

flyride
-
Posts
2,438 -
Joined
-
Last visited
-
Days Won
127
Everything posted by flyride
-
Synology's cache is just the open source flashcache: https://en.wikipedia.org/wiki/Flashcache All right. Now we want to try and mount the filesystem and if successful, have you start pulling files off of it. It might not mount, and/or those files might be garbage when they get to the part of the filesystem serviced by /dev/md2, so you need to verify the files that you copy off. Since you are using btrfs, it should detect corruption and alert you through the DSM web interface, so please monitor that too. Note that even if you are getting a lot of good data off the filesystem, some files are very likely to be corrupted. # mount -o ro,norecovery /dev/vg1/volume_1 /volume1
-
I think /dev/md3 is your cache, which we really don't care about at this point. The lvm is reporting all its parts are present. Now we want to activate it. # vgchange -ay
-
FWIW, I am no LVM expert. I don't use SHR and therefore LVM on any of my systems. The problem we need to solve isn't very complicated. But, if you don't like the advice (or someone more knowledgeable on LVM wants to jump in), please respond accordingly. Here's where we are now. The system's logical volumes (syno_vg_reserved_area and volume1) are allocated from a volume group (vg1), which is comprised of the three physical arrays /dev/md2, /dev/md4 and /dev/md5. We know that /dev/md4 and /dev/md5 are in good shape, albeit degraded (because of the missing 10TB drive). /dev/md2 is also activated in degraded mode, but we aren't totally sure it is good because we had to recover a non-optimal drive into the array and also intelligently guess at its position within it. Also, the integrity of the data on that drive is not completely known. When and if we do get the share accessible, we will want to mount it read-only and verify that files are accessible and not corrupted. The system was booted many times where DSM would try to start the lv when /dev/md2 was not available, so somewhere along the line it was flagged as "missing." Now, it is potentially NOT missing (if it is functional), or possibly still missing (if it is corrupted). I think we should avoid booting the system as much as possible, which means trying to correct lvm from the command line. So, here are some next steps: # vgextend --restoremissing vg1 /dev/md2 # lvm vgscan # vgdisplay
-
Thanks. Look in the archive folder (/etc/lvm/archive) and post the file with the newest timestamp, and also one with a date stamp from BEFORE the crash.
-
Ok, sorry for being away so long. Will have some time in the next 24 hours to work on this. I was kinda hoping someone might have come up with some ideas about investigating lvm in my absence. But I built up a test environment to see if it can help at all. In the meantime, please run and post: # pvdisplay -m # cat /etc/lvm/backup/vg1
-
I'm at work and can't help for awhile... A few things have to be sorted out logically - is /dev/md2 in a valid state? If not, the LVM probably won't come up correctly. 2 of 3 PV's are active but I'm not quite sure yet how to prove the array is or is not the cause. We don't want to make any changes to the array since it could be in a bad order, and we can try some options (like pushing the 10TB into slot 11 instead of 10). Anyone who wants to investigate some way to understand the PV down state, and/or how to check a degraded array for quality, please be my guest! I agree with not touching anything or rebooting right now since remapping is not our friend now. If we do get data from it, I advise copying everything off, burning it down and rebuilding. Back in awhile.
-
I cannot remember what I actually tested way back when, but I do know I loaded a 916 image up and it was using the old 3.10.x kernel. But as Jun explicitly identified 4th gen then it must fail somewhere, maybe just transcoding. Since virtually nobody uses 916 I'll change the guide to be conservative. Thanks!
-
# pvdisplay -v
-
# pvdisplay -a
-
Hmmm let's try this # lvm vgscan
-
# pvscan -v -v
-
So far, so good. # cat /etc/fstab # vgchange -ay
-
Neat. # pvs # vgs # lvs # pvdisplay # vgdisplay # lvdisplay
-
Well, it's hero or jackass time. It's been fun trying to figure this out, but that's over now. The huge problem with this recovery is that the ongoing hardware failures have caused the disk devices to renumber on a frequent basis. It makes matching up current state with saved history virtually impossible and basically just created a basket case. To recap, we've done a total of two "irrevocable" things. First we forced /dev/md2 to accept a slightly out of sequence (3TB) disk, which initially made the array mountable. Then, since we were having difficulty resyncing the 10TB disk, we zeroed the superblock (second irrevocable thing) on its /dev/md2 array member, to force it completely out of the array and resync. The resync problem was due to a 6TB disk apparently failing and recovering itself, and we finally saw it fail completely across all the arrays. Neither of these irrevocable things are too much of a problem, except now you have determined that the "good" 10TB drive is failed and removed it from the system, which leaves the "bad" superblock-zeroed 10TB drive as the only path to recover /dev/md2. It is important to be correct about that, as it is possible that the "bad" 10TB drive has corrupted data on it due to the failed resync. And, we can't tell at all what state it is in, because there is no superblock. Working with such a large/complex array, we rely on the array and member metadata to keep things straight (normal procedure). Now we cannot do that either because of the zeroed superblock. We have to try and force the "bad" array member back into the correct position in the array because it no longer knows where to go. If we force create the array now and the device addressing isn't correct (meaning that it doesn't match the RAID order that was extracted from the device numbering), we are virtually certain to lose the array (we can try a couple of obvious permutations, but with 13 disk slots for combinations, the problem is significant). So, before you execute the commands below, be ABSOLUTELY sure that everything is totally stable, and that the active drive names match the drive map, which was derived from your most recent fdisk: Research, cross-check, ask questions, validate anything you see fit. At the end of the day, this is your data, not mine. And frankly, I have never put an array into this position before and cannot easily simulate or test a recovery. If something doesn't match up in your mind, you want a second opinion, or you just don't want to for any reason, do NOT do the following: # mdadm --stop /dev/md2 # mdadm -Cf /dev/md2 -e1.2 -n13 -l5 --verbose --assume-clean /dev/sd[bcdefpqlmno]5 missing /dev/sdk5 -u43699871:217306be:dc16f5e8:dcbe1b0d # cat /proc/mdstat But if everything goes well, you should have a mounted, degraded /dev/md2. Under no circumstances attempt to add or replace a disk to resync it.
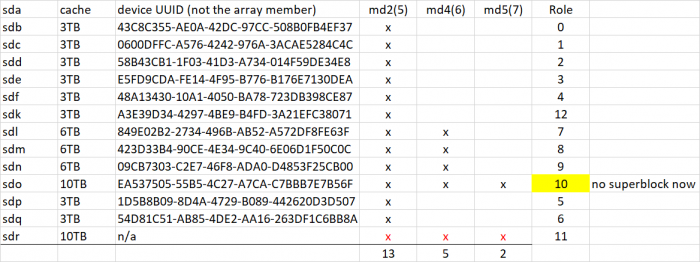
-
Well, that's fun. # mdadm --examine /dev/sd[bcdefklmnopq]5 | egrep 'Role|/dev/sd'
-
G1610T is Ivy Bridge, it should be fine for 916, but not 918.
-
Do you have another 10TB drive available? Assuming not, we'll just have to recover in a degraded state - the next step will be to double-check that we can force the md2 array online reasonably safely with what is left. If there is an unexpected reboot or an additional device failure please let me know. Here's a map of the disks as just presented. # mdadm --detail /dev/md2 # mdadm --detail /dev/md4 # mdadm --detail /dev/md5 # mdadm --examine /dev/sd[bcdefklmnopq]5 | egrep 'Event|/dev/sd'

-
From my first post "your data will patiently wait for you." Please, try and isolate and fix your hardware. Have you replaced every SATA cable? Are you SURE your power is good? You have a LOT of drives. Vibration? Cooling? Or just a drive failure? The fact that multiple drives have gone down suggests that you have some fundamental problem. If mdstat hangs, there's a reason. If there is really a bad drive, narrow it down and take it out of the system. We'll try to work with what's left. But the hardware has to work, otherwise time is being wasted.
-
See if you can sort out what's going on. Maybe a power problem? Cabling, drive physical stability, it can all factor. Advise when you have made a decision. Sorry this might be going down the tubes. I was pretty confident of our success until very recently!
-
# mdadm --manage /dev/md5 --add /dev/sdp7 # mdadm --manage /dev/md4 --add /dev/sdp6 # cat /proc/mdstat
-
Between the last mdstat and your current one, your /dev/sdp went offline - that is one of your 10TB drives. Check all your connections and cables, if they are "stretched" or not stable, secure them. Reboot. Post another mdstat. If you can't get your hardware stable, this is a lost cause. Standing by for status.
-
Woops, /dev/sdr got remapped too, to /dev/sdo. Those commands won't do anything. I don't advise changing it now but your Idx mapping could use some work. # mdadm --zero-superblock /dev/sdo5 # mdadm --manage /dev/md2 --add /dev/sdo5 # cat /proc/mdstat
-
Yes, /dev/sdp moved to /dev/sdg, and /dev/sdo moved to /dev/sdp They are the same drives, show clean and are in the right order still. So now let's try and resync again: # mdadm --zero-superblock /dev/sdr5 # mdadm --manage /dev/md2 --add /dev/sdr5 # cat /proc/mdstat
-
# mdadm --examine /dev/sd[gp]5 Let's confirm the drives look the same despite remapping, then we'll try and resync again.
-
Do you have another SATA port you can plug /dev/sdp into? Maybe take out your SSD and put it there? At the very least, change the SATA cable. There is a hardware failure of some sort we are encountering. We need to get the array resynced because you still have two drives affected, otherwise we will probably lose data. But it would be nice if the array stopped self-immolating. If you can do this, boot and post a new mdstat.


