Search the Community
Showing results for tags 'crash'.
Found 14 results
-
 Hi, some time ago on my xpenology 6.1.5 i got RAID1 crashed due to power failure. then I sure did the most stupidiest thing - didn't made a backup of hdd before trying to recover raid... and after week of trying different things i have following: 1) /VOLUME2 - single 2tb HDD used for non-vital stuff - working okay. i even backed up almost all important data from RAID1 - it was in 'readonly' state for a while :) 2) /VOLUME1 - crashed two RAID1 hdds. disk A and disk B. - disk A is almost okay, but says system volume crashed, - disk B - after trying to reassemble raid to make it think it contains one drive only - i ended up with 'recreating' raid and clearing superblock. (I wanted to reassemble with mdadm -assemble -disks=1, but instead made --create, so it cleared superblock :( ) now synology doesnt see volume1 at all. and shows raid is crashed. Now the need - i have 3 iSCSI LUNs - one non growing - and i just took the image file from @iSCSI folder and successfully copied all the data from inside - two more - looks like they are in strange ADVANCED format and growing-style. I cannot understand how to mount them or copy (ls shows unreal file sizes like 100 GB). I tried to check with 'btrfs --show' but it doesnt recognize any filesystem inside. I have really important data there, how can i copy or mount those stange LUNs? p.s. i had no spare drive to add to rebuild raid classically by adding new disk - and also was worried about stressing existing drives - both are 45.000 hrs+ online.
Hi, some time ago on my xpenology 6.1.5 i got RAID1 crashed due to power failure. then I sure did the most stupidiest thing - didn't made a backup of hdd before trying to recover raid... and after week of trying different things i have following: 1) /VOLUME2 - single 2tb HDD used for non-vital stuff - working okay. i even backed up almost all important data from RAID1 - it was in 'readonly' state for a while :) 2) /VOLUME1 - crashed two RAID1 hdds. disk A and disk B. - disk A is almost okay, but says system volume crashed, - disk B - after trying to reassemble raid to make it think it contains one drive only - i ended up with 'recreating' raid and clearing superblock. (I wanted to reassemble with mdadm -assemble -disks=1, but instead made --create, so it cleared superblock :( ) now synology doesnt see volume1 at all. and shows raid is crashed. Now the need - i have 3 iSCSI LUNs - one non growing - and i just took the image file from @iSCSI folder and successfully copied all the data from inside - two more - looks like they are in strange ADVANCED format and growing-style. I cannot understand how to mount them or copy (ls shows unreal file sizes like 100 GB). I tried to check with 'btrfs --show' but it doesnt recognize any filesystem inside. I have really important data there, how can i copy or mount those stange LUNs? p.s. i had no spare drive to add to rebuild raid classically by adding new disk - and also was worried about stressing existing drives - both are 45.000 hrs+ online. -
After 4-5 years happy usage of Debian9 + Proxmox5.2 + Xpenology dsm 5.2 I upgraded six months ago to DSM6.2.3 Proxmox6.3-3 Debian10. All went well, until a few weeks ago... One night at 3am my volume 2 crashed! Since then I can read my shares from volume 2, but not write. It is read-only. I suspect the activation of write back cache in proxmox is the reason. Status of SMART and all my harddrives and raid controller is just fine, so I suspect no hardware issue. After using google, this forum and youtube I still have no solution. The crashed volume has all my music, video's, photo's and documents. I have a spare 3TB WD RED HD directly connected to the MB and copied most importend files. However I have a backup of the most important files, I prefer to restore the crashed volume, but starting to become a bit desparate. I think the solution is to stop /dev/md3 and re-create /dev/md3 with the same values, but something is keeps /dev/md3 bussy and prevents me to do. Could someone please help me? Setup: - Hardware: Asrock µATX Bxxx(I forgot), Adaptec 8158Z raid controller with 4 x 3TB WD RED (2 new, 2 second hand and already replaced b'cos broken within waranty) -Software: XPenology DSM6.2.3 Proxmox6.3-3 Debian10 -Xpenology: Volume1 is 12GB and has the OS (i guess?), Volume2 is single unprotected 8TB ext4 and has all my shares. 4GB RAM and 2 cores. Output: see attachment output.txt
-
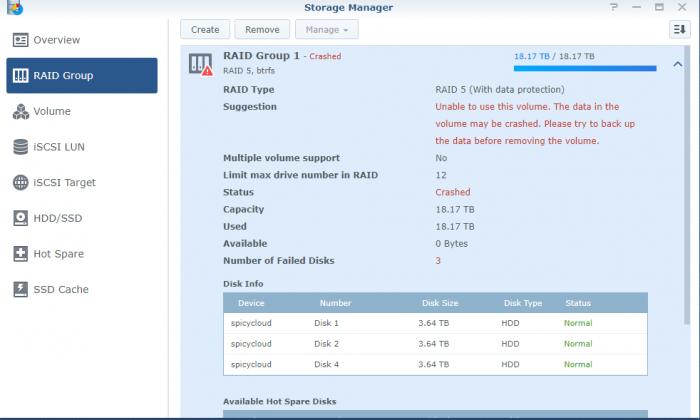
 Hi Team, I've been running 6.1 for the passed 12 months. I noticed an alert that drive 6 of my 6 drive RAID 5 was beginning to fail. I purchased another drive and replaced i t the other day and set it to expand into the raid group. Today i had an issue with an application so I rebooted the Synology. It didn't come back up. I now have a crash error with 3 of the six drives are stating they are failing. I noticed that the new drive had failed to initiate and 2 other drives have failed. Im now in a bad situation. I tried to place the old drive back in to see if it may be bale to reinstate the array but no luck. Am I out of luck here? Is it recoverable? I have about 100GB of data that really concerns me, and would love to recover if possible. The rest is not so important.
Hi Team, I've been running 6.1 for the passed 12 months. I noticed an alert that drive 6 of my 6 drive RAID 5 was beginning to fail. I purchased another drive and replaced i t the other day and set it to expand into the raid group. Today i had an issue with an application so I rebooted the Synology. It didn't come back up. I now have a crash error with 3 of the six drives are stating they are failing. I noticed that the new drive had failed to initiate and 2 other drives have failed. Im now in a bad situation. I tried to place the old drive back in to see if it may be bale to reinstate the array but no luck. Am I out of luck here? Is it recoverable? I have about 100GB of data that really concerns me, and would love to recover if possible. The rest is not so important.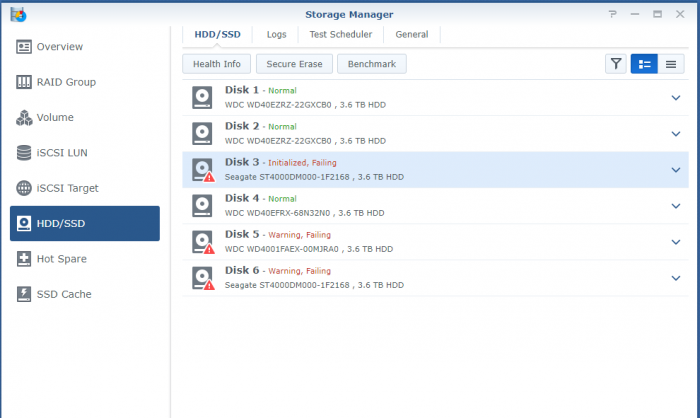
-
 Bonjour, Mon NAS est en version 3615XS en DSM 6.1.3 avec juns 1.02 alpha. J'ai un HDD de 4 TO (plein) que je souhaite récupérer... enfin j'espère pouvoir... Pas de raid car c'est avant un media center. J'avais crée les volume en "basic" je ne me souviens pas du type de système de fichier. Suite à une mésaventure avec ma clés usb, j'ai donc tenté de la recréée avec juns 1.02 b (j'ai pas trouvé la alpha) Avec le syno assistant, j'ai remarqué que le NAS avait changé d'ip, une fois connecté dessus il à travaillé durant 10 minutes pour "récupération".... Actuellement quand je me connecte j'ai le message suivant. Aie 😕 donc, DSM ne semble plus présent. Quoi faire ? Quelle procédure suivre pour accéder au données et les récupérer ? Merci d'avance pour vos réponses. Bonne soirée
Bonjour, Mon NAS est en version 3615XS en DSM 6.1.3 avec juns 1.02 alpha. J'ai un HDD de 4 TO (plein) que je souhaite récupérer... enfin j'espère pouvoir... Pas de raid car c'est avant un media center. J'avais crée les volume en "basic" je ne me souviens pas du type de système de fichier. Suite à une mésaventure avec ma clés usb, j'ai donc tenté de la recréée avec juns 1.02 b (j'ai pas trouvé la alpha) Avec le syno assistant, j'ai remarqué que le NAS avait changé d'ip, une fois connecté dessus il à travaillé durant 10 minutes pour "récupération".... Actuellement quand je me connecte j'ai le message suivant. Aie 😕 donc, DSM ne semble plus présent. Quoi faire ? Quelle procédure suivre pour accéder au données et les récupérer ? Merci d'avance pour vos réponses. Bonne soirée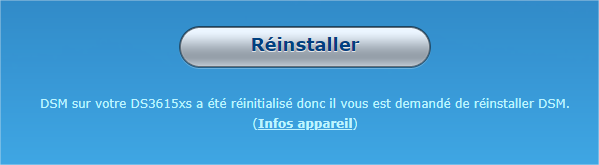
-
I been trying to troubleshoot my volume crash myself but I am at the end of my wits here. I am hoping someone can shine some light on to what my issue is and how to fix it. A couple weeks I started to receive email alerts stating, “Checksum mismatch on NAS. Please check Log Center for more details.” I hopped on my NAS WebUI and I did not really seem much in the logs. After checking my systems were still functioning properly and I could access my file, I figured something was wrong but was not a major issue…..how wrong I was. That brings us up until today, where I notice my NAS was only in read only mode. Which I thought was really odd. I tried logging into the WebUI but after I entered my username and password, I was not getting the NAS’s dashboard. I figured I would reboot the NAS, thinking it would fix the issue. I had problems with the WebUI being buggy in the past and a reboot seemed to always take care of it. But after the reboot I received the dreaded email, “Volume 1 (SHR, btrfs) on NAS has crashed”. I am unable to access the WebUI. But luckily, I have SSH enabled and logged on to the server and that’s where we are now. Some info about my system: 12 x 10TB Drives Synology 6.1.X as a DS3617xs 1 SSD Cache 24 GBs of RAM 1 x XEON CPU Here is the output of some of the commands I tried already: (Have to edit some of the outputs due to SPAM detection) Looks like the RAID comes up as md2. Seems to have the 12 drives active, not 100% sure Received an error when running the this command: GPT PMBR size mismatch (102399 != 60062499) will be corrected by w(rite). I think this might have to do something with the checksum errors I was getting before. When I try to interact with the LV it says it couldn't open file system. I tried to unmounted the LV and/or remount it, it gives me errors saying its not mounted, already mounted or busy. Can anyone comment on whether this is a possibility to recover the data? Am I going in the right direction? Any help would be greatly appreciated!
-

Sorry, the page you are looking for is not found - crash
CheapSk8 posted a question in General Questions
Hi all. Just installed Xpenology DS3617xs with Jun's 1.02b on Acer Revo RL85 (iCeleron 2957U@1.4GHz/4GB RAM/Realtek PCIe GBE lan/2x INTEL 250GB SSD) Everything is OK, running for couple of days, virtually 0 problems after installation. Decided to quickly backup settings, logged in - Control panel -> Update & Restore -> Configuration Backup. Few second after I clicked on backup and confirmed the standard dialog listing backed items of configuration the window returned back to the initial screen. I waited a few seconds, hoping the save dialog window will pop up... nothing. Next thing I click back and the screen refreshes and shows only a Synology logo and "Sorry, the page you are looking for is not found". From an older post here and searching around I know it happens to some Syno hardware users too. Something to do with Apache crashing. Unfortunately I have not enabled SSH, so can't really connect to my box anymore. Restart doesn't help, Synology assistant can't find the station. The only way I can see now is to boot linux pe, delete partitions, reinstall the whole thing... no data on it to care about, mostly barebone, so not a big deal, just wondering if someone has any experience with this.... Cheers! -

How to recover data from a crashed BTRFS drive? // Help request
geoprea1989 posted a question in General Questions
Hi guys, I decided to make a call for help as right now I'm stuck on recovering data from my BTRFS drive. I am using a hardware RAID 1 on the back-end [2x 4TB WD Red Drives], and on the front-end, on XPEnology I configured a Basic RAID Group with only "one drive" passed from ESXi. Until this January I've been using EXT file system, but I read that BTRFS is better both in speed and stability terms, so I decided to give it a go :) I run my system on UPS which can keep the system powered for more than 4 hours, in case of a blackout, so I though that my data was safe. Two weeks ago I decided to power off the system after 3 months of continual usage, just for checking that everything is okay and to clean it's inside for dust, as a normal routine check. Unfortunately, after I powered on my system, the main data drive from XPEnology was crashed, not even degraded. I rebooted it thinking that it might run a fsck by itself, but unfortunately it remained crashed. I ejected both drives from the system and ran extensive checks on them, both smart tests and surface checks, and everything looks just fine. Given these, I decided to eject one of the drives from the system and to connect it to an external docking station, in order to perform other troubleshooting. Unfortunately, seems that I'm unable to get it mounted, even as RO, with recovery parameters :( I have the drive connected to a live Parted Magic OS running, for troubleshooting and hope so, recovery procedures :) This is the output of some of the commands I issued, but with no luck to have it mounted: root@PartedMagic:~# btrfs version btrfs-progs v4.15 root@PartedMagic:~# cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath] md3 : active raid1 sda3[0] 3902163776 blocks super 1.2 [1/1] root@PartedMagic:~# lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT loop253 squashfs sr0 loop254 squashfs loop252 squashfs sda ├─sda2 linux_raid_member 7b661c20-ea68-b207-e8f5-bc45dd5a58c4 ├─sda3 linux_raid_member DISKSTATION:3 be150a49-a5a3-f915-32bf-80e4732a20ac │ └─md3 btrfs 2018.01.02-20:42:27 v15217 1457616f-5daf-4487-ba1c-07963a0c4723 └─sda1 linux_raid_member root@PartedMagic:~# btrfs fi show -d Label: '2018.01.02-20:42:27 v15217' uuid: 1457616f-5daf-4487-ba1c-07963a0c4723 Total devices 1 FS bytes used 2.15TiB devid 1 size 3.63TiB used 2.21TiB path /dev/md3 root@PartedMagic:~# mount -t btrfs -oro,degraded,recovery /dev/md3 /mnt/temp1 mount: wrong fs type, bad option, bad superblock on /dev/md3, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so. root@PartedMagic:~# dmesg | tail -n 100 [SNIP] [39026.756985] BTRFS info (device md3): allowing degraded mounts [39026.756988] BTRFS warning (device md3): 'recovery' is deprecated, use 'usebackuproot' instead [39026.756989] BTRFS info (device md3): trying to use backup root at mount time [39026.756990] BTRFS info (device md3): disk space caching is enabled [39026.756992] BTRFS info (device md3): has skinny extents [39027.082642] BTRFS error (device md3): bad tree block start 1917848902723122217 2473933062144 [39027.083051] BTRFS error (device md3): bad tree block start 5775457142092792234 2473933062144 [39027.083552] BTRFS error (device md3): bad tree block start 1917848902723122217 2473933062144 [39027.083936] BTRFS error (device md3): bad tree block start 5775457142092792234 2473933062144 [39027.097706] BTRFS error (device md3): bad tree block start 1917848902723122217 2473933062144 [39027.098146] BTRFS error (device md3): bad tree block start 5775457142092792234 2473933062144 [39027.114806] BTRFS error (device md3): bad tree block start 1917848902723122217 2473933062144 [39027.115410] BTRFS error (device md3): bad tree block start 5775457142092792234 2473933062144 [39027.133510] BTRFS error (device md3): bad tree block start 1917848902723122217 2473933062144 [39027.133941] BTRFS error (device md3): bad tree block start 5775457142092792234 2473933062144 [39027.136206] BTRFS error (device md3): open_ctree failed root@PartedMagic:~# btrfsck /dev/md3 checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found E41F2C90 wanted 90ED32B2 checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A bytenr mismatch, want=2473933062144, have=1917848902723122217 Couldn't setup device tree ERROR: cannot open file system root@PartedMagic:~# btrfs check --repair /dev/md3 enabling repair mode checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found E41F2C90 wanted 90ED32B2 checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A bytenr mismatch, want=2473933062144, have=1917848902723122217 Couldn't setup device tree ERROR: cannot open file system root@PartedMagic:~# btrfs restore -v -i /dev/md3 /mnt/temp1 checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found E41F2C90 wanted 90ED32B2 checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A bytenr mismatch, want=2473933062144, have=1917848902723122217 Couldn't setup device tree Could not open root, trying backup super checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found E41F2C90 wanted 90ED32B2 checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A bytenr mismatch, want=2473933062144, have=1917848902723122217 Couldn't setup device tree Could not open root, trying backup super checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A checksum verify failed on 2473933062144 found E41F2C90 wanted 90ED32B2 checksum verify failed on 2473933062144 found 908A6889 wanted 1646EB1A bytenr mismatch, want=2473933062144, have=1917848902723122217 Couldn't setup device tree Could not open root, trying backup super root@PartedMagic:~# btrfs rescue super-recover -v /dev/md3 All Devices: Device: id = 1, name = /dev/md3 Before Recovering: [All good supers]: device name = /dev/md3 superblock bytenr = 65536 device name = /dev/md3 superblock bytenr = 67108864 device name = /dev/md3 superblock bytenr = 274877906944 [All bad supers]: All supers are valid, no need to recover root@PartedMagic:~# smartctl -a /dev/sda | grep PASSED SMART overall-health self-assessment test result: PASSED root@PartedMagic:~# btrfs inspect-internal dump-super /dev/md3 superblock: bytenr=65536, device=/dev/md3 --------------------------------------------------------- csum_type 0 (crc32c) csum_size 4 csum 0x91d56f51 [match] bytenr 65536 flags 0x1 ( WRITTEN ) magic _BHRfS_M [match] fsid 1457616f-5daf-4487-ba1c-07963a0c4723 label 2018.01.02-20:42:27 v15217 generation 31802 root 2473938698240 sys_array_size 129 chunk_root_generation 30230 root_level 1 chunk_root 20987904 chunk_root_level 1 log_root 0 log_root_transid 0 log_root_level 0 total_bytes 3995815706624 bytes_used 2366072147968 sectorsize 4096 nodesize 16384 leafsize (deprecated) 16384 stripesize 4096 root_dir 6 num_devices 1 compat_flags 0x0 compat_ro_flags 0x0 incompat_flags 0x16b ( MIXED_BACKREF | DEFAULT_SUBVOL | COMPRESS_LZO | BIG_METADATA | EXTENDED_IREF | SKINNY_METADATA ) cache_generation 22402 uuid_tree_generation 31802 dev_item.uuid 8c0579fe-b94c-465a-8005-c55991b8727e dev_item.fsid 1457616f-5daf-4487-ba1c-07963a0c4723 [match] dev_item.type 0 dev_item.total_bytes 3995815706624 dev_item.bytes_used 2428820783104 dev_item.io_align 4096 dev_item.io_width 4096 dev_item.sector_size 4096 dev_item.devid 1 dev_item.dev_group 0 dev_item.seek_speed 0 dev_item.bandwidth 0 dev_item.generation 0 Given these, do you have any other idea that I should apply to get my data recovered? In case you need the output of other troubleshooting commands, please, just let me know, and I will post them here. Thank you in advance for your tips and help! :) -
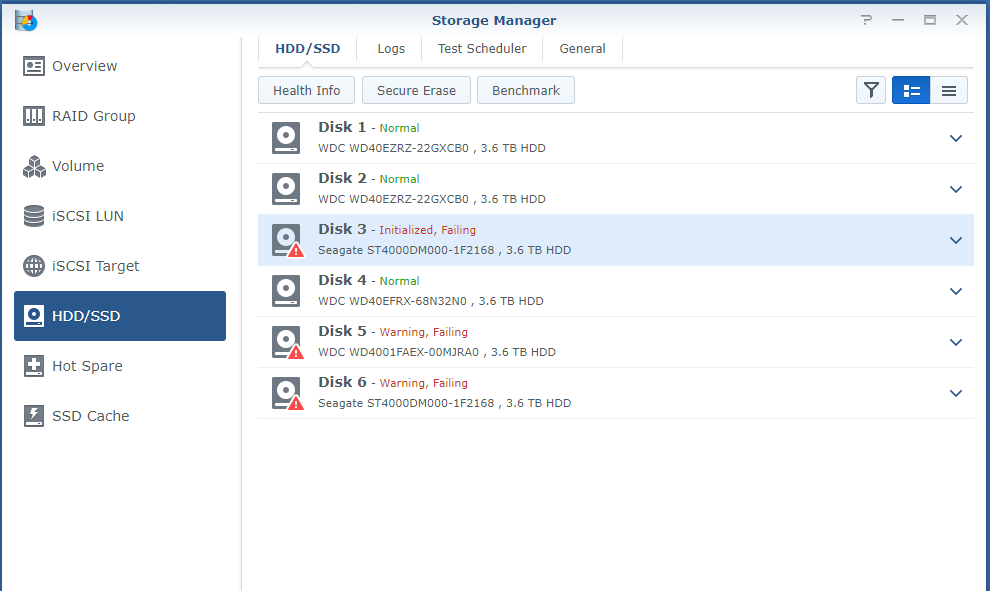
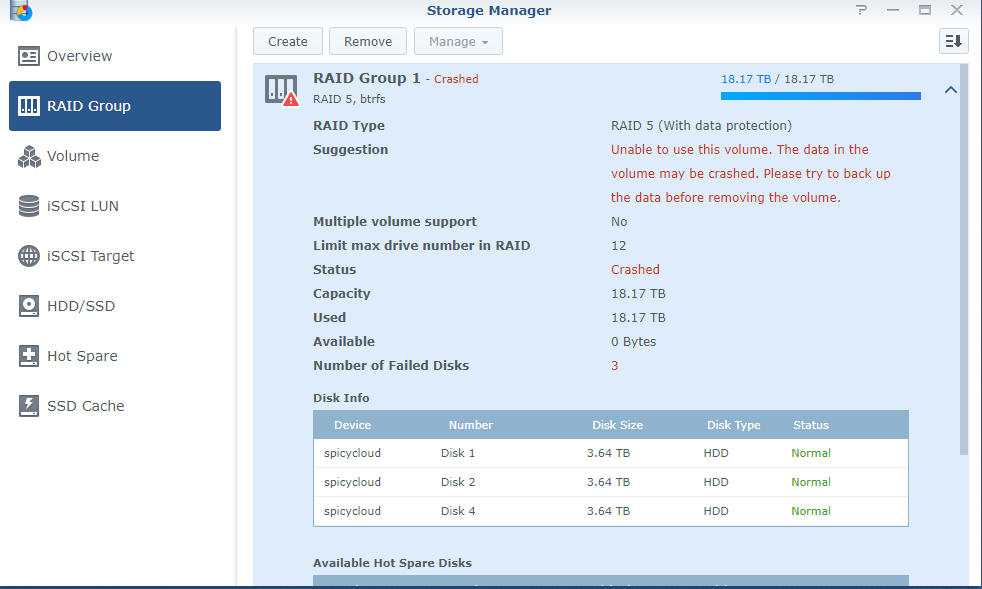
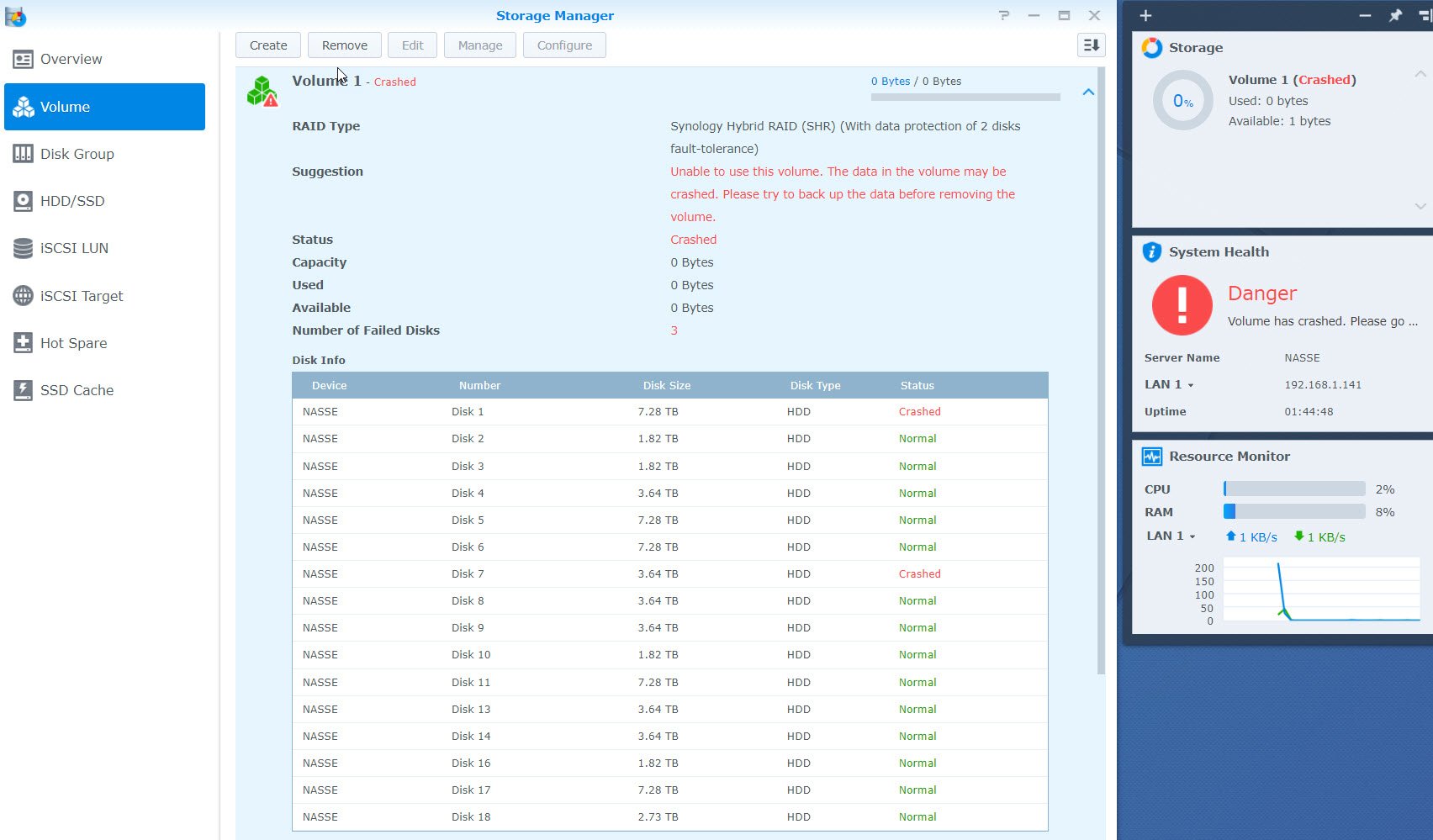
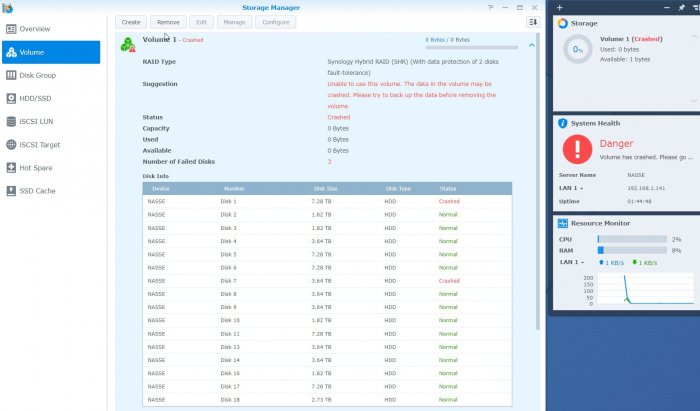
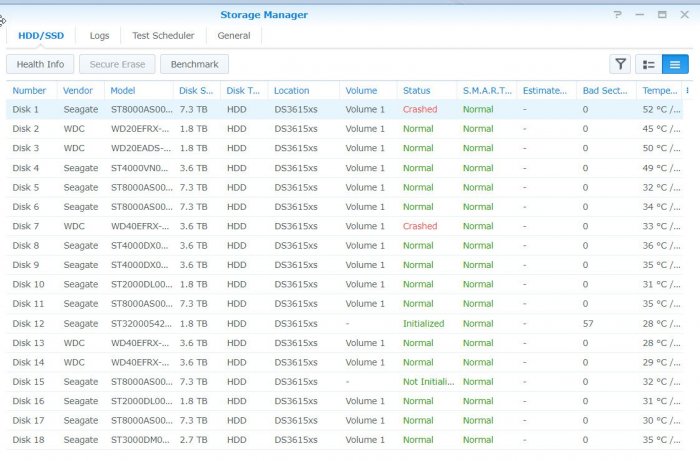
Hi all! SHR-2 Crashed 3 failed HDD, please help, only 2 disks report crashed in red color but I have still 2 disks initiated but I can't use "Manage" button to repair. I have SHR-2 with 2 failing disk but I see that I got 3 disks with problems..... How can I get back my data. in Putty the MD2 seems quiet ok I just need 80-90% of the data back because is so much. I need someone that knows this in detail and ask also for more data if needed from me. It seems that I need assistance due to mange button can't be used (it greyed) even I have 2 disks available for mending the volume. Anyway I need help to fix the volume. It seems that \md2 is the raid that has the info back as I need. Check the picture. I need one more disk up and running to get the volume intact again. That is the help I need. https://unsee.cc/b006d547/ root@NASSE:/usr# cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1] md2 : active raid6 sdk5[0] sdg5[21] sdj5[16] sdi5[15] sdb5[20] sdf5[18] sdd5[11] sdc5[10] sdh5[22] sda5[8] sdr5[7] sdq5[23] sdp5[4] sde5[24] sdm5[2] 31178806272 blocks super 1.2 level 6, 64k chunk, algorithm 2 [18/15] [U_UUUU_UUUUU_UUUUU] Please reply fast but with accurate information.
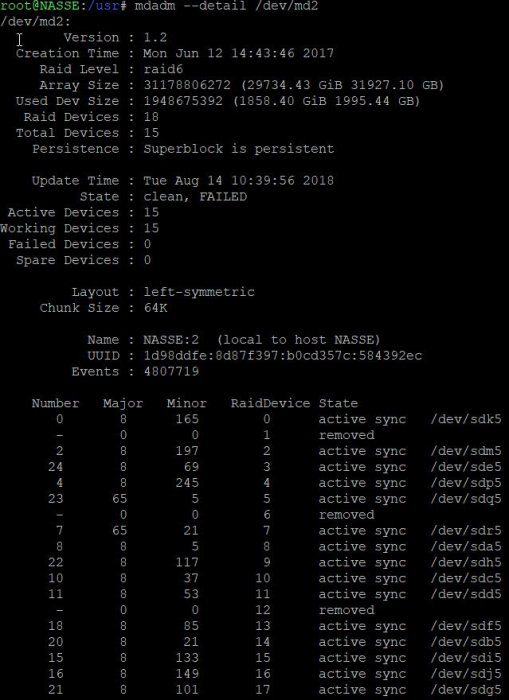
-
Hi everyone! Recently I updated from 5.2 to 6.1 (6.1.5 at the moment). I've been using XPEnology on DSM 5.2 for about a year and a half. The update went fine, except that now I have a strange problem. When I use any of the services, the router crashes and restarts. This happens with Plex, Transmission, and Nextcloud (Docker). There is no problem until any of these services are used intensively. For example I can leave transmission running without problems until I add a torrent, which in around 30 seconds make the router crash. Same for Plex and Nextcloud. This could mean that the router cannot handle too many connection, or that probably there are some packets that are bounced back and fort between router and server, overloading the network. I tried to understand what was happening using tcpdump, but I was not able to find much. In 3 minutes, tcpdump logged about 800'000 packets. I don't actually know if this i normal or too much. I could post a link for the tcpdump, if anyone has more experience with this than I have. The router is not faulty, since I already made my internet provider replace it for a new one. Same problem as before. The router is a personalized version (UPC Switzerland) of the Touchstone TG2492. I've been having this problem for about two weeks now and before trying to reinstall everything from scratches I wanted to the community. Also because I have no idea where to put the 7TB of data that I have on the NAS. Thank you!
-
Hello, running DSM 6.1 (jun's loader) on Asus A88X-Plus/USB 3.1 with AMD A series A10-7860K CPU, 8 Gb RAM and expanded from 8 disks to 10, system is configured as RAID 6. As the motherboard natively only supports 8 disks I added a PCI-E sata controller Highpoint Rocket 640L. I added the 2 disks to the external sata controller. The system appears to have succesfully switched from 8 to 10 disks, but never fully worked,as the system partition appears to be faulty of the 2 added disks. Re-installing DSM did not work either, everything ok until I get a timeout when writing the config files (using network cable, not wireless). The 2 new disks are kicked out for some reason and my system falls down from 10 disk to 8 (RAID 6, so this is critical). After a reboot they are visible again, I can add them and parity check runs but ultimately fails (data ok/system partition fails). Yet the drives don't contain any errors, from extended disk checks from both synology as well as other disk checking software. At this moment the x-th parity check is running after adding the disks again but I fear that this will be yet a futile attempt. What could be wrong ? Is the external sata controller not supported ? Other ideas ? Any tricks I can do to "force" a correct and full system partition re-installation ? Many thanks ! Kind regards, Cooled Spirit.
-
Hi everyone My hardware: AMD E450M1-deluxe OS: 6.1.3 Update 8 loader 1.02b My problem DS finder, DS file, DS download .... always crash out when I login with ip-lan or ddns. The only DS photo and DS cloud app is no proplem At first I used "loader 1.01 DSM 6.0.2 update 6" cant login the app, i tried up loader 1.02b 6.1.3 update 8 but alway crash If I must to new install , can I keep the data, my NAS is not raid sorry i use google translate.
-
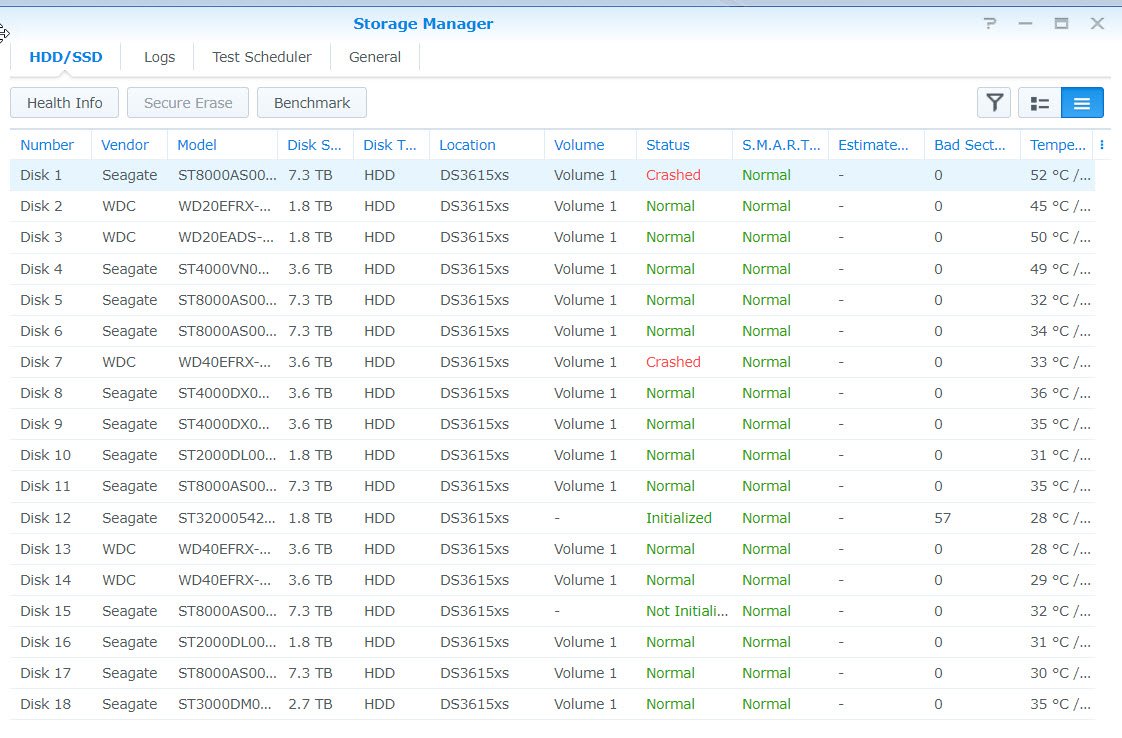
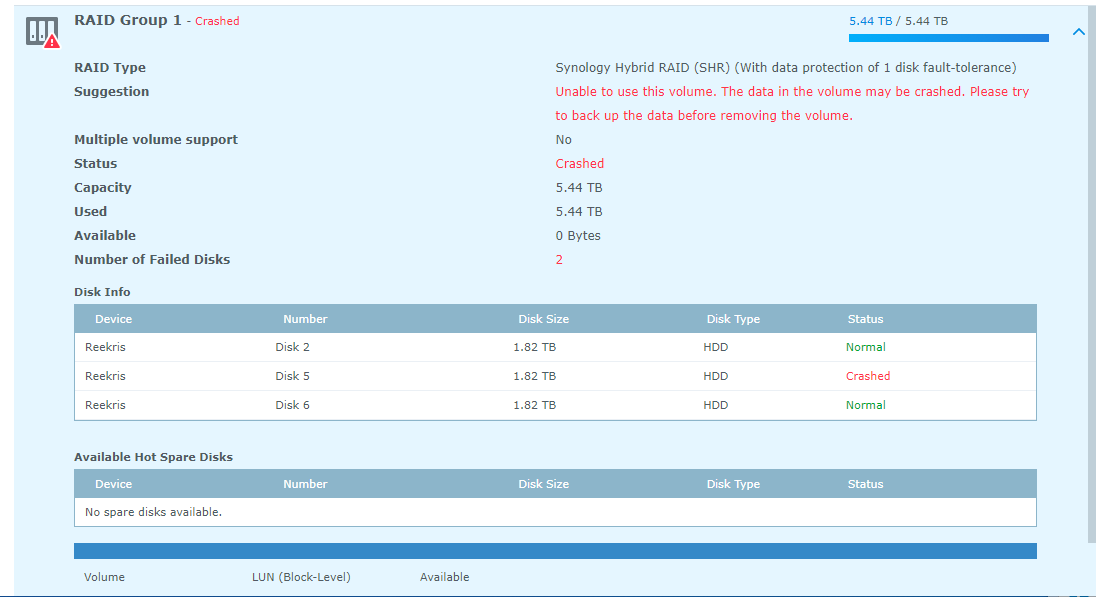
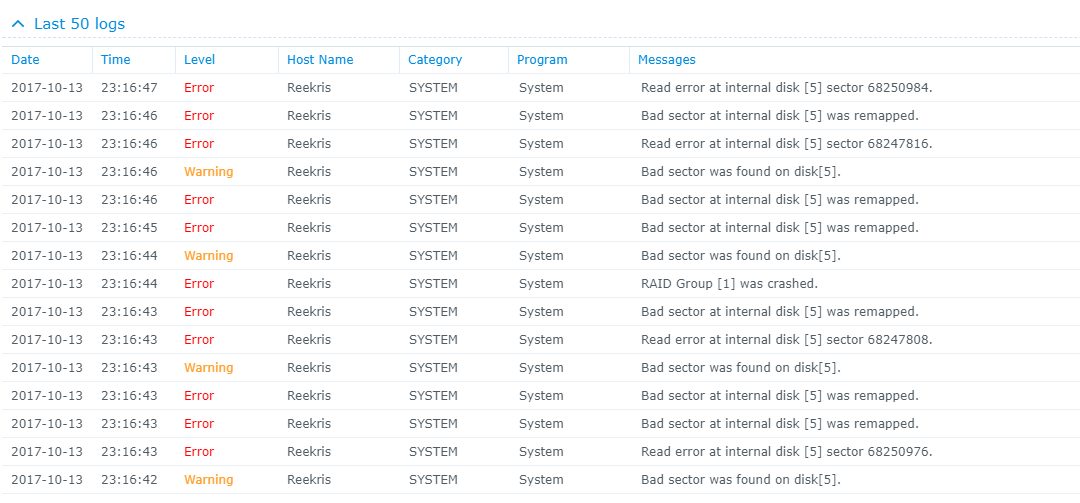
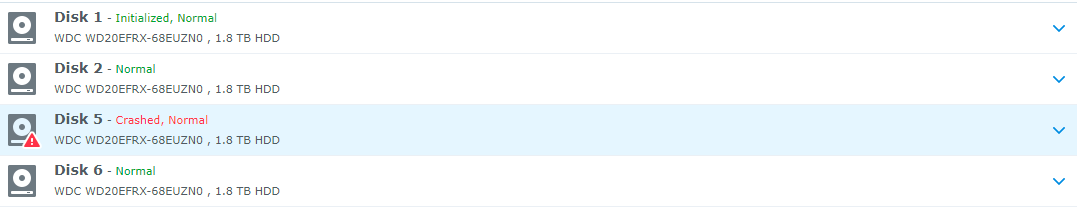
Alright, strap yourselves in, because this might get long... Hardware setup: 4x WD 2TB Red in SHR ASRock H81M-HDS Mobo Intel Celeron Processor 8GB Crucial Ballistix RAM First, some background: A few days ago I noted the network drives that I have on my system were not showing up in Windows so I navigated to the system via my browser and the system told me I needed to install an update and that my drives were from an old system and would need migration. I wrote a different post about that here: The versions it wanted to install was the same version (or slightly higher) of 5.2 so I thought nothing of it and agreed to let the system update. It went through the install smoothly, but never rebooted. Eventually I was able to navigate back to the web browser and it told me I now had 5.2 firmware, but 6.1-15152 DSM. I am still unclear how this install happened, but I assume that it downloaded it automatically from the internet even though I had enabled the "only install security patches" option. As I posted in the Tutorial forum a few posts after the linked one, I was able to get Jun's loader installed and boot into 6.1-15152 and I thought all was well. However, when I booted into the DSM, I was in a world of hurt. I have one bad disk in the array clearly that lists bad sectors, but that's the point of the SHR array right? Well I let the RAID start to repair itself and always around 1.5% into the repair it crashes and tells me the System Volume has crashed. However, you'll notice in the Disk Info Section there are only 3 disks. Looking into the logs show that Disk 5 (the bad one) failed at trying to correct bad sectors: However, when this happens Disk 1 (AFAIK, perfectly fine drive) switched into Initialized, Normal but drops out of the RAID array and then it goes into crash mode. I don't understand the relationship between Disk 5 crashing out when repairing the RAID and Disk 1 disappearing. It stands to reason that if Disk 1 is fine, which is seems to be that it would just fail and stay in degraded mode until I can swap in a new drive. I have tried starting the system with Disk 5 unplugged, but that does no good. I have also begun playing around with attempts at data recovery in a LiveUSB of Ububntu using some of Synology's guides as well as just googling around. So I suppose I have a few questions. 1. Does anyone know of a relationship between possibly installing the new system, and the bad disk causing the good disk to crash? 2. How likely is it that Disk 1 (AFAIK good disk) is also toast. 3. Do you have any tips for recovering data from a situation like this? I would greatly appreciate any help or advice you can provide. I have been banging my head against a wall for 3 nights working on this. I have all the really important stuff backed up to the cloud so it is not a matter of life and death (5 year, 10000 photos) but there is a lot of other media that I am willing to do a lot to not replace or only replace some of.
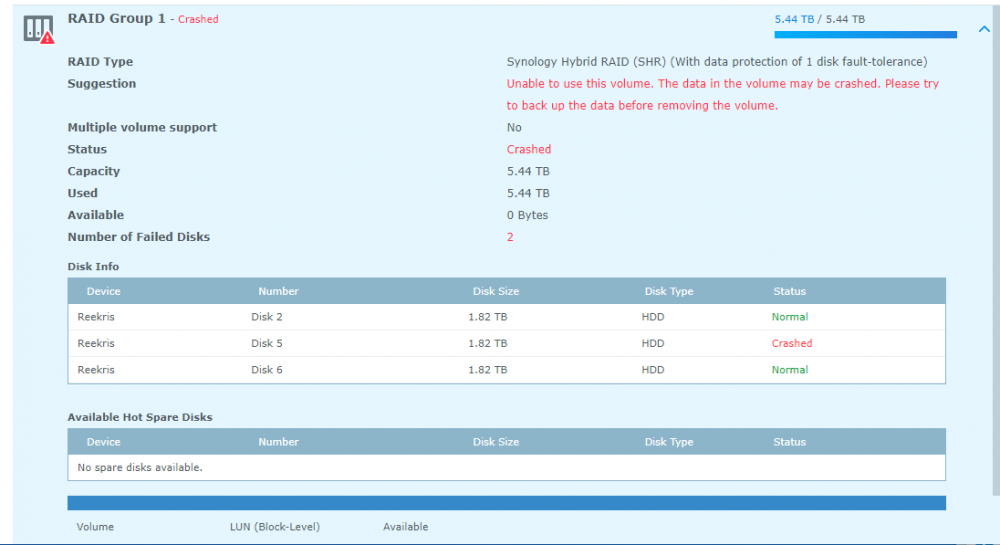
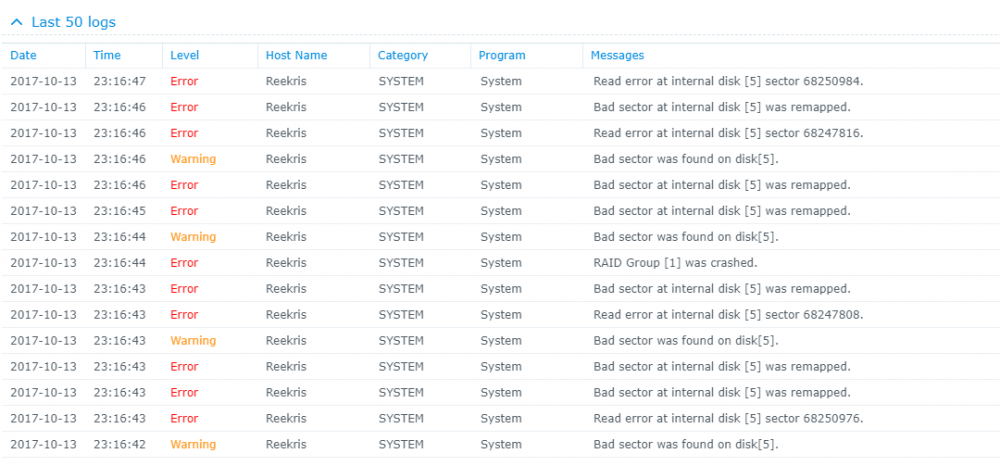
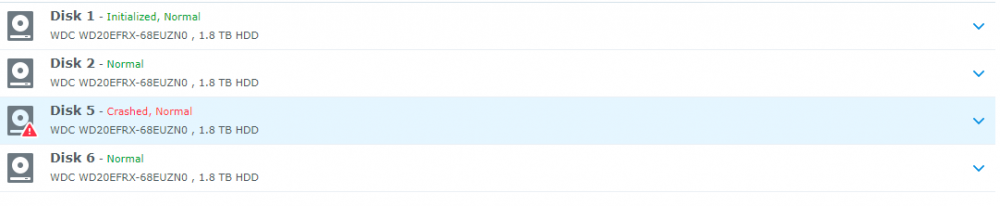
-
 Hi, I updated to DSM 6 using Jun's loader. Shortly after, I tried to add another HDD to my NAS. DSM wasn't recognizing the HDD, so I powered it off and used the SATA cables from one of the working drives to ensure it wasn't the cables. This is where everything went wrong. When DSM booted up, I saw the drive I needed, but DSM gave an error of course. After powering the unit off and swapping the cables back, it still said it needed repair, so I pressed repair in Storage Manager. Everything seemed fine. After another reboot, it said it had crashed. I let the parity check run overnight and now the RAID is running healthy as well as each individual disk, but the Volume has crashed. It's running SHR-1. I believe the mdstat results below show that it can be recovered without data loss, but I'm not sure where to go from here? Another thread added the removed '/dev/sdf2' back into active sync, but I'm not sure which letters are assigned where. /proc/mdstat/ admin@DiskStationNAS:/usr$ cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] md3 : active raid1 sdc6[0] sdd6[1] 976742784 blocks super 1.2 [2/2] [UU] md2 : active raid5 sde5[0] sdd5[3] sdf5[2] sdc5[1] 8776305792 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU] md1 : active raid1 sdc2[1] sdd2[2] sde2[0] sdf2[3] 2097088 blocks [12/4] [UUUU________] md0 : active raid1 sdc1[0] sdd1[1] sde1[2] sdf1[3] 2490176 blocks [12/4] [UUUU________] unused devices: <none> admin@DiskStationNAS:/usr$ mdadm --detail /dev/md2 mdadm: must be super-user to perform this action admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md2 Password: /dev/md2: Version : 1.2 Creation Time : Sat Aug 29 05:40:53 2015 Raid Level : raid5 Array Size : 8776305792 (8369.74 GiB 8986.94 GB) Used Dev Size : 2925435264 (2789.91 GiB 2995.65 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Sun Aug 27 09:38:44 2017 State : clean Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 Layout : left-symmetric Chunk Size : 64K Name : DiskStationNAS:2 (local to host DiskStationNAS) UUID : d97694ec:e0cb31e2:f22b36f2:86cfd4eb Events : 17027 Number Major Minor RaidDevice State 0 8 69 0 active sync /dev/sde5 1 8 37 1 active sync /dev/sdc5 2 8 85 2 active sync /dev/sdf5 3 8 53 3 active sync /dev/sdd5 admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md3 /dev/md3: Version : 1.2 Creation Time : Thu Jun 8 22:33:42 2017 Raid Level : raid1 Array Size : 976742784 (931.49 GiB 1000.18 GB) Used Dev Size : 976742784 (931.49 GiB 1000.18 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Sun Aug 27 00:07:01 2017 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Name : DiskStationNAS:3 (local to host DiskStationNAS) UUID : 4976db98:081bd234:e07be759:a005082b Events : 2 Number Major Minor RaidDevice State 0 8 38 0 active sync /dev/sdc6 1 8 54 1 active sync /dev/sdd6 admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md1 /dev/md1: Version : 0.90 Creation Time : Sun Aug 27 00:10:09 2017 Raid Level : raid1 Array Size : 2097088 (2048.28 MiB 2147.42 MB) Used Dev Size : 2097088 (2048.28 MiB 2147.42 MB) Raid Devices : 12 Total Devices : 4 Preferred Minor : 1 Persistence : Superblock is persistent Update Time : Sun Aug 27 09:38:38 2017 State : clean, degraded Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 UUID : a56a9bcf:e721db67:060f5afc:c3279ded (local to host DiskStationNAS) Events : 0.44 Number Major Minor RaidDevice State 0 8 66 0 active sync /dev/sde2 1 8 34 1 active sync /dev/sdc2 2 8 50 2 active sync /dev/sdd2 3 8 82 3 active sync /dev/sdf2 4 0 0 4 removed 5 0 0 5 removed 6 0 0 6 removed 7 0 0 7 removed 8 0 0 8 removed 9 0 0 9 removed 10 0 0 10 removed 11 0 0 11 removed admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md0 /dev/md0: Version : 0.90 Creation Time : Fri Dec 31 17:00:25 1999 Raid Level : raid1 Array Size : 2490176 (2.37 GiB 2.55 GB) Used Dev Size : 2490176 (2.37 GiB 2.55 GB) Raid Devices : 12 Total Devices : 4 Preferred Minor : 0 Persistence : Superblock is persistent Update Time : Sun Aug 27 10:28:58 2017 State : clean, degraded Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 UUID : 147ea3ff:bddf1774:3017a5a8:c86610be Events : 0.9139 Number Major Minor RaidDevice State 0 8 33 0 active sync /dev/sdc1 1 8 49 1 active sync /dev/sdd1 2 8 65 2 active sync /dev/sde1 3 8 81 3 active sync /dev/sdf1 4 0 0 4 removed 5 0 0 5 removed 6 0 0 6 removed 7 0 0 7 removed 8 0 0 8 removed 9 0 0 9 removed 10 0 0 10 removed 11 0 0 11 removed Hide
Hi, I updated to DSM 6 using Jun's loader. Shortly after, I tried to add another HDD to my NAS. DSM wasn't recognizing the HDD, so I powered it off and used the SATA cables from one of the working drives to ensure it wasn't the cables. This is where everything went wrong. When DSM booted up, I saw the drive I needed, but DSM gave an error of course. After powering the unit off and swapping the cables back, it still said it needed repair, so I pressed repair in Storage Manager. Everything seemed fine. After another reboot, it said it had crashed. I let the parity check run overnight and now the RAID is running healthy as well as each individual disk, but the Volume has crashed. It's running SHR-1. I believe the mdstat results below show that it can be recovered without data loss, but I'm not sure where to go from here? Another thread added the removed '/dev/sdf2' back into active sync, but I'm not sure which letters are assigned where. /proc/mdstat/ admin@DiskStationNAS:/usr$ cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] md3 : active raid1 sdc6[0] sdd6[1] 976742784 blocks super 1.2 [2/2] [UU] md2 : active raid5 sde5[0] sdd5[3] sdf5[2] sdc5[1] 8776305792 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU] md1 : active raid1 sdc2[1] sdd2[2] sde2[0] sdf2[3] 2097088 blocks [12/4] [UUUU________] md0 : active raid1 sdc1[0] sdd1[1] sde1[2] sdf1[3] 2490176 blocks [12/4] [UUUU________] unused devices: <none> admin@DiskStationNAS:/usr$ mdadm --detail /dev/md2 mdadm: must be super-user to perform this action admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md2 Password: /dev/md2: Version : 1.2 Creation Time : Sat Aug 29 05:40:53 2015 Raid Level : raid5 Array Size : 8776305792 (8369.74 GiB 8986.94 GB) Used Dev Size : 2925435264 (2789.91 GiB 2995.65 GB) Raid Devices : 4 Total Devices : 4 Persistence : Superblock is persistent Update Time : Sun Aug 27 09:38:44 2017 State : clean Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 Layout : left-symmetric Chunk Size : 64K Name : DiskStationNAS:2 (local to host DiskStationNAS) UUID : d97694ec:e0cb31e2:f22b36f2:86cfd4eb Events : 17027 Number Major Minor RaidDevice State 0 8 69 0 active sync /dev/sde5 1 8 37 1 active sync /dev/sdc5 2 8 85 2 active sync /dev/sdf5 3 8 53 3 active sync /dev/sdd5 admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md3 /dev/md3: Version : 1.2 Creation Time : Thu Jun 8 22:33:42 2017 Raid Level : raid1 Array Size : 976742784 (931.49 GiB 1000.18 GB) Used Dev Size : 976742784 (931.49 GiB 1000.18 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Sun Aug 27 00:07:01 2017 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Name : DiskStationNAS:3 (local to host DiskStationNAS) UUID : 4976db98:081bd234:e07be759:a005082b Events : 2 Number Major Minor RaidDevice State 0 8 38 0 active sync /dev/sdc6 1 8 54 1 active sync /dev/sdd6 admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md1 /dev/md1: Version : 0.90 Creation Time : Sun Aug 27 00:10:09 2017 Raid Level : raid1 Array Size : 2097088 (2048.28 MiB 2147.42 MB) Used Dev Size : 2097088 (2048.28 MiB 2147.42 MB) Raid Devices : 12 Total Devices : 4 Preferred Minor : 1 Persistence : Superblock is persistent Update Time : Sun Aug 27 09:38:38 2017 State : clean, degraded Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 UUID : a56a9bcf:e721db67:060f5afc:c3279ded (local to host DiskStationNAS) Events : 0.44 Number Major Minor RaidDevice State 0 8 66 0 active sync /dev/sde2 1 8 34 1 active sync /dev/sdc2 2 8 50 2 active sync /dev/sdd2 3 8 82 3 active sync /dev/sdf2 4 0 0 4 removed 5 0 0 5 removed 6 0 0 6 removed 7 0 0 7 removed 8 0 0 8 removed 9 0 0 9 removed 10 0 0 10 removed 11 0 0 11 removed admin@DiskStationNAS:/usr$ sudo mdadm --detail /dev/md0 /dev/md0: Version : 0.90 Creation Time : Fri Dec 31 17:00:25 1999 Raid Level : raid1 Array Size : 2490176 (2.37 GiB 2.55 GB) Used Dev Size : 2490176 (2.37 GiB 2.55 GB) Raid Devices : 12 Total Devices : 4 Preferred Minor : 0 Persistence : Superblock is persistent Update Time : Sun Aug 27 10:28:58 2017 State : clean, degraded Active Devices : 4 Working Devices : 4 Failed Devices : 0 Spare Devices : 0 UUID : 147ea3ff:bddf1774:3017a5a8:c86610be Events : 0.9139 Number Major Minor RaidDevice State 0 8 33 0 active sync /dev/sdc1 1 8 49 1 active sync /dev/sdd1 2 8 65 2 active sync /dev/sde1 3 8 81 3 active sync /dev/sdf1 4 0 0 4 removed 5 0 0 5 removed 6 0 0 6 removed 7 0 0 7 removed 8 0 0 8 removed 9 0 0 9 removed 10 0 0 10 removed 11 0 0 11 removed Hide -
I've had a mixture of WD Red drives in a Syno DS410 and an Intel SSE4200 enclosure running Xpenology for years with very few drive issues. Recently I thought I'd repurpose an Intel box I'd built a few years ago but was just sitting there (CPU/RAM/MOBO) and successfully set it up with 4x3TB WD Red drives running Xpenology. When given the choice, I chose to create a btrfs RAID 5 volume. But. In the 5 or so months I've been running this NAS, three drives have crashed and started reporting a bunch of bad sectors. These drives have less than 1000 hours on them, practically new. Fortunately they are under warranty at some level. But, still, wondering, could this be btrfs? I'm no file system expert. Light research suggests that while btrfs has been around for several years and of course is a supported option in Synology, some feel it isn't ready for prime time. I'm at a loss to explain why 3 WD Red drives with less than 1000 hours on them manufactured on different dates are failing so catastrophically. I understand btrfs and bad sectors are not really in the same problem zone; software shouldn't be able to cause hardware faults. I considered heat but these drives are rated at 65 celsius and they are not going above 38 or so. If it matters, when drives fail, the drive always reports problems at boot up; in fact, as the volume is now degraded with the loss of yet another drive I'm just not turning the system off until I get a new drive in there; one of the remaining drives reported failure to start up properly in the past week. Final consideration I have is that this is a build-a-box using a Gigabyte motherboard and 4 drives on the SATA bus in AHCI mode. Some sort of random hardware issue in this system could possibly be causing bad sectors to be reported on the drives?? Seems unlikely. Has anyone ever heard of SynologyOS reporting bad sectors when there weren't actually bad sectors? Anyone have any thoughts on this? Should I go back to ext4? This is mainly a plex media server.