

WiteWulf
-
Posts
423 -
Joined
-
Last visited
-
Days Won
25
Posts posted by WiteWulf
-
-
2 hours ago, nemesis122 said:
I can confirm that i have the same Gen8 reboots sometimes and again randomly so in this case i think htis kernel panic.
It's interesting that you and @erkify are seeing spontaneous reboots, and that they could be associated with Docker containers. Can you both please monitor the serial console output (if you can) and see what's happening on your systems when they crash? I was having a lot of these reboots on my Gen8 when I initially went to 6.2.4 on redpill, and they persisted when I moved to 7.0.1
More detail here if you're interested in helping solve this one:
Quotefor the issue with the blank system info i add this line and is working
sed -i 's/supportsystemperature="yes"/supportsystemperature="no"/g' /etc.defaults/synoinfo.conf
sed -i 's/supportsystempwarning="yes"/supportsystempwarning="no"/g' /etc.defaults/synoinfo.conf
information for this line are here
https://gist.github.com/Izumiko/26b8f221af16b99ddad0bdffa90d4329
Thanks for the above, I've had the same blank General tab problem and this fixed it. Am I right in thinking that synoinfo.conf gets recreated at boot time? Would those lines need to go in a script that gets run regularly for it to be persistent?
-
13 hours ago, scoobdriver said:
@WiteWulf Out of interest are you passing any additional Parameters for the onboard b120i sata controller
SataIdxMap , SataPortMap etc ?
Just going to try using the onboard controller in ACHI mode , as HBA support doesn't seem quite there yet .
Do we still need to pass SataIdxMap=0C00 to pass the USB boot to position 13 , etc ?
Nope, nothing additional at all. "It just works", as Steve would have said 😀
-
8 minutes ago, havast said:
I have to pass through to the VM 2 BroadCom NetExtreme NICs. Unfortunatelly the syno didnt recognise them. ) Maybe missing drivers i think. Any suggestions?
Don't pass them through. Set up a vswitch in ESXi with the Broadcom NIC(s) as uplinks to your LAN and present e1000e adapters to the VM. They're supported in redpill/DSM7.x afaik
-
 1
1
-
-
3 hours ago, WiteWulf said:
Yeah, I had a feeling it was going to be a USB serial port issue...
So, after doing some googling, it seems Synology have dropped support for ALL USB devices other than storage in DSM 7. This is causing problems for lots of people with USB TV tuners, DACs, WiFi, serial ports, zigbee interfaces, Bluetooth, printers, you name it.
https://mariushosting.com/synology-how-to-add-usb-support-on-dsm-7/
-
 1
1
-
-
32 minutes ago, Orphée said:
Yeah, I had a feeling it was going to be a USB serial port issue...
-
25 minutes ago, nemesis122 said:
What has changed with this commit?
thank you
The clue's in the title

"Dial back ioctl() logging"
ct85msi and I had noticed excessive logging of ioctl() messages (not errors) to the console. This should have no functional impact on the operation of the system.
-
1
-
-
1 minute ago, nemesis122 said:
Hi no im note sure this can also be Kernel panic the server reboots and in the log -->“shutdown improperly” and then it does disk scrubbing to check integrity.
this is happen with docker running or creating, also this is happen when i copy files over smb
In that case I'd definitely suggest watching the serial console output and seeing what happens when it reboots because of docker or SMB activity.
-
12 minutes ago, ct85msi said:
@WiteWulf, maybe this is our fix?
https://github.com/RedPill-TTG/redpill-lkm/commit/f486cc8c873950660d9ee08054478b7b4629ced6
Can someone test? I have a baremetal and it`s not near me to change the usb boot stick to test
")
Yeah, that'll definitely be it.
At this point I'd like to take the opportunity to thank @ThorGroup for the excellent quality of their code commenting, it's really very professional and makes figuring out stuff like this much easier.
-
 2
2
-
-
1 hour ago, Franks4fingers said:
Can I ask what you are backing up to, how you are backing it up and is it everything on your NAS including (potentially) music, movies, pics, TV etc etc or just the main OS install and associated config?
I'm doing two things:
- take a system configuration backup from Control Panel -> Update & Restore -> Manual Export. This produces a small file that I store somewhere safe
- use Hyper Backup from the Synology Package Centre to create a backup of all Folders and Applications to a 6TB USB3 external HDD
With these two steps complete I should be able to rebuild my server from a clean install if necessary, or at least get very close to it.
-
1
-
-
2 hours ago, nemesis122 said:
all is working but when i set a docker container as example JD2 the system shutdown and reboot
I think this is NIC driver Related
This is interesting, I was seeing similar behaviour with Docker, although mostly with one particular container (influxdb). What is the exact spec of your micro server, please?
Are you sure it’s shutting down and rebooting? My system would kernel panic and do a hard reboot, followed by a notification from DSM that it was “shutdown improperly” and then it does disk scrubbing to check integrity.
Watch the serial console output while you run docker and see if it’s kernel panic’ing, then post the output of you can.
You’re the only other person I’ve seen with docker related reboots so I’m curious to know more. I posted more about my experience here.
-
7 hours ago, Ermite said:
Installed bromolow-7.0.1-42214 to my HP N54L.
I was used Jun's Loader 1.03b (DSM 6.2.3) and all HDD fully migrated with no error. (only keep my data, drop before config)
and it work well, but some part is not work.
1. Info Center - General tab is blank.
2. USB UPS cannot work. I'm using APC UPS, it worked with 6.2.3.
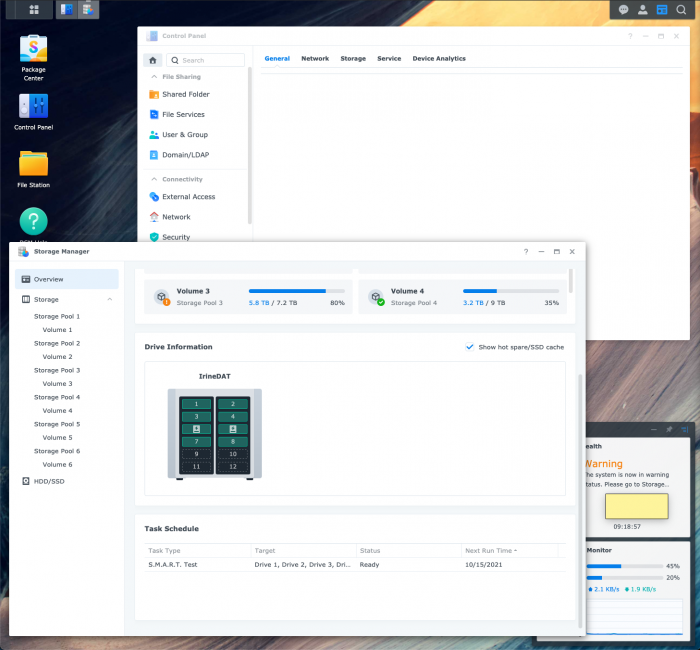
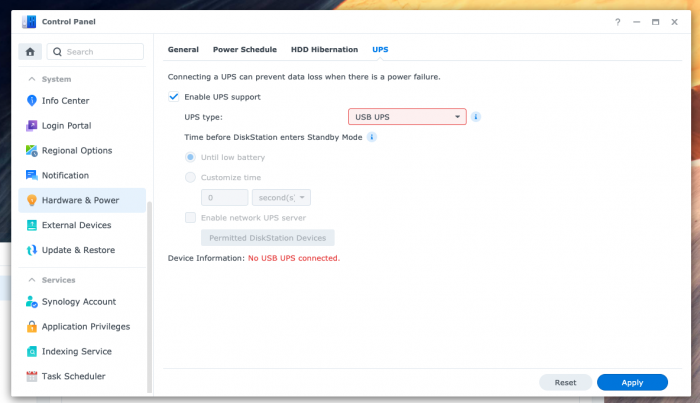
The blank “General” screen in Control Panel is a known bug in the Synology software, I believe.
Not sure what the problem is with the UPS, though.
-Is DSM seeing the UPS there at all?Sorry, was posting from my phone earlier and couldn't see the screenshot you'd posted clearly, "No USB UPS connected"- Is it listed by Synology as a supported device in 7.x?
- Can you see it if you run ‘lsusb’ from the cli?
- Have a look at the console output and see what’s happening when you connect the UPS to the server. Any obvious errors?
-
56 minutes ago, scoobdriver said:
Try mount -t vfat ……
That was almost it!
mount -t vfat /dev/synoboot1 /mnt/synoboot1...would fail with the same error.
But:
cd /dev mount -t vfat synoboot1 /mnt/synoboot1..works!
You have to be in /dev for it to work 🙄
Found it here after Googling. Which, of course, links back to a post on this forum
This is dumb, I've never seen this sort of behaviour in decades of using posix systems.
-
1
-
-
For some reason, since updating to the latest redpill version (Monday 13th of September), I can no longer mount /dev/synoboot1 in my running server. I'm absolutely certain I did this recently to edit the grub.cfg and update the MAC addresses in there, but I get the following now:
bash-4.4# mount /dev/synoboot1 /mnt/synoboot1 mount: /mnt/synoboot1: wrong fs type, bad option, bad superblock on /dev/synoboot1, missing codepage or helper program, or other error.It's not the end of the world, but it was handy being able to edit the bootloader stick when it was still plugged in inside the server and just reboot it for changes, rather than having to take it out and edit it in another machine.
Am I doing something wrong?
FWIW, disk still thinks the device is valid:
bash-4.4# fdisk /dev/synoboot Welcome to fdisk (util-linux 2.33.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): p Disk /dev/synoboot: 14.9 GiB, 16018046976 bytes, 31285248 sectors Disk model: USB Flash Drive Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0xf110ee87 Device Boot Start End Sectors Size Id Type /dev/synoboot1 * 2048 100351 98304 48M 83 Linux /dev/synoboot2 100352 253951 153600 75M 83 Linux /dev/synoboot3 253952 262143 8192 4M 83 Linux -
40 minutes ago, spikexp31 said:
However, I would have one question because that is not clear to me for now.
Reading earlier comments, I saw that onboard Nics on micro gen8 are not supported for bare-metal install but would it work with vmxnet3.ko drivers under ESXI ?
or the hardware incompatibility is also true with ESXI ?
I have currently a P222 controller in the pcie port...I will have to choose If I want network or raid controller..
A few people have managed to get the tg3 driver (for the onboard Broadcom NIC) added to the boot image on a Gen8, baremetal. Read back the last page or two looking posts by scoobdriver and pocopico.
-
1
-
-
9 minutes ago, Aigor said:
The worst part of process 🤣 i have almost 18 Tbyte to backup
Of course the alternative is to wait for this to be formally released and don't take the risk with production data. Or live dangerously.
-
1
-
-
1 hour ago, Aigor said:
Forgive me if i'm dumb, if i would build loader for 7.01 for HP Gen8 Microserver, how should i do?
Can i perform direct upgrade in place without lost config and data?
Should i backup, perform new installation and restore?
Which process should be better with balance between data integrity and less operation?Regardless of what upgrade/migration/fresh build approach you take, you should always take a backup of your data first. The developers do not recommend this release for production use in it's current state and you should not risk your data with it.
With that in mind...
It's not possible to do an "upgrade" from 6.2.3/Jun's loader (which I assume you're on at present) in the sense of invoking an upgrade in the DSM Control Panel. However, most people on here refer to the following procedure as "upgrade", although it's really a migration:
- take a backup
- shutdown your server
- remove the Jun's bootloader USB stick
- replace with a new USB stick with the redpill loader on it, built with your SN, MAC address(es) and VID/PID in the grub.cfg
- boot the server on the redpill stick
- the server should dchp and you can either use the Syno tool to find it, or look at the DHCP logs on your router and see what IP address it gets
- browse to http://<your_server_ip>:5001, if it's gone well you should see the Syno web page telling you that it's found disks from another Synology server and offering to migrate them for you. Run through the migration process and you should have 7.x server with all your existing data, settings and packages preserved
Did I mention to TAKE A BACKUP first?
-
2
-
-
Hmmm, rather than grep'ing through /var/log/synoboot.log I looked in dmesg output instead:
$ dmesg | grep ttyS0 [ 0.000000] Command line: BOOT_IMAGE=/zImage mac2=001B78579575 mac1=001B78579574 netif_num=1 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=0 vid=0x05dc syno_hdd_detect=0 pid=0xc75c console=ttyS0,115200n8 elevator=elevator sn=xxxxLWNxxxxx root=/dev/md0 earlyprintk loglevel=15 log_buf_len=32M syno_port_thaw=1 HddHotplug=0 withefi syno_hw_version=DS3615xs vender_format_version=2 [ 0.000000] Kernel command line: BOOT_IMAGE=/zImage mac2=001B78579575 mac1=001B78579574 netif_num=1 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=0 vid=0x05dc syno_hdd_detect=0 pid=0xc75c console=ttyS0,115200n8 elevator=elevator sn=xxxxLWNxxxxx root=/dev/md0 earlyprintk loglevel=15 log_buf_len=32M syno_port_thaw=1 HddHotplug=0 withefi syno_hw_version=DS3615xs vender_format_version=2 [ 0.000000] console [ttyS0] enabled, bootconsole disabled [ 0.630529] <redpill/cmdline_delegate.c:389> Cmdline: BOOT_IMAGE=/zImage mac2=001B78579575 mac1=001B78579574 netif_num=1 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=0 vid=0x05dc syno_hdd_detect=0 pid=0xc75c console=ttyS0,115200n8 elevator=elevator sn=xxxxLWNxxxxx root=/dev/md0 earlyprintk loglevel=15 log_buf_len=32M syno_port_thaw=1 HddHotplug=0 withefi syno_hw_version=DS3615xs vender_format_version=2 [ 0.634385] <redpill/cmdline_delegate.c:401> Param #9: |console=ttyS0,115200n8| [ 0.634552] <redpill/cmdline_delegate.c:296> Option "console=ttyS0,115200n8" not recognized - ignoring [ 0.641367] <redpill/uart_swapper.c:410> Swapping ttyS1<=>ttyS0 started [ 0.649547] <redpill/uart_swapper.c:427> ======= OUTPUT ON THIS PORT WILL STOP AND CONTINUE ON ANOTHER ONE (swapping ttyS1 & ttyS0) ======= [ 0.649844] <redpill/uart_swapper.c:429> ### LAST MESSAGE BEFORE SWAP ON "OLD" PORT ttyS1<=>ttyS0 [ 0.650045] <redpill/uart_swapper.c:433> ### FIRST MESSAGE AFTER SWAP ON "NEW" PORT ttyS1<=>ttyS0 [ 0.650048] <redpill/uart_swapper.c:340> Shutting down physical port iobase=0x2f8 (mapped to ttyS0) [ 0.650049] <redpill/uart_swapper.c:318> Checking if port iobase=0x2f8 irq=3 (mapped to ttyS0) active [ 0.678077] <redpill/uart_swapper.c:461> ======= OUTPUT ON THIS PORT CONTINUES FROM A DIFFERENT ONE (swapped ttyS1 & ttyS0) ======= [ 0.681962] <redpill/uart_swapper.c:464> Swapping ttyS1 (curr_iob=0x2f8) <=> ttyS0 (curr_iob=0x3f8) finished successfully [ 1.942332] <redpill/sanitize_cmdline.c:102> Sanitized cmdline to: BOOT_IMAGE=/zImage mac2=001B78579575 mac1=001B78579574 netif_num=1 earlycon=uart8250,io,0x3f8,115200n8 syno_hdd_powerup_seq=0 syno_hdd_detect=0 console=ttyS0,115200n8 sn=sn=xxxxLWNxxxxx root=/dev/md0 HddHotplug=0 withefi syno_hw_version=DS3615xs vender_format_version=2 [ 2.984023] serial8250: ttyS0 at I/O 0x3f8 (irq = 4) is a 16550A
My system appears to be behaving the same as yours after all, and calling uart_swapper. But in my case the output continues on the iLO VSP ¯\_(ツ)_/¯
Not sure I trust the content of /var/log/synoboot.log any more. I think it may be sanitised.
-
@scoobdriver @altas I've just had a grep through /var/log/synobootup.log on my system and can't see any reference to 'redpill/uart_swapper', which seems to be the culprit for you two.
Here's the code, see if you can figure out what's going on:
https://github.com/RedPill-TTG/redpill-lkm/blob/master/internal/uart/uart_swapper.c
It seems to be a module written to "fix" behaviour in some kernels that erroneously swaps the console output to an alternate tty by swapping it back again. For some reason this is being called unnecessarily on your systems, and swapping the console output away from your active, functioning virtual tty. FYI, I'm running a bromolow 7.0.1-RC1 42214 image.
I don't know why this is happening for you, or why it's not happening for me. Closer inspection of the code (or explanation from @ThorGroup) may help.
-
1
-
-
24 minutes ago, scoobdriver said:
@WiteWulf I know you use the serial port emulator on ILO 4 .
I have my GEN8 now booting with the onboard NIC and discoverable , but my serial log stop at :
[ 2.758884] <redpill/uart_swapper.c:427> ======= OUTPUT ON THIS PORT WILL STOP AND CONTINUE ON ANOTHER ONE (swapping ttyS1 & ttyS0) =======
[ 2.762939] <redpill/uart_swapper.c:429> ### LAST MESSAGE BEFORE SWAP ON "OLD" PORT ttyS1<=>ttyS0
Are you doing something to resolve this ?
No, it's weird, someone else (@altas?) contacted me with exactly the same problem. Mine "just works" and continues to output to the vsp, it even offers me a login prompt. I'm running with Advanced iLO license on my system (only cost me £10 on eBay) which also allows for virtual boot media.
Just to be clear, to access the console, I:
- ssh to the ilo, ie. 'ssh Administrator@diskstation-ilo'
- from the </>hpiLO-> prompt I issue the 'vsp' command to launch the virtual serial port
- I don't login if all I want to see is console output
% ssh Administrator@diskstation-ilo Administrator@diskstation-ilo's password: User:Administrator logged-in to diskstation-ilo.osx.ninja(192.168.1.11 / FE80::D2BF:9CFF:FE45:F58A) iLO Advanced 2.78 at Apr 28 2021 Server Name: diskstation-iLO Server Power: On </>hpiLO-> vsp Virtual Serial Port Active: COM1 Starting virtual serial port. Press 'ESC (' to return to the CLI Session. Password: [ 6968.613699] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda [ 6968.614727] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb [ 6968.614728] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 6968.616323] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc [ 6968.616324] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 6968.617563] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd [ 6968.617564] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 6968.859345] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop
-
Just now, Fallen said:
When you say "NICs in my config are online", you're reffering to the onboard ones?
I watched this thread from the start and everything you posted. I'm in the same situation, gen8 baremetal, 16gb + 1230v2, but with onboard nics.
I have jun's loader + dsm 6.2.3.
I tried redpill, but i was unsuccesfull, like you, because my onboard nics were offline.What should i try next?
No, if you look in my sig (I'm aware it doesn't display on mobile devices, sorry) you'll see I'm running a PCIe HP NC360T dual GigE NIC instead of the onboard Broadcom adapter (which I have disabled). It should be possible to add the correct driver (tg3.ko, iirc) to a boatloader image and some folk in this thread have been working on it.
-
I'm also seeing this one appear less regularly:
[ 2393.339671] <redpill/smart_shim.c:340> ATA_CMD_ID_ATA confirmed SMART support - noop [ 2393.380207] <redpill/smart_shim.c:794> Handling ioctl(0x30d) for /dev/sdc [ 2393.413945] <redpill/smart_shim.c:809> sd_ioctl(0x30d) - not a hooked ioctl, noop
0x30d appears to be querying the HDD for it's identity, HDIO_GET_IDENTITY, ie. the disk serial number.
Again, mdadm seems happy with the state of my disks/volumes, as does Storage Manager in DSM (which is really just a GUI frontend to mdadm anyway).
*edit*
Indeed, issuing 'hdparm -i /dev/sde' from the command line immediately results in the following to appear in the console output:
[ 3550.279075] <redpill/smart_shim.c:794> Handling ioctl(0x304) for /dev/sde [ 3550.312542] <redpill/smart_shim.c:809> sd_ioctl(0x304) - not a hooked ioctl, noop [ 3550.349957] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sde [ 3550.383866] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop [ 3550.424725] <redpill/smart_shim.c:794> Handling ioctl(0x30d) for /dev/sde [ 3550.457940] <redpill/smart_shim.c:809> sd_ioctl(0x30d) - not a hooked ioctl, noop
...although hdparm itself outputs the following with no error:
bash-4.4# hdparm -i /dev/sde /dev/sde: Model=OCZ-VERTEX2, FwRev=1.37, SerialNo=OCZ-8N58I75919N424M6 Config={ Fixed } RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=4 BuffType=unknown, BuffSize=unknown, MaxMultSect=16, MultSect=1 CurCHS=16383/16/63, CurSects=16514064, LBA=yes, LBAsects=117231408 IORDY=on/off, tPIO={min:120,w/IORDY:120}, tDMA={min:120,rec:120} PIO modes: pio0 pio1 pio2 pio3 pio4 DMA modes: mdma0 mdma1 mdma2 UDMA modes: udma0 udma1 udma2 udma3 udma4 udma5 *udma6 AdvancedPM=no WriteCache=disabled Drive conforms to: unknown: ATA/ATAPI-2,3,4,5,6,7 * signifies the current active modeSomething in DSM is querying the storage devices in a way that smart_shim isn't equipped to handle, or doesn't like.
Having said that, these don't seem to be errors. Did someone just leave debug turned on?
Yeah, having had a quick look over smart_shim.c itself, it appears that the actions undertaken on lines 794 and 809 (as referenced in the logging output) are announcing that it's not a special drive command that needs to be handled by the shim, and should simply be proxied to the device as-is:
It's code that's meant to emulate SMART on device that don't have it natively, which the disks in my system do. Same goes for the ATA_CMD_ID_ATA messages, it's confirming that a valid SMART response was received from the drive and there's no need to handle it with the shim.
I'm convinced this is simply a case of excessive logging, and nothing's actually going wrong.
-
I know, but they're messages (not errors) regarding ioctl interactions with your SATA HDDs, nothing to do with your USB stick. I think you're conflating two different issues.
-
4 minutes ago, ct85msi said:
@WiteWulfthis is the error I was talking about. It mounts the usb boot stick and dmesg gives me this error.
I opened a ticket https://github.com/RedPill-TTG/redpill-load/issues/30
I'm not convinced. I'm not seeing any errors on my system regarding the USB stick (it's not visible once booted, as it should be), and the messages are all regarding the storage devices on my system (sda, sdb, sdc and sdd are the SATA HDDs, while sde is the SSD).
-
I just booted my baremetal Gen8 off an image created with @ThorGroup's latest redpill code (as of this release), and haydibe's 0.8 toolchain. This is using bromolow 7.0.1-RC1 (42214) It booted successfully, all disks and NICs in my configuration are online, but I'm seeing the following on the serial console every 10-60 seconds (it is not occurring on a regular pattern):
Quote[ 446.593174] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sda
[ 446.626781] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop
[ 446.666090] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdb
[ 446.700210] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop
[ 446.740036] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdc
[ 446.773960] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop
[ 446.812469] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sdd
[ 446.846153] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop
[ 446.884977] <redpill/smart_shim.c:794> Handling ioctl(0x2285) for /dev/sde
[ 446.918111] <redpill/smart_shim.c:809> sd_ioctl(0x2285) - not a hooked ioctl, noop
[ 446.965213] <redpill/smart_shim.c:794> Handling ioctl(0x31f) for /dev/sde
The messages appear in clumps for each SATA device in my system (four HDDs and SSD used for read cache). It's as if something is trying to query the disks at a low level and failing as the redpill smart_shim doesn't handle it (hence the 'noop').
0x31f appears to be "HDIO_DRIVE_CMD execute a special drive command"
0x2285 is SG_IO, which appears to be used for sending SCSI commands to a device
The system appears to be fully functional other than the logging described above. NB these messages were not present in the console output on ThorGroup's previous release.
*edit*
My guess is it's to do with this:
SCSI drives monitoring subsystem This is more of a dev-only functionality, but lies in the core of all the features described above. In short, Linux kernel contains a mechanism for publishing and subscribing to events. Unfortunately it's a rather new and niche subsystem. The SCSI driver, as one of the oldest parts of the Linux kernel, doesn't support the notifications. In order to react to new drives being connected to the system we developed an extension for the SCSI driver adding that functionality. We will probably pursue upstreaming of these changes, so one day they can land in the kernel natively. For details see the following commits: https://github.com/RedPill-TTG/redpill-lkm/commit/098bae23fe21ccd495e57b846539704899fda639 (add the notification subsystem) https://github.com/RedPill-TTG/redpill-lkm/commit/ccc58c0883c3f0cc8a8599918cc0d5cd9491f678 (extract common SCSI functionality to a submodule)EDIT: see my follow up post on the next page, I think this is just a case of excessive debug logging, and nothing's actually wrong here.

RedPill - the new loader for 6.2.4 - Discussion
in Developer Discussion Room
Posted
Thanks for the continued hard work developing and supporting this, @haydibe, it's an invaluable resource for those community members for whom maintaining docker is a stretch of the *nix skills. The streamlining of the build process also leaves a lot more time for us to get on with solving compatibility issues and bugs with the redpill tools themselves, so everyone wins!