satdream
-
Posts
98 -
Joined
-
Last visited
-
Days Won
2
Everything posted by satdream
-
Have a look here (Satdream 3.5" Western Digital) I compiled (and maintain up to date) overall Western Digital HDD, with each certified core product (eg. cad US7SAP) and different branding reuse, the 3.3v pin is Power Disable function of SATA 3.2+ and next release, and only on limited models (and not all in the same capacity !), check the line 3.3v pin issue. Btw, the 3.3v is not affecting most of NAS or microserver etc. as not cabled, but if any issue, alternative to kapton is simply a Molex/SATA supply changer ... Personnaly I have 6x 14TB + 6x 12TB in HP microserver Gen 8 with extension SAS card with disks in a rack ... working perfectly ! Same available for Toshiba and Seagate ... 3.5" Synthesis
-
Au moins sur la hardcopy: Cloud Station Sharesync n'est plus maintenu, il est très avantageusement remplacé par Synology Drive Share Sync qui fonctionne parfaitement pour faire la synchro entre NAS etc. et ce sans besoin d'un ID quickconnect
-
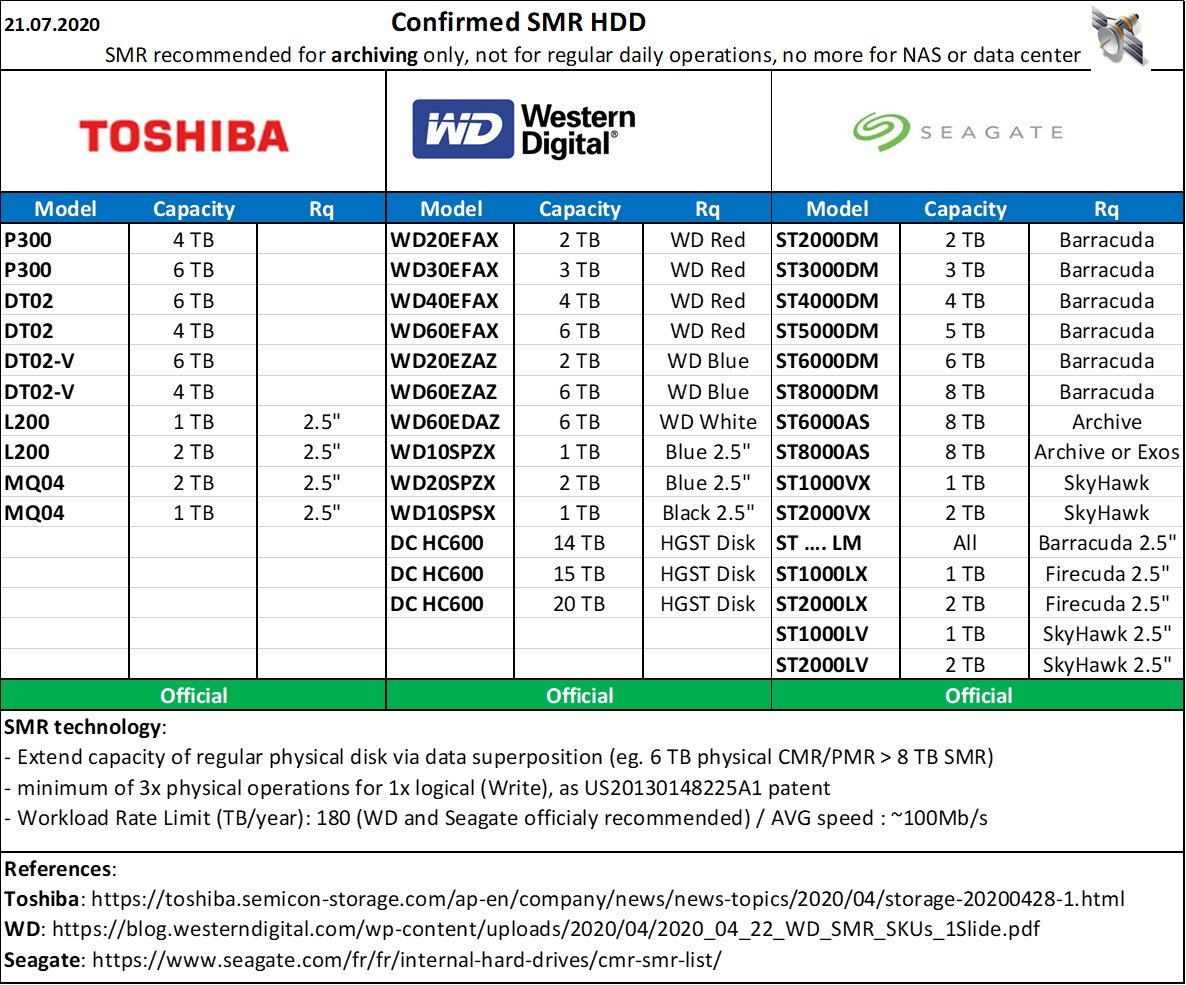
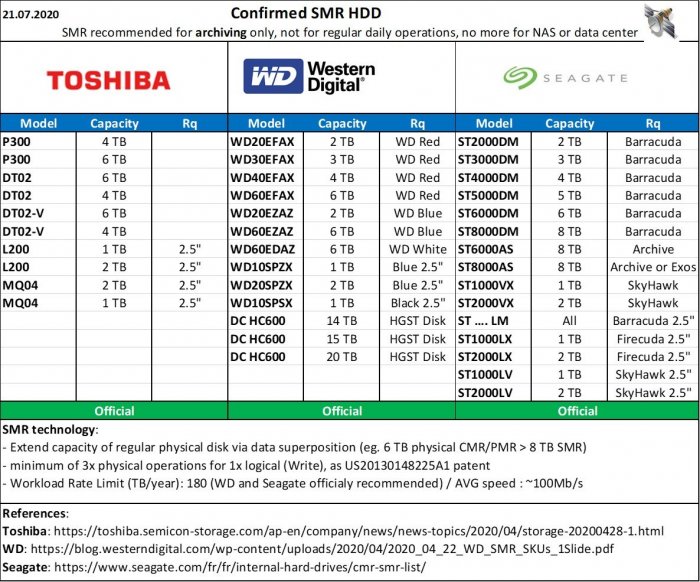
Hi All, my small contrib here vs. the huge work of @June and other developers with Xpenology (and also the amazing work of @IG-88 with drivers/compiled moduled).. Following long work performed analyzing service manuals, OEM documents, but also mainly the certification requests to authorities (that lists the branding or the sub-version of each physical disk), here is the synthesis of current disks by manufactuer; published also on RedIt and French forums, free to share/reuse keeping the small (c) marking. Hope this help ! Satdream. 3.5" HDD Seagate Toshiba Western Digital w/specific White models (extractable from external case) + identified downgraded ones Western Digital HDD Code decrypter 2.5" HDD (All manufacturers) 3.5" & 2.5" SMR recall (All manufacturers)
-
SMR official lists
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: DSM 6.2.2-24922 Update 4 - Loader version and model: JUN'S LOADER v1.03b - DS3617xs - Using custom extra.lzma: Yes - Installation type: BAREMETAL - HP Microserver Gen8 - Additional comments: 1) Manual Update 2) Once update finished, the Gen8 start to reboot automatically = switch off quickly (during the "long" boot test process of the Gen8=without issue) 3) Update extra.lzma (simple copy/paste under W10) on the SDCard from which the Gen8 boot 4) Boot Gen8 with updated SDCard => no issue with integrated NiC, the Gen8 is fine visible on network ! 5) Log via SSH then update /etc.default/synoinfo.conf if specific (eg. more HDDs etc.) the update reseted values, supposed to be restored to - esataportcfg to 0x00000 (instead default 0xff000), - usbportcfg to 0x7C000 (instead default 0x300000) = 5 USB on the Gen8 - internalportcfg to 0xFFFFFF (instead of default 0xfff) = 21 Disks support in my case
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: DSM 6.2.3-25426 - Loader version and model: JUN'S LOADER v1.03b - DS3617xs - Using custom extra.lzma: Yes - Installation type: BAREMETAL - HP Microserver Gen8 - Additional comments: REBOOT REQUIRED -- Manual Update + update /etc.default/synoinfo.conf if specific (eg. more HDDs etc.) The update reseted values, supposed to be restored to - esataportcfg to 0x00000 (instead default 0xff000), - usbportcfg to 0x7C000 (instead default 0x300000) = 5 USB on the Gen8 - internalportcfg to 0xFFFFFF (instead of default 0xfff) = 21 Disks support in my case
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: Disks migration from DS3615xs/6.1.2/loader 1.02b - Loader version and model: JUN'S LOADER v1.03b - DS3617xs - Using custom extra.lzma: YES - Installation type: BAREMETAL - HP Gen8 Micro 12Gb i5 3470T - New install - Dell H310 w/LSI 9211-8i P20 IT Mode + extension Rack of SAS/SATA mixed HDD - Additional comments: Gen8 onboard Dual Broadcom NiC working (no need of additionnal NiC thanks to native drivers from IG-88)
-
Done tests with fresh install: confirm that IronWolf is working fine in a new fresh install in mixed SAS/SATA environment, but then tried migration and same issue ... Ironwolf support from DSM 6.2.2 24922 update 4 have a bug ... disk is put out of the pool as in default even if status is normal ... Close topic/my contribution, and thanks again to all you sending me suggestions (and private message), and especially to @flyride ! FINISH
-
Got finally pool working and all status at Normal removing IronWolf, then replacing it, and adding another disk too, after long (long) resync. now config is full working w/DSM 6.2.2-24922 Update 4 ... But IronWolf is really an issue, will made other tests (not with my data, but fake config ) in order to try to understand, but for the moment I have to reconfigure all data accesses etc. Thanks all for support !
-
Resync finalized with the new WD 12TB, extracted the 10TB IronWolf = all data available ... resync successfull ... But the pool is still failed ... then removed the unused 5TB Toshiba (from the beginning of issues I do not understand why this HDD was status changed to initalized in DSM assuming the Raid manager consider it as Ok in the Raid volume), as DSM asking for a 8TB minimum disk, I plugged a new 8TB Seagate NAS HDD version ... Resync initated, 8h prevision ... for the 1st round ... Rq: the resync duration predication is a bit unprecised, and do not consider that 2x resync are requested, but only the on-going one : but MD3 then MD2 shall be resync (SHR consider MD0/MD1 as system partition duplicated on all disks, data are on MD2/MD3 and parity error correction on MD4/MD5, btw the high volume to sync is on MD3 and MD2, why DSM shows 2x consecutive reparing/resync actions but is not able to give the cumulated duration eval).
-
I run a basic grep -rnw etc. from root on the Ironwolf serial number, that returned a limited number of files ... btw I understood that overall displayed disks details are stored now in SQLite db, that I was able to edit with DBbrowser ... not difficult to remove smart tests results etc. btw it is also in those files the account, connection etc. logs are stored ... plugging AHCI/Sata it generated a specifc disk_latency file too (the Gen8 internal AHCI is a 3Gb link, as the Dell H310 a 6Gb x2 links, btw the DSM is able to determinate a latency in the accesses). It is those .SYNOxxxx files listed previously, and a disk_latency_tmp.db then made cleaning removing in SQLite records where the IronWolf serial was identified, but not change on the disk status ... except removing the log/trace/history of smart tests and extended one, not change on the disk himself. But now the issue seems to be more precisely linked with the pool management, as the disk health status is at "Normal" but the allocation is "Faulty" ... it means to determinate how the pool consider disks in its structure ... and why the eSata have impact (as for the IronWolf management) ...
-
Some news: Few other tests performed: - Installed IronWolf directly on SATA direct on Gen8 interface, and "provoc" an install/migration with another boot card = IronWolf listed as "Normal/OK", but the 8 TB SATA WD installed in external inclosure with other SAS HDD not recognized/disks missing - Update the synoconf removing eSata etc. - the 8TB WD is detected etc. => the IronWolf become as "Faulty" and automatically set out of the pool in DSM => the IronWolf HDD are managed specifically in DSM allowing few additional functions as monitoring, smart specific etc. BUT it is an issue in my case as in order to be compatible of SAS +SATA HDD in the same enclosure, parameters modify the way DSM is detecting the IronWolf ... potentially the eSata support is used in interfacing IronWolf ... => not the same behaviour under DSM 6.1 ... where it was working perfectly, issue with 6.2.2 Current status: - installed a new 12 GB WD SATA on Gen8 AHCI SATA (in addition to the 8 disks installed via the H310 LSI card) - DSM pool manager accepted the disk and initiated a recovery: 1st disk check (taked ~12h) = Ok - then recovery in progress ... estimated at 24h to be continued ...
-
Work now with integrated NIC using driver extension published two weeks ago, I run Gen8 with 6.2-24922 Update 4, but I performed a fresh install, no idea if update from previous release will work (see specific way to use driver extension)
-
Many thanks, no worry about release 6.1/6.2 confusion, I provided in this topic a lot of info (and few mix ) ... btw Ok understood concerning array rebuild etc. I am with you: more and more I check = it is a "cosmetic" issue as you told ... but archiving in .bak the two files have nothing changed I assume the log files are not impacting the identification of faulty disk on 6.2 ... and no idea from where to change setting in the config files ... Interresting point : even if the files are in .bak, DSM still list the tests performed and status in history ... btw /var/log files are not considered Is it something to do in /var/log/synolog ? root@Diskstation:/var/log/synolog# ll total 296 drwx------ 2 system log 4096 Dec 27 02:01 . drwxr-xr-x 19 root root 4096 Dec 26 20:51 .. -rw-r--r-- 1 root root 26624 Dec 27 02:01 .SYNOACCOUNTDB -rw-r--r-- 1 system log 114688 Dec 27 01:47 .SYNOCONNDB -rw-r--r-- 1 system log 32768 Dec 27 02:01 .SYNOCONNDB-shm -rw-r--r-- 1 system log 20992 Dec 27 02:01 .SYNOCONNDB-wal -rw-r--r-- 1 system log 12288 Dec 25 18:10 .SYNODISKDB -rw-rw-rw- 1 root root 3072 Dec 27 01:50 .SYNODISKHEALTHDB -rw-r--r-- 1 system log 8192 Dec 27 01:47 .SYNODISKTESTDB -rw-r--r-- 1 root root 2048 Dec 22 15:40 .SYNOISCSIDB -rw-r--r-- 1 system log 14336 Dec 27 01:50 .SYNOSYSDB -rw-r--r-- 1 system log 32768 Dec 27 01:51 .SYNOSYSDB-shm -rw-r--r-- 1 system log 1080 Dec 27 01:51 .SYNOSYSDB-wal None are editable ... Thanks Ps: It is 2am and I will stop investigate the 2 coming days as out of home, will continue when back
-
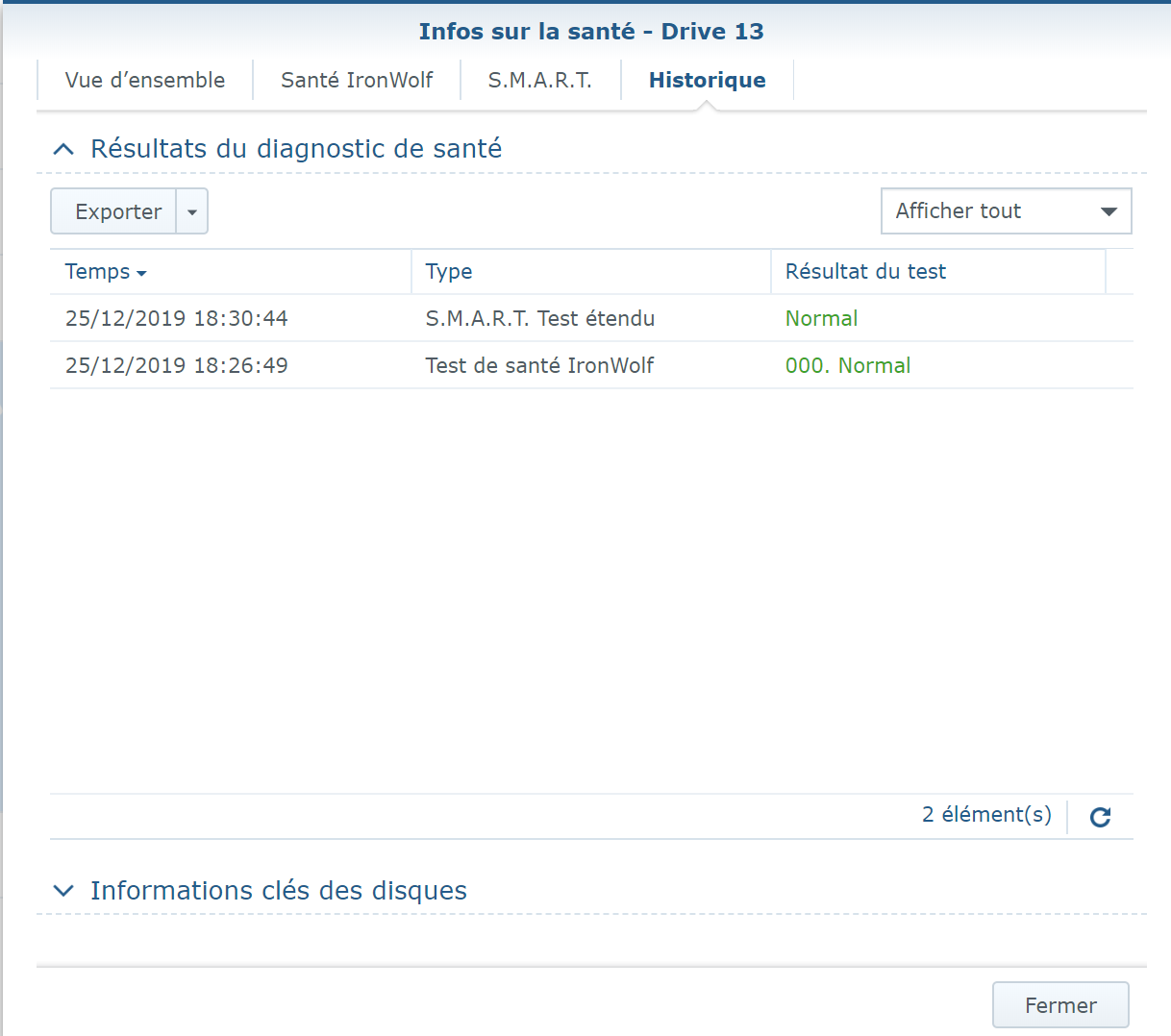
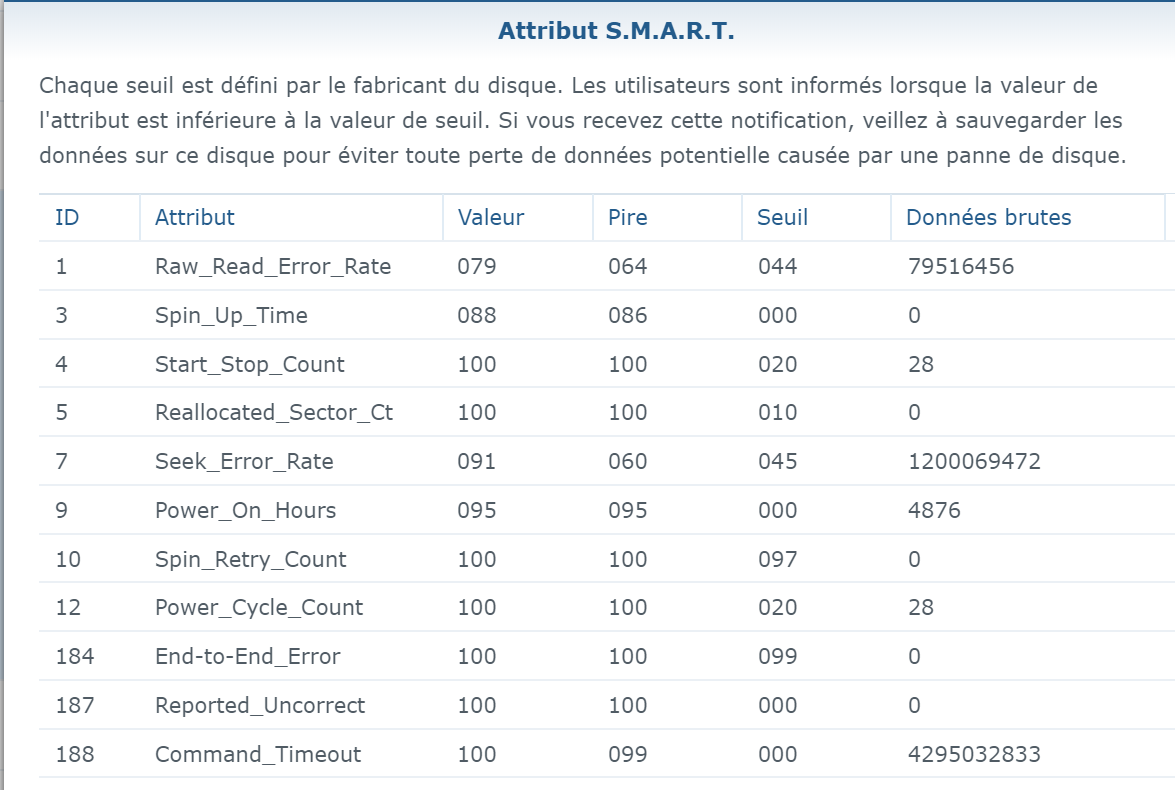
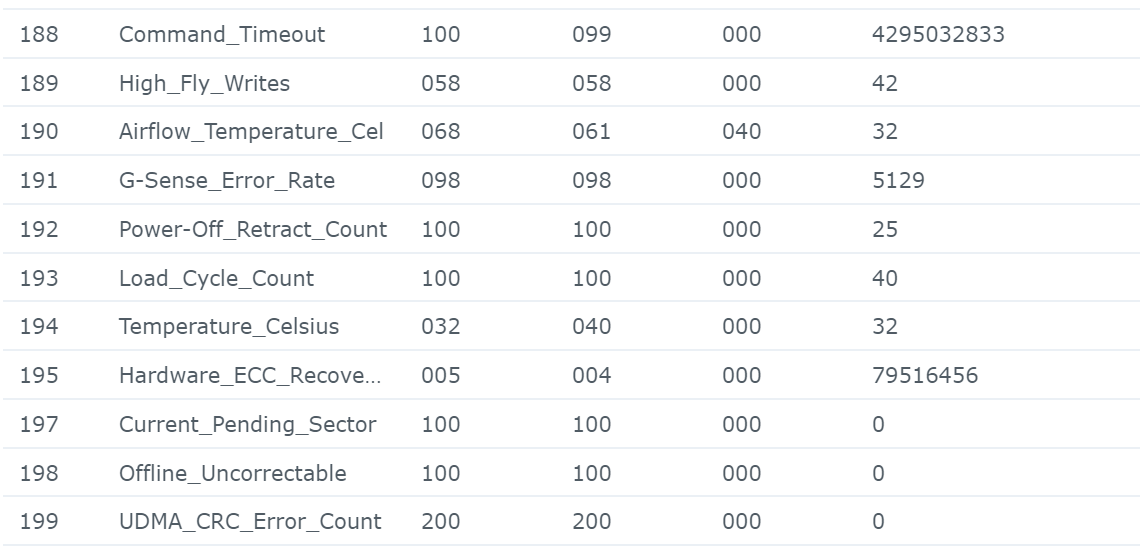
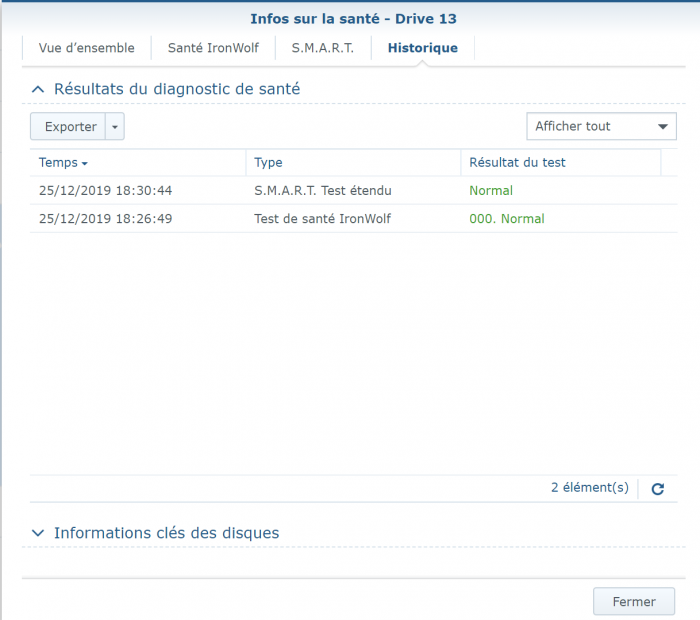
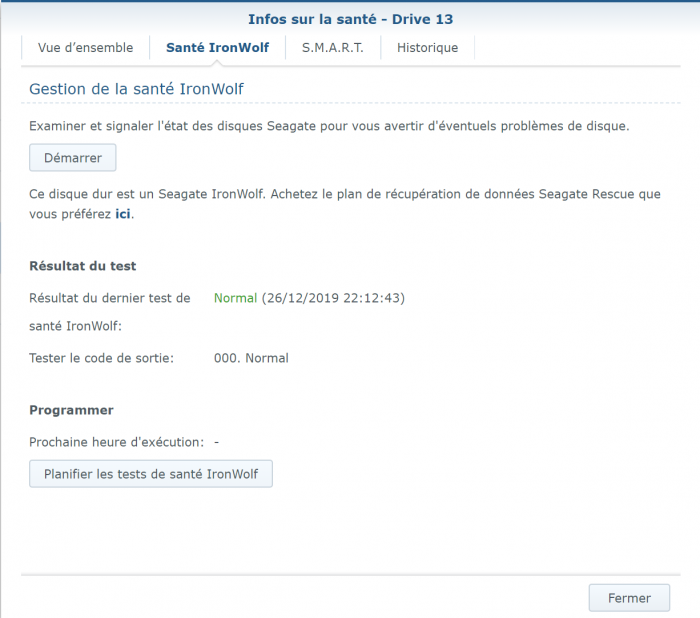
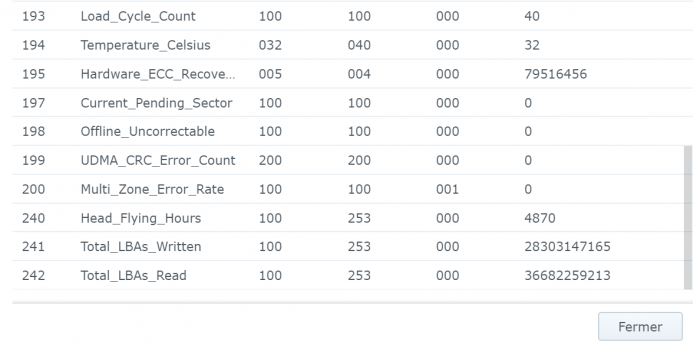
Sorry for wrong formulation mixed Smart test and Smart status ... : - the SMART Extended reported No Errors, everything as "Normal" = final disk health status is "normal": - But strangly (see the hardcopy of SMART details) the SMART status shows few errors (assuming SMART details are sometime a bit "complex" to analyze): Raw_read error_rate Seek_error_rate Hardware_ECC_recovered Checking on few forums it seems not really an issue and common with IronWolf ... assuming the reallocated sector is at 0 ... Feel pretty confident on SMART extended tests as it is a non-destructive physical tests (read value/write value of each disk sector) ... In addition IronWolf have a specific test integrated in DSM, that I run and report No Error (000. Normal) Found no smart_test_log.xml but: /var/log/healthtest/ dhm_<IronWolfSerialNo>.xz /var/log/smart_result/2019-12-25_<longnum>.txz I keep them waiting recommandation ! What about rebuild the array ? Sequence to rebuild the array is well known as following one: 1. umount /opt 2. umount /volume1 3. syno_poweroff_task -d 4. mdadm -–stop /dev/mdX 5. mdadm -Cf /dev/mdxxxx -e1.2 -n1 -l1 /dev/sdxxxx -u<id number> 6. e2fsck -pvf -C0 /dev/mdxxxx 7. cat /proc/mdstat 8. reboot but my array look likes to be correct as cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1] md2 : active raid5 sdk5[1] sdh5[7] sdi5[6] sdm5[8] sdn5[4] sdg5[3] sdj5[2] 27315312192 blocks super 1.2 level 5, 64k chunk, algorithm 2 [8/7] [_UUUUUUU] md3 : active raid5 sdk6[1] sdm6[7] sdh6[6] sdi6[5] sdn6[4] sdg6[3] sdj6[2] 6837200384 blocks super 1.2 level 5, 64k chunk, algorithm 2 [8/7] [_UUUUUUU] md5 : active raid5 sdi8[0] sdh8[1] 3904788864 blocks super 1.2 level 5, 64k chunk, algorithm 2 [3/2] [UU_] md4 : active raid5 sdn7[0] sdm7[3] sdh7[2] sdi7[1] 11720987648 blocks super 1.2 level 5, 64k chunk, algorithm 2 [5/4] [UUUU_] md1 : active raid1 sdg2[0] sdh2[5] sdi2[4] sdj2[1] sdk2[2] sdl2[3] sdm2[7] sdn2[6] 2097088 blocks [14/8] [UUUUUUUU______] md0 : active raid1 sdg1[0] sdh1[5] sdi1[4] sdj1[1] sdk1[2] sdl1[3] sdm1[6] sdn1[7] 2490176 blocks [12/8] [UUUUUUUU____] unused devices: <none> only the IronWold disk is consider as faulty ... not sure rebuild array will reset the disk error It is completly crazy, the disk are all normal, the arry is fully accessible, but DSM consider a disk as faulty and block any action (including adding drive etc.) Thx
-
No change, the regenerated disk_overview.xml is now without the disconnected SSD, the structure of each disk is exactly the same tag as for the IronWolf: <SN_xxxxxxxx model="ST10000VN0004-1ZD101"> <path>/dev/sdm</path> <unc>0</unc> <icrc>0</icrc> <idnf>0</idnf> <retry>0</retry> </SN_xxxxxxx> Where the DSM is storing the disk status ? I remember something as Synology has a customized version of md driver and mdadm toolsets that adds a 'DriveError' flag to the rdev->flags structure in the kernel ... but don't know I to change it ... Thx
-
Done, removedxml tag of IronWolf, but after reboot still the same status ... and I see that the former SSD I removed from install (disconnected) are listed in the disk_overview.xml What about performing a reinstall ? btw changing serialid of 3615xs in order to initiate a migration ? will it reset status ? as I do not reinstall applications/config etc. not a big issue to perform a migration ... Thanks a lot
-
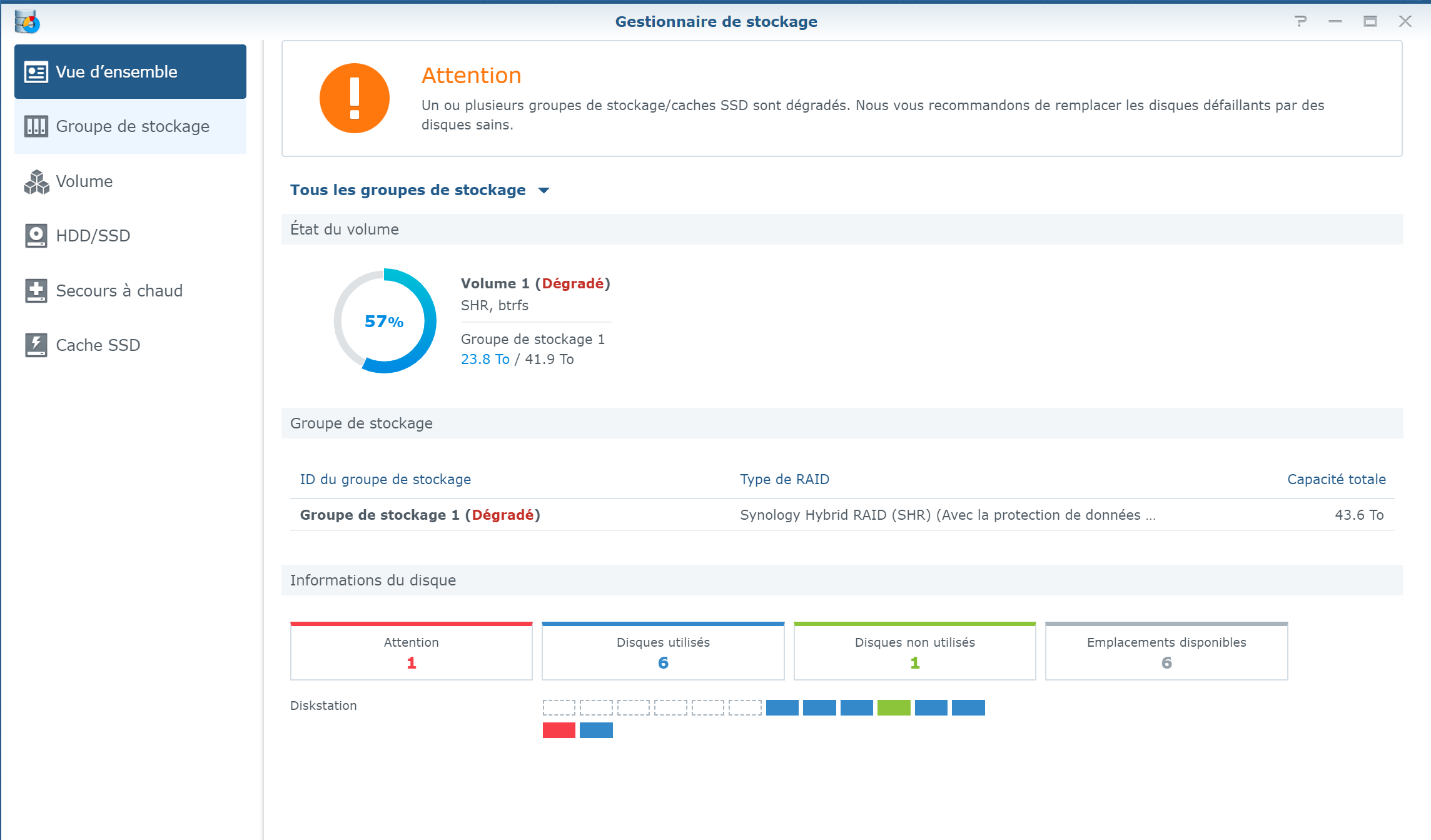
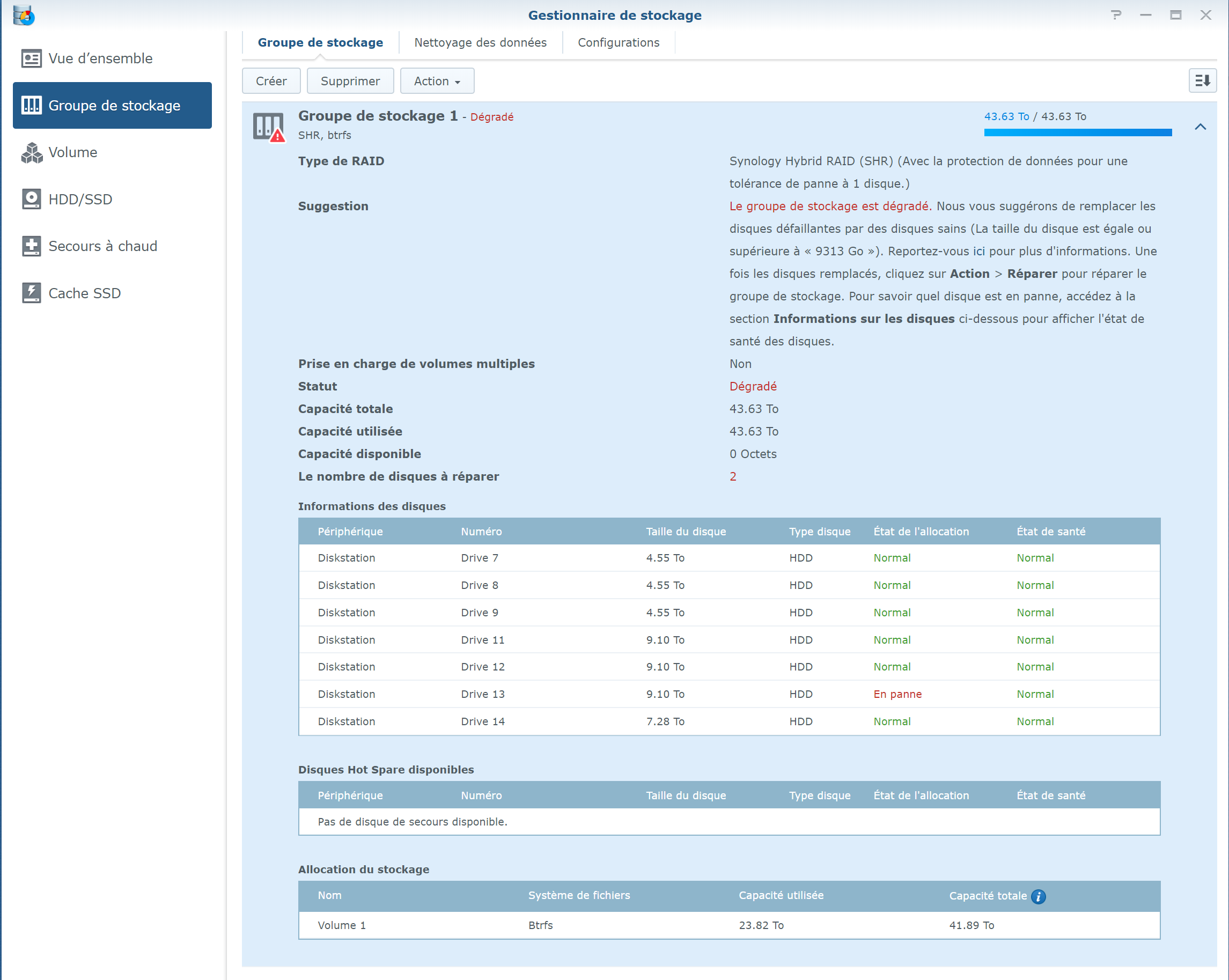
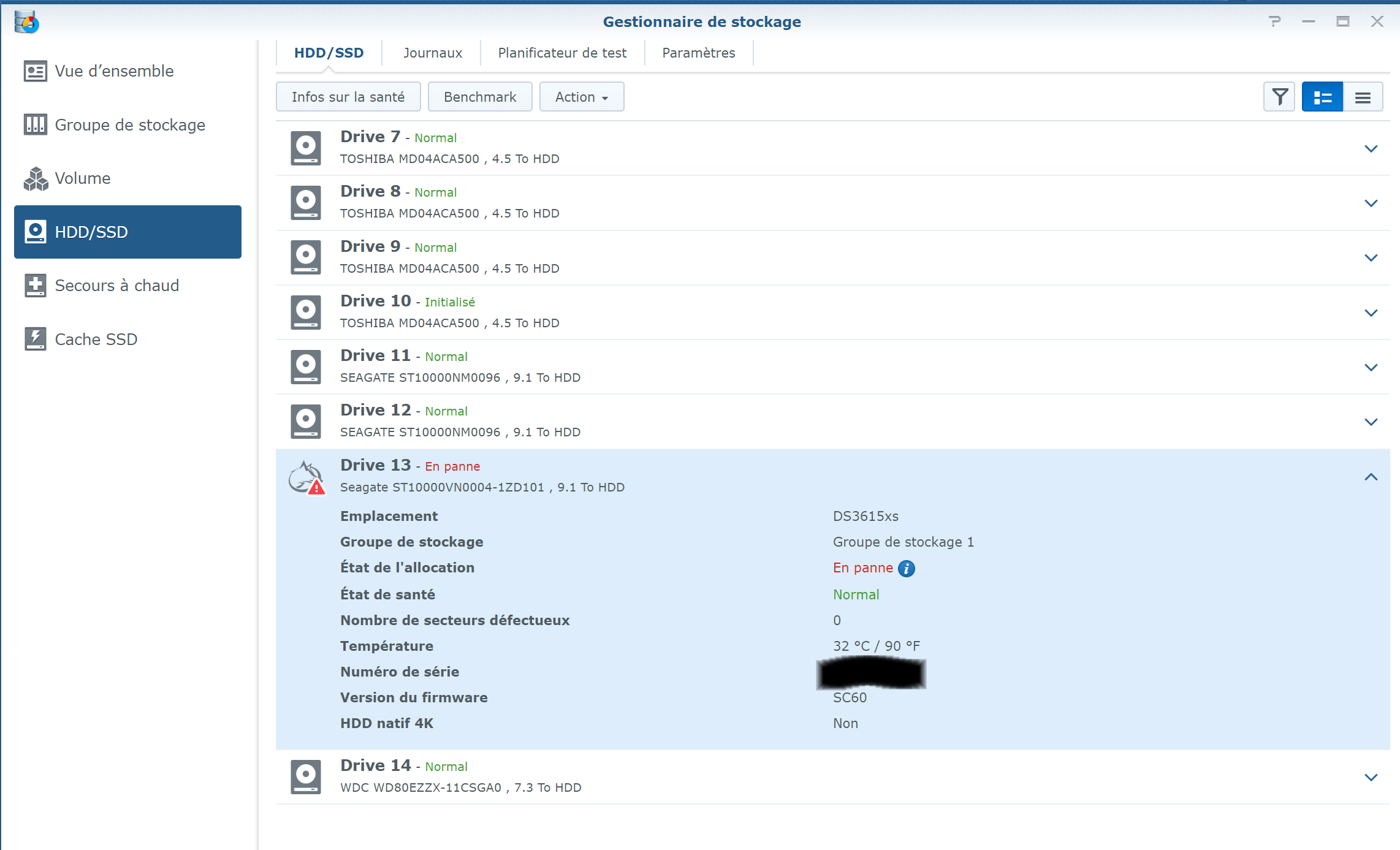
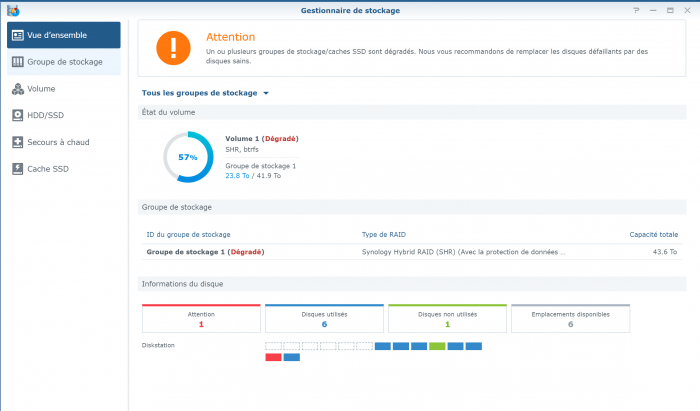
Here is the screenshot, but sorry it is in French ... IronWolf is displayed as "En panne" (="Failed" or "Broken") but with 0 bad sectors (but the SMART Extended test returned few errors) the pool status as "degraded" with the "failed drive" show as "Failed allocation status" and the rest of disks as normal the list of disks (the unused Toshiba is displayed as "Initied") And the SMART status of the IronWolf Many Thanks !
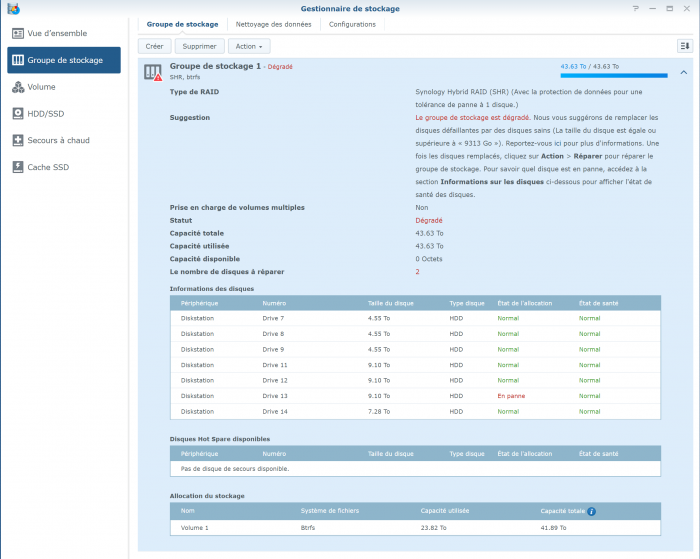
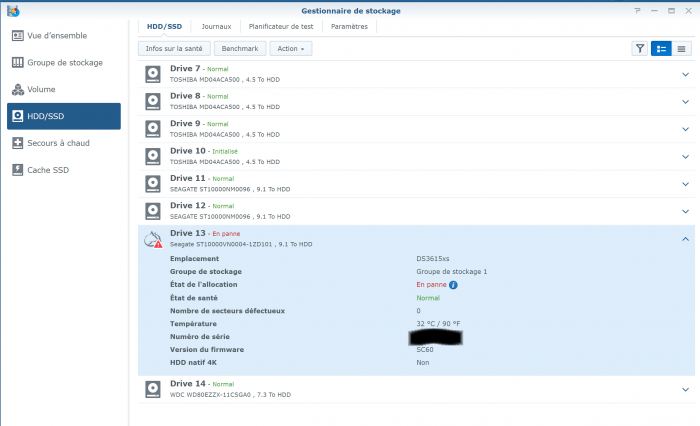
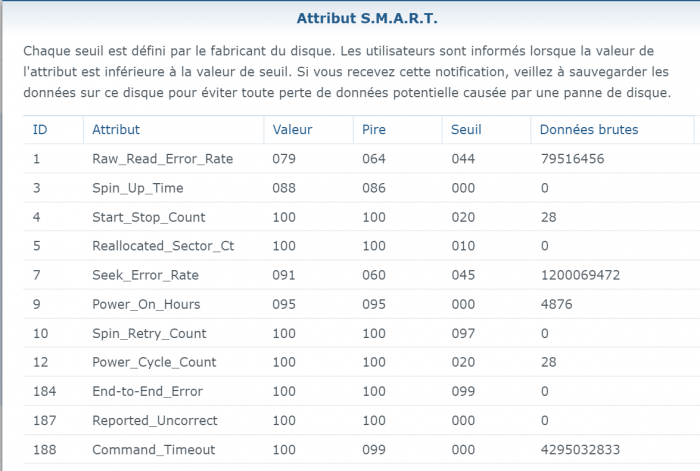
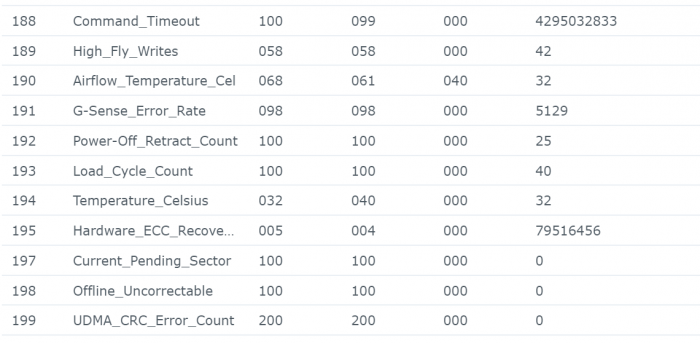
-
Hi again, last news: after 20h hours of test, the IronWolf Pro 10TB is analysed at “Normal” without Errors … 😰 But DSM shows it as faulty … I do not understand (again, sorry) as the configuration is: Toshiba 5TB: sdg, sdj, sdk, sdl Seagate Exos 10TB: sdh, sdi Western Digital 8TB: sdn Seagate IronWolf Pro 10TB: sdm And I understand the “initiated” status is certainly correct on the Toshiba 5TB, and the “faulty” IronWold Pro 10TB is fully operational … @flyride Could you please confirm my analyse bellow ? dmesg extract: ... [ 32.965011] md/raid:md3: device sdk6 operational as raid disk 1 = Toshiba 5 TB [ 32.965013] md/raid:md3: device sdm6 operational as raid disk 7 = IronWold Pro 10 TB [ 32.965013] md/raid:md3: device sdh6 operational as raid disk 6 = Exos 10 TB [ 32.965014] md/raid:md3: device sdi6 operational as raid disk 5 = Exos 10 TB [ 32.965015] md/raid:md3: device sdn6 operational as raid disk 4 = WD 8 TB [ 32.965016] md/raid:md3: device sdg6 operational as raid disk 3 = Toshiba 5 TB [ 32.965016] md/raid:md3: device sdj6 operational as raid disk 2 = Toshiba 5 TB … [ 32.965507] md/raid:md3: raid level 5 active with 7 out of 8 devices, algorithm 2 [ 32.965681] RAID conf printout: [ 32.965682] --- level:5 rd:8 wd:7 [ 32.965683] disk 1, o:1, dev:sdk6 = Toshiba 5TB [ 32.965684] disk 2, o:1, dev:sdj6 = Toshiba 5TB [ 32.965685] disk 3, o:1, dev:sdg6 = Toshiba 5TB [ 32.965685] disk 4, o:1, dev:sdn6 = WD 8 TB [ 32.965686] disk 5, o:1, dev:sdi6 = Exos 10 TB [ 32.965687] disk 6, o:1, dev:sdh6 = Exos 10 TB [ 32.965688] disk 7, o:1, dev:sdm6 = IronWolrd Pro 10 TB … mdstat returns: Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1] md3 : active raid5 sdk6[1] sdm6[7] sdh6[6] sdi6[5] sdn6[4] sdg6[3] sdj6[2] 6837200384 blocks super 1.2 level 5, 64k chunk, algorithm 2 [8/7] [_UUUUUUU] md2 : active raid5 sdk5[1] sdh5[7] sdi5[6] sdm5[8] sdn5[4] sdg5[3] sdj5[2] 27315312192 blocks super 1.2 level 5, 64k chunk, algorithm 2 [8/7] [_UUUUUUU] md5 : active raid5 sdi8[0] sdh8[1] 3904788864 blocks super 1.2 level 5, 64k chunk, algorithm 2 [3/2] [UU_] md4 : active raid5 sdn7[0] sdm7[3] sdh7[2] sdi7[1] 11720987648 blocks super 1.2 level 5, 64k chunk, algorithm 2 [5/4] [UUUU_] md1 : active raid1 sdg2[0] sdh2[5] sdi2[4] sdj2[1] sdk2[2] sdl2[3] sdm2[7] sdn2[6] 2097088 blocks [14/8] [UUUUUUUU______] md0 : active raid1 sdg1[0] sdh1[5] sdi1[4] sdj1[1] sdk1[2] sdl1[3] sdm1[6] sdn1[7] 2490176 blocks [12/8] [UUUUUUUU____] => In all cases the Toshiba 5TB (identified as “sdl”) is never used … except in md0/md1 partition (=status initiated) ... and the “faulty” IronWolf Pro (identified as "sdm") is working … !!! ... mdadm --detail /dev/md2 gives this result: /dev/md2: Version : 1.2 Creation Time : Thu Aug 3 09:46:31 2017 Raid Level : raid5 Array Size : 27315312192 (26049.91 GiB 27970.88 GB) Used Dev Size : 3902187456 (3721.42 GiB 3995.84 GB) Raid Devices : 8 Total Devices : 7 Persistence : Superblock is persistent Update Time : Thu Dec 26 18:41:14 2019 State : clean, degraded Active Devices : 7 Working Devices : 7 Failed Devices : 0 Spare Devices : 0 Layout : left-symmetric Chunk Size : 64K Name : Diskstation:2 (local to host Diskstation) UUID : 42b3969c:b7f55548:6fb5d6d4:f70e8e8b Events : 63550 Number Major Minor RaidDevice State - 0 0 0 removed 1 8 165 1 active sync /dev/sdk5 2 8 149 2 active sync /dev/sdj5 3 8 101 3 active sync /dev/sdg5 4 8 213 4 active sync /dev/sdn5 8 8 197 5 active sync /dev/sdm5 6 8 133 6 active sync /dev/sdi5 7 8 117 7 active sync /dev/sdh5 Btw, the Raid mechanisms is working, as data are accessible ... but DSM do not change status on IronWolf Pro …😖 I was close to a big mistake: I have not to change the IronWolf Pro because it is part of the working RAID, and the 20 hours test (SMART Extended) on the IronWolf Pro shows a correct status without currupted sector etc. confirm this. How do I force DSM to change status on disk IronWolf Pro 10 TB from faulty to normal ?!? Because the Toshiba 5 TB is not initiated (and perhaps the faulty drive ?) but DSM do not want to initiate it til the 10TB is not "replaced" ... that I have certainly not to do if I want to keep all data ... Thanks !
-
Gen8 users (and other ?), in case of SAS HDD installed both with SATA on the same Mini-SAS port w/mixed SATA/SAS Disks (connected via LSI PCie card)= do not configure the "SasIdxMap=0", it shall not be part of Grub.cfg in order to allow detection of mix of Disks, if configured the SATA disks are not mapped by DSM !
-
Yes, listed the exact message shown by DSM that is generic about SSD installed structure telling about "read-write SSD cache" ... but it was obviously configured in "read-only" I fully agree about the status "Initialized" as not strictly in use in disks pool, but I figure a wrong status or it was not possible to get access to data assuming the faulty HDD is also out of the pool ... and btw 2 disks out do not allows access to data (or I miss something in pool mechanisms) Current status is: - after 24h hours of parity (coherence) check = OK - x2 SSD excluded (cache switched "Off") - x3 5Tb + x1 WD 8Tb + x2 Seagate Exos = Normal - 5Tb Toshiba = Initialized - 10Tb Seagate Ironwolf Pro = still in default => Smart full test in progress on the Ironwolf Pro = On-going (~20h planned) => Spare 10Tb disk ordered for exchange asap Thanks ! Ps: for Gen8 users w/mixed SATA/SAS Disks = do not configure the "SasIdxMap=0", it shall not be part of Grub.cfg in order to allow detection of mix of Disks, if configured the SATA disks are not mapped by DSM.
-
Thanks, I was using SSD cache in r/o, never in r/w, just as a facility to ease video operation (eg. fast-back from cache etc.) But I tried as suggested to delete it, then the volume is still with a failed HDD, btw a 10Tb Seagate Ironwolf Pro Red special NAS ! pretty new ... = will replace it asap then check it and potentially ask waranty to be apply. It remains suprizing that 1 disk is in default (the 10Tb), and another one (a 5Tb) is not in status "Normal" but in status "Initiated" ... I do not understand why it is not in status "Normal" assuming it works as the whole data are available ... and the faulty 10Tb was excluded from the disks pool/volume ! Thanks for your advises.
-
I found the solution, it is in conf files to make changes: - max capacity to update (from x12 to x14 in my case, due to AHCI showing additional disk ports on Gen8) - then avoid DSM to exclude disks (recognized by system as checked in demsg) assimilated them to USB or eSATA: Disable eSATA updating esataportcfg to 0x00000 (instead default 0xff000) = 0 eSATA for Gen8 Align exact USB ports updating usbportcfg to 0x7C000 (instead default 0x300000) = 5 USB for Gen8 default HW config. Align exact port to consider updating internalportcfg to 0x3FFF (instead of default 0xfff) = 14 Disks ports in my case After reboot the all disks are detected and mapped ... SOLVED
-
SOLVED Hi everybody, a big thanks to all of you that supported me, and thanks to this forum and other ones ... as I finally solved my issue. @flyride: many thanks for our support and suggestion, btw I tried a last change in DSM configuration last night (before doing the test w/1.02b + 6.1.7 + HDD 1To) ... "but" ... the system found overall disks and initiated a recovery, btw I was not able to perform tests, and the rescue target is finally the 3615xs/1.03b/6.2.2 as it started to recover ... Details: - my description was a bit wrong, the Gen8 has not a eSata connector inside but a SFF-8087 miniSAS, as the same on the DELL H310 with x2 SFF-8087 miniSAS, and external inclosure is a SFF-8088 SAS connected on H310 with a classic SFF-8088 to SFF-8087 ... = no eSATA - I discover investing the demsg that the reported number of HDD SDD is correct but the mapped disks is incorrect, with 2 missing ones . = I remember that the DSM do not display eSATA drives in the disks pool/available ones - Thanks to disks pool structure, the order and mapping have no impact on DSM (I strongly recommend to create a pool of disk previously to volume or to convert volume to pool in order to be independant of disks mapping id) - Finally, following this forum (a bit old topic as conf files changed and do not addressing external SAS SCSI mapped drives etc. ) https://hedichaibi.com/fix-xpenology-problems-viewing-internal-hard-drives-as-esata-hard-drives/ I updated the conf files in order to: Disable eSATA updating esataportcfg to 0x00000 (instead default 0xff000) = 0 eSATA Align exact USB ports updating usbportcfg to 0x7C000 (instead default 0x300000) = 5 USB Align exact port to consider updating internalportcfg to 0x3FFF (instead of default 0xfff) = 14 Disks ports Then after rebooting (the citated topic is not correct considering external SAS, it is mandatory to reboot), the DSM found overall disks with lot of errors and "strange" ones: - One SSD not synchro = corrected immediatly via resync - A system partition wrong on a disk = repaired asap (as in SHR the system partition is duplicated on several disks) - A disk not included in the Disks pool = waiting to repair - A disk in default = waiting to understand and repair ... But ... all data available (from few checks performed picking files here and here ...), it is very surprizing if a disk is out of the pool and another one in default ... as tolerance of only 1x disk crash ... I suspect a wrong report ... but I have to wait to finalize check. Current status is DSM performing a global disks coherence check, it will take ~24h to verify, then I will reboot and check if something remains wrong. But for the moment I am able to backup, not all data, but the most critical ones ! Thanks.
-
Yes, thanks, I consider btw the 1st alternative as the most secure, and I will perform the test you suggest. But fyi I continued to investigate : HP Gen 8 microserver hardware includes a eSata/4xSATA internal + 2xSata internal (for CD-Rom purpose, the "ODD" connector) - In Legacy mode (not Loader 1.03b compatible) the Gen8 consider 4+2 Sata distinct i/f but with "SataPortMap=44" in grub.cfg (the second 4 have no impact) is restrict on #1 to #4 idx => and the SAS Card connected HDD are mapped in order (SasidxMap=0) starting at idx #5 - In AHCI mode the Gen8 consider unique SATA with 4+2 connectors = 6 ... and the "SataPortMap=4" have no effect to restrict the number of SATA port, in get #1 to #6 idx ... => consequently the SAS Card connected HDD are mapped starting at idx #7 ... Btw, I proceed in order to extended the number of supported HDD in synoinfo.conf from 12 to 14 Disks but ... the missing disks in the inclosure are not displayed by DSM ... even if they are recognized by the system, as an extract from dmesg shows: [ 1.726330] ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) = 1st connected SATA disk detected ... [ 1.727050] sd 0:0:0:0: [sda] 234441648 512-byte logical blocks: (120 GB/111 GiB) = SSD1 = sda => mount as Disk 1 ... [ 2.190444] ata2: SATA link up 6.0 Gbps (SStatus 133 SControl 300) = 2d connected SATA disk detected ... [ 2.205887] sd 1:0:0:0: [sdb] 234441648 512-byte logical blocks: (120 GB/111 GiB) = SSD2 = sdb => mount as Disk 2 ... [ 2.511531] ata3: SATA link down (SStatus 0 SControl 300) = sdc = nothing more connected on Gen8 SATA [ 2.816612] ata4: SATA link down (SStatus 0 SControl 300) = sdd [ 3.121693] ata5: SATA link down (SStatus 0 SControl 300) = sde [ 3.426775] ata6: SATA link down (SStatus 0 SControl 300) = sdf ... [ 3.821242] mpt2sas0: LSISAS2008: FWVersion(20.00.07.00), ChipRevision(0x03), BiosVersion(07.39.02.00) = PCie board detected [ 3.821243] mpt2sas0: Dell 6Gbps SAS HBA: Vendor(0x1000), Device(0x0072), SSVID(0x1028), SSDID(0x1F1C) ... [ 6.155956] sd 6:0:0:0: [sdg] 9767541168 512-byte logical blocks: (5.00 TB/4.54 TiB) = HDD1 = sdg => mount as Disk 7 ... [ 6.655951] sd 6:0:1:0: [sdh] 9767541168 512-byte logical blocks: (5.00 TB/4.54 TiB) = HDD2 = sdh => mount as Disk 8 ... [ 7.156168] sd 6:0:2:0: [sdi] 9767541168 512-byte logical blocks: (5.00 TB/4.54 TiB) = HDD3 = sdi => mount as Disk 9 ... [ 7.656316] sd 6:0:3:0: [sdj] 9767541168 512-byte logical blocks: (5.00 TB/4.54 TiB) = HDD4 = sdj => mount as Disk 10 ... [ 22.320896] sd 6:0:4:0: [sdk] 19532873728 512-byte logical blocks: (10.0 TB/9.09 TiB) = HDD6 = sdk => mount as Disk 11 = SAS disk !!! ... [ 27.755589] sd 6:0:5:0: [sdl] 19532873728 512-byte logical blocks: (10.0 TB/9.09 TiB) = HDD8 = sdl => mount as Disk 12 = SAS disk !!! ... [ 28.160476] sd 6:0:6:0: [sdm] 15628053168 512-byte logical blocks: (8.00 TB/7.27 TiB) = HDD5 = sdm = Not Mounted = SATA disk !! ... [ 28.691687] sd 6:0:7:0: [sdn] 19532873728 512-byte logical blocks: (10.0 TB/9.09 TiB) = HDD7 = sdn = Not Mounted = SATA disk !! But what is very strange is that during test with test disks I installed Sata disks in enclosure and they was mounted ... btw two possibilities: or a mix of SAS and SATA is now not compatible of mounting (why ?!?), or I missed something in the Grub.cfg with loader 1.03b assuming current parameter is: set sata_args='sata_uid=1 sata_pcislot=5 synoboot_satadom=1 DiskIdxMap=0E SataPortMap=68 SasIdxMap=0' My assumption is a set of 2 SATA controler (Rq: if I put only one with 6 ports, the disks are mixed in index but still 2 missing) Will perform test with 1.02b loader and test HDD ... assuming I have the original loader configuration/grub.cfg Many thanks !