flyride
-
Posts
2,438 -
Joined
-
Last visited
-
Days Won
127
Everything posted by flyride
-
Not sure how SAS works out exactly but non-Synology branded hardware SATA port multipliers are not supported. Looking at the card and specification, there is some sort of SAS multiplexing going on, so it may not work for this application.
-
The strange part of this question is that you edited grub.cfg when you built your system. So here is the FAQ entry that covers this: https://xpenology.com/forum/topic/13061-tutorial-install-dsm-62-on-esxi-67/ And just for good measure, here is a thread that asks and answers the exact same question, and describes a different access method: https://xpenology.com/forum/topic/30105-trying-to-edit-grubcnf-on-installed-system-ds918-623-25426 Search is quite powerful on this forum.
-
Why not post an fdisk dump along with the rest of it? Seems like it would be necessary information. Anyway, I suspect you have an MBR partition table, needs to be converted to GPT to support >2TB. You will also need this as there is much more work ahead of you once you get that done: https://xpenology.com/forum/topic/14091-esxi-unable-to-expand-syno-volume-even-after-disk-space-increased/ It may be easier to just build a new vdisk and copy/mirror your stuff over to it.
-
Excellent, very glad it seems to be working out given the circumstances. My advice after a corruption and recovery event like this is always to offload all the data, delete everything (volume, storage pool, shr, etc) and then rebuild it from scratch. Otherwise something we did not find may bite you in the future. You may want to do this anyway in order to get more space as detailed prior.
-
Try and reboot and see if your volume mounts.
-
This thread (starting with the linked post) details a specific recovery using lvm's backup. However, your underlying problem (which is not really known) is different than the the thread original poster. https://xpenology.com/forum/topic/41307-storage-pool-crashed/?do=findComment&comment=195342 The folder with the backup data is /etc/lvm/backup The restore command involved is vgcfgrestore (or in your case lvm vgcfgrestore) You are running older lvm (because of DSM 5.2) than this example so there might be other differences.
-
So if you review the response about trying to expand your physical volume on the other thread, you can see the broken logic. DSM didn't automatically expand your SHR because it isn't possible with the SHR structure and rules. Now understand that to the filesystem (ext4), this is all done under the covers: /dev/md2 + /dev/md3 + /dev/md4 = continuous storage (vg1000) which ext4 then writes a filesystem upon. The storage expansion procedure that you apparently were following is a special use case (which was stated in the thread header, along with admonishment for backup). A virtual disk can be grown in ESXi, but it does not get registered as a disk change event with DSM, so its automatic expansion doesn't occur. So my procedure adds storage to the end of an existing partition, which is relatively simple to inform lvm and DSM, and doesn't disturb any existing data. I think essentially what you have attempted is to add storage in the middle of the lvm. DSM does this as part of its expansion logic, but I don't know exactly how it is accomplished. If done indiscriminately, this corrupts ext4 as parts of the filesystem with data changed LBA's. But we cannot even see your lv's so something else seems to have happened that seems more catastrophic. Given that you want more space - if you delete and remake the SHR, you will get 32TB. If you have a backup of your data, that may be preferable. If you don't have a backup, you might try and restore the lvm from its automatic backup. I still don't know what exactly has been done that was destructive, and would hope to identify the action that caused the corruption before attempting any irreversible action for recovery.
-
cannot expand volume on Xpeneology DSM 5.2-5967
flyride replied to gizmomelb's question in General Questions
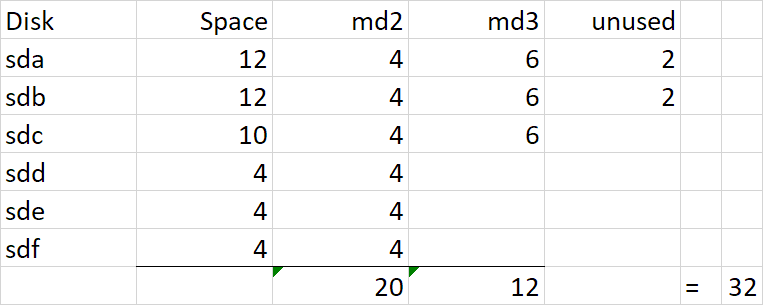
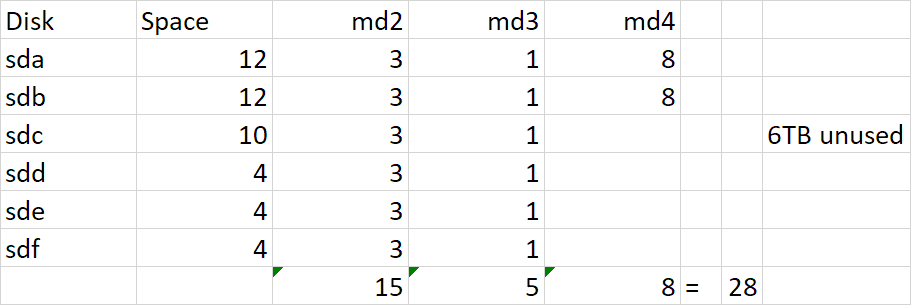
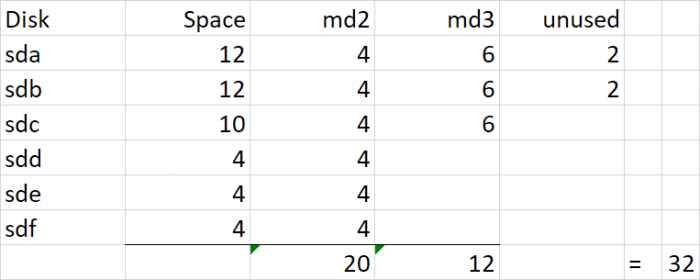
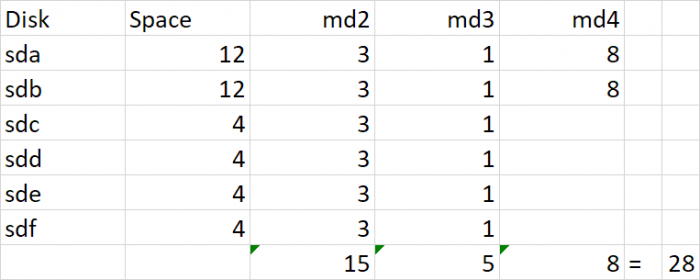
I realize you are posting in the other thread to try and recover your data. I'm posting on this one to help with some forensic reconstruction and to potentially explain why you cannot get more storage from your SHR based on replacing the 4TB with a 10TB drive. To recap, at some point in your history, you had 4TB and 1TB drives that comprised your SHR. It would appear that you replaced all your 1TB drives with 4TB and that left you the following SHR makeup: Because you had 1TB drives, the 4TB drives were split into two pieces, a 3TB RAID5 and a 1TB RAID5, which are joined together via lvm and then presented as a unified storage (vg1000) to DSM for your filesystem. The 1TB md3 RAID was required in order to provide redundancy for the 1TB drives, but when they were removed, DSM cannot collapse them and maintains the 1TB RAID indefinitely (or at least until you delete and remake the SHR). Then, you added in 2x 12TB drives. These drives mostly became their own RAID1 (since they are the only drives large enough to back up themselves), but SHR does something stupid and adds them to existing RAID5 arrays (4TB and 1TB) in hopes that it will make more storage available. Unfortunately it results in the same space available if they were totally reserved for RAID1, but it does work with some combinations of drive sizes. However, this is what I dislike about SHR, things get very complicated. Now you replaced sdc with a 10TB drive. Notice that there is no more space available and 6TB is unused. The reason for this is that the existing arrays need redundancy restored, and when that is complete there is no space to achieve redundancy with the remaining space on sdc. In other words, the drive gets configured with partitions to support /dev/md2 and /dev/md3 but it isn't big enough to also be added to /dev/md4. Had you added a 12TB drive, /dev/md4 would have transformed into a RAID5 and added 8TB additional space. But as it is, SHR has nowhere to grow.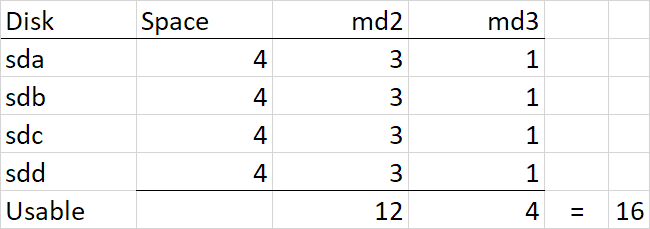

-
Ok, but we did a vgchange -ay some time ago. Try a lvm vgscan and lvm lvscan to see what is there first.
-
Generally DSM automatically expands when physical drives are added. The link you posted is a quite different use case using virtual drives on ESXi, where the space gets expanded by modifying the VM underlying storage, without adding drives. So, do you know what was executing when it crashed? Also, any luck investigating the physical members of the lv - i.e. lvm pvscan
-
Docker only can use devices that are already in existence in Linux. Docker apps are really just a chroot of the host Linux environment. This is the real reason for this. It's hard for Synology to make newer drivers work with old kernels, just like it is for @IG-88 extra.lzma All is not lost if you have the time and inclination. Even DSM on real Synology can compile loadable drivers that can be added via modprobe.
-
Is this the same system? Did you do something to try and expand with your 10GB disk and toast your volume? If so, you should explain exactly what was attempted and what happened. Also it would have been helpful if you had mentioned the system was a 5.2 build.
-
I understand. You really need to become a student of mdadm, lvm and ext4 in order for this to go well. I urge you to take the time and understand the commands you are typing in and not just blindly follow someone else's (potentially misinformed) process. There many permutations of lvm commands, just do some googling. pvscan alias for "lvm pvscan" for example. FWIW, vgchange -ay is the command that starts the logical volume if all its physical members are working. It would make your /dev/lv1000 device start working if the members were intact and functioning. Yes, your array appears fine (per your original post) so don't mess with that. The array is your Disk Group. That is the same size it always was. The DSM volume (filesystem) within it has a size of 0 because DSM cannot recognize a filesystem at the moment. There is a lot of stuff in that thread that has to do with the array, does not apply to you and would be quite dangerous if you followed it. Again, right now you need to figure out what is going on with the "physical" storage devices (/dev/md2, /dev/md3, /dev/md4) that are part of the lv. To be clear lv = logical volume. This is storage and not the DSM volume that lives within it and is called a "volume" within the UI. The entire LVM metadata configuration can be recreated from an automatic backup that is saved within your /etc structure. But you have to figure out what is happening with the devices first.
-
You kind of skipped the first step. Figure out what's wrong here, otherwise you are just blindly following random tasks and pushing buttons.
-
Well generally, you need to validate the members of your volume group and start it - i.e. sudo vgchange -ay When you do get it to start, then try to mount the volume per the fstab. If it won't mount, then fsck is the tool that is needed to attempt to fix your volume. Any post that references btrfs does not apply to you. Investigate your pv/lv starting with this post, and really any linux lvm data recovery thread. https://xpenology.com/forum/topic/14337-volume-crash-after-4-months-of-stability/?do=findComment&comment=107971
-
If your array is healthy, then you have a vg or filesystem issue. Make sure you know which filesystem type the volume was (btrfs or ext4). Dumping /etc/fstab will tell you. This thread may help serve as a template for data recovery: https://xpenology.com/forum/topic/14337-volume-crash-after-4-months-of-stability
-
Tutorial: Install DSM 6.2 on HP Mediasmart EX485 or EX490
flyride replied to jadehawk's topic in Tutorials and Guides
The largest drives on the market at the moment are 16TB, and there is no issue with using them with any of the supported XPe platforms. -
1.04b loader is UEFI bootable. The only loader that does not support UEFI is 1.03b (BIOS or CSM required).
-
I think this is positive confirmation that FMA3 is indeed required (prior statement by inference and deduction only). Turns out virtually all Pentiums don't have it, and no Celerons do. https://en.wikipedia.org/wiki/FMA_instruction_set Sorry it won't work, but your processor upgrade is simple to a supported Haswell CPU.
-
That's the right one. May as well install update 3 (not 6.2.4!) and see if it overwrites whatever is going wrong. https://global.download.synology.com/download/DSM/criticalupdate/update_pack/25426-3/synology_apollolake_918%2B.pat Barring that I would just run a migration install of 6.2.3 from DS Assistant and see if that fixes things. https://global.download.synology.com/download/DSM/release/6.2.3/25426/DSM_DS918%2B_25426.pat
-
Did you install using DDSM PAT file or with the proper DS918+ PAT file? If DDSM, its validation check is failing and it is behaving as expected (shutting down to deny you services). DDSM is only for Synology VMM.
-
Tutorial: Install DSM 6.2.x on ESXi 6.7/7.0 as BAREMETAL
flyride replied to snailium's topic in Tutorials and Guides
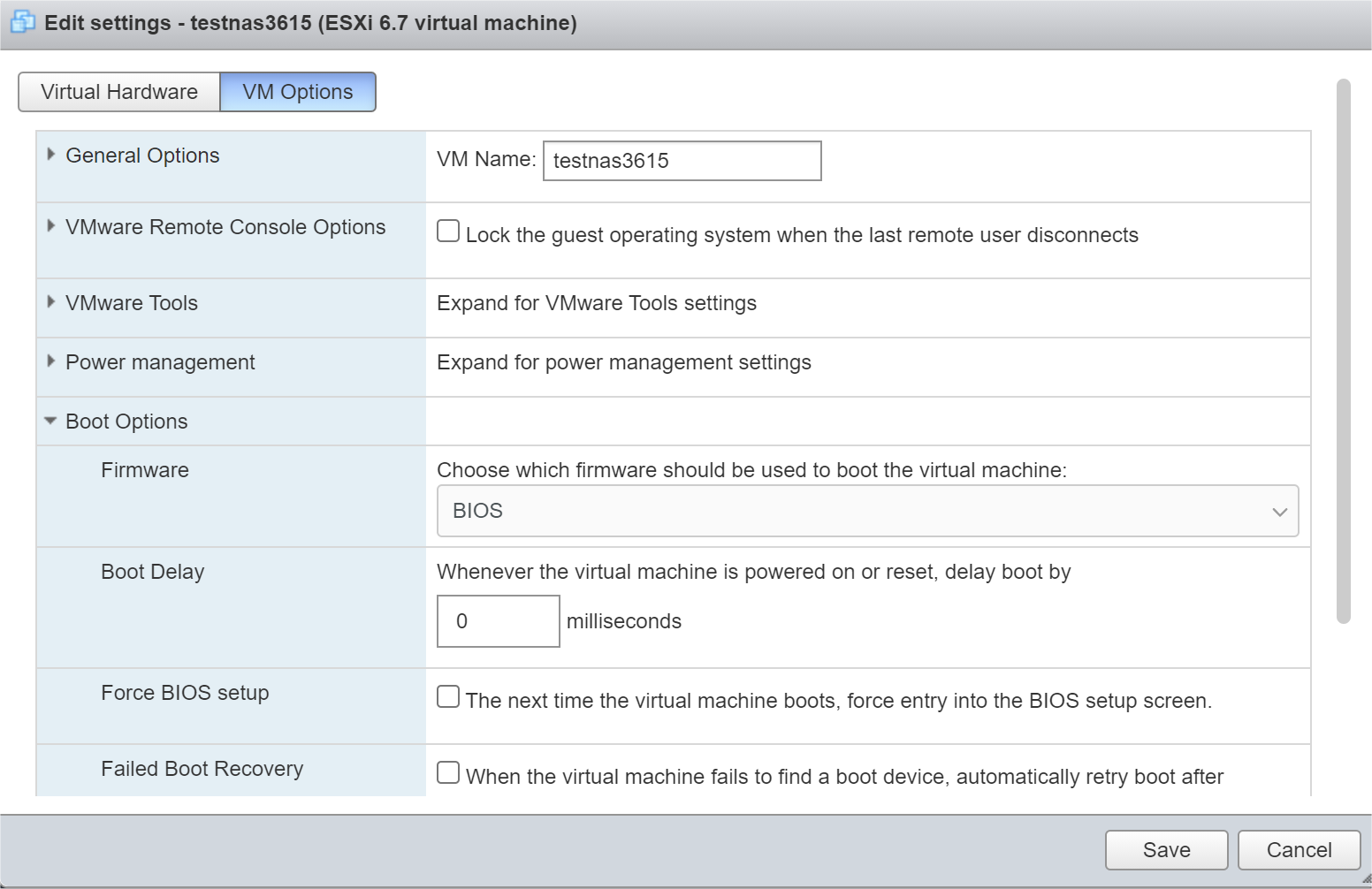
Not true (at least with VM built in 6.7), set BIOS mode here: This particular VM is running 1.03b happily with ESXi 7. I would be very surprised if ESXi 7 VM's did not have BIOS option, but if that happens, create the VM with an earlier ESXi version.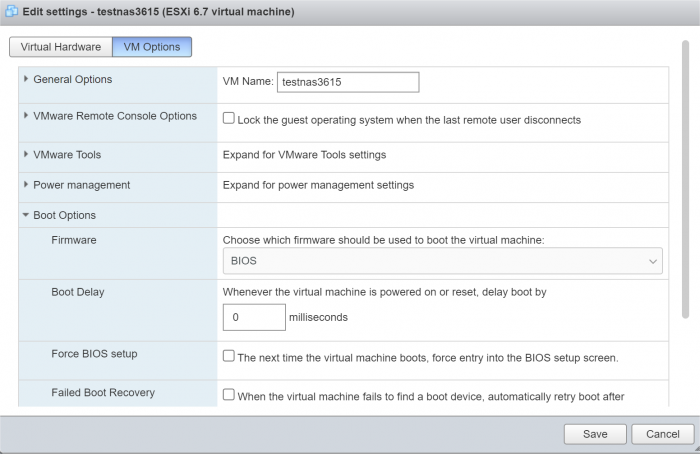
-
Looks good from here. DSM retried an error and there was no loss of data integrity. I'd keep using it if it were me.
-
Should be fine, but you may need extra.lzma to support the embedded network card. Take a careful analysis at RAID10 risks before using it. It's not a whole lot better than RAID5 and uses a lot of storage for little value.
-
DSM detected a read error. It retried and was able to read the data. The sector may be flagged for replacement if the drive decided that it was bad a.k.a. "Uncorrected Pending" But it cannot actually replace the sector until a write operation happens to the drive. Only then it will say it is a bad sector. However, if it writes it, and then reads it and it is okay, it may decide it's not worth flagging it as a bad sector (Uncorrected Pending then disappears). This is not uncommon. If the drive were under warranty you might be able to press WD to replace it. But out of warranty, it's just your comfort level. If you want more advice post the entire SMART screenshot for that drive.