data Base #DDB ddb.adapterType = "lsilogic" ddb.deletable = "true" ddb.encoding = "UTF-8" ddb.longContentID = "cd061c7d6828764fa3d6bf989fb45bdb" ddb.thinProvisioned = "1" ddb.toolsInstallType = "0" ddb.toolsVersion = "2147483647" ddb.uuid = "60 00 C2 9a ee da ca 33-df 5e 04 3f 80 55 f9 62" ddb.virtualHWVersion = "10"
@scoobdriver was right, I just needed to add following args (extracted from jun's loader grub.cfg file) :
sata_uid=1 sata_pcislot=5 DiskIdxMap=0C SataPortMap=1 SasIdxMap=0
to make SATA1 available in VMWare configuration, it should make LSI passtrough work (just a guess, did not try yet on my production env) @psychoboi32 (try at your own risk)My current VM settings are :
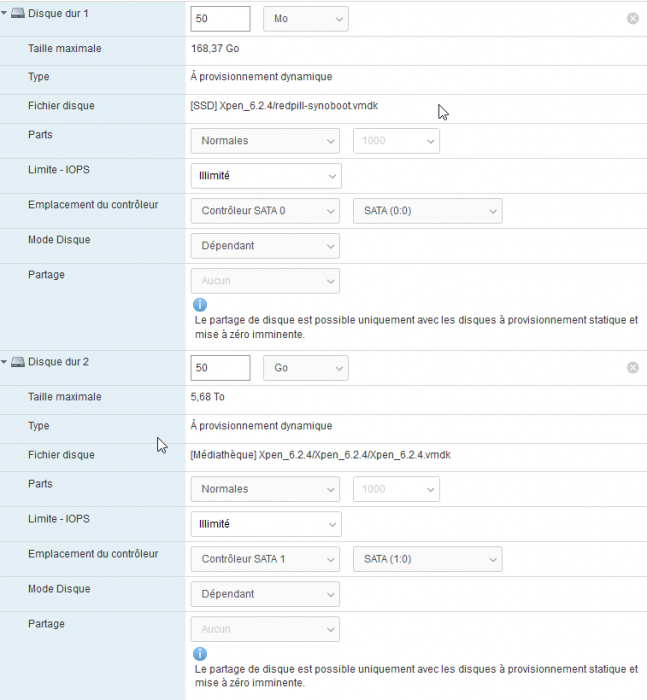
@ThorGroup I'm using same SSD as pool storage for data disk.
I created a 40GB virtual disk exactly the same way as I did for Jun's loader, or that I usually do for other VM likes Ubuntu currently used to build loader with docker.
I build the loader from a Ubuntu's VM running on the same SSD where my Xpenology PROD (jun's) is running.

So I really don't think it can be a failure from SSD pool storage...
I also tried to create a 50GB virtual disk on my real NAS pool storage, same result.
21.log 175.14 kB · 4 downloads 23.log 55.52 kB · 5 downloads
There is something strange about how ESXi emulates HDDs indeed. We have it on our list. As w workaround someone posted a way to manually create disks and put them into a pool (kind of side-stepping the UI) in the GH issue. From what we know it shouldn't be a problem at all if used like this as internally DSM uses just a combo of MDs and LVMs anyway.
On 8/20/2021 at 11:55 AM, psychoboi32 said:I just notice I can only boot redpill if I use legacy bios but for apollolake xpenlogy it was recommended to use UEFI, hmm can we resolve some errors by that idk but we can try.
The UEFI boot actually causes an another set of problems. The DSM is perfectly happy when booted using legacy boot as long as the "withefi" option is enabled. The issue with UEFI is that is not really standarized (or we should say it's very loose). Since EFI can initialize devices and what not on some platforms e.g. serial ports or USB ports aren't working when booted into Linux. This is why we opted to force the loader into legacy/BIOS mode. This isn't a limitation per se - it's just how we configured the GRUB and if needed it can be easily enabled to boot in UEFI mode if desired.
On 8/20/2021 at 2:49 PM, haydibe said:You are right, wasn't that hard after all.
I have noticed the backup, but honestly don't like the idea of restoring someone elses backup.
At the end it was as easy as adding a virtio network card, the usb controller and serial0 port, and manualy edit the vm's conf to add:
args: -device 'qemu-xhci,addr=0x18' -drive 'id=synoboot,file=/var/lib/vz/images/XXX/redpill-DS918+_7.0-41890.img,if=none,format=raw' -device 'usb-storage,id=synoboot,drive=synoboot,bootindex=5'at the top of the vm config file: /etc/pve/nodes/zzz/qemu-server/xxx.conf
Then used this user_config.json:
{ "extra_cmdline": { "pid": "0x0001", "vid": "0x46f4", "sn": "xxxxxxxx", "mac1": "xxxxxxxxxxx" }, "synoinfo": {}, "ramdisk_copy": {} } }Of course with a generated sn and mac1.
What should I say: Successfully migrated one of my old XPE vm's from ESXi to Proxmox.
I do favor the usb bootdrive approach over the sata_dom boot approach. For me that's the way to go, unless ThorGroup argues in one of their fabulous explainations why it's better to use sata_dom instead
The SATA DOM may be A TAD BIT more stable (i.e. more consistant to boot), just MAYBE a tiny bit, but if it boots it doesn't matter. The USB boot relies on precise timing while SATA shim has an exclusive control over the driver - that's why, in short, the SATA DOM may be a tiny bit better. However, where it makes an actual difference is when your boot drive is not emulated.
SATA DOMs are meant to run 24x7, they're meant to sit in a hot case for years, they're meant to be overwritten many times. USB sticks... not so much. SATA DOMs are often times slower and more expensive. So in essence if you can replace the physical USB flash drive when it fails and doesn't boot after a reboot go with USB as it's easier to grab and update/edit. If you want something rock solid and/or you cannot easily replace it if it fails go with the SATA DOM
On 8/20/2021 at 3:37 PM, Orphée said:Inside the user_config.json
{ "extra_cmdline": { "vid": "0x058f", "pid": "0x6387", "sn": "1XXXXXXXXX9", "mac1": "001132XXXXXX", "sata_uid": "1", "sata_pcislot": "5", "DiskIdxMap": "0C", "SataPortMap": "1", "SasIdxMap": "0" }, "synoinfo": {}, "ramdisk_copy": {} }The sata_uid and sata_pcislot doesn't have any effect. In fact you should NOT include them as they're not masked from the cmdline presented to the OS. As far as we can see they never did have any effect even in Jun's loader.
On 8/20/2021 at 4:10 PM, T-REX-XP said:@ThorGroup,From the device perspective it look like this: MMC/SD card mmcblk0 device. Thanks in advance.
That is most likely not gonna work as syno kernel only supports boot drives originating from the SCSI driver (and its derivatives like USB). SD/MMC cards are handled by a different driver. Since we cannot modify the kernel itself it may be hard to pull off. While we may simulate its presence as /dev/synoboot other things will start falling apart as everything in DSM expects /dev/synoboot to be an SCSI-complaint device, have an SCSI type etc
On 8/20/2021 at 5:52 PM, Orphée said:OK !
Working on ESXi !!
I found the issue !
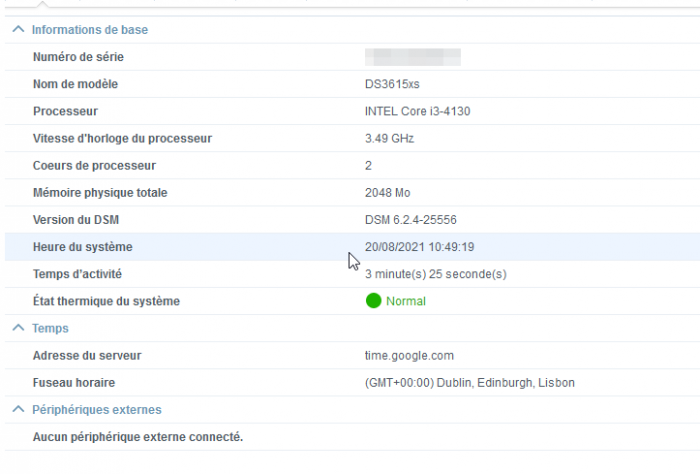
I was using Jun's loader vmdk to mount redpill-synoboot.img
actually I was wrong...
I took Starwind V2V converter to convert redpill IMG to VMDK and it created the vmdk file and the associated flat.vmdk disk :
# Disk DescriptorFile version=1 encoding="windows-1252" CID=fbd25003 parentCID=ffffffff isNativeSnapshot="no" createType="vmfs" # Extent description RW 262144 VMFS "synoboot-flat.vmdk" 0 # The Disk Data Base #DDB ddb.adapterType = "ide" ddb.geometry.cylinders = "260" ddb.geometry.heads = "16" ddb.geometry.sectors = "63" ddb.longContentID = "b54753230135a2f2b9fa336bfbd25003" ddb.thinProvisioned = "1" ddb.uuid = "60 00 C2 98 2d f4 38 d4-22 d2 67 98 f0 73 54 b3" ddb.virtualHWVersion = "4"I was able to initiate disk, all seems OK :
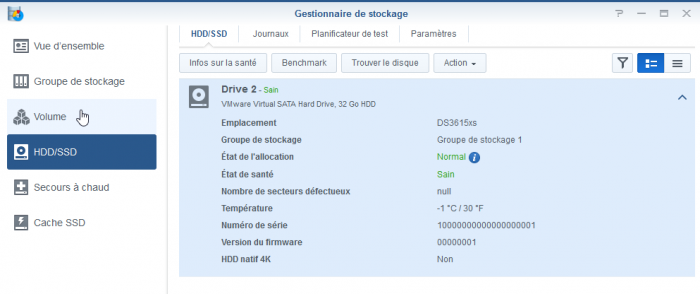
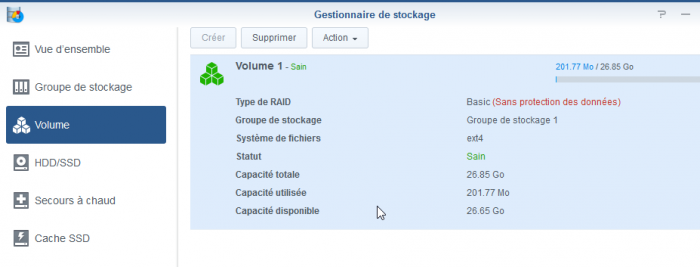
Thanks @ThorGroup
Hm, so what's actually different here from the "normal" way ESXi creates disks? We don't use ESXi very often - you seem to have more experience with it
Your boot disk may be too big if DSM tries to format it.
On 8/20/2021 at 6:39 PM, sebg35 said:From my side i was not able to install DSM 7, using Esxi 7.0 and DSM7 for 918+ (2* 100GB DATA disks are defined under sata1:0 and sata1:1) :
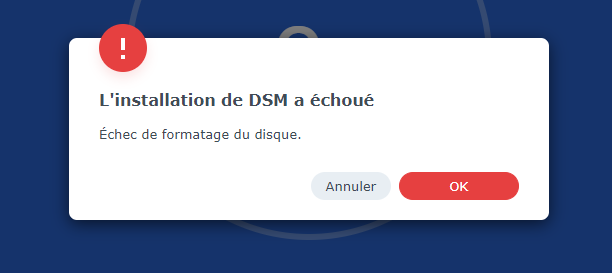
It sounds like it can't find both data disks, and installer is trying to format synoboot (After a reboot -> Grub rescue)
[...]
Your disks moved beyond the sdz limit. DSM doesn't support sdaa-sdaz enumeration (only single letters). You need to play with the SATA mapping. See this post: https://xpenology.com/forum/topic/44285-proxmox-hba-passthrough-second-virtual-controller-not-detected/?do=findComment&comment=204352
On 8/20/2021 at 7:11 PM, haydibe said:If layers end up in the buildcache, you can clean it with: docker builder purge -a
If images stack up in the local image cache, you can clean them with: docker image purge (warning: this will remove all "dangling" images, where the image:tag got assigned to a new image). Though, I typical remove the images by hand with `docker image rm imageid1 imageid2 image3` (you can delete one or more images at a time)
Huge thanks for helping everybody with the docker - it's amazing. We just saw your PM... yes, that one from like 3 weeks ago (sorry!!! we must've clicked the notification and dismiss it). We couldn't give enough likes!
On 8/20/2021 at 7:12 PM, Orphée said:@ThorGroup I tried the exact same steps with bromolow-7.0-41222
But it fails
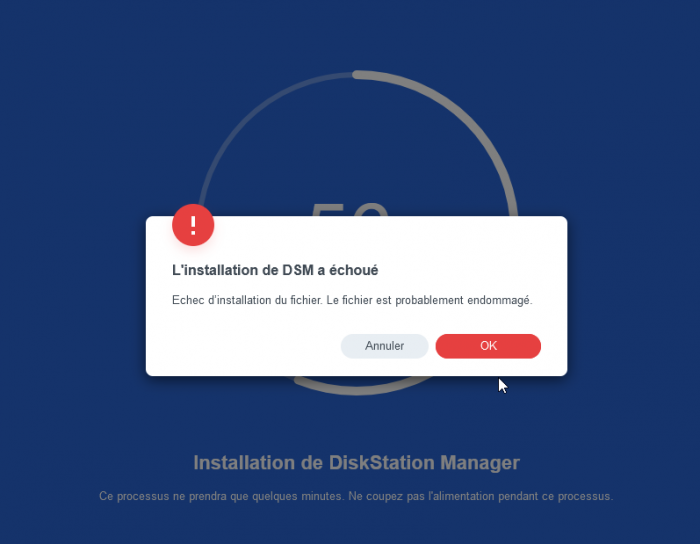
FYI I also tried to update 6.2.4 to "update 2" but it fails and loop in restore mode.
messages.txt 265.25 kB · 1 download tee_telnet_7.0_21.log 589.98 kB · 0 downloads dmesg.txt 191.25 kB · 0 downloads
Correct us if we are wrong but the log says you only have a single ~34GB SATA drive and you're booting with SATA DOM support. For it to work you need the loader image to be mounted as SATA and it has to be <=1GiB.
On 8/20/2021 at 7:16 PM, Orphée said:Not with passthrough yet. it is a created 32GB drive on SATA 1:0 (added new SATA controller)
I won't risk my "prod" disks until it is considered as stable.But I'm not able to install DSM 7.0 with DS3615xs on ESXi yet... Only 6.2.4 is working currently.
Edit :
as a reminder, my user_config.json :
{ "extra_cmdline": { "vid": "0x058f", "pid": "0x6387", "sn": "1330LXXXXXX", "mac1": "001132XXXXXX", "sata_uid": "1", "sata_pcislot": "5", "DiskIdxMap": "0C", "SataPortMap": "1", "SasIdxMap": "0" }, "synoinfo": {}, "ramdisk_copy": {} }Do not use sata_uid and sata_pcislot - this will not cause problems in the current versions but it can in the future.
On 8/20/2021 at 8:05 PM, Orphée said:Ok so I replaced SataPortMap and DiskIdxMap values
I took yours instead of Jun's loader
with jun's loader values :
DiskIdxMap=0C
SataPortMap=1
it fails
with :
DiskIdxMap=1000
SataPortMap=4
it works
Then I'm able to boot/install DSM 7.0
But same as you, I can't initialise volume, disk does not meet requirements.
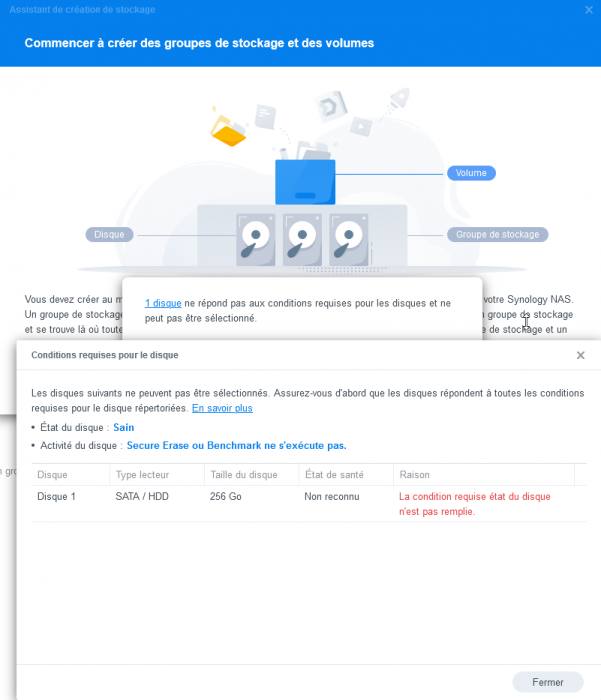
And Info Center is empty, whereas on 6.2.4 it is filled with SN and stuffs...
7.0_21.log_OK_boot_disk_KO_2.txt 390.57 kB · 0 downloads
dmesg.txt 199.83 kB · 1 download messages.txt 242.48 kB · 0 downloads
This is an issue tracked on GH: https://github.com/RedPill-TTG/redpill-lkm/issues/14
There's a workaround but not a proper solution yet. As for the info center it's a JS bug in the DSM itself.On 8/20/2021 at 8:32 PM, scoobdriver said:Ok where at the same point then
the bonus with those values are the data disk shows as disk 1 not 2
edit ; I think juns loader for esxi also uses
DiskIdxMap=1000
SataPortMap=4
Be careful with blindly copying SATA maps from Jun's loader. We're emulating SATA DOM differently and thus you will lose one drive if you just copy it. Look at
On 8/20/2021 at 9:32 PM, dreamtek said:The current version cant support ovmf(uefi) in pve?Once i choose Q35+OVMF,it stuck at efi shell during booting
We deliberately disabled UEFI boot (see above for more reasoning). You can use SeaBIOS with Q35 (or others). To our knowledge there's no disadvantage of using BIOS mode.
On 8/20/2021 at 11:35 PM, Orphée said:I'm trying to update DSM 6.2.4 to DSM 6.2.4 update 2
I see this in logs :
[ 995.929991] <redpill/intercept_execve.c:92> Blocked ./H2OFFT-Lx64 from running
And the update fails and DSM switch to recover (not recoverable actually)
Is it something expected @ThorGroup ?
Thanks
Yes, this is specifically made to disable BIOS update which normally is done on syno hws. If ran on any other hardware it will either crash the CPU (the VM or physical box will act like the reset button was pressed), or it will damage the BIOS (if running on a real hw and the motherboard happens to use the same Insyde BIOS).
See more on that here: https://github.com/RedPill-TTG/dsm-research/blob/master/quirks/hw-firmware-update.md
On 8/20/2021 at 11:59 PM, psychoboi32 said:you are right so what should I do means I have coffeelake machine, and choosing bromollow give it kernel panic and it reboot (I don't know correct word) (C-C-C-C-R). I have last option which is passthough all my hdd and mask its drive controller (everything physical hdd to virtual) (no temp. nothing it will just work for sake of POC (prof of concept)).
We will have a way to load drivers in the stable release
On 8/21/2021 at 12:53 AM, Orphée said:Really?! It will be a dealbreaker for me!
Edit : this ? : https://mariushosting.com/synology-how-to-use-reverse-proxy-on-dsm-7/
In general, you shouldn't have the DSM panel open to the public internet (with reverse proxy or not ;)).
On 8/21/2021 at 1:00 AM, haydibe said:The RP would've been the dealbreaker. I couldn't find it. Thanks to Orphée, we know it exists, but it placed in the "advanced" tab of the "Login Portal" navigation item.
Docker works fine. Just tested a compose deployment -> works like a charm. Tested a swarm stack deployment -> still broken (been broken since 17.05 supports the swarm mode) on Synology's Docker distribution.
Syno's docker is ancient and modified. (at least on v6). It's good for simple things but anything more advanced... oh boy, we've tried and it's painful
On 8/21/2021 at 1:33 AM, Balrog said:Ahhh, v0.5.4 did the trick! Thank you very much for the hint! Now the loader will compile.
I only get some warnings:
... include/linux/kfifo.h:390:37: warning: initialization of 'unsigned char' from 'int *' makes integer from pointer without a cast [-Wint-conversion] ... /opt/redpill-lkm/config/cmdline_delegate.c:405:74: warning: value computed is not used [-Wunused-value] ... /opt/redpill-lkm/config/runtime_config.c:168:53: warning: passing argument 2 of 'validate_nets' discards 'const' qualifier from pointer target type [-Wdiscarded-qualifiers]I will be able to test the image hopefully tomorrow.
We've fixed the kfifo stuff (see update notes at the beginning of this post). Other ones are harmless. We're planning to fix them as they shouldn't be there if we care about the code quality (and we do!).
On 8/21/2021 at 2:41 AM, jumkey said:Use Github Action automatically compile kernel modules
download https://github.com/jumkey/redpill-lkm/actions/runs/1151689502
now we can go making windows version rp-load with something like @@@GITGITHUB_LKM@@@/rp.ko
That's an amazing idea! We shouldn't run out of "free minutes" as the LKM compilation doesn't use a lot of resources. Can you create an issue in the loader repo, so we don't lose it in the sea of posts?
The only thing which we cannot build on GH are full loader images as they contain syno propraitary binaries from PATs.
On 8/21/2021 at 2:53 AM, psychoboi32 said:I am missing something, can somebody help my virtio driver not working i follow what I understood and put mpt3sas.ko like virtio did but none of them loading
poor me
hope anyone help
Edit 1:-
@haydibe R u able to get lsi-sas-2008 card & virtio on ds3615xs built. means i tried but failed hope you guide me here.
proxmox config
args: -device 'qemu-xhci,addr=0x18' -drive 'id=synoboot,file=/var/lib/vz/template/iso/DS3615xs7.img,if=none,format=raw' -device 'usb-storage,id=synoboot,drive=synoboot,bootindex=5' boot: order=scsi0;ide2 cores: 4 hostpci0: 0000:01:00 hostpci1: 0000:08:00 memory: 8192 name: xpen numa: 0 ostype: l26 scsihw: virtio-scsi-pci serial0: socket smbios1: uuid=CBA73ABA-6D53-44E8-BFB1-7A32B71F794E sockets: 1 vga: serial0 virtio1: local-lvm:vm-500-disk-0,cache=unsafe,size=32G ~
Edit 2:-
Is anyone know how to get logs dmesg and all on proxmox, i only use proxmox as production server never debug it. thanksWhen using virtio CONTROLLER your disk should be set to SATA and not to virtio PORT. The disk must present itself as SCSI-complaint to the Linux kernel so that syno patches pick it up properly.
To get the logs you need to add a serial port (Even better if you can add 2). Then you can access them by typing "qm terminal 101 -serial0" where 101 is the id of your VM and the "serial0" is the number of your serial port on the VM counting from 0 up to 3.
On 8/21/2021 at 3:50 AM, psychoboi32 said:edit 1.1:- wow sata failed and scsi both shows me this

failed due to file corrupt
Sent from my iPhone using TapatalkThat is often caused by a weird issue in QEMU where if you reset the machine too quickly it will not respond to some SCSI commands. If it happens all the time try stoppping the VM, placing the file again, wait ~10s, and start the VM again.
On 8/21/2021 at 4:48 AM, haydibe said:Should we worry about this output in /var/log/messages?
2021-08-20T22:30:28+02:00 dsm synocloudserviceauth[27855]: cloudservice_get_api_key.cpp:21 Cannot get key 2021-08-20T22:30:28+02:00 dsm synocloudserviceauth[27855]: cloudservice_register_api_key.cpp:293 Register api key failed: Auth Fail 2021-08-20T22:30:28+02:00 dsm notify[27851]: pushservice_update_ds_token.c:52 fgets failed 2021-08-20T22:30:28+02:00 dsm notify[27851]: pushservice_update_ds_token.c:147 Can't set api key 2021-08-20T22:30:28+02:00 dsm notify[27851]: pushservice_utils.c:325 SYNOPushserviceUpdateDsToken failed. 2021-08-20T22:30:28+02:00 dsm notify[27851]: pushservice_utils.c:387 GenerateDsToken Failed 2021-08-20T22:30:28+02:00 dsm notify[27851]: Failed to get ds token.Since 18:30 this block repeats roughly 50 times in the logs. Seems there is the need to supress one more url.
Huh.... it's spamming these hardcore. They probably didn't predict that they cannot access the API.
On 8/21/2021 at 4:50 PM, joad said:Hi, I am currently testing 7.0-41222 DS3615xs on a barebone Xeon E3-1245. Everything works fine except info center and the general tab, it is completely empty.
Does anyone have ideas on how to start troubleshooting?
That's actually a DSM bug - if you look into Chrome dev console you will see that the UI gets the data from the backend but the JS fails to display the tab. It can be safely ignored - they will probably fix it as this is still a beta on 3615. If not there's really nothing you're losing here
On 8/22/2021 at 2:01 PM, gadreel said:2021-08-21T19:20:19+03:00 RedPill synocgid[7672]: noise.cpp:206 Failed [pkey.empty() && !get_device_info_from_store(account, did, pkey, state, rememberme)]
2021-08-22T00:52:58+03:00 RedPill synocgid[7672]: session/timeout.cpp:70 gadreel has session timeout.
2021-08-22T00:52:58+03:00 RedPill synocgid[7672]: noise.cpp:206 Failed [pkey.empty() && !get_device_info_from_store(account, did, pkey, state, rememberme)]
2021-08-22T08:09:53+03:00 RedPill synocgid[7672]: session/timeout.cpp:70 gadreel has session timeout.
2021-08-22T08:09:53+03:00 RedPill synocgid[7672]: AccessTokenWrapper.cpp:103 (AccessTokenWrapper.cpp:103)Failed [!szSid || !szSid[0]]
2021-08-22T08:49:57+03:00 RedPill synocgid[7672]: noise.cpp:206 Failed [pkey.empty() && !get_device_info_from_store(account, did, pkey, state, rememberme)]
I do not know if these failed messages have anything helpful... other than that I have been running Apollolake 7/0 for days without any issues.
There are actually perfectly normal, regardless of the hardware (i.e. they appear on a real hw as well).
On 8/22/2021 at 9:05 PM, Orphée said:I have to re-stop my PROD Jun's Xpenology, stop ESXi, remove my 4 prod disks, place my temp test disk, reboot ESXi, and start 7.0 test VM...
Comparing dmesg from Jun's loader with redpill
I don't see in redpill dmesg any reference to :
mpt2sasFrom my Jun's loader dmesg
[ 1.445556] megasas: 06.506.00.00-rc1 Sat. Feb. 9 17:00:00 PDT 2013 [ 1.449366] mpt2sas version 20.00.00.00 loaded [ 1.449589] scsi31 : Fusion MPT SAS Host [ 1.451133] mpt2sas0: 64 BIT PCI BUS DMA ADDRESSING SUPPORTED, total mem (4055204 kB) [ 1.523249] mpt2sas0: MSI-X vectors supported: 1, no of cores: 2, max_msix_vectors: -1 [ 1.523262] mpt2sas 0000:0b:00.0: irq 77 for MSI/MSI-X [ 1.524207] mpt2sas0-msix0: PCI-MSI-X enabled: IRQ 77 [ 1.524209] mpt2sas0: iomem(0x00000000fd3fc000), mapped(0xffffc90008240000), size(16384) [ 1.524211] mpt2sas0: ioport(0x0000000000005000), size(256) [ 1.560214] tsc: Refined TSC clocksource calibration: 3492.075 MHz [ 1.560217] Switching to clocksource tsc [ 1.638116] mpt2sas0: Allocated physical memory: size(7445 kB) [ 1.638119] mpt2sas0: Current Controller Queue Depth(3305), Max Controller Queue Depth(3432) [ 1.638121] mpt2sas0: Scatter Gather Elements per IO(128) [ 1.696633] mpt2sas0: LSISAS2008: FWVersion(20.00.07.00), ChipRevision(0x03), BiosVersion(07.39.02.00) [ 1.696635] mpt2sas0: Protocol=(Initiator,Target), Capabilities=(TLR,EEDP,Snapshot Buffer,Diag Trace Buffer,Task Set Full,NCQ) [ 1.696766] mpt2sas0: sending port enable !! [ 1.700974] mpt2sas0: host_add: handle(0x0001), sas_addr(0x5003005703dbf193), phys(8) [ 1.707097] mpt2sas0: port enable: SUCCESSDo I miss something about mtp2sas ?
I'm still trying to understand how DiskIdxMap and SataPortMap works... maybe I'm missing something with it...
See the haydibe post as well as this guest post with screenshots:
On 8/22/2021 at 9:16 PM, haydibe said:(...)
Though, I am currious what `sata_uid=1 sata_pcislot=5` actualy means? Does it specify the location of the sata_dom drive?
sata_uid and sata_pcislot are parameters which were read by the Jun's loader but never actually used for anything. We're speculating that he wanted to shim the SCSI driver but decided against (as this is a buuumpy road as we've found). In previous DSM versions a userland hack was useful, now not so much.
While running RP you should NOT add these parameters as they're not removed from cmdline. While this doesn't cause any issues yet it may start in future DSM versions.The comment in the shim - https://github.com/RedPill-TTG/redpill-lkm/blob/master/shim/boot_dev/sata_boot_shim.c - explains in details various methods of searching for the SATA DOM and addresses why relying on the location isn't a good idea
On 8/23/2021 at 2:00 AM, mcdull said:May I know what is the targeted minimum hardware for redpill project?
I am curious if my idle QNAP TS-439 Pro II+ with 32bit atom (cpu:D410) is able to boot 6.2.4.
Thanks.
If this atom supports MOVB you can even run 918+ build. However for this hardware 3615xs build is probably the best. Regardless, that CPU is very slow. It will run... it will.... but the experience will be pretty miserable.
On 8/23/2021 at 12:02 PM, tbc0309 said:The reason for this installation error is that there is an error in executing the external "update" binary file. The specific operation method is: manually modify "scemd" in the "/usr/syno/bin" directory, prohibit him from executing the "update" binary file, and instead point to a script defined by himself to solve the file parsing during installation.

You should NEVER modify scemd as it's protected by a checksum and it will trigger autodestruction with time limit. Normally the RP kernel module blocks all update files. Are you talking about "updater" file? This is the main updater file which does the whole DSM installation.
On 8/24/2021 at 2:16 AM, Dreadnought said:I get the notification that Disk 2 is reidentified every minute. I hope that one day this issue is also beeing fixed.
It will. We didn't get to the ESXi weirdness with drives. It may be the problem with hddmon or SMART. Proxmox/QEMU emulate a partial SMART (fully fake but it's there). This is what may be missing on ESXi.
On 8/25/2021 at 4:05 PM, seanone said:Thank you for your hard work, @ThorGroup @haydibe and others.
Wait for face detection and mpt3sas available.
We believe there should be a separate topic for the face detection problem. It was discussed somewhere on the page 22-24 - we're not sure if anyone created a separate topic (and it's a completely separate from the loader).
On 8/25/2021 at 9:57 PM, Orphée said:Should Proxmox considered as a better alternative than ESXi in the future ? or is it just a matter of debugging time ?
In our experience Proxmox was superior. ESXi is amazing for enterprise when you're running a fully supported hardware. In any other circumstances Proxmox is most likely a better choice. Especially that ESXi free version is more like a trial version of the full thing.
@haydibe hit the nail in the head with explanation.On 8/26/2021 at 2:37 PM, Orphée said:I'll stay on esxi then, unless redpill loader needs proxmox in near future (esxi bugs or anything else)
If you like ESXi definitely stay on it. It will be working on it. The issue with ESXi is that it's mostly concentrated on supporting Windows and its quirks. It's less friendly towards Linux guests and their quirks (e.g. it doesn't emulate SMART from what we see, at least on the free version).
On 8/26/2021 at 7:19 PM, ghtester said:I have succesfully compiled the image using docker, unfortunately the baremetal devices I can use for testing have just Broadcom ethernet adapters. Is there an easy way to modify the script(s) to get compiled & included tg3 module driver please? Where should I start looking?
Currently - no. We will have a sane method of adding drivers in the future.
On 8/26/2021 at 7:22 PM, Davide said:Hello all, i'm following this thread since its appareance
Built redpill.ko on a centos 7 machine with gcc 4.8.5 ... all seems ok
Built image on a centos 8 machine because on the centos 7 machine it fails with
include/patch.sh: line 52: @@@COMMON@@@/ramdisk-001-disable-root-pwd.patch: File o directory non esistente
[!] One of the patches - @@@COMMON@@@/ramdisk-001-disable-root-pwd.patch - failed to applySo far, so good
I'm trying to run the loader on a libvirt vm
It always fails on starting scemd
:: Starting scemd
[ 12.708612] BUG: unable to handle kernel paging request at 0000000000004cf9
[ 12.709011] IP: [<ffffffff8138c567>] syno_mv_9235_disk_led_set+0x27/0xc0
[ 12.709011] PGD 175fbd067 PUD 175fff067 PMD 0
[ 12.709011] Oops: 0000 [#1] SMP
[ 12.709011] Modules linked in: bromolow_synobios(PO) nfsv3 nfs lockd sunrpc i40e(O) ixgbe(O) igb(O) i2c_algo_bit e1000e(O) dca vxlan ip_tunnel vfat fat sg virtio_scsi(OF) virtio_net(OF) virtio_blk(OF) virtio_pci(OF) virtio_ring(OF) virtio(OF) etxhci_hcd usb_storage xhci_hcd uhci_hcd ehci_pci ehci_hcd usbcore usb_common [last unloaded: bromolow_synobios]
[ 12.709011] CPU: 1 PID: 4595 Comm: scemd Tainted: PF O 3.10.108 #41222
[ 12.709011] Hardware name: QEMU Standard PC (Q35 + ICH9, 2009), BIOS rel-1.14.0-0-g155821a-rebuilt.opensuse.org 04/01/2014
Someone could have some ideas?
Many thanks in advance
That seems like a completely borked loader code hmm... the variable is not replaced + it seems like the kernel module didn't load at all. Can you try again with the newest version and if not working post the issue on GH? It's much easier to manage it rather than reply to mixed posts
On 8/27/2021 at 11:32 PM, loomes said:(...)
The smallupdate part. At this point it hangs everytime when i upgraded. After disable this all works fine.
@Orphée THX
We need to investigate that small part further - can you create a GH issue for this in the loader repo?
13 hours ago, yanjun said:Hello, I have a lsi 9207-8i working in IT mode, which means that it is used as an hba card to pass my hard drive to my nas virtual machine. Under jun 6.2.3, my pve virtual machine startup mode is set to UEFI, but currently redpill does not support this option, so when I select the HBA card through LSI 9207-8i and start the virtual machine, the system first loads the LSI ROM and shows that 8 hard disks have been read (in my case) , And then stuck in the following interface: Booting from Hard Disk..., my guess is because the hard disk loaded by the HBA card affects the arrangement of the entire hard disk, resulting in the inability to read the boot information, I don’t know if my guess is Correct, do you have any ideas for solving this problem.
When I cancel the option of rom-bar =1 in the pass-through, boot can start, but I get a lot of error messages, and finally get stuck in the place shown below
[...]
These errors seem to be coming from inside of the Linux-made driver for the HBA card. There may be some problem with IRQs on your platform?
13 hours ago, coint_cho said:I have saw a few options given by the members of this thread such as using VirtIO as my ethernet adapter in vmdx but since my knowledge with VM is scarce.. not really sure how to do that.
You need to make your ethernet as e1000e or virtIO - then it should see it
You should be able to double click the adapter in the VM config and change that.
-
3
-
12
-
3 minutes ago, psychoboi32 said:
it is easy if you need my config i can share with you
boot: order=usb0 cores: 4 cpu: SandyBridge hostpci0: 0000:01:00 hostpci1: 0000:08:00 memory: 8192 name: XPenology-TMP-ds918 net1: e1000=8A:C1:48:E3:A6:4D,bridge=vmbr0 numa: 0 ostype: l26 sata0: local-lvm:vm-102-disk-2,size=32G scsihw: virtio-scsi-pci serial0: socket smbios1: uuid=04F674CF-F8B7-4268-998C-629149B97412 sockets: 1 tablet: 0 usb0: host=090c:1000,usb3=1 vga: serial0
just make vm and put this config change pcie card according that if you need any help how to passthrough i have written guide i can share with you
there was backup of proxmox available on this forum just use that and remove jun loader files and put redpill there as you can see my vm name it is used from that 😛With SATA supported we will say there isn't even a need for any config as the default one works perfectly (just clicking through in the Proxmox UI). As for the one you posted we're curious about two things:
- Why set the cpu to SandyBridge manually?
- Why e1000 instead of VirtIO? (virtio will be more performant as it doesn't do a full emulation)
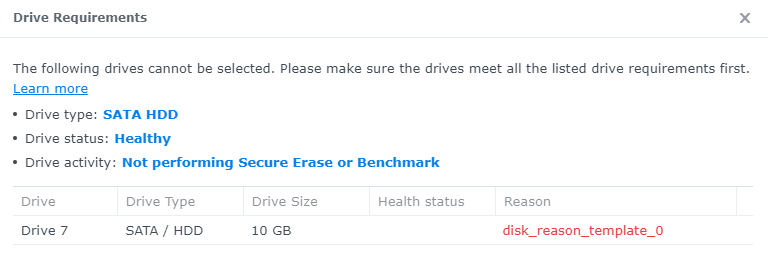

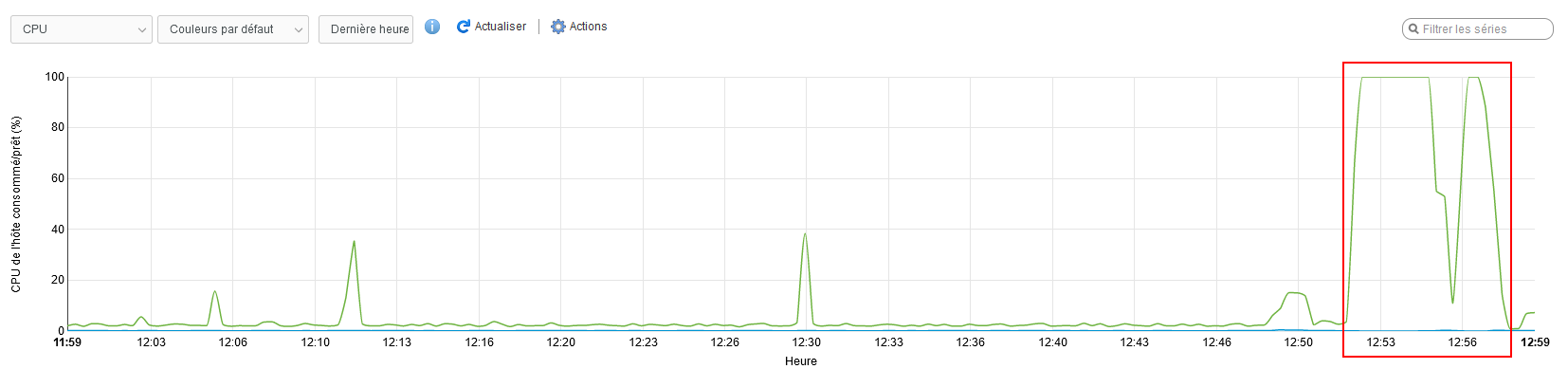







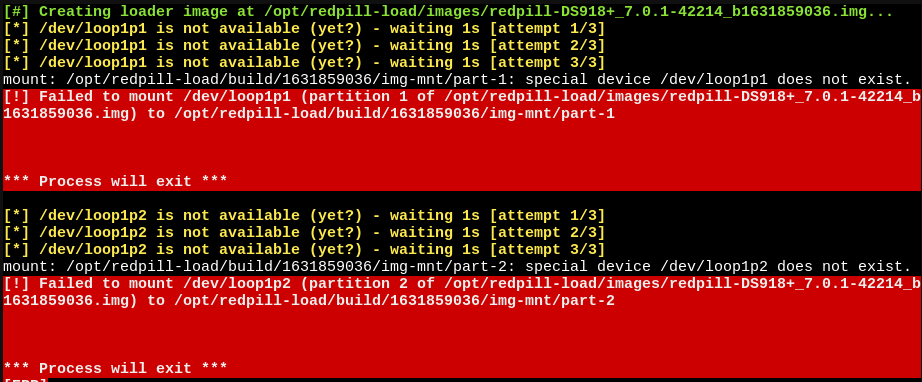
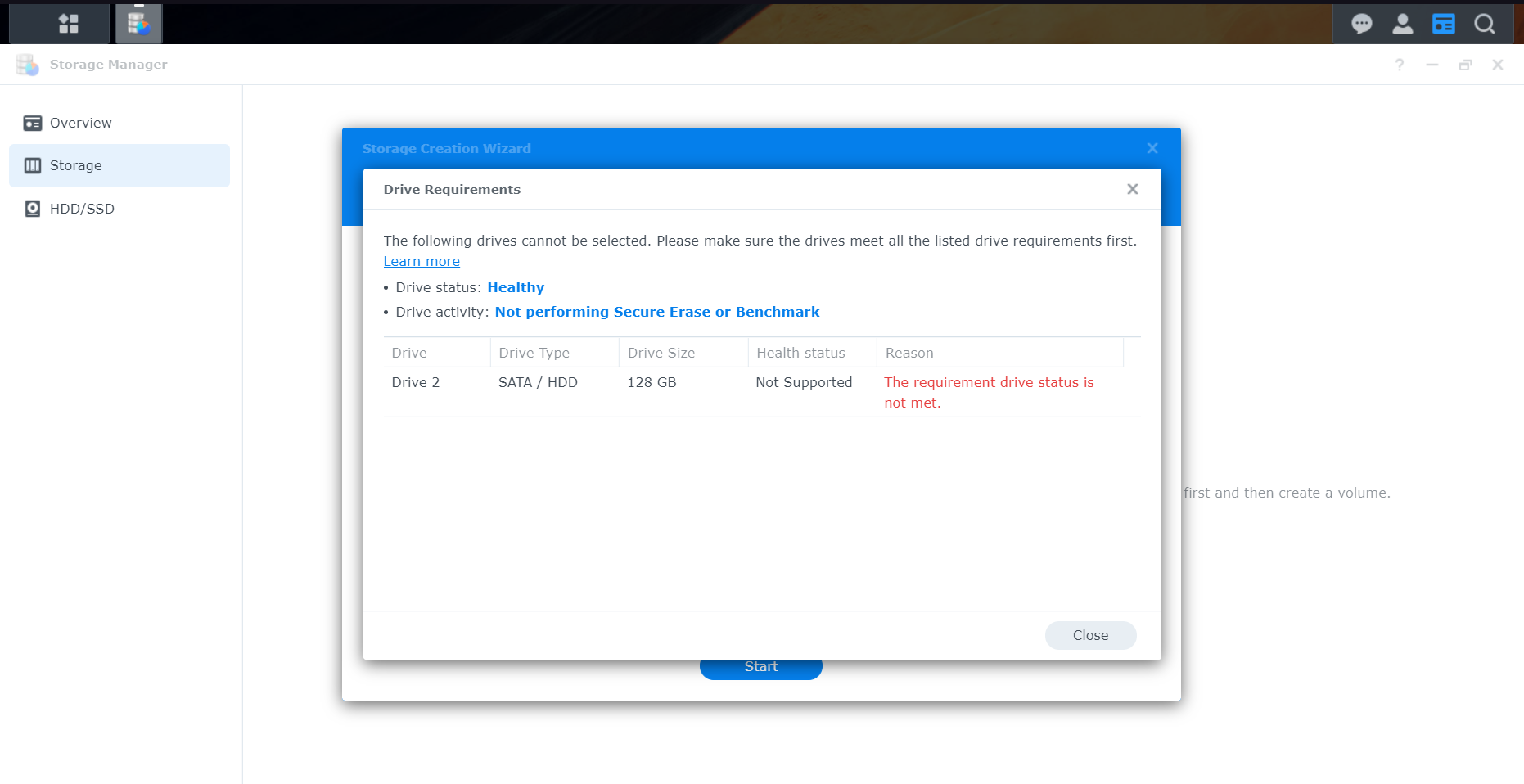


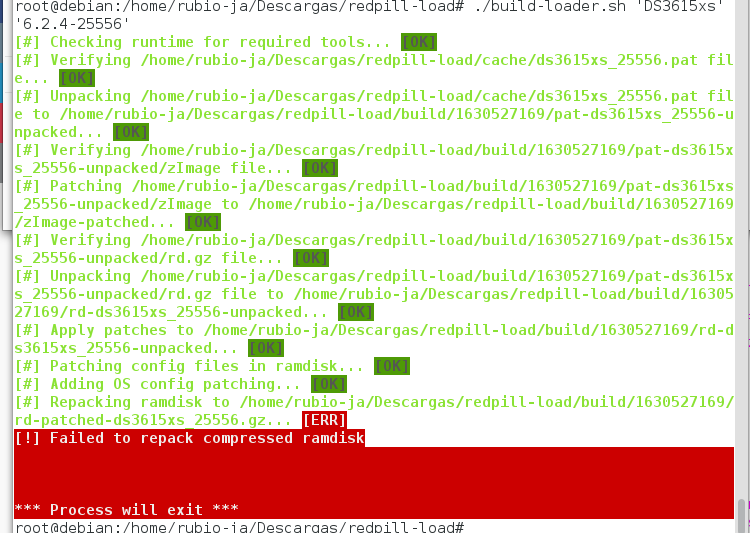

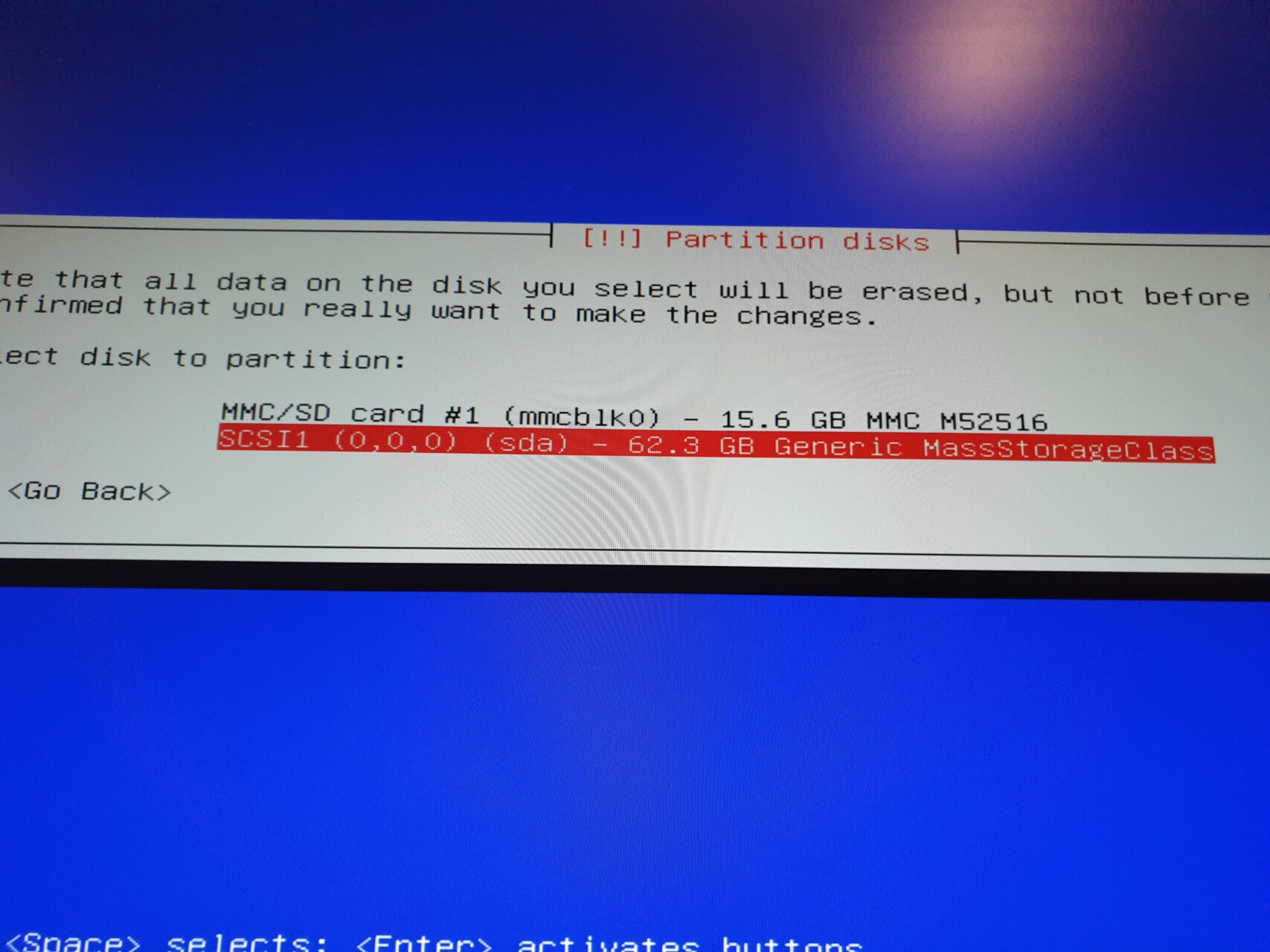

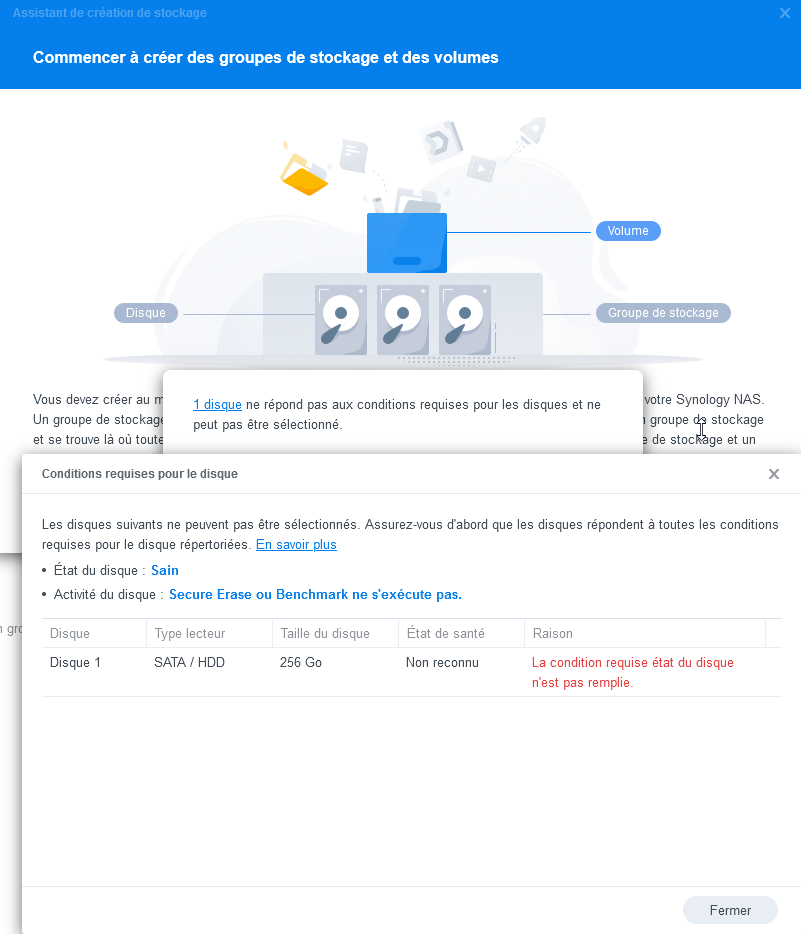
DSM 7.0.1 now supports btrfs data deduplication
in Readers News & Rumours
Posted
Sadly this "requires at least one btrfs volume that only consists of synology SSDs" - there's probably a reason for that.