Search the Community
Showing results for tags 'shr'.
Found 14 results
-

SHR-1 and SSD cache with no data protection - how reliable?
SergeS posted a question in General Questions
I have four drives shr-1 volume (of course, with data protection) and one drive SSD cache (of course, with NO data protection, read-only). I know, in case of any single drive of shr-1 volume will crash I will not lose any data, that is what data protection is. But what gonna happen if my SSD read-only cache drive crashed? Will I loose data on the volume? I believe not, but I would like to get some confirmation :-). -
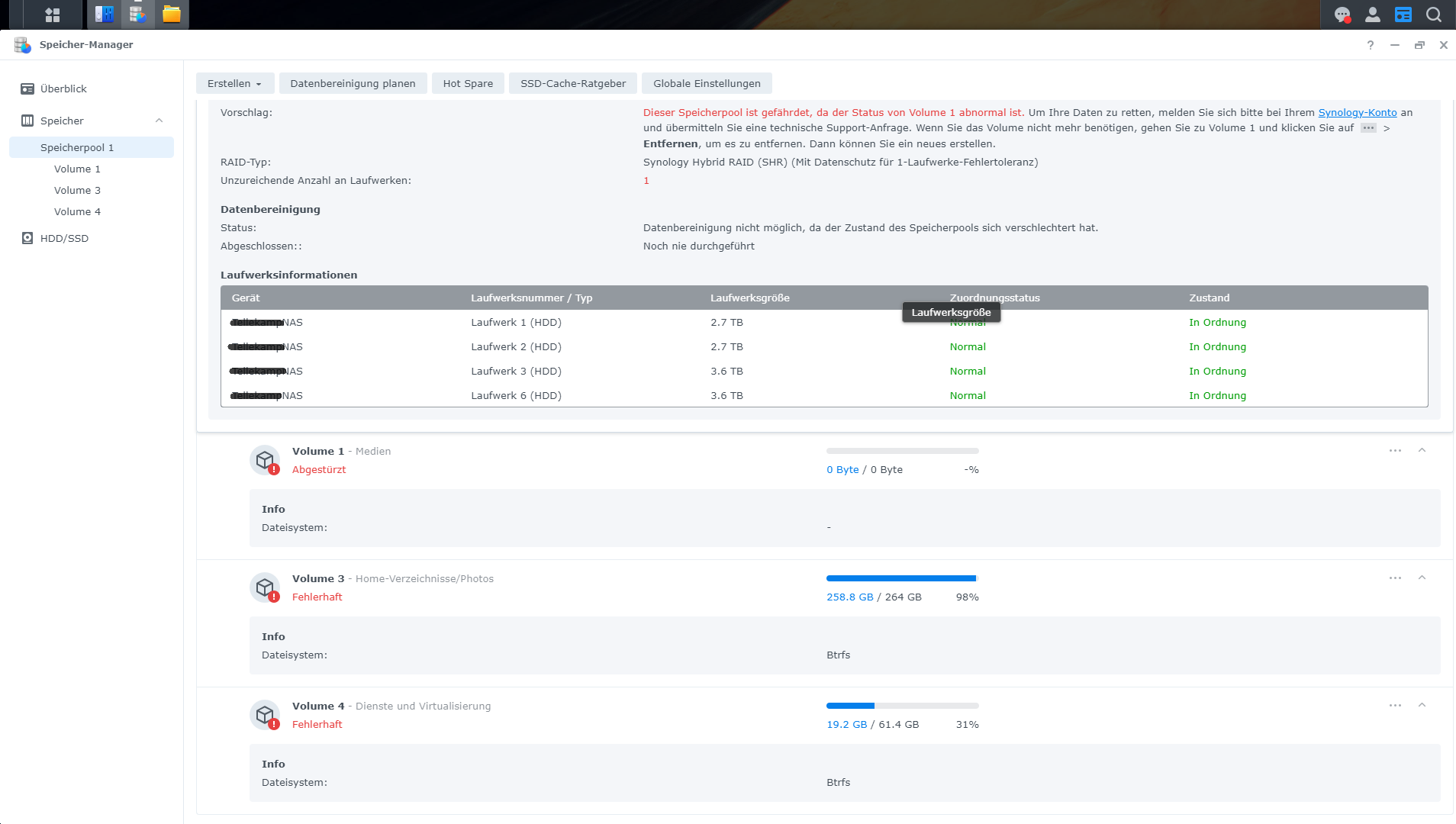
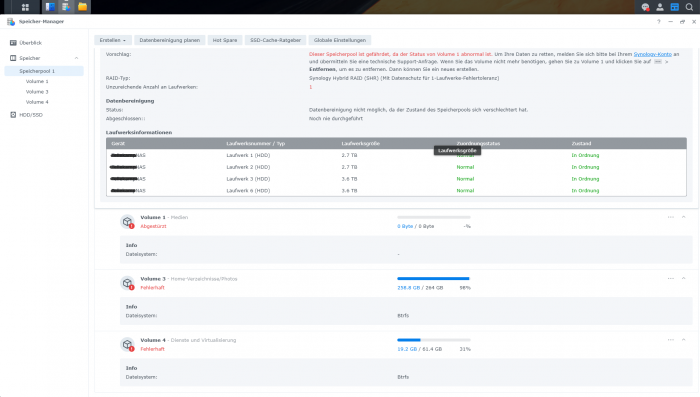
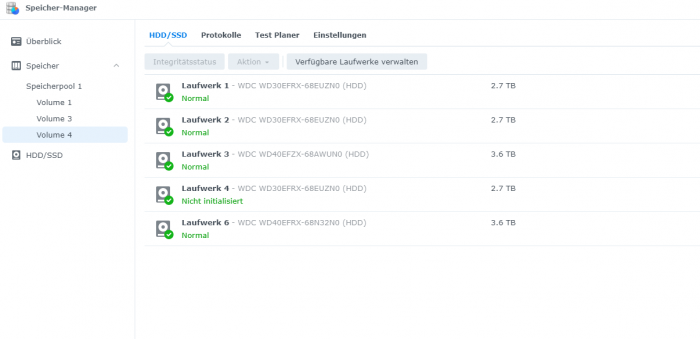
Hallo zusammen, Ich habe leider ein Problem, und hoffe hier auf eure Hilfe. Kurz zum Aufbau und aktuellem Status SHR-1 mit 5 (vor dem Stress 4) WD Red + HDDs : 3x 3TB und 2x 4TB (eine der 3TB Platten ist derzeit nicht eigebunden s.u.) ---> Volume 1 , EXT4 , 7 TB (Kein aktuelles Backup..... Shame on me) ---> Volume 3 , BTRFS, 260 GB (Backup 2 Tage alt) ---> Volume 4, BTRFS, 62 GB (Backup 2 Tage alt) Nach dem Update auf DSM 7.0 welches mehrere Tage Problemlos lief, baute ich gestern eine weitere 4TB Platte ein und fügte sie meinem SHR-1 hinzu. Bei ca. 75 % steig dann eine der 3TB Platten aus, mit stauts "Abgestürzt" die Volumes liefen alle noch, und das Raid hat sich trotz Status (Fehlerhaft) weiter erweitert, kurz vor Ende, ist die Kiste dann gänzlich eingefroren, und hat irgendwann nicht mal mehr auf pings reagiert. Nach einem Neustart lief die Speichererweiterung einfach weiter, jedoch jedoch nun war neben der Festplatte auch mein größtes Volume (1) "Abgestürzt". Sowie die beiden anderen Volumes auf dem selben SHR-1 Speicherpool in ReadOnly gegangen. Ich habe die Raid- Erweiterung dann zuende laufen lassen. Die Defekte Platte habe ich ausgetauscht(Auch wenn sie gar nicht so defekt scheint) Jedoch bleibt mein größtes Volume (und da es Medien sind, fehlt hier leider ein aktuelles Backup) weg, und ich möchte ungern den Raid reparieren mit der neuen Platte, und dabei eventuell die noch vorhandenen Daten des Volume überschreiben und es endgültig zerstören. Daher würde ich bevor ich das Raid repariere gerne das Volume wieder eingehängt bekommen. Um sicherzugehen das ich nichts weiter beschädige. Anbei ein Paar Infos aus der Konsole: cat /etc/fstab: none /proc proc defaults 0 0 /dev/root / ext4 defaults 1 1 /dev/mapper/cachedev_0 /volume1 ext4 usrjquota=aquota.user,grpjquota=aquota.group,jqfmt=vfsv0,synoacl,relatime,ro,nodev 0 0 /dev/mapper/cachedev_1 /volume3 btrfs auto_reclaim_space,ssd,synoacl,relatime,nodev 0 0 /dev/mapper/cachedev_2 /volume4 btrfs auto_reclaim_space,ssd,synoacl,relatime,nodev 0 0 lvdisplay: Using logical volume(s) on command line. --- Logical volume --- LV Path /dev/vg1/syno_vg_reserved_area LV Name syno_vg_reserved_area VG Name vg1 LV UUID HOyuTp-ozYw-WG4X-M1vA-WqQW-tRIm-CUoU8h LV Write Access read/write LV Creation host, time , LV Status available # open 0 LV Size 12.00 MiB Current LE 3 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 1024 Block device 249:0 --- Logical volume --- LV Path /dev/vg1/volume_1 LV Name volume_1 VG Name vg1 LV UUID o1PTXF-fKVl-9mKe-TFpF-lAd7-0TE4-8qgHGM LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 7.84 TiB Current LE 2055680 Segments 16 Allocation inherit Read ahead sectors auto - currently set to 1024 Block device 249:1 --- Logical volume --- LV Path /dev/vg1/volume_3 LV Name volume_3 VG Name vg1 LV UUID 4xFm7L-rVxD-w2Fc-GLQb-Hde5-9mLi-RX5vOa LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 275.00 GiB Current LE 70400 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 249:2 --- Logical volume --- LV Path /dev/vg1/volume_4 LV Name volume_4 VG Name vg1 LV UUID W6q8V3-wRjS-7pG6-Ww94-6oLm-vl3H-PCq2eR LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 64.00 GiB Current LE 16384 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 249:3 vgdisplay: Using volume group(s) on command line. --- Volume group --- VG Name vg1 System ID Format lvm2 Metadata Areas 4 Metadata Sequence No 55 VG Access read/write VG Status resizable MAX LV 0 Cur LV 4 Open LV 3 Max PV 0 Cur PV 4 Act PV 4 VG Size 8.17 TiB PE Size 4.00 MiB Total PE 2142630 Alloc PE / Size 2142467 / 8.17 TiB Free PE / Size 163 / 652.00 MiB VG UUID NyGatF-b85O-Ceg3-MuPY-sOTW-S2bo-P3ODO5 --- Logical volume --- LV Path /dev/vg1/syno_vg_reserved_area LV Name syno_vg_reserved_area VG Name vg1 LV UUID HOyuTp-ozYw-WG4X-M1vA-WqQW-tRIm-CUoU8h LV Write Access read/write LV Creation host, time , LV Status available # open 0 LV Size 12.00 MiB Current LE 3 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 1024 Block device 249:0 --- Logical volume --- LV Path /dev/vg1/volume_1 LV Name volume_1 VG Name vg1 LV UUID o1PTXF-fKVl-9mKe-TFpF-lAd7-0TE4-8qgHGM LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 7.84 TiB Current LE 2055680 Segments 16 Allocation inherit Read ahead sectors auto - currently set to 1024 Block device 249:1 --- Logical volume --- LV Path /dev/vg1/volume_3 LV Name volume_3 VG Name vg1 LV UUID 4xFm7L-rVxD-w2Fc-GLQb-Hde5-9mLi-RX5vOa LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 275.00 GiB Current LE 70400 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 249:2 --- Logical volume --- LV Path /dev/vg1/volume_4 LV Name volume_4 VG Name vg1 LV UUID W6q8V3-wRjS-7pG6-Ww94-6oLm-vl3H-PCq2eR LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 64.00 GiB Current LE 16384 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 249:3 --- Physical volumes --- PV Name /dev/md2 PV UUID aWjDFY-eyNx-uzPD-oqBO-5Gym-54Qr-zzkxUZ PV Status allocatable Total PE / Free PE 175270 / 0 PV Name /dev/md3 PV UUID J2CWXO-UmYK-duLr-3Rii-QcCe-nIoZ-aphBcL PV Status allocatable Total PE / Free PE 178888 / 0 PV Name /dev/md4 PV UUID 9xHJQ8-dK65-2lvJ-ekUz-0ezd-lFGD-pDsgZx PV Status allocatable Total PE / Free PE 1073085 / 0 PV Name /dev/md5 PV UUID GQwpPp-1c3c-4MSR-WvaB-2vEc-tMS6-n9GZvL PV Status allocatable Total PE / Free PE 715387 / 163 LVM Backup vor der Speichererweiterung: :~$ ls -al /etc/lvm/backup/ total 16 drwxr-xr-x 2 root root 4096 May 23 17:55 . drwxr-xr-x 5 root root 4096 May 23 17:44 .. -rw-r--r-- 1 root root 5723 May 23 17:53 vg1 Ich bin Dankbar für jede Hilfe. Schönen Abend noch Steven PS: Ja ich weis, es geht genau das Volume flöten von dem ich kein Backup habe welch Ironie
-
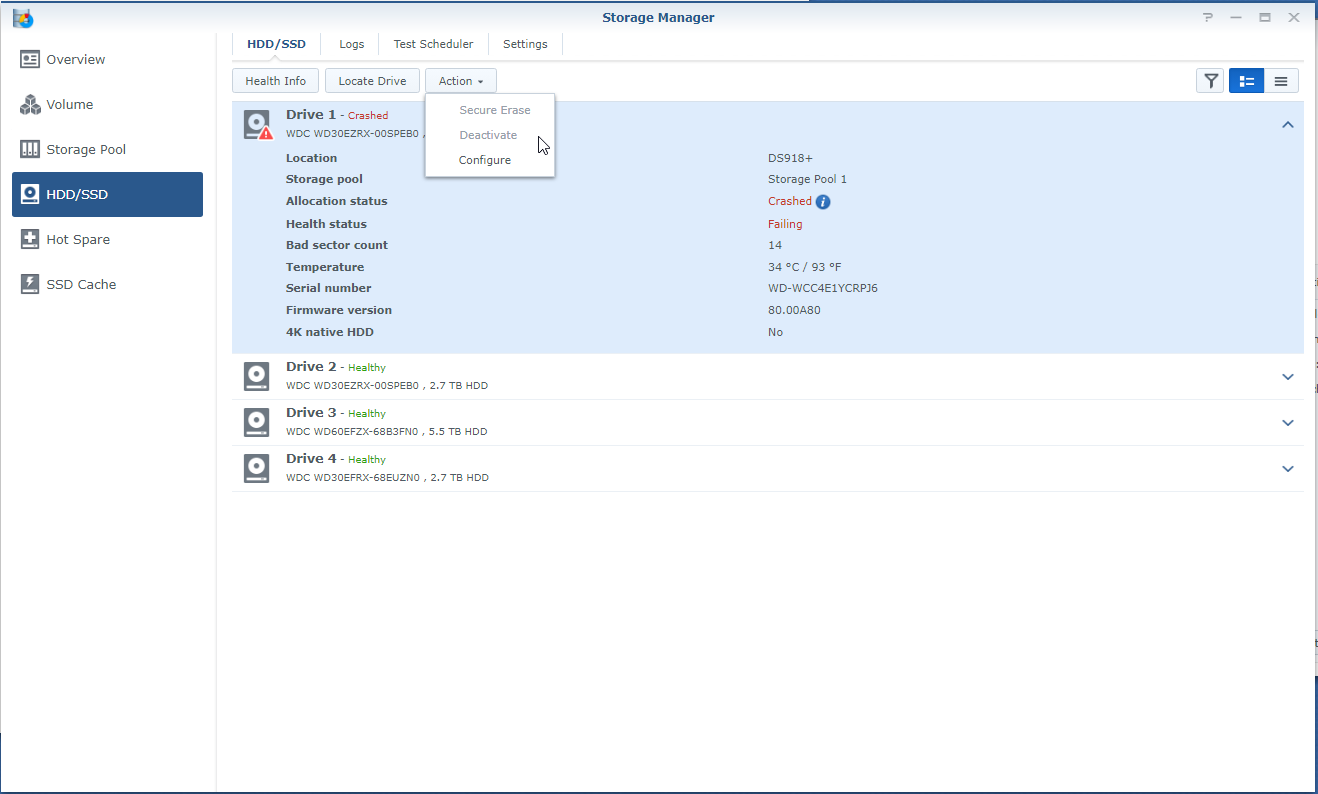
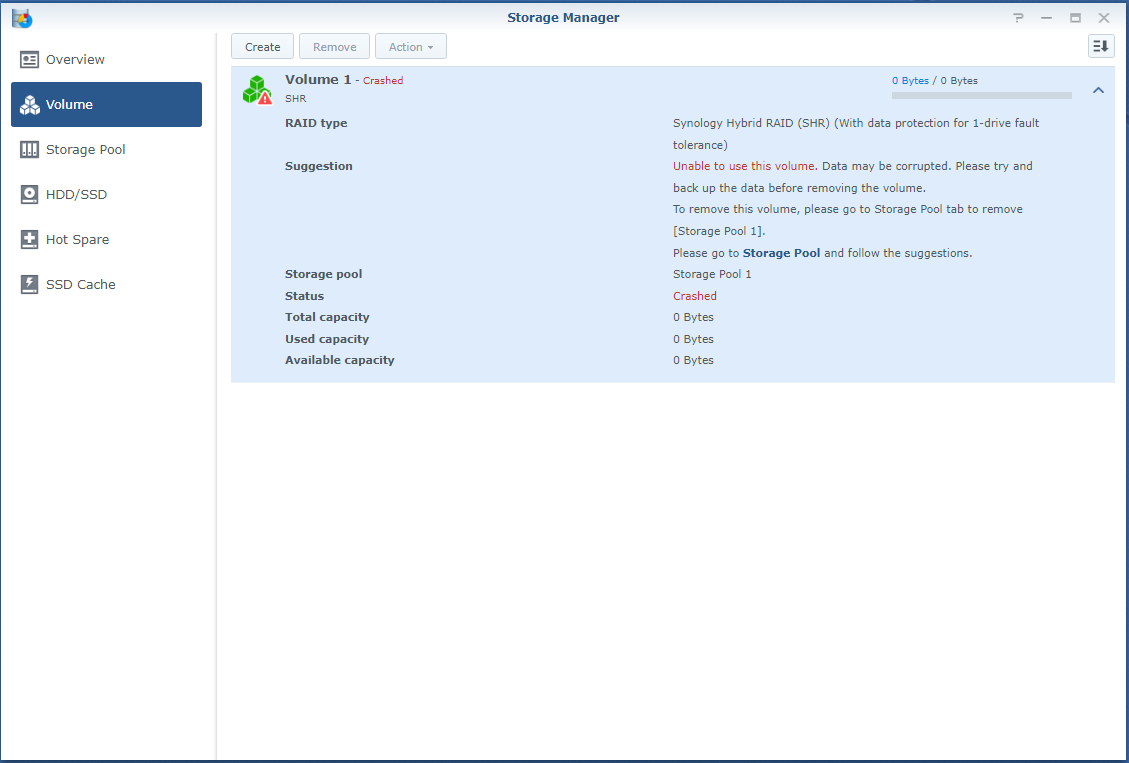
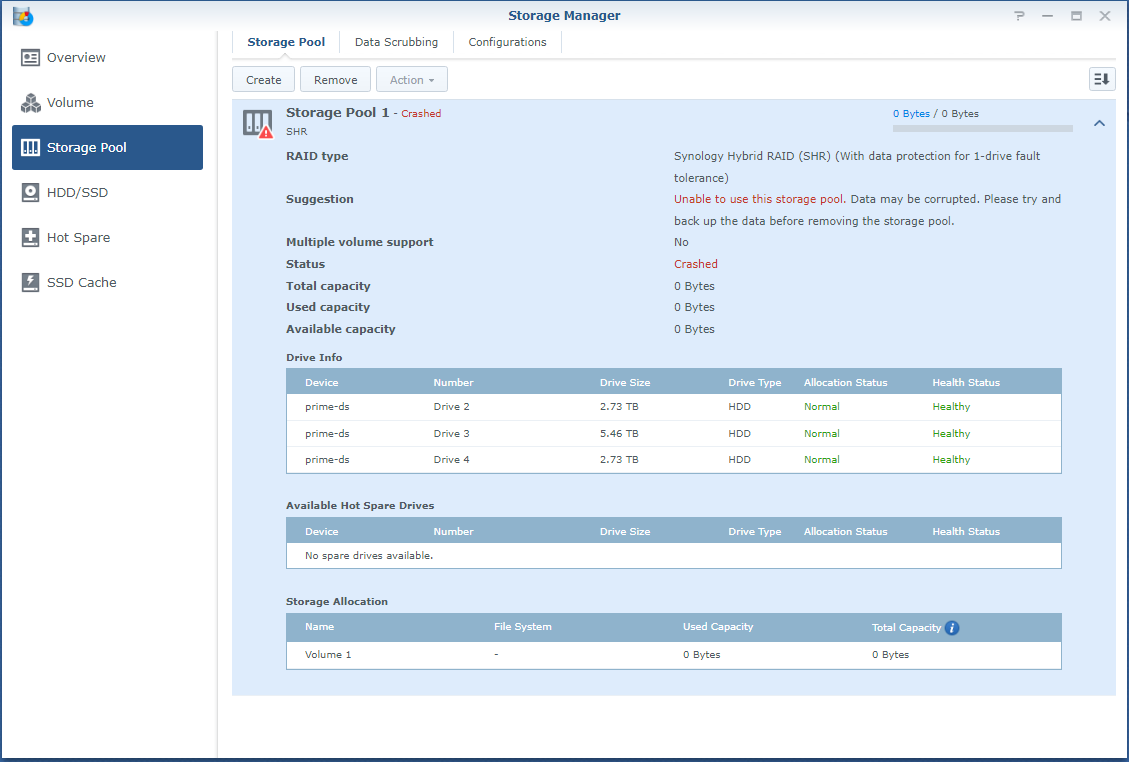
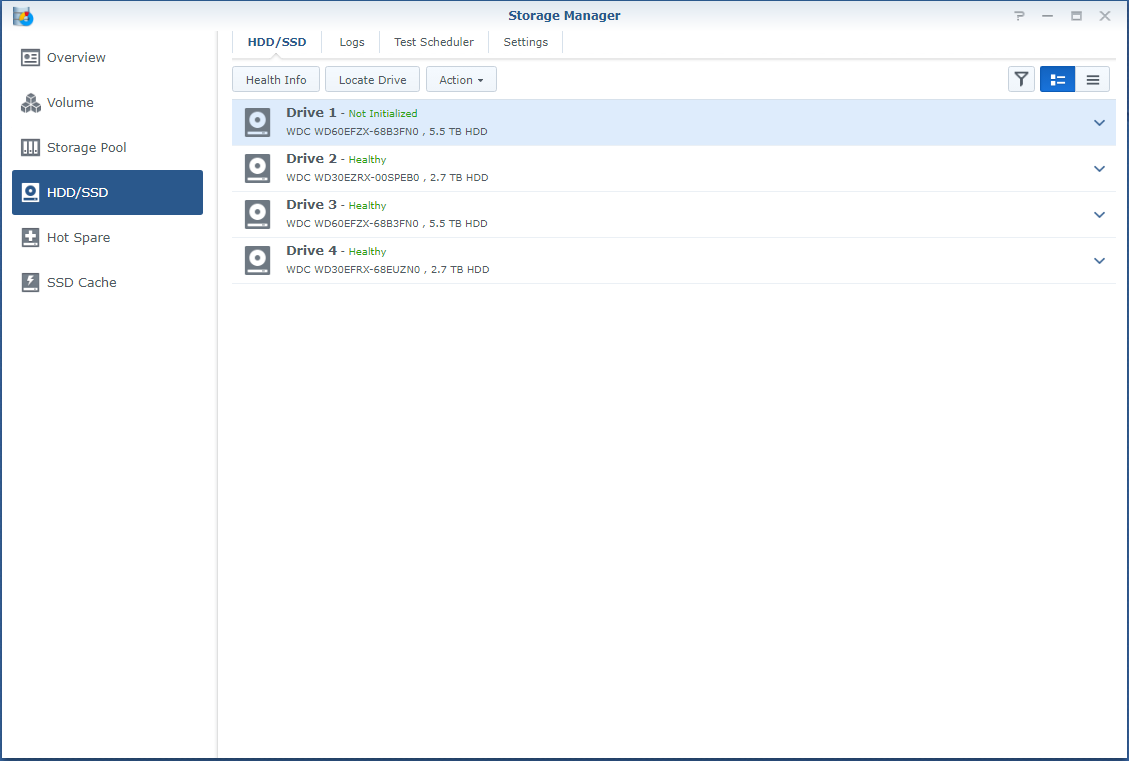
 So, I'm a bit stuck. Over the last years when a disk crashed, I'd pop the crashed disk out, put in a fresh one and repair the volume. No sweat. Over time I've migrated from a mixed 1 and 2TB disks to all 3TB one and earlier this year I'd received a 6TB one as a RMA for a 3TB one from WD. So I was running: Disk 1: 3TB WD - Crashed Disk 2: 3TB WD Disk 3: 6TB WD Disk 4: 3TB WD So I've bought a shiny new 6TB WD to replace disk 1. But that did not work out well. When running the above setup; I've a degraded volume, but it's accessable. When putting in the new one, the volume is crashed and the data is not accessable. I'm not able to slect the repair option; only 'Create'. When putting back the crashed disk, after a reboot the volume is accessable again (degraded). I've did a (quick) SMART test on the new drive and it seems OK. The only thing that's changed since the previous disk replacement is that I've did an upgrade to 6.2.3-25426. Could that be a problem? However, before we proceed (and I waste your time), I've got backups. Of everything. So, deleting and recreating a new volume (or the entire system) would not be that big of a deal; It'll only cost me a lot of time. But that seems the easy way to go. I've got a Hyper-Backup of the system on an external disk and all the apps and a few of the shares. The bigger shares are backed up to several other external disks. If I delete the volume, create a new one, restore the last Hyper-Backup and copy back the other disks, I'm golden? The Hyper-Backup will contain the original shares? Might that not be the best/simplest solution, I've attached some screenshots and some outputs so we know what we are talking about.. Thanks!
So, I'm a bit stuck. Over the last years when a disk crashed, I'd pop the crashed disk out, put in a fresh one and repair the volume. No sweat. Over time I've migrated from a mixed 1 and 2TB disks to all 3TB one and earlier this year I'd received a 6TB one as a RMA for a 3TB one from WD. So I was running: Disk 1: 3TB WD - Crashed Disk 2: 3TB WD Disk 3: 6TB WD Disk 4: 3TB WD So I've bought a shiny new 6TB WD to replace disk 1. But that did not work out well. When running the above setup; I've a degraded volume, but it's accessable. When putting in the new one, the volume is crashed and the data is not accessable. I'm not able to slect the repair option; only 'Create'. When putting back the crashed disk, after a reboot the volume is accessable again (degraded). I've did a (quick) SMART test on the new drive and it seems OK. The only thing that's changed since the previous disk replacement is that I've did an upgrade to 6.2.3-25426. Could that be a problem? However, before we proceed (and I waste your time), I've got backups. Of everything. So, deleting and recreating a new volume (or the entire system) would not be that big of a deal; It'll only cost me a lot of time. But that seems the easy way to go. I've got a Hyper-Backup of the system on an external disk and all the apps and a few of the shares. The bigger shares are backed up to several other external disks. If I delete the volume, create a new one, restore the last Hyper-Backup and copy back the other disks, I'm golden? The Hyper-Backup will contain the original shares? Might that not be the best/simplest solution, I've attached some screenshots and some outputs so we know what we are talking about.. Thanks!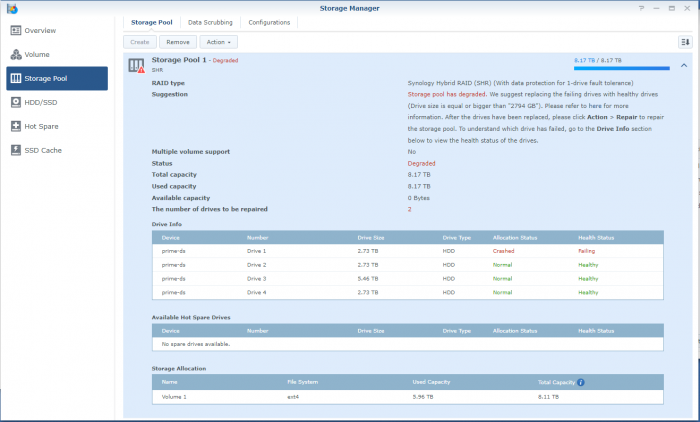
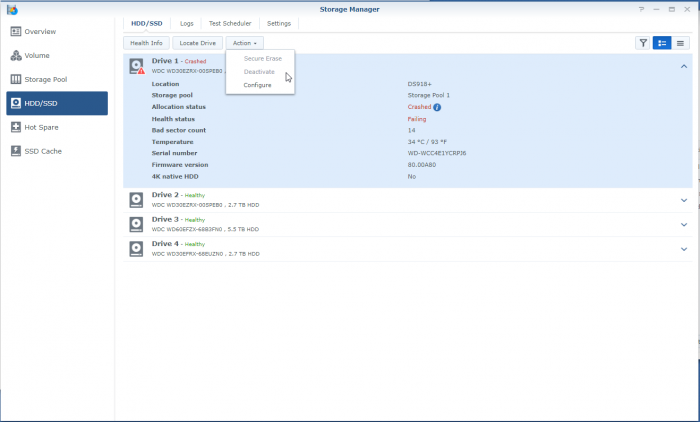
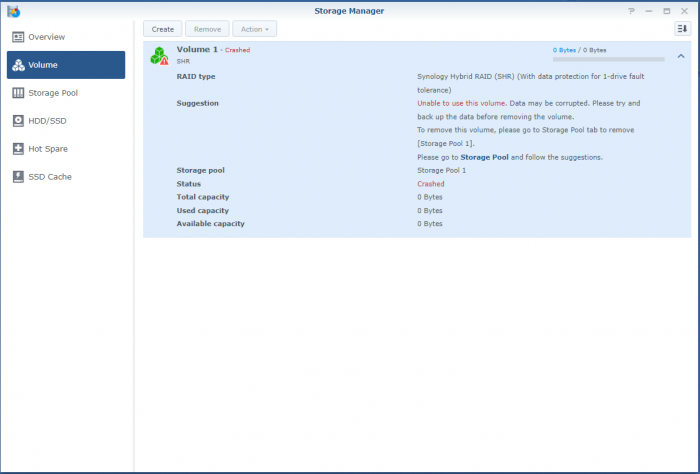
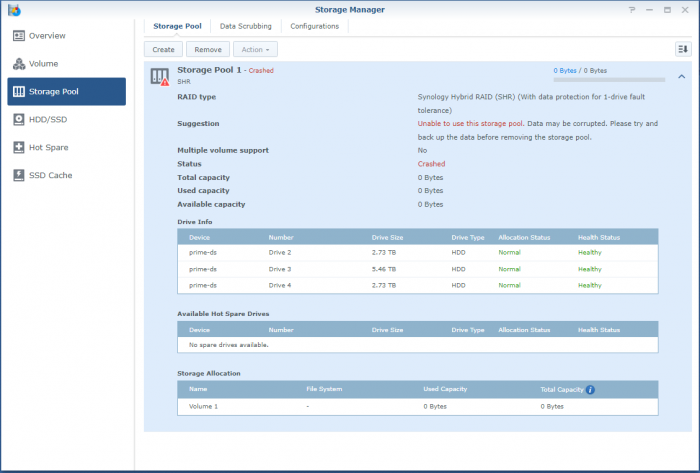
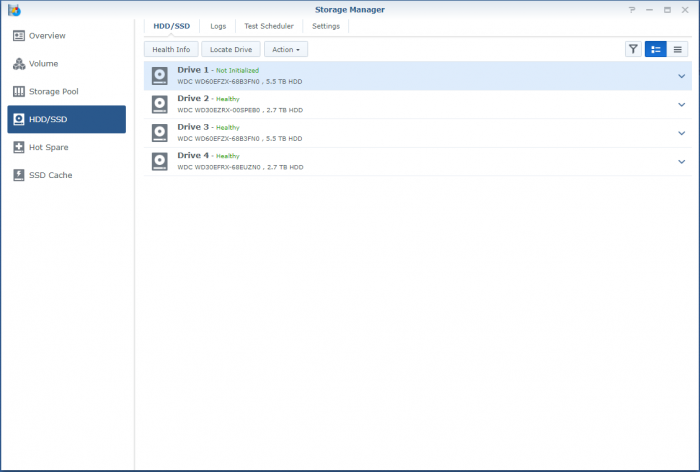
-
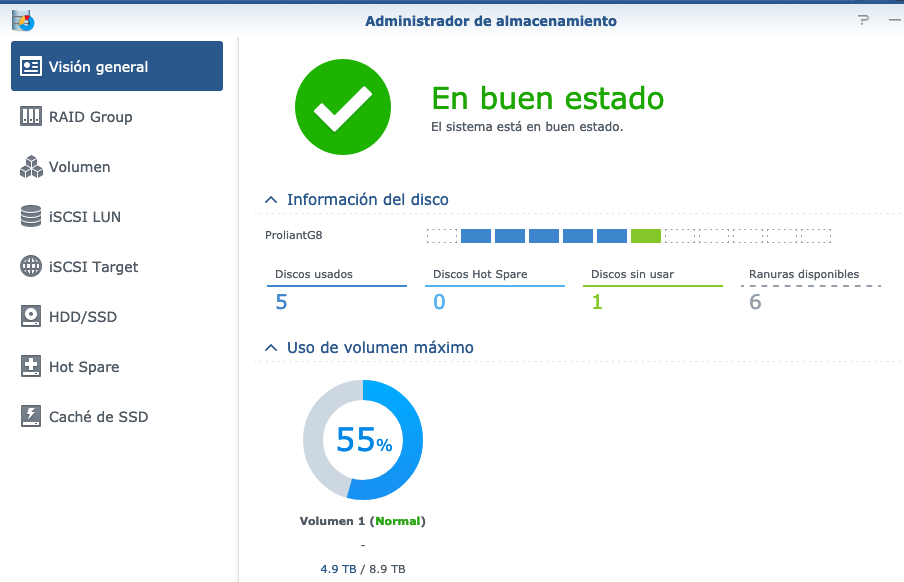
Buenos días, Tengo un HP Proliant Microserver gen8 con Proxmox montado y una de las máquinas virtuales con un Xpenology DSM 6.1. En ese Xpenólogy, la primera bahía (sata0) la tengo con la imagen de arranque synoboot.img y luego las cuatro bahías físicas del servidor están mapeadas directamente como sata1, sata2, sata3, sata4 con un grupo SHR y finalmente un sata5 con un disco virtual mapeado de un SSD como caché SSD por lo que me aparece la primera bahía utilizada sin uso y las siguientes 5 bahías con los discos. He conseguido otro servidor igual y quiero migrarlo con el DSM 6.2 Baremetal físico sin usar máquina virtual y el problema que tengo es que, como no necesito la imagen de arranque como disco ya que lo arranco desde microsd, los discos físicos empiezan a contar desde el principio por lo que quedan todos desplazados un lugar a la izquierda respecto al otro servidor. He procedido a cambiar el sata0 del synoboot.img de arranque del servidor virtual a sata6 para liberar la primera bahía virtual, querría dejar el servidor virtual con las bahías como el físico antes de migrar físicamente los discos al primero por lo que ahora queda como adjunto en la primera imagen. Mi miedo es que si muevo todos los discos una bahía menos al no estar en la bahía que tenían no reconozca el grupo SHR y pierda los datos. Como es un SHR con tolerancia a un disco de fallo, en vez de mover todos los discos podría mover la bahía de 1 de ellos por ejemplo el que está como sata4 la pase al sata0 pero no se si eso funcionará, es decir: si falla el disco de la bahía del sata4, Sinology sólo reconstruye el SHR si el "nuevo disco" lo monto en el sata4 o podría elegir otra bahía para reconstruirlo y así decirle que utilice la sata0? una vez tenga los 4 discos físicos en las 4 primeras posiciones, quitaría la caché SSD y procedería a mover los discos a las 4 bahías del servidor físico Cómo véis mi planteamiento? cómo lo puedo hacer? si de una NAS se jode una bahía y no se puede utilizar para reconstruir un grupo RAID, ¿no se puede asignar otra bahía para ese disco del grupo?

-
 So I have a bunch of drives in /volume1: 5x3TB 3x6TB (added later) Now I have a bunch more drives that currently in /volume3 (/volume2 was deleted, just 1 SSD for VM storage): 1x3TB 2x10TB and a bunch of unused drives: 3x3TB So I wanted to add all of the drives into one big /volume1. So... 1. I backed up /volume1 using HyperBackup into /volume2. 2. delete/destroy /volume1, 3. add all 3TB drives first (minus the one 3TB drive in /volume2) as well as the 3x6TB drives into the newlybuilt /volume1. All in SHR. 4. restore the HyperBackup from /volume2, destroy /volume2 5. Expand/add the 2x10TB from /volume2 into /volume1. So I'm left with 1x3TB unused. Questions: 1. Will this work? 2. What will happen to my DSM and apps during deletion, creation of SHR, and during restoration from HyperBackup? 3. Will the newly created volume/storage pool be in /volume1 or /volume4 after I removed /volume1? 4. Anything else I need to worry about? Because /volume1 used size is 20TB, and the HyperBackup in /volume2 is 18.4TB in size. Cheers and thanks!
So I have a bunch of drives in /volume1: 5x3TB 3x6TB (added later) Now I have a bunch more drives that currently in /volume3 (/volume2 was deleted, just 1 SSD for VM storage): 1x3TB 2x10TB and a bunch of unused drives: 3x3TB So I wanted to add all of the drives into one big /volume1. So... 1. I backed up /volume1 using HyperBackup into /volume2. 2. delete/destroy /volume1, 3. add all 3TB drives first (minus the one 3TB drive in /volume2) as well as the 3x6TB drives into the newlybuilt /volume1. All in SHR. 4. restore the HyperBackup from /volume2, destroy /volume2 5. Expand/add the 2x10TB from /volume2 into /volume1. So I'm left with 1x3TB unused. Questions: 1. Will this work? 2. What will happen to my DSM and apps during deletion, creation of SHR, and during restoration from HyperBackup? 3. Will the newly created volume/storage pool be in /volume1 or /volume4 after I removed /volume1? 4. Anything else I need to worry about? Because /volume1 used size is 20TB, and the HyperBackup in /volume2 is 18.4TB in size. Cheers and thanks! -
hi i have a ds3617xs setup. i created aa shr volume with 4 2TB disk. one of the disk died and i decided that i needed more space ,so i bought 2 new 4TB red drives. i started by replacing the failed 2TB drive with a 4TB repaired my volume and finally swapped an other 2Tb for a 4TB. all went well expect the total volume size doesn't seem to have increased. i was expecting to have 8TB available but i only have 5.6TB. do any of you can give me a clue about what's going on?
-
So I've been running different versions of Xpenology for a while now and when I think about it, the only real reason I like it is because I can use multiple types of drive sizes to create one volume. My workplace recently bought a brand new Supermicro server valued over $15k USD and the IT guy was explaining how the "pools" work in the new Windows Server environment. Apparently, it's a rip of a Linux method of creating volumes which means this now works similar to SHR in that it can create volumes with multiple drive sizes without hiding a big chunk of data because it won't fit into an equal RAID amount. For me the biggest plus would be if I have to restart my server, I won't have to rebuild the entire volume because windows server supports more than 12 drives unlike Xpenology on reboot. Not to mention hyperthreading power. I was just wanting to hear peoples thoughts on this. Would you switch to windows server 2016? Why or why not?
-
A little background... I've been thinking about setting up a NAS for quite a while. Recently my family decided to digitize the entire stockpile of VHS and camcorder Hi8 home videos. After digitizing the first box, we calculate that it's going to take many terabytes to get it all done. Cloud storage is looking to be hundreds of dollars a year. So I decided to pull the trigger and build a NAS to store them all along with all my other media. I have Roku's all through the house and purchased PLEX. Roku's have a great PLEX application. My co-worker suggested building my own NAS to save money and have a NAS capable of supporting PLEX transcoding and various other computing intensive activities desirable on a NAS. I'm using a Windows box with an I-3 processor and 12 GB RAM that was laying around. It had a couple of 500 GB drives and I added 2 more 4 TB drives with the expectation of upgrading the 500's over time. In another thread on this forum, I was told that all I needed was a supported SATA 3.0 expansion card with the port density I wanted and let DSM's software RAID controller do the work. I went with that advice and installed a four port SATA 3.0 card to give me 6 ports total including the 2 motherboard SATA 3.0 ports. Currently the 4 drives are attached to the card. I had small spare SSD drive that I connected to the motherboard that I intend to use as a cache. After the hardware build, I followed these instructions: https://github.com/XPEnology/JunLoader/wiki/Installing-DSM-6.0-Bare-Metal and successfully installed DSM from the .pat file linked to in this tutorial. Using the two 500 GB drives was based on my co-worker's experience of using SHR to have a redundant RAID setup with different sized drives and the ability to swap out a bad drive with a larger drive and/or upgrade to larger drives in the future. However after the install, when attempting to build the RAID group, there is no SHR option. Some quick research revealed that not all versions of DSM support SHR. Here's a page that lists those versions: https://www.synology.com/en-us/knowledgebase/DSM/tutorial/Storage/Which_models_have_limited_support_for_Synology_Hybrid_RAID_SHR Looking in the specs of my DSM install shows that it thinks it's a DSM3615xs device. Sure enough, this is listed on the above page as not supporting SHR. So my questions are, should I pursue trying to install a version of DSM that does support SHR with the xpenology boot loader? I really like the idea of being able to use what ever size drives I want. If I set up a traditional RAID, I'll need to purchase two more 4 TB drives now and then I'd have to start all over if I want to increase drive size instead of adding more 4 TB drives. If SHR is desirable, what version of DSM should I use and where do I get it? Thanks
-
Hi Everyone, I made a really stupid mistake of deleting volume 1 of my NAS. The Volume consists of 2 - 2TB WD drives and 1 - 1TB WD drive. one of the 2TB drives failed and I was supposed to repair it. I've done this before but in this instance, it totally slipped my mind that I need to uninstall the failed drive first before running the repair function. I made the moronic mistake of thinking the repair function was the remove volume function and now I lost volume 1. The failed drive is now uninstalled, the other 2 drives show they are healthy but the status is "system partition failed". Is there a way I can rebuild volume 1 or just remount it from the data of the 2 remaining drives? Thanks so much for your help. Details: RAID: SHR Machine: DS3615xs DSM Version: 5.2-5644
-
Общие FAQ / Общие часто задаваемые вопросы Перевод. Оригинал здесь https://xpenology.com/forum/topic/9392-general-faq/ Целью данного руководства являются ответы на обычно задаваемые вопросы! Это не раздел, где просят о помощи. Для этой цели Вы можете использовать форум. 1. Что такое XPEnology? XPEnology представляет собой основанный на Linux загрузчик, разработанный с целью эмулировать (оригинальный) загрузчик Synology, позволяющий операционной системе (ОС) Synology Disk Station Manager (DSM) работать на сторонних аппаратных средствах (читай: железе, выпущенном не компанией Synology) и эмулировать определённые модели устройств Diskstation. В случае последнего загрузчика, к эмулируемым моделям относятся: DS916, DS3615 и DS3617. 2. Законно ли использовать это? Операционная система Disk Station Manager (DSM) основана на открытом исходном коде и XPE/DSM использует преимущества, вытекающие из распространения и использования открытого кода. Вам всегда стоит использовать собственное суждение и читать перед установкой и использованием операционной системы DSM с XPEnology. Мы не можем быть ответственны за Ваши действия. * вопрос спорный, поскольку сама ОС DSM разработана на основе открытого исходного кода, однако она использует пакеты, которые лицензированы компанией Synology и подразумевают их использование при согласии с условиями лицензии. 3. Как насчёт использования Synology QuickConnect и других фирменных сервисов? QuickConnect и сервисы, которые используют серверы Synology, требуют подлинный серийный номер и MAC адрес Synology. Неправильное/неправомерное использование сервисов Synology не приветствуется XPE-сообществом. 4. Почему Менеджер (Мониторинг) Ресурсов показывает, что у меня двуядерный процессор core i3? Потому что это жёстко запрограммировано. Тем не менее это всего лишь "косметическая" особенность. Вы можете проверить с помощью следующей команды установленные в системе процессоры: 5. Как я могу получить доступ к своему NAS через Интернет? Есть несколько способов, но в любом случае Вам придётся настраивать перенаправление/проброс портов (port forwarding). Необходимые (задействованные по умолчанию) порты перечислены ниже, на сайте Synology: https://www.synology.com/ru-ru/knowledgebase/DSM/tutorial/General/What_network_ports_are_used_by_Synology_services Рекомендуется также настроить службу DDNS (Dynamic DNS) или на Вашем роутере/маршрутизаторе (см. руководство, прилагаемое к роутеру), или на NAS-устройстве, как показано в этом уроке: https://xpenology.com/forum/topic/7573-tutorial-setup-a-ddns-in-dsm/ Также рекомендуется использовать решение VPN для удалённого доступа для лучшей безопасности. 6. Какие настройки последовательного порта для консольного соединения с загрузчиком Jun's? Известно, что эти настройки работают в Putty: Показать содержимое COM1 Speed - 115200 Data Bits - 8 Stop Bits - 1 Parity - None Flow Control - None Hide 7. Куда я могу сообщить если обновление работает или не работает? Вы можете сделать это, перейдя по ссылке ниже. Пожалуйста, прочтите READ ME темы форума прежде чем сообщать что-либо. https://xpenology.com/forum/forum/78-critical-updates/ 8. Для чего нужен загрузчик и где сохраняется ОС DSM, когда я устанавливаю её на свой компьютер? Сколько места они занимают? Загрузчик имитирует внутренний чип, который находится в реальных устройствах Synology. Этот внутренний флэш-ключ содержит микропрограмму (ядро), необходимую для загрузки. Когда вы устанавливаете DSM благодаря загрузчику, DSM устанавливается на все диски, присутствующие в машине, а не на ваш USB диск, содержащий загрузчик. Теперь давайте предположим, что вы установили DSM, и решили обновить её. DSM будет обновляться на всех жестких дисках. Если обновление также поставляется с обновленной прошивкой (ядром), то оно также будет обновлено и на USB-ключе. Это в основном единственная часть, которая копируется в загрузчик. Вот почему в некоторых случаях, если у вас было работающее устройство XPEnology, которое по какой-то причине сломалось, и вы пытаетесь переустановить более раннюю версию DSM, Вы не сможете этого сделать, потому что ядро, содержащееся в USB-ключе, новее, чем в .PAT-файле, используемом для переустановки DSM. Теперь, когда Вы устанавливаете DSM, создаются два раздела. Системный Раздел (~2 ГБ) и раздел подкачки - SWAP (~2,4 ГБ), которые находятся в RAID1 (всегда). Каждый раз, когда вы добавляете новый диск в свой компьютер, он инициализируется, и на нем создаются два раздела и устанавливается DSM. Цель всего этого заключается в том, что до тех пор, пока у вас есть один рабочий диск, вы сможете загрузить DSM. 9. Как вернуть SHR RAID в новых версиях DSM? Добавлено 14/12/2019 по просьбе @i926 (Moderator) Начиная с версии DSM 6, Synology лишила нас поддержки по умолчанию, в создании гибридных массивов SHR и SHRII. Пользователем @A.S._id, были созданы скрипты, для удобства возвращения поддержки SHR и SHRII и обратно по умолчанию Включение поддержки SHR и SHRII : ssh admin@ Ваш ip sudo -s cd /etc.defaults sed -i '/^/s:supportraidgroup="yes":support_syno_hybrid_raid="yes":' synoinfo.conf reboot Отключение поддержки SHR и SHRII. Возврат к значению по умолчанию ssh admin@ Ваш ip sudo -s cd /etc.defaults sed -i '/^/s:support_syno_hybrid_raid="yes":supportraidgroup="yes":' synoinfo.conf reboot Решение проблемы, любезно предоставил @A.S._id, за что ему Респект и Уважуха 😉
-
 hi, if some one has some time to spare it might worth a try to have a look into the extra.lzma /etc/jun.patch jun is using that to patch (diff files) dsm config files at boot on 916+ he is patching synoinfo.conf to maxdisks=12 (there might be a mistake in that case as he sets the intern disks to 0xff instead of 0xfff? - maybe just a typo no one recognized before?) that could also be done on 3515/17 to achieve a higher disk count and activate shr and as patch (diff) kicks in if it exactly matches it could be done in a way that it kicks in when the already modded synoinfo.conf is reset to the default one like when a dsm update reseting the synoinfo.conf mostly interesting for people with a higher disk count then 12 any one willing to do and test it? if done and tested it could be part of the extra.lzma i do for the additional drivers (extended jun.patch file) like new default disk count to 24 (needs to touch maxdisks, usbportcfg, internalportcfg, esataportcfg) and activate SHR in best case there will be much less hassle when updating dsm
hi, if some one has some time to spare it might worth a try to have a look into the extra.lzma /etc/jun.patch jun is using that to patch (diff files) dsm config files at boot on 916+ he is patching synoinfo.conf to maxdisks=12 (there might be a mistake in that case as he sets the intern disks to 0xff instead of 0xfff? - maybe just a typo no one recognized before?) that could also be done on 3515/17 to achieve a higher disk count and activate shr and as patch (diff) kicks in if it exactly matches it could be done in a way that it kicks in when the already modded synoinfo.conf is reset to the default one like when a dsm update reseting the synoinfo.conf mostly interesting for people with a higher disk count then 12 any one willing to do and test it? if done and tested it could be part of the extra.lzma i do for the additional drivers (extended jun.patch file) like new default disk count to 24 (needs to touch maxdisks, usbportcfg, internalportcfg, esataportcfg) and activate SHR in best case there will be much less hassle when updating dsm -
I'm just getting started on my own bare metal installation but I have been running several true Synology systems for years. First things I noticed was the lack of SHR (Synology Hybrid Raid) as an option. Is this a hardware limitation or something else?
-
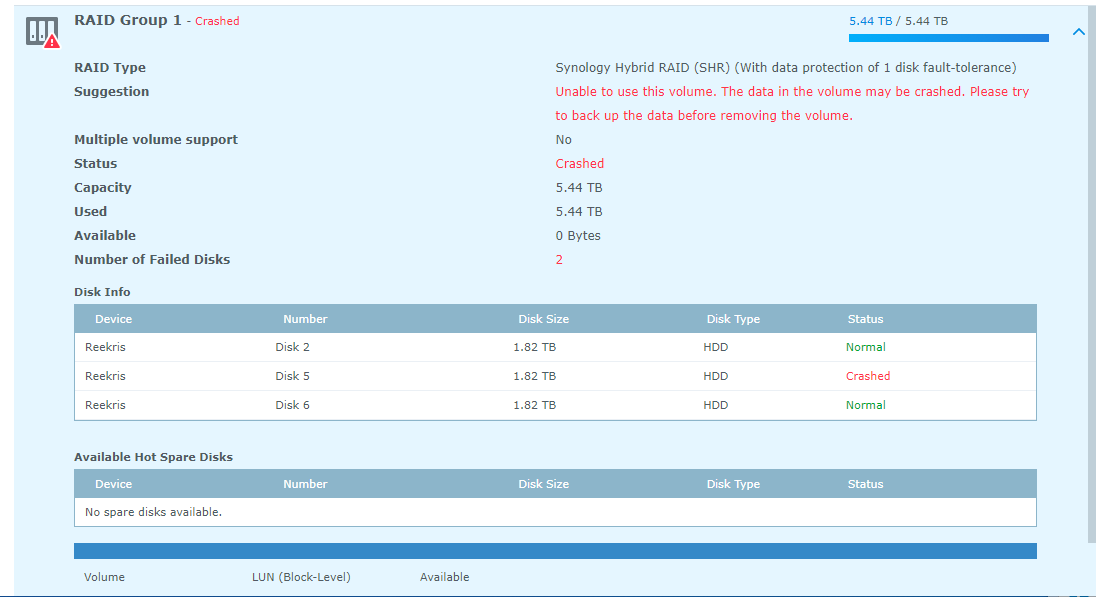
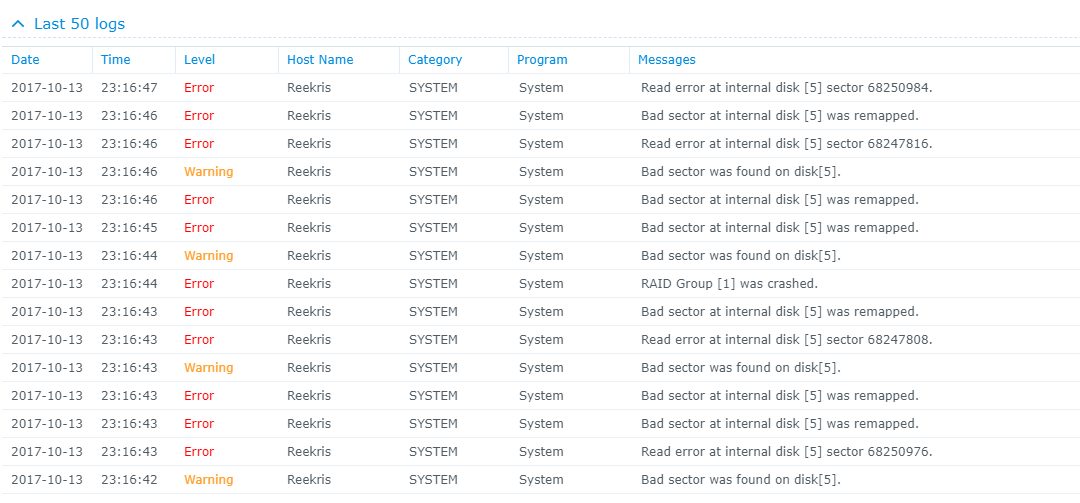
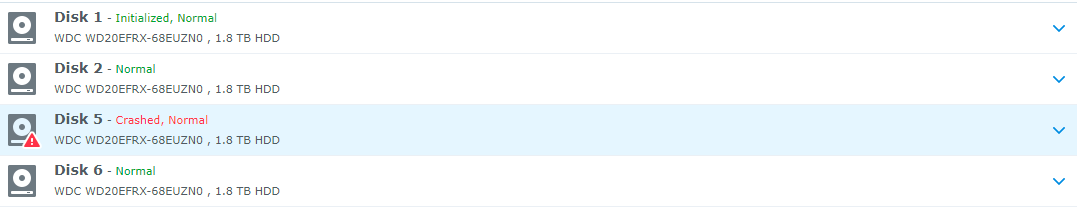
Alright, strap yourselves in, because this might get long... Hardware setup: 4x WD 2TB Red in SHR ASRock H81M-HDS Mobo Intel Celeron Processor 8GB Crucial Ballistix RAM First, some background: A few days ago I noted the network drives that I have on my system were not showing up in Windows so I navigated to the system via my browser and the system told me I needed to install an update and that my drives were from an old system and would need migration. I wrote a different post about that here: The versions it wanted to install was the same version (or slightly higher) of 5.2 so I thought nothing of it and agreed to let the system update. It went through the install smoothly, but never rebooted. Eventually I was able to navigate back to the web browser and it told me I now had 5.2 firmware, but 6.1-15152 DSM. I am still unclear how this install happened, but I assume that it downloaded it automatically from the internet even though I had enabled the "only install security patches" option. As I posted in the Tutorial forum a few posts after the linked one, I was able to get Jun's loader installed and boot into 6.1-15152 and I thought all was well. However, when I booted into the DSM, I was in a world of hurt. I have one bad disk in the array clearly that lists bad sectors, but that's the point of the SHR array right? Well I let the RAID start to repair itself and always around 1.5% into the repair it crashes and tells me the System Volume has crashed. However, you'll notice in the Disk Info Section there are only 3 disks. Looking into the logs show that Disk 5 (the bad one) failed at trying to correct bad sectors: However, when this happens Disk 1 (AFAIK, perfectly fine drive) switched into Initialized, Normal but drops out of the RAID array and then it goes into crash mode. I don't understand the relationship between Disk 5 crashing out when repairing the RAID and Disk 1 disappearing. It stands to reason that if Disk 1 is fine, which is seems to be that it would just fail and stay in degraded mode until I can swap in a new drive. I have tried starting the system with Disk 5 unplugged, but that does no good. I have also begun playing around with attempts at data recovery in a LiveUSB of Ububntu using some of Synology's guides as well as just googling around. So I suppose I have a few questions. 1. Does anyone know of a relationship between possibly installing the new system, and the bad disk causing the good disk to crash? 2. How likely is it that Disk 1 (AFAIK good disk) is also toast. 3. Do you have any tips for recovering data from a situation like this? I would greatly appreciate any help or advice you can provide. I have been banging my head against a wall for 3 nights working on this. I have all the really important stuff backed up to the cloud so it is not a matter of life and death (5 year, 10000 photos) but there is a lot of other media that I am willing to do a lot to not replace or only replace some of.
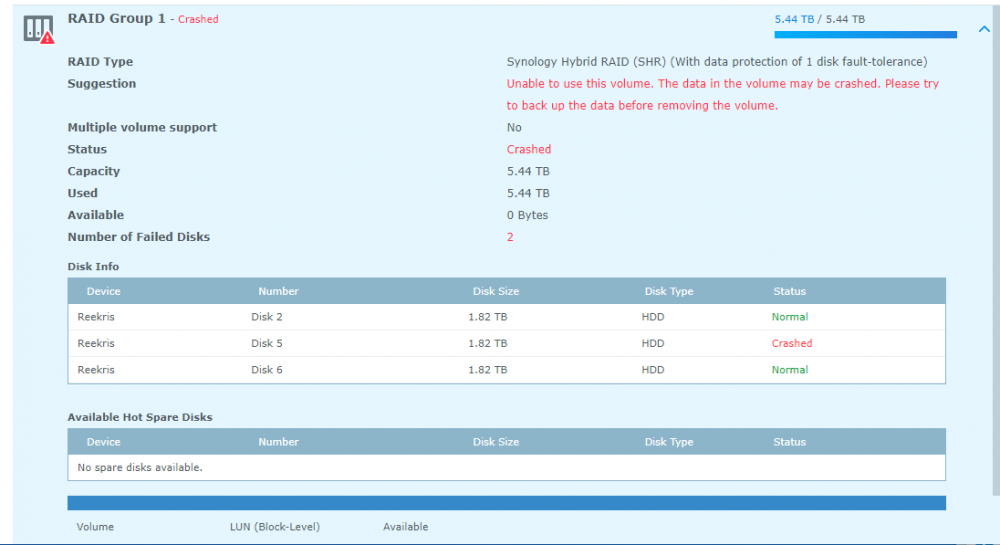
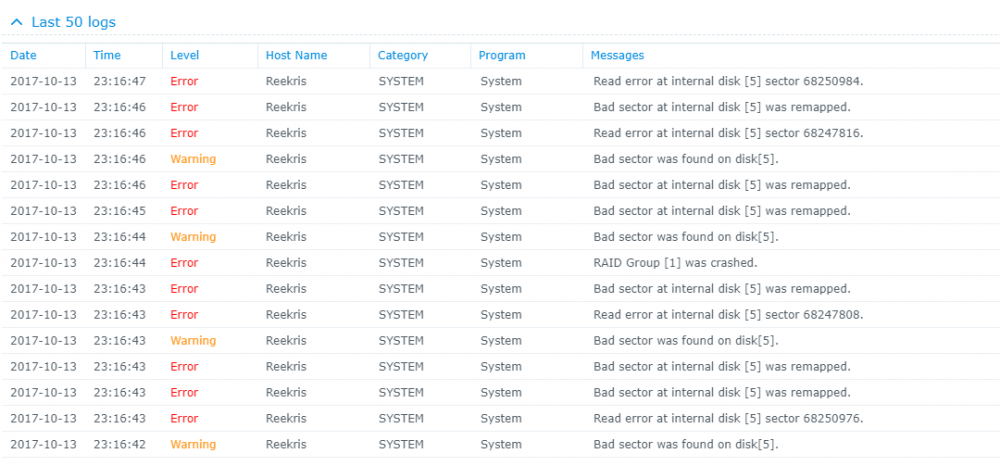
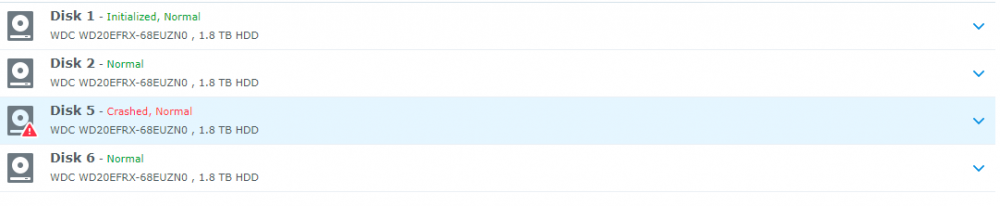
-
 I have run DSM 5.2 for quite a while. Initially on HP microserver, then on ESXi. upgraded a couple of times(from dsm4). didn't have issue. This time, I upgraded from 5.2 to 6.1, also from ESXi to directly run on Lenovo ts440. It took me a while to make upgrade and migration work because I initially downloaded wrong loader image. When it finally worked, I noticed one of the 6 disks that make up my primary volume is missing. files are still fine though, but the volume was in 'degrade' state. Before I realized it was because DS3615 support upto 12 internal drives by default, and just by chance the missing drive was on the 13th slot, I did a couple of thing trying to identify which drive was missing and if it was damaged. - ... multiple try to pull out individual drive -- now two drives were missing. but I can get SHR back once I everything back - I narrow down to one of three drives, so instead of pulling them one by one, I rotate them in different slot. Let me call them A, B, C and this is in original slot order; after switch, the order became B, C, A. - now I can see that C was originally missing, but now A is missing and C appears but has error access system partition. and now the volume is "crashed". Now I think the fatal step was that I opt to "repair" the system partition on C at this point. I should have put everything back at this point. Of course I still don't have all the drives, but I finally remembered 12 disk limit by DS3615's default, and I change that to 24, expecting all would be good. However I was present with the degraded volume with 0 size and 0 available space, and the shared directories disappeared from both web interface and ls -l command (ssh remote in). the missing drive becomes available drive, so I can use it to 'repair' the volume. I started to really worry now, but still remain hopeful that after repair I will be able to recover some data. I was wrong. after repair I have a volume with full size (about 13T), but all used, and 0 byte free space, and all folders are still missing. I did back up my photo/home video folders, home folders, and shared document folders. I do wish to get my video library, music, and ebook libraries back, so that I don't need to go back the the original media (some might not here anymore). I am quite comfortable with linux command line, if someone can point out a way to recover the data it would be very much appreciated!!! Thank you in advance!
I have run DSM 5.2 for quite a while. Initially on HP microserver, then on ESXi. upgraded a couple of times(from dsm4). didn't have issue. This time, I upgraded from 5.2 to 6.1, also from ESXi to directly run on Lenovo ts440. It took me a while to make upgrade and migration work because I initially downloaded wrong loader image. When it finally worked, I noticed one of the 6 disks that make up my primary volume is missing. files are still fine though, but the volume was in 'degrade' state. Before I realized it was because DS3615 support upto 12 internal drives by default, and just by chance the missing drive was on the 13th slot, I did a couple of thing trying to identify which drive was missing and if it was damaged. - ... multiple try to pull out individual drive -- now two drives were missing. but I can get SHR back once I everything back - I narrow down to one of three drives, so instead of pulling them one by one, I rotate them in different slot. Let me call them A, B, C and this is in original slot order; after switch, the order became B, C, A. - now I can see that C was originally missing, but now A is missing and C appears but has error access system partition. and now the volume is "crashed". Now I think the fatal step was that I opt to "repair" the system partition on C at this point. I should have put everything back at this point. Of course I still don't have all the drives, but I finally remembered 12 disk limit by DS3615's default, and I change that to 24, expecting all would be good. However I was present with the degraded volume with 0 size and 0 available space, and the shared directories disappeared from both web interface and ls -l command (ssh remote in). the missing drive becomes available drive, so I can use it to 'repair' the volume. I started to really worry now, but still remain hopeful that after repair I will be able to recover some data. I was wrong. after repair I have a volume with full size (about 13T), but all used, and 0 byte free space, and all folders are still missing. I did back up my photo/home video folders, home folders, and shared document folders. I do wish to get my video library, music, and ebook libraries back, so that I don't need to go back the the original media (some might not here anymore). I am quite comfortable with linux command line, if someone can point out a way to recover the data it would be very much appreciated!!! Thank you in advance!