

WiteWulf
-
Posts
423 -
Joined
-
Last visited
-
Days Won
25
Posts posted by WiteWulf
-
-
Just migrated to 7.0.1-RC1 on my baremetal HP Gen8 Microserver with NC360T NIC. The upgrade/migration went very smoothly apart from a similar issue I had going from 6.2.3 to 6.2.4 in that the connected NIC went back to DHCP and I had to set it up again with it's static details. Everything seems good so far. Now I wonder if that influxdb docker still crashes it 🤔🤣
-
7 minutes ago, scoobdriver said:
@WiteWulf Did you happen to try the same with the on onboard NIC ?
when I get home in a few days I will try on mine if not. (Will try with a ‘standard’ build. And also with kg3.ko added.I haven't, but the comments on the previous page from MastaG suggested it was failing for them, and flyride confirmed that the drivers for the onboard NIC were included as an addition in Jun's bootloader and are not included at present in redpill. There was mention of adding a "tg3" driver to redpill, but I've not found any more information on that (it seems the forum search doesn't like such small search terms).
-
That explains why my dashboards were all empty when I tried it with 2.x, then
")
Ah, the joys of upgrading database containers for docker apps. This is why I typically take an "if it ain't broke, don't fix it" approach to stuff at home...
-
Following up on the NIC compatibility on baremetal HP Gen8 Microserver: I've just booted off redpill 7.0 stick and it found the PCIe NC360T NIC interfaces successfully (I didn't bother installing, though). Gonna test with 7.0.1 now and see if I can actually install it.
-
I updated Grafana (which is accessing the influxdb) to 6.7.6 and influxdb to 1.9.3 and that seemed to go well without crashing, but then when I stopped influxdb it kernel panic'd again.
1.9.3 is the latest version of the 1.x train, so I'm going to try upgrading to later major version release and see if that helps matters...
...
Further experimentation with updating the version of influxdb suggests that the kernel panics are always either related to the influxdb process itself or containers-shim, and seem to occur when either starting or stopping the influxdb container. If the container starts up without precipitating a kernel panic it appears to continue to run without error indefinitely.
-
I made some progress with the spontaneous reboots I've been seeing since migrating to 6.2.4 but spun it off into a separate topic as it's not entirely relevant to this thread:
-
Morning all, I'm posting this as a new topic as, although it's relevant to and following an installation of a redpill bootloader, I don't think it's entirely relevant to the main thread. I hope that was the right decision.
I recently migrated my baremetal HP Gen8 Microserver (more details in my sig) from Jun's bootloader and 6.2.3 to redpill and 6.2.4. While the system is stable and fully functional once booted, I observed that it can sometimes be unstable immediately after booting into DSM and have seen it spontaneously reboot on a few occasions. I figured out how to get at the serial console through iLO yesterday and have tracked the problem down to docker causing kernel panics.
Below are three captures from the console:
[ 103.818908] IPv6: ADDRCONF(NETDEV_CHANGE): dockerc0d00b9: link becomes ready [ 103.854064] docker0: port 1(dockerc0d00b9) entered forwarding state [ 103.885457] docker0: port 1(dockerc0d00b9) entered forwarding state [ 103.923967] IPv6: ADDRCONF(NETDEV_CHANGE): docker3a8cc71: link becomes ready [ 103.958558] docker0: port 2(docker3a8cc71) entered forwarding state [ 103.990058] docker0: port 2(docker3a8cc71) entered forwarding state [ 105.796257] aufs au_opts_verify:1571:dockerd[17060]: dirperm1 breaks the protection by the permission bits on the lower branch [ 118.904833] docker0: port 1(dockerc0d00b9) entered forwarding state [ 119.032982] docker0: port 2(docker3a8cc71) entered forwarding state [ 138.152539] Kernel panic - not syncing: Watchdog detected hard LOCKUP on cpu 7 [ 138.188407] CPU: 7 PID: 19491 Comm: influxd Tainted: PF O 3.10.105 #25556 [ 138.225421] Hardware name: HP ProLiant MicroServer Gen8, BIOS J06 04/04/2019 [ 138.259973] ffffffff814c904d ffffffff814c8121 0000000000000010 ffff880109bc8d58 [ 138.296392] ffff880109bc8cf0 0000000000000000 0000000000000007 000000000000001b [ 138.333751] 0000000000000007 ffffffff80000001 0000000000000010 ffff8801038d8c00 [ 138.371395] Call Trace: [ 138.383636] <NMI> [<ffffffff814c904d>] ? dump_stack+0xc/0x15 [ 138.412498] [<ffffffff814c8121>] ? panic+0xbb/0x1ce [ 138.436526] [<ffffffff810a0922>] ? watchdog_overflow_callback+0xb2/0xc0 [ 138.469406] [<ffffffff810b152b>] ? __perf_event_overflow+0x8b/0x240 [ 138.499832] [<ffffffff810b02d4>] ? perf_event_update_userpage+0x14/0xf0 [ 138.532041] [<ffffffff81015411>] ? intel_pmu_handle_irq+0x1d1/0x360 [ 138.563004] [<ffffffff81010026>] ? perf_event_nmi_handler+0x26/0x40 [ 138.593865] [<ffffffff81005fa8>] ? do_nmi+0xf8/0x3e0 [ 138.618725] [<ffffffff814cfa53>] ? end_repeat_nmi+0x1e/0x7e [ 138.647390] <<EOE>> [ 138.658238] Rebooting in 3 seconds..
..and again:
[ 120.861792] IPv6: ADDRCONF(NETDEV_CHANGE): docker81429d6: link becomes ready [ 120.895824] docker0: port 2(docker81429d6) entered forwarding state [ 120.926580] docker0: port 2(docker81429d6) entered forwarding state [ 120.997947] IPv6: ADDRCONF(NETDEV_CHANGE): docker28a2e17: link becomes ready [ 121.032061] docker0: port 1(docker28a2e17) entered forwarding state [ 121.063120] docker0: port 1(docker28a2e17) entered forwarding state [ 136.106729] docker0: port 1(docker28a2e17) entered forwarding state [ 136.518407] docker0: port 2(docker81429d6) entered forwarding state [ 191.452302] Kernel panic - not syncing: Watchdog detected hard LOCKUP on cpu 3 [ 191.487637] CPU: 3 PID: 19775 Comm: containerd-shim Tainted: PF O 3.10.105 #25556 [ 191.528112] Hardware name: HP ProLiant MicroServer Gen8, BIOS J06 04/04/2019 [ 191.562597] ffffffff814c904d ffffffff814c8121 0000000000000010 ffff880109ac8d58 [ 191.599118] ffff880109ac8cf0 0000000000000000 0000000000000003 000000000000002c [ 191.634943] 0000000000000003 ffffffff80000001 0000000000000010 ffff880103817c00 [ 191.670604] Call Trace: [ 191.682506] <NMI> [<ffffffff814c904d>] ? dump_stack+0xc/0x15 [ 191.710494] [<ffffffff814c8121>] ? panic+0xbb/0x1ce [ 191.735108] [<ffffffff810a0922>] ? watchdog_overflow_callback+0xb2/0xc0 [ 191.768203] [<ffffffff810b152b>] ? __perf_event_overflow+0x8b/0x240 [ 191.799789] [<ffffffff810b02d4>] ? perf_event_update_userpage+0x14/0xf0 [ 191.834349] [<ffffffff81015411>] ? intel_pmu_handle_irq+0x1d1/0x360 [ 191.865505] [<ffffffff81010026>] ? perf_event_nmi_handler+0x26/0x40 [ 191.897683] [<ffffffff81005fa8>] ? do_nmi+0xf8/0x3e0 [ 191.922372] [<ffffffff814cfa53>] ? end_repeat_nmi+0x1e/0x7e [ 191.950899] <<EOE>> [ 191.961095] Rebooting in 3 seconds..
After completing the reboot it did it again:
[ 140.355745] aufs au_opts_verify:1571:dockerd[18688]: dirperm1 breaks the protection by the permission bits on the lower branch [ 145.666134] docker0: port 3(docker9ee2ff2) entered forwarding state [ 150.217495] aufs au_opts_verify:1571:dockerd[18688]: dirperm1 breaks the protection by the permission bits on the lower branch [ 150.278812] device dockerbc899ad entered promiscuous mode [ 150.305436] IPv6: ADDRCONF(NETDEV_UP): dockerbc899ad: link is not ready [ 152.805689] IPv6: ADDRCONF(NETDEV_CHANGE): dockerbc899ad: link becomes ready [ 152.840264] docker0: port 5(dockerbc899ad) entered forwarding state [ 152.870670] docker0: port 5(dockerbc899ad) entered forwarding state [ 154.476203] docker0: port 4(docker07f3e3e) entered forwarding state [ 167.931582] docker0: port 5(dockerbc899ad) entered forwarding state [ 194.017549] Kernel panic - not syncing: Watchdog detected hard LOCKUP on cpu 2 [ 194.052575] CPU: 2 PID: 19580 Comm: containerd-shim Tainted: PF O 3.10.105 #25556 [ 194.094270] Hardware name: HP ProLiant MicroServer Gen8, BIOS J06 04/04/2019 [ 194.128400] ffffffff814c904d ffffffff814c8121 0000000000000010 ffff880109a88d58 [ 194.164811] ffff880109a88cf0 0000000000000000 0000000000000002 000000000000002b [ 194.201332] 0000000000000002 ffffffff80000001 0000000000000010 ffff880103ee5c00 [ 194.238138] Call Trace: [ 194.250471] <NMI> [<ffffffff814c904d>] ? dump_stack+0xc/0x15 [ 194.279225] [<ffffffff814c8121>] ? panic+0xbb/0x1ce [ 194.304100] [<ffffffff810a0922>] ? watchdog_overflow_callback+0xb2/0xc0 [ 194.337400] [<ffffffff810b152b>] ? __perf_event_overflow+0x8b/0x240 [ 194.368795] [<ffffffff810b02d4>] ? perf_event_update_userpage+0x14/0xf0 [ 194.401338] [<ffffffff81015411>] ? intel_pmu_handle_irq+0x1d1/0x360 [ 194.432957] [<ffffffff81010026>] ? perf_event_nmi_handler+0x26/0x40 [ 194.464708] [<ffffffff81005fa8>] ? do_nmi+0xf8/0x3e0 [ 194.488902] [<ffffffff814cfa53>] ? end_repeat_nmi+0x1e/0x7e [ 194.517219] <<EOE>> [ 195.556746] Shutting down cpus with NMI [ 195.576047] Rebooting in 3 seconds..
Following the third reboot I logged into the DSM web UI as quickly as I could after booting and stopped all the running containers. It's been stable since then.
Each time it kernel panic'd in these three examples it was something to do with docker: either containers-shim or influxd (which is a process in an InfluxDB container).
The influxdb container is running off a pretty ancient image version (1.77), so I'm going to try updating the image and see if it's any more stable. I'll update with results.
-
Ah, so the drivers were never actually in the Synology firmware image at all, then, they were part of Jun's image? I installed the NC360T pcie card as, at the time, it was the only way to retain networking and upgrade to 6.2.2, but it was strongly suggested at the time that this situation would persist after 6.2.2. It all makes more sense when you put it like that.
With drivers for the Gen8 onboard NICs never part of the Synology image it makes sense that they're not seen by 6.2.4 or later, and that Gen8 users wanting to remain on baremetal will need to add a PCIe NIC to their system.
-
12 minutes ago, Kouill said:
Yes I use Minitool Partition Wizard to make the first partition active, it boots but still have no network with 6.2.4 and 7.0.1
I had the same problem with my Gen8: wouldn't boot off the redpill stick until I marked the first partition active.
It's interesting to hear you're also seeing no NIC with 6.2.4 or 7.0.1. Are you trying to use the onboard NICs? If so it definitely sounds like they left out the drivers again after 6.2.3
I'm running 6.2.4 with an HP NC360T pcie dual-nic and it's working fine.
-
Well, that's annoying; did they remove the driver again in 6.2.4 and 7.x, I wonder? I'll try pulling the NC360T card out of my Gen8 and booting with a fresh loader stick with the correct MAC address in the config tomorrow when I have chance. I'd like to confirm if the onboard NIC is supported, or if the return to functionality in 6.2.3 was just a blip.
-
 1
1
-
-
3 minutes ago, MastaG said:
Would it be possible to share your image, so I can give it a shot?
And can you also point me to the dockerfiles so I can see if he puts anything special in the user_config?
Sure, I'll DM you a link to the image
Here's the latest toolchain docker script:
-
I'm using the docker method and scripts provided by haydibe, rather than doing it myself (macOS isn't the easiest environment for compiling non-Mac stuff in), and 6.2.4 compiles and runs just fine on my baremetal Gen8 (although I'm not using the onboard NIC, but this shouldn't be an issue from what scoobdriver said).
-
7 minutes ago, MastaG said:
I couldn't find an option to make the iLO show the serial output instead of what's on the screen.
I've tried setting different consoles by editing the grub cmd line, like ttyS0, ttyS1, tty0 and tty1 but it refuses to show anything after "Booting the kernel."
You can get at the serial console by following this guide (which I didn't know was possible with the iLO until I Googled it just now, so that's good to know!):
https://serverfault.com/questions/830748/how-to-enable-and-use-the-serial-terminal-of-a-hp-microserver-gen9(Confirmed works on my Gen8, they both have the same iLO4 card in them)
-
2 minutes ago, scoobdriver said:
I believe this changed. 6.2.3 supports onboard nic. I use the two standard nics on my gen 8 with no modifications.
Oh, that's cool, didn't realise that! That opens up the possibility of getting a better/additional HBA to go in there at some point...
-
11 minutes ago, MastaG said:
So I got a little further.
...
Now using the redpill.ko built by the DSM 7.0 toolchain (and stripped) my Microserver Gen8 doesn't reboot any longer.
It now just sits there at the "Booting the kernel." screen.
However I can't see any DHCP being requested and I still don't have any console output.
Any ideas?
What version of DSM and bootloader where you previously running, and do you have a PCIe NIC in your Gen8? Synology dropped the driver that was compatible with the onboard NIC a few versions ago (6.2.2, iirc) and users needed to either move to ESXi and vmxnet, or else fit a compatible PCIe NIC and disable the onboard NIC.No longer the case, apparently. Driver support for the onboard NIC came back with 6.2.3
-
25 minutes ago, scoobdriver said:
Do you notice this makes any difference on gen8 Microserver (e3-1275 v2) ?
It makes no noticeable difference to performance, as it scales back up on demand, but as to reducing power consumption I honestly can't say. The PDU the server is connected to isn't sensitive enough to even notice the Gen8 is powered on or off. The only thing it ever really notices is when the PS4 Pro is on and working hard. I could stick a meter on it and measure it properly, but I'm really not that bothered, I just like to think that I'm doing at least something to minimise the impact of having a Xeon sat there doing very little for 90% of the time. I would imagine spinning down the 4 HDDs would have more impact, but the server's constantly logging monitoring data for a few bits and pieces and the HDDs wouldn't stay off for more than a few minutes, and spinning them up and down that much could shorten their life span.
-
1
-
-
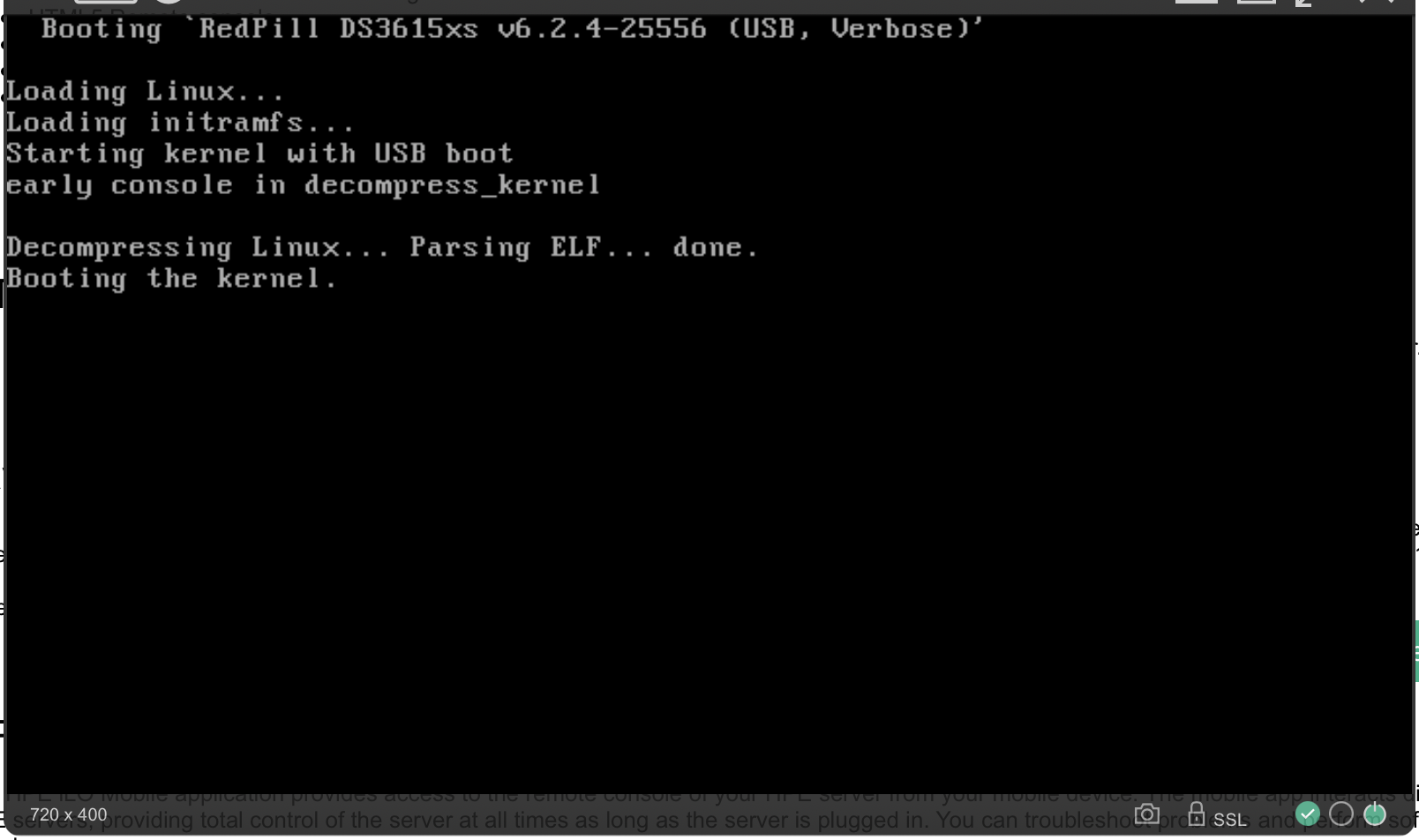
@MastaG I've successfully installed 6.2.4 baremetal on a Gen8 and can confirm that console output stops at what you're seeing with "Booting the kernel.". It should eventually bring up a network interface and DHCP, though, not reboot. I've not tried 7.x yet, so can't comment on that. This is my console that's been booted into DSM for 6hrs+
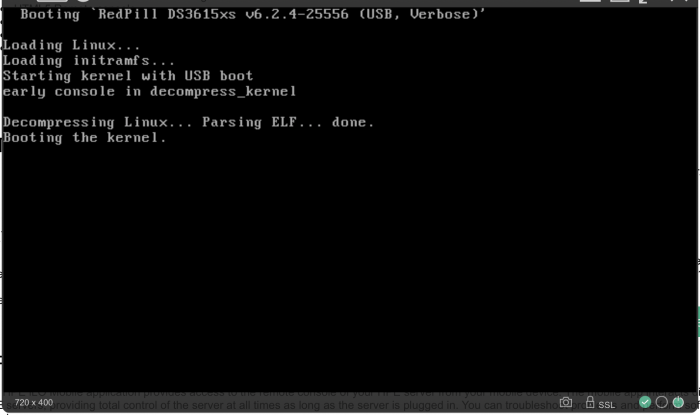
-
1 hour ago, titoum said:
for those going fresh don't forget to setup your gouvernor to powersaver again
")
Good call! It's so long since I did a fresh install of xpenology I'd forgotten all about that. I set mine to conservative, fwiw, as this box does some Plex transcoding from time to time.
More info here for those who were unaware of this:
-
1 minute ago, shibby said:
without luck.
Any suggestion how to upgrade 6.2.4 to 7.0?
You haven't stated what procedure you're following, how it's failing or what hardware you have. If you want help you need to give people a lot more information.
-
Question: I have an HP NC360T PCIe NIC card in my system. I'm only using one interface, so have only declared one of them in my user_config.json. Is this a problem?
I notice in Control Panel in DSM that two interfaces are detected, and both have the same MAC address (the one I declared for the interface that I'm actually using). Likewise, running 'ifconfig' from the cli reports two interfaces with the same MAC address. I know that an OSI 7-layer network stack shouldn't have an issue with multiple interfaces on a system having the same MAC address (it's standard on Sun machines, for example), but will DSM complain about this?
Next time I rebuild the boot stick I'll be sure to declare both interfaces, but am just curious for now.
-
I had a couple more odd reboots of my system this morning. They always seem to occur shortly after a reboot. I'd restarted the system after updating firmware on the iLO card in my system, and the server rebooted almost immediately after it had booted into DSM (I think it managed about 3 minutes uptime), then rebooted again shortly afterwards. Looking in /var/log/messages for entries just before it reboots each time there's nothing that stands out, other than that it's typically doing stuff you'd expect after the system had just rebooted: starting docker containers and registering certificates for a couple of webhosts I have on the server
-
7 hours ago, Franks4fingers said:
Can I ask a quick q on this please. What OS were you using to craft the image in the first place and get your loader operating successfully? I have a spare Optiplex 9020 that I am thinking to re-purpose for this instead of using my windows based surface.
I built the tool chain, created the image and flashed it to USB stick on macOS, but as it’s all actually built inside a docker container that’s not all that relevant. If you’re interested in doing the same, Amoureux wrote a simple guide for the docker/tool chain/image part on macOS, just search through this thread and make sure you get the latest version of haydibe’s tool chain (0.7.2 at this point, I think), not the one Amoureux links to. -
Excellent point! I did not notice that

I'll be quiet now...
-
46 minutes ago, abesus said:
Ive successfully built and use loader for 980+. Unfortunatelly, I'm using Xeon E3-1265L V4 and there were many errors in system logs. System was hanging-up every few hours. It looks like DS918+ is using some new CPU/GPU instructions that are missing in my old xeon.
After that I've tried DS3615xs loader. DSM 7.0 is in beta stage so I've tried 6.2.4. Everything is working great except moments. How can I find valid SN/MAC combination for ds3615xs?
DS918+ isn't compatible with that CPU. I've got the same CPU in an HP Microserver and can only use the Bromolow images, such as DS3615XS.
You can see what CPU type matches Bromolow and Apollolake (the versions available on xpenology). Ignore the core count and RAM, though, as xpenology will use whatever it's given (although DSM will only report the CPU it's intended for, not what's actually fitted).
RedPill - the new loader for 6.2.4 - Discussion
in Developer Discussion Room
Posted · Edited by WiteWulf
Well, surprise surprise... 🙄
Actually, this is worse than it was on 6.2.4 now. It's panicking as soon as I start a different container this time (a linked pair of librenms and mysql containers). I've a suspicion as to what may be consistent between these containers that's different to the containers that are not causing crashes....watch this space...
...
Oh, this is ridiculous: just loading the docker app in the web UI is throwing a kernel panic now 🙄