satdream
-
Posts
98 -
Joined
-
Last visited
-
Days Won
2
satdream's Achievements
Advanced Member (4/7)
13
Reputation
-
Ok, wrong suggestion ... I understand the DSM system partition is full ... btw I have to find a solution to mount it (but with 21 HDD it is not simple and potential dammages will results, as to mound with mdadm the correct partition to free space ...). Definitively ARC Loader "Next" is strongly bugged ... as the switch from former release induct a mess in config ... Does somebody knows how to mount correctly the system partition with such disks quantity to free space ? [Update] great thanks to @Polanskiman and his tutorial ... I was able to assemble the whole disks of system partition, and then to mount it, cleaning autoupdate and update folders, and log one from var folder to free enough space ... recovered 1 SSD + 20xHDD (204 TB of disks !) ... but btw, I still have the bug of the control panel not opening ...
-
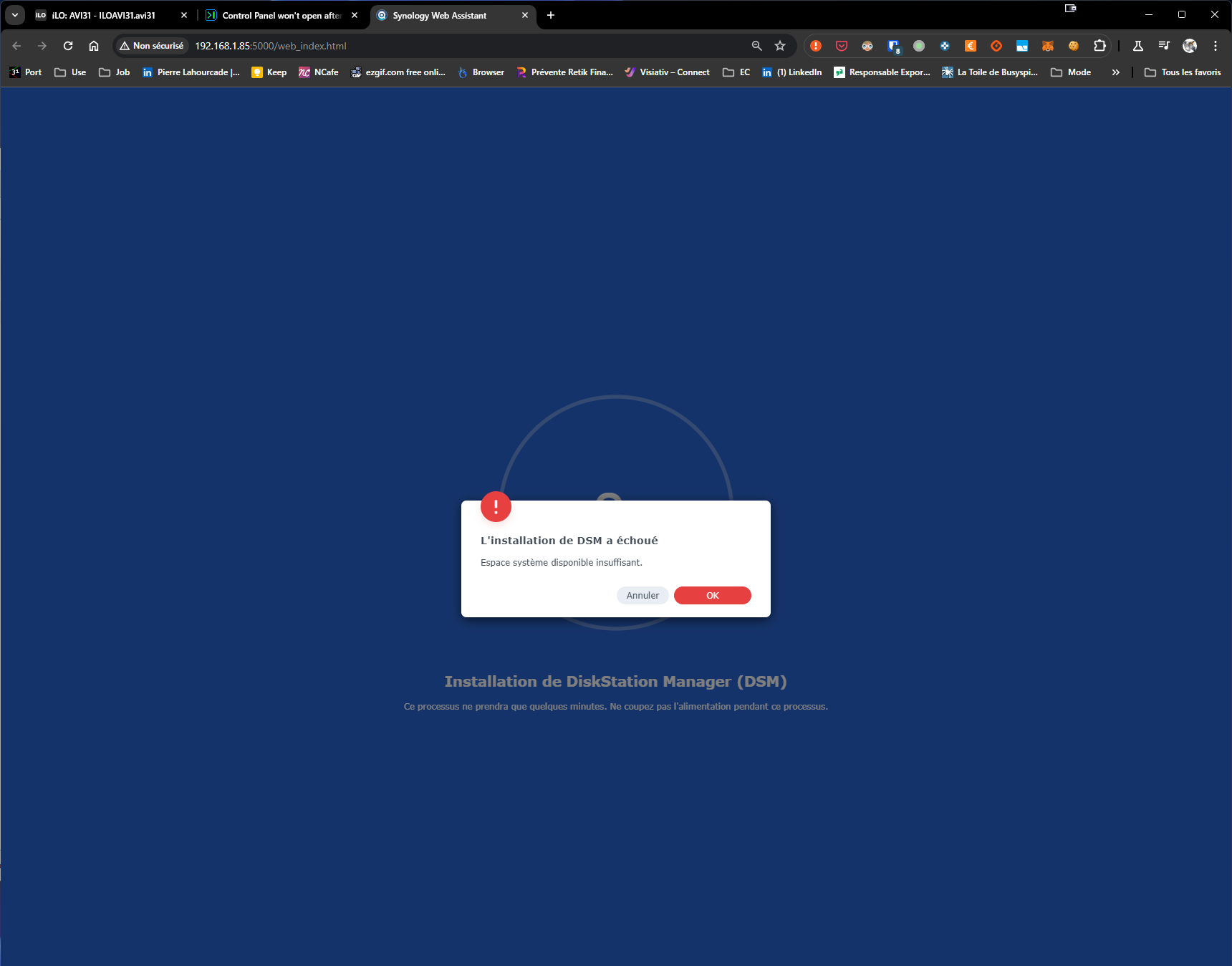
Could not migrate to 4021XS ... got message "no enough free space" [Update]: where is this space not enough ? is it on the SDCard I am booting on Arc ? because I do not understand how it could not be enough free space on HDD ... Btw Arc image is fixed size ... it is to extend partition but I have errors trying to ... The 1st partition is 50MB only ... the 2d also, system do not use the 3rd one ?!?
-
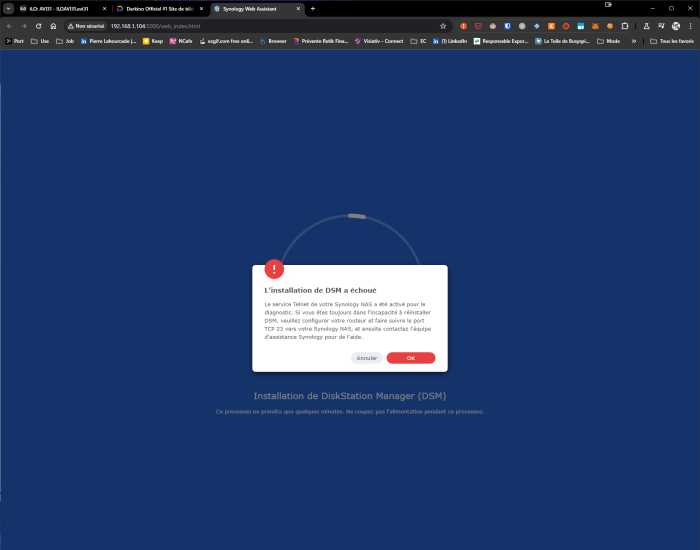
It do not works, got error message something like "DSM version could not be installed" ... telnet activated ... call Synology support etc. Now I am blocked ... as then I updated loader, again from clean, tried to reinstall ... and same message ... bricked
-
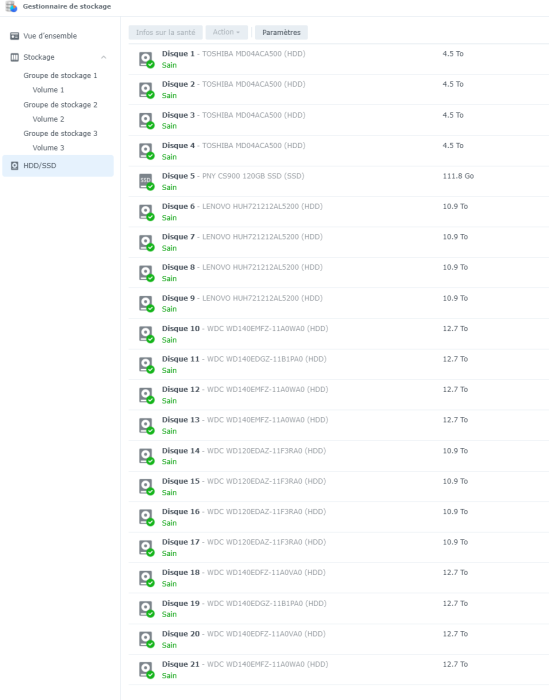
Thanks for supporting, "usually" changing for an upper model is wo/lost of data (btw in my case it suppose moving from 3622XS to 4021XS+), but I could not take any risk about my data ... To explain a bit more why I do not want to take any risk, this is my HDD config ... with a basic 4xHDD + Cache SSD in HPGen8 (16GB Xeon E3-1265L) baremetal + SAS Rack of 16xHDD connected via SAS SAS9202-16E-LSI ... Will try ... Thanks.
-
Thanks,but I know/apply correct procedure and I do not use restore with code assuming a full reinstall ... I restart from blank and fill all fields manually (MAC, SerialNum etc.) as new device. The issue is being under a minor release w/DSM 7.2.1 69057-Update 4 = the ARC Loader force reinstall only install the Update 4 patch, and not the full DSM. Btw it seems not possible to do in another way as no roolback possible due to patches, especially w/security aspects ... Expect to solve with major release ... as moving to another model is too risky regarding high storage capacity installed w/thousands of documents etc.
-
You're lucky because with last release 24.3.10 I have no progress ... force reinstall do not solve issue on my side ...
-
Hi, I updated with last ARC version 24.2.18 but still it do now stricly reinstall DSM, assuming no download of last syno release ...
-
Do it w/24.2.1-next, but here again no change ... btw ARC once selecting DSM 7.2.1 69057 do not really download the full DSM install (w/Update 1), I am sure about, because the downloading time is too short (wrt my ISP speed connection), it probably download the Update 4 patch ... Then clean config/reboot/force reinstall it is the same as the DSM booting 1st time (migration/recover) download/install DSM too fast (in < 5 sec it start from 0% to finish at 100%) ... before reboot ... Well, I will not try anymore til a new major DSM release ... It is too risky for me changing model (eg. moving to RS4021xs on same architecture) as > 120 To storage being this server (I had only one time an issue, moving 3617xs to 3622xs and it was 7 days rebuild/recheck/restore full storage capacity ... !) Thanks.
-
Sorry, but I strictly updated with 24.1.19, and then do it again with 24.1.17 but in anyway the force reinstall once selected made DSM install very quickly. My humble opinion is the system is loading only the 7.2.1 update 4 small upgrade and not the 7.2.1 incl. update 1 which is the only one with the full DSM install. Look likes no possibility to reverse back to previous release than update 4 ... I have x4 HP Gen8 Microserver is the same config (HP Gen8 - 16Gb - Intel Xeon E3-1265L v2 2.5 Ghz - Intel NIC + SAS9202-16E-LSI etc.) and only 1 is not starting control panel ... unfortunately it is my main server with 15x HDD in rack connected to ... and really an issue as reverse proxy configured on ... Will try to remove loader option (I had in the past CPUId module induction problems ...) but if not working, I do not see other option than expecting a major DSM update, and force install manually via SSH ... Thanks for your time.
-
It do not still work ... what I do: - reboot, then ARC, config mode - perform full upgrade - clean config (no restore) - build loader / reboot - select force reinstall, ARC boot - and then the DSM is installed (it is very fast, no ask to download etc.) - reboot - login DSM ... = control panel do not open ... Where I am wrong ? Thanks.
-
Finally I update to last leader (was already in -next release), then forced reinstall DSM = perfoming a "recovery" from 1st boot, and then ... unfortunatly it is no change, Control Panel still not opening ...
-
Same issue .... strangly it was starting immediatly after the update, but then after a reboot it is now blocked to open ... Is DSM reinstall then updating to 7.2.1 release 4 do not reproducing the same issue ?
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: DSM 7.2.1 69057-Update 3 - DSM version AFTER update: DSM 7.2.1 69057-Update 4 - Loader version and model: ARC Loader v24.1.2 DS3622xs+ - Using custom extra.lzma: NO - Installation type: BAREMETAL - HP Microserver Gen8 - 16Gb - Intel Xeon E3-1265L v2 2.5 Ghz - Intel NIC - SAS9202-16E-LSI - QNAP USB 3.0 Ethernet 5GbE (acq111)
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: DSM 7.2-64570 U3 - Loader version and model: ARC Loader v23.10.2a DS3622xs+ - Using custom extra.lzma: NO - Installation type: BAREMETAL - HP Microserver Gen8 - 16Gb - Intel Xeon E3-1265L v2 2.5 Ghz - Intel NIC - SAS9202-16E-LSI - QNAP USB 3.0 Ethernet 5GbE - Additional comments: Update loader restoring config was not working, had to perform migration w/same S/N etc. then boot succesfull. QNAP USB 3.0 Ethernet 5GbE and all 20 HDDs + 2 SSDs perfectly working
-
Hi, I did not changed usual config using 5th SATA for SSD as cache for the system, and as you remark the 5th SATA port (as the port 3 and 4) only runs at 3Gb/s (vs. 6Gbs/s for the port 1 and 2) ... Personaly I did not see the benefit using a SSD for boot vs. using fast SD card to boot (it is fast enough from my perspective), btw the boot itself is not critical in terms of operations performance (once booted there is nothing to do with SD Card). But in anyway highest speed and flexible configuration is mainly via an additional extension card to bypass internal SATA configuration limits. Best Sat.