flyride
-
Posts
2,438 -
Joined
-
Last visited
-
Days Won
127
Everything posted by flyride
-
That looks like a pretty nice low cost card, and with an onboard PCIe switch too.
-
I am pretty sure i350 onboard NIC is e1000e so that should be ok. If you wish to prove with another NIC get yourself a cheap Intel CT $20 and try that.
-
Also be sure you are setting up Legacy BIOS boot (not UEFI) with 1.03b. See more here: https://xpenology.com/forum/topic/13333-tutorialreference-6x-loaders-and-platforms/
-
I would expect that motherboard to run 1.03b and associated DSM platform well. Make sure you are building your system and connecting with the gigabit port first. Also, try DS3615xs instead of DS3617xs. You don't need the cores support of DS3617xs.
-
What 10Gbe adapter?
-
If all your problems started after that power supply replacement, this further reinforces the idea of stable power. You seem reluctant to believe that a new power supply can be a problem (it can). For what it's worth, 13 drives x 5w equals 65w, that shouldn't be a factor. In any debugging and recovery operation, the objective should be to manage the change rate and therefore risk. Replacing the whole system would violate that strategy. Do the drive connectivity failures implicate a SAS card problem? Maybe, but a much more plausible explanation is physical connectivity or power. If you have an identical SAS card, and it is passive (no intrinsic configuration required), replacing it is a low risk troubleshooting strategy. Do failures implicate the motherboard? Maybe, if you are using on-board SATA ports, but the same plausibility test applies. However, there is more variability and risk (mobo model, BIOS settings, etc). Do failures implicate DSM or loader stability? Not at all; DSM boots fine and is not crashing. And if you reinstall DSM, it's very likely your arrays will be destructively reconfigured. Please don't do this. So I'll stand by (and extend) my previous statement - if this were my system, I would change your power and cables first. If that doesn't solve things, maybe the SAS card, and lastly the motherboard.
-
I can't really answer your question. Drives are going up and down. That can happen because the interface is unreliable, or the power is unreliable. A logic problem in the SAS card is way more likely to be a total failure, not an intermittent one. If it were me, I would completely replace all your SATA cables and the power supply.
-
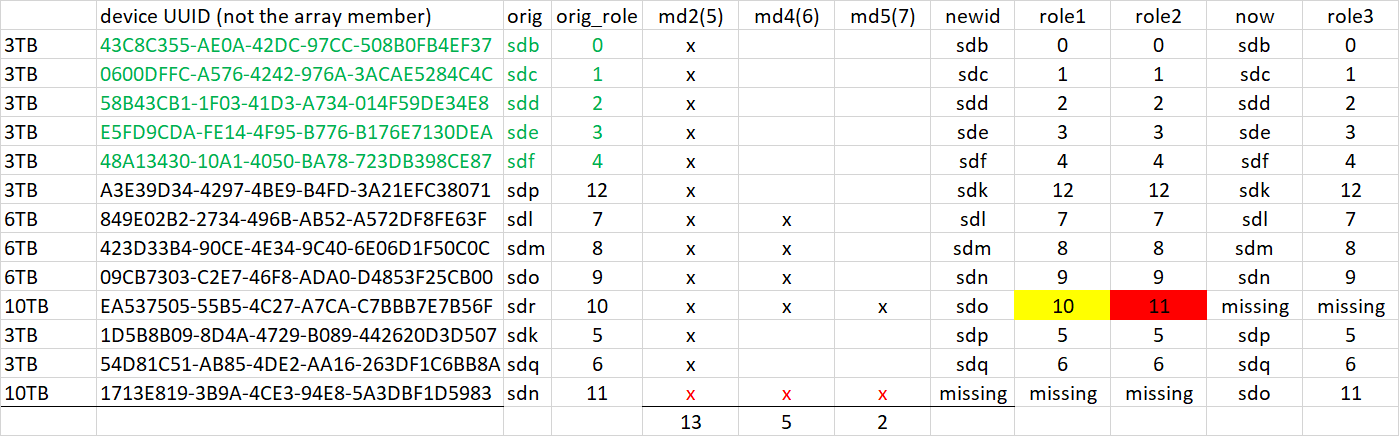
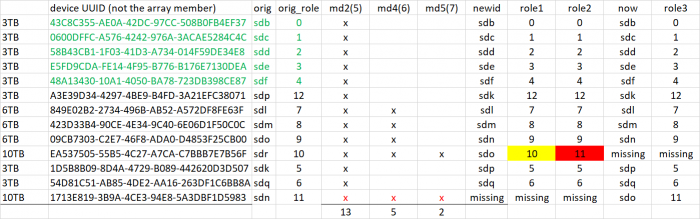
Everything is going up and down right now. You can see the changed drive assignments between the two last posted mdstats. We can't do anything with this until it's stable.
-
Your drives have reordered yet again. I know IG-88 said your controller deliberately presents them contiguously (which is problematic in itself) but if all drives are up and stable, I cannot see why that behavior would cause a reorder on reboot. I remain very wary of your hardware consistency. Look through dmesg and see if you have any hardware problems since your power cycle boot. Run another hotswap query and see if any drives have changed state since your power cycle boot. Run another mdstat - is it still slow?
-
# mdadm --assemble --run /dev/md4 -u648fc239:67ee3f00:fa9d25fe:ef2f8cb0 # mdadm --assemble --run /dev/md5 -uae55eeff:e6a5cc66:2609f5e0:2e2ef747
-
# mdadm --stop /dev/md4 # mdadm --stop /dev/md5 # mdadm --assemble /dev/md4 -u648fc239:67ee3f00:fa9d25fe:ef2f8cb0 # mdadm --assemble /dev/md5 -uae55eeff:e6a5cc66:2609f5e0:2e2ef747 The first one will probably error out complaining that /dev/sdo6 is not current. We'll be able to fix that.
-
There are alternatives to DSM native LetsEncrypt, i.e. Docker apps.
-
I don't have a plan to plug the disconnected 10TB at this time. # mdadm --detail /dev/md5 # mdadm --detail /dev/md4
-
Ok then, lets complete the last task then, try to incorporate your second 10TB drive into the array: # mdadm -Cf /dev/md2 -e1.2 -n13 -l5 --verbose --assume-clean /dev/sd[bcdefpqlmn]5 missing /dev/sdo5 /dev/sdk5 -u43699871:217306be:dc16f5e8:dcbe1b0d # cat /proc/mdstat
-
To compare, we would have to fgrep "hotswap" /var/log/disk.log not "hotplug" But looking at your pastebin it appears that the only drive to hotplug out/in is sda, which doesn't affect us. But why that happened is still concerning. Please run it again (with hotswap) and make sure there are no array drives changing after 2020-01-21T05:58:20+08:00
-
I was referring to the array table I made not matching up to one of the mdstats. This appears to suggest continuing hotplug operations (drives going up and down) at the moment you keyed the first array creation command, which might have made the first array test invalid. Continuing our current trajectory: First, repeat fgrep "hotplug" /var/log/disk.log and make sure there are no new entries in the log since the report above. If there are new entries, your system still isn't stable. If it's the same as before, move forward with: # mdadm -Cf /dev/md2 -e1.2 -n13 -l5 --verbose --assume-clean /dev/sd[bcdefpqlmn]5 missing /dev/sdo5 /dev/sdk5 -u43699871:217306be:dc16f5e8:dcbe1b0d # cat /proc/mdstat
-
Sorry, but please run the fdisk -l as individual commands. # fdisk -l /dev/sdb # fdisk -l /dev/sdc # fdisk -l /dev/sdd # fdisk -l /dev/sde # fdisk -l /dev/sdf # fdisk -l /dev/sdk # fdisk -l /dev/sdl # fdisk -l /dev/sdm # fdisk -l /dev/sdn # fdisk -l /dev/sdo # fdisk -l /dev/sdp # fdisk -l /dev/sdq Also: # fgrep "hotswap" /var/log/disk.log # date
-
Hold up. I found a table error. It will take me awhile to noodle it out. Please be patient.
-
# fdisk -l /dev/sd?
-
So just to be clear, you want me to take out the power and sata cable from the current 10TB, and put them into the "bad" 10TB? I don't have to power down btw. Yes, exactly that.
-
Unfortunately this is the same result. We moved the 10TB from slot 10 to slot 11, and the array is still not readable. We don't want to add to the array. But replacing the 10TB drive is the next (and probably last) step. This goes back to this conversation here: "now you have determined that the "good" 10TB drive is failed and removed it from the system, which leaves the "bad" superblock-zeroed 10TB drive as the only path to recover /dev/md2. It is important to be correct about that, as it is possible that the "bad" 10TB drive has corrupted data on it due to the failed resync" So here's how this needs to go. # vgchange -an # mdadm --examine /dev/sd?5 # mdadm --stop /dev/md2 Post the result of the examine. Then if at all possible, disconnect the "old" 10TB drive and replace it with the other "new" 10TB without powering down the system. Please install the "new" drive to the same port. If you have to power down and power up the system, please post that you did. Assuming the drive is stable and not going up and down, then: # mdadm --examine /dev/sd?5 # cat /proc/mdstat Post the result of both commands.
-
Ok, nothing new got added to dmesg. Because /dev/md2 is first in the vg, this is definitively telling us that /dev/md2 is not good. We are starting to run low on options. If for some reason we have the position of the 10TB drive wrong (slot 10), we can try the other spot (slot 11). A more likely scenario is that the drive is damaged from corrupt and we are out of luck for this drive. But let's test the wrong slot possibility: # vgchange -an # mdadm --stop /dev/md2 # mdadm -Cf /dev/md2 -e1.2 -n13 -l5 --verbose --assume-clean /dev/sd[bcdefpqlmn]5 missing /dev/sdo5 /dev/sdk5 -u43699871:217306be:dc16f5e8:dcbe1b0d # vgchange -ay # mount -t btrfs -o ro,nologreplay /dev/vg1/volume_1 /volume1 Post results of all commands.
-
Try this, but I don't really expect it to work: # mount -t btrfs -o ro,nologreplay /dev/vg1/volume_1 /volume1
-
Hmm, it turns out norecovery is not a valid option in Syno's compile of btrfs. Investigating.
-
Please do NOT repair, that would be catastrophic at this point.