

mcdull
-
Posts
252 -
Joined
-
Last visited
-
Days Won
4
Posts posted by mcdull
-
-
20 hours ago, titoum said:
those that took the steps to move to dsm 7.0.
no issues with plex or hyperbackup ?
what kind of error did you encountered? I did not use plex as I have no GPU.
But hyperbackup seems fine with google.
-
I have some issue in migrating.
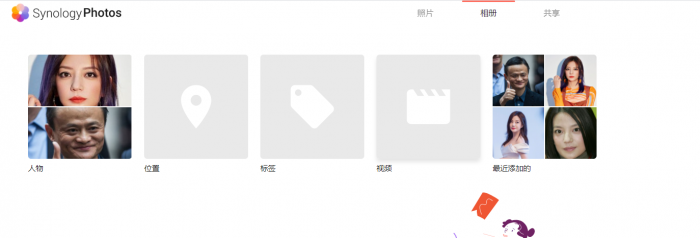
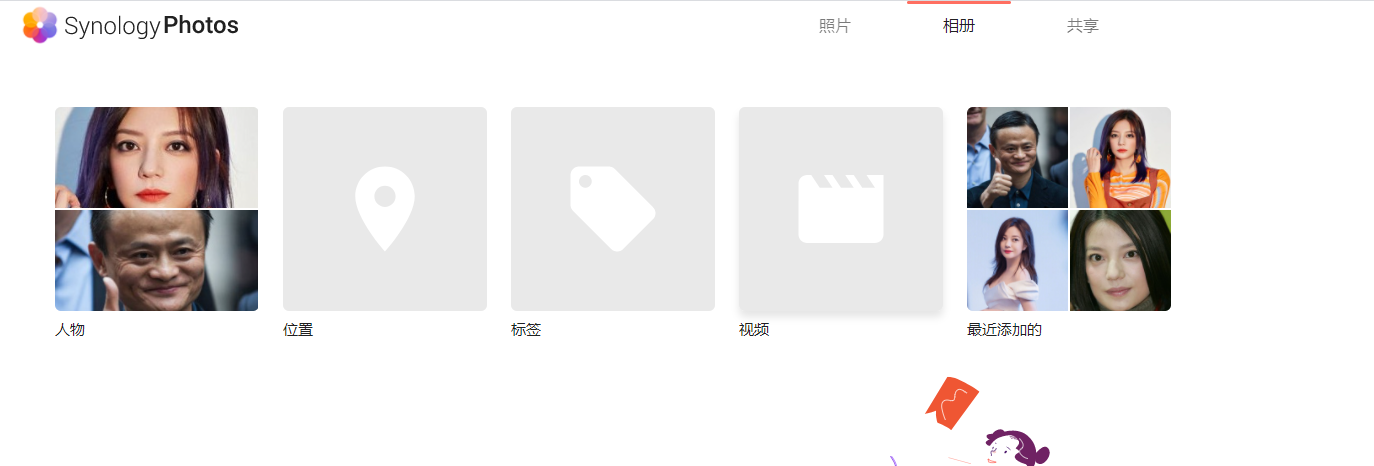
I do have some images with facial recognition when old version in Jun's loader still works. But now it is must not work with DSM7 (I uses AMD cpu) and no GPU at all.
Now the synology photos keep telling me that its trying to migrate from old photos and moments app, and keep waiting the 30000+ photos to complete.
Any suggestions for me?
-
7 hours ago, ThorGroup said:
If this atom supports MOVB you can even run 918+ build. However for this hardware 3615xs build is probably the best. Regardless, that CPU is very slow. It will run... it will.... but the experience will be pretty miserable.
Thanks, just try from dust. Turn out it is too old that it stop at the word "GURB" only on screen. Tried both usb sticks and DOM.
-
I have finally migrate my existing production vm to DSM7. looks good at the moment. Its running under proxmox.
Due to immou group, I cannot passthrough the 9211i controller, instead I rdm all hdd using virtual SATA.
-
44 minutes ago, jumkey said:
use real sn and mac with GPU Passthrough Facial Detection can be work
root@DSM:~# ls /dev/dri/ card0 renderD128 root@DSM:~#
do you know if any pci-e gpu is capable of doing so? my system only have one GTX1080 and already pass through to Windows VM, and I am using AMD cpu without gpu in it.
-
30 minutes ago, jforts said:
I successfully boot with Proxmox all works fine during the testing. But still cannot boot from baremetal, after choose the USB drive, it just bypass to boot from USB drive. Anyone have this problem?
Below is my DSM in Proxmox
")
1. use lagacy bios to boot (cms)
2. Make sure you use the correct vid pid of your real usb.
-
42 minutes ago, loomes said:
No they dont use HW Transcoding. With the 3615xs 7.0 Version (no HW transcoding support) Face Detection works fine in a Proxmox Machine.
Proxmox Machine with 918+ 7.0 dont work with i915 or without.
Legit Serial Nr and Mac Number for 3615xs and 918+.
Btw, the i915 Driver integrated in the Syno Image works fine (Video transcoding is also working). So theres is no general Reason to replace it when its loaded fine:
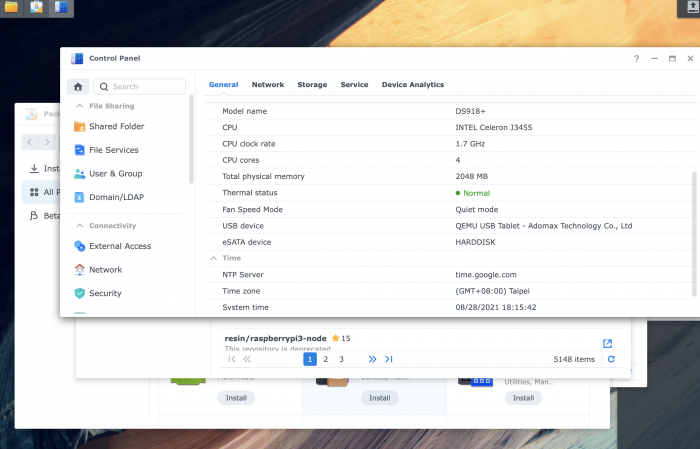
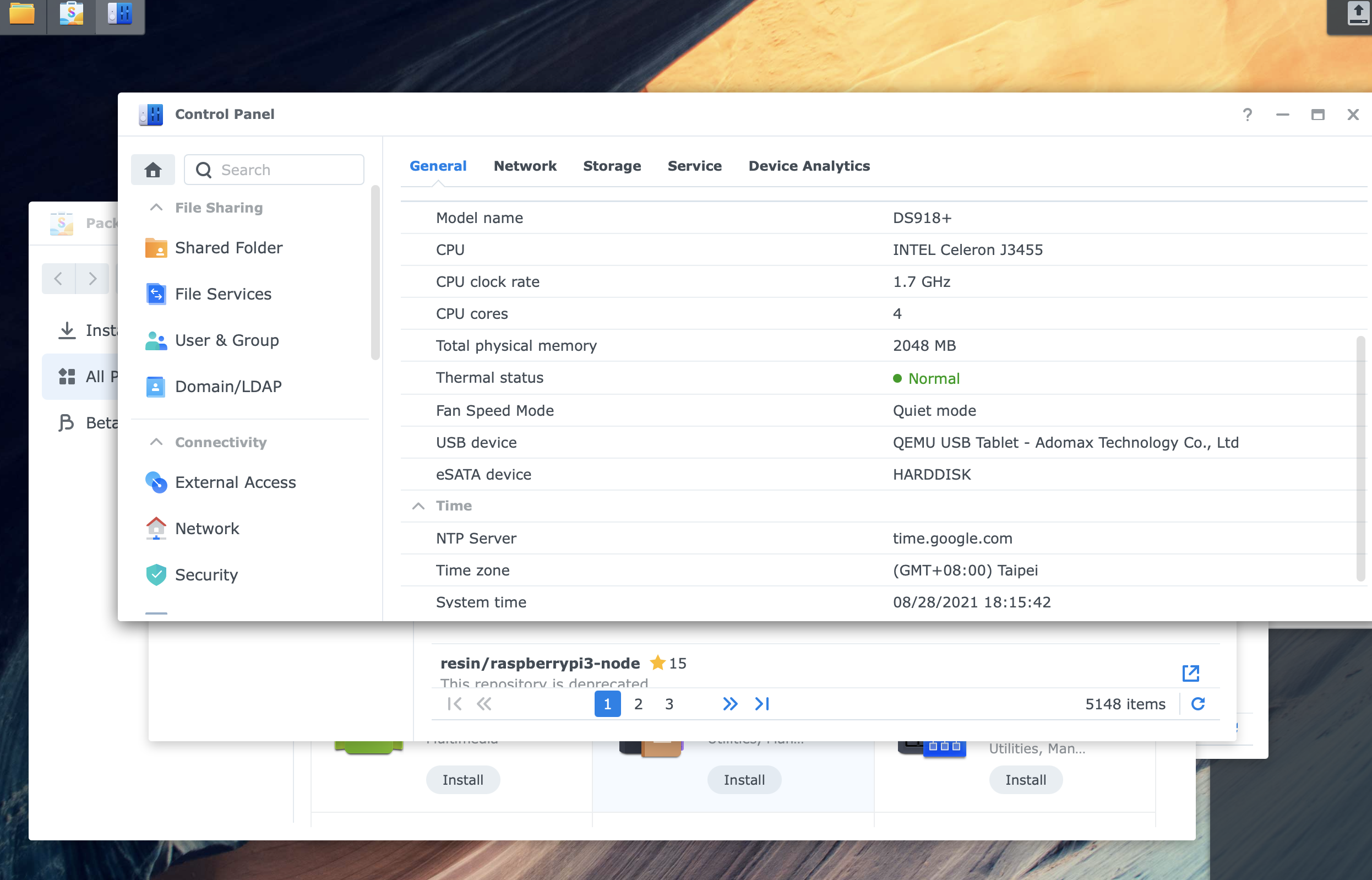
lsmod | grep i915 i915 1308361 0 drm_kms_helper 121033 1 i915 drm 310096 3 i915,drm_kms_helper iosf_mbi 4298 1 i915 fb 34959 2 i915,drm_kms_helper video 27139 1 i915 backlight 6219 2 i915,video button 5105 1 i915 i2c_algo_bit 5456 1 i915 root@DS918plus:/usr/lib/modules# dmesg | grep i915 [ 9.218265] i915 0000:01:00.0: Invalid ROM contents [ 9.241795] [drm] Finished loading DMC firmware i915/kbl_dmc_ver1_04.bin (v1.4) [ 9.263590] [drm] Initialized i915 1.6.0 20171222 for 0000:01:00.0 on minor 0 [ 9.699633] i915 0000:01:00.0: fb0: inteldrmfb frame buffer deviceI think the Problem is another why Facial Detection sometimes works and sometimes not.
true and not true.
It depends on moments version.
-
3 hours ago, phytan said:
I know, so it is dead end now.
I'm curious why it works in i5-8500t but not J4125 since 920+ is using J4125...
you use baremetal or what?
-
23 minutes ago, phytan said:
I'm using J4125 CPU. But I'm using Unraid KVM virtual machine to simulate the 918+.
The Moments+ 6.2.3+Jun's loader works file in the virtual machine, but Photos + 7.0 + redpill does not work.
I'm using real SN and quick connect has been activated.
I guess it might be similar limitation for 6.2.2 and 6.2.3 Moments. 6.2.2 works but 6.2.3 does not and need the patch.
if you need patch for 6.2.3 to work, it means it will not work in 7.0 coz there is no patch yet.
The patch is actually just and old version of library.
-
1 hour ago, Orphée said:
Should Proxmox considered as a better alternative than ESXi in the future ? or is it just a matter of debugging time ?
its different.
If supported, Esxi is almost guaranteed to be more stable.
However, Proxmox always have better compatibility and community support.
I expect the beta or nightly build is better built on Proxmox, then port to ESXi for production use.
-
 1
1
-
 1
1
-
-
oh, thx... some discussion on web said it was 32bit. And I checked it was x86-64. hope it works.
-
 1
1
-
-
May I know what is the targeted minimum hardware for redpill project?
I am curious if my idle QNAP TS-439 Pro II+ with 32bit atom (cpu:D410) is able to boot 6.2.4.
Thanks.
-
18 minutes ago, scoobdriver said:
@haydibe Thanks for your work . Could you advise how I "Clean up" the docker tool .
I'm running this on a small VM , it works great first time , but if I try to generate a new image , I'm out of disk space (seems to grow every time I generate and image for the same Architecture) .
without removing everything and starting again , are there any locations I can remove files ?
In general it should clear up by itself under /opt
And ./images that it will store the final img file.
You may refer to these locations. (I uses dockerce only)
to me I would rather make a snapshot and revert it when necessary.
-
just learnt that DSM7 has bug in processing BTRFS that will cause data loss. I will have my fingers crossed
-
24 minutes ago, stefauresi said:
Hi,
I know you said virtualize DSM is the best way .... but actualy my server is baremetal (918+) with 40To , how migrate my baremetal install to promox then i don't have material for backup my data ?
your hdd stays the same whenever you go virtualize from physical or vise versa.
its just the harddisk or the entire controller you need to passthrough to the vm, then it is the same as baremetal.
If you feel dont like it, you can always return to baremetal without touching your hdd. Just to make sure the new enclosure have at least the same version of DSM and support your RAID type.
-
20 minutes ago, jumkey said:
chmod +x redpill-load/config/_common/iosched-trampoline.sh
fix the latest version rp.ko cannot be loaded
Great, it works.
Since I used auto, that's why I didnt notice the permission. XD.. thanks.
-
1 hour ago, ThorGroup said:
We've got more progress notes. As with every update we have something big today too
Revamped loading schema
This seems like an implementation detail which isn't important at all. However, this change is a milestone in making the kernel module stable and robust.Previously we went with a naive (but working!) method of simply throwing "insmod rp.ko" into the first bash file loaded after the kernel passes control to the user space. Well, it does work but it has many problems, which aren't obvious at first:
-
module loading is asynchronous (some things may overstep actions we take, especially on fast multicore CPUs)
- this was responsible for rare but existing issue with synobios loading before we were able to shim some of its functions
-
some methods in the kernel aren't available
- dreaded issue https://github.com/RedPill-TTG/redpill-lkm/issues/10 crashing many systems was the major reason pushing us to do this. For some reasons it was affecting mostly ESXi and KVM-accelerated QEmu (interestingly almost never affecting software emulation in QEmu, go figure) on Linux v4.
- @jumkey@gadreel are the people we noted on GH but we remember many more posts in this thread.
-
things may already be too far gone to react to them
-
If you remember our previous post we had a "gotcha" with SATA-based booting. In essence the some/all drives were already probed and ready before we could even think about loading a kernel module. We solved this with virtually unplugging set drives and replugging them. Neat, but wouldn't it be nice to not do it? Well, now we can
")
-
If you remember our previous post we had a "gotcha" with SATA-based booting. In essence the some/all drives were already probed and ready before we could even think about loading a kernel module. We solved this with virtually unplugging set drives and replugging them. Neat, but wouldn't it be nice to not do it? Well, now we can
We had to get creative here. We knew that Jun's loader used to somehow load very early. From what we found we assumed it's some kexec trickery. Reading the kernel init process, starting from init/main.c which is probably one of the first files Linus Torvalds created (and which to this day carries the date of 1991 :)). The file contains a curious hint - a call to "load_default_modules()" which does only a single call to "load_default_elevator_module()". Connecting the dots with the Jun's "elevator" boot parameter and more digging in the kernel we figure out that we can not only load much earlier but more importantly do it while the kernel is still in its init stage (explained below). The kernel essentially ASKS us to load the RedPill module - what an irony, isn't it?
So how does that trick work?!
Loading kernel modules is complex. However, in short there are two distinct ways for them to load: from userspace or from kernel space. The latter is kind of misleading since the kernel, after doing some checks, calls /sbin/modprobe to actually load the module (see `kmod.c`). This path is hardcoded in the kernel. Usually it's a symlink to a kmod utility which uses userspace syscalls to load the module.Here comes the less-intuitive part. RedPill LKM is loaded on the kernel's request. It happens because we specify the `elevator=elevator` boot param. This causes kernel to, very early in the boot process (in fact still being in the formal init-before-boot stage), request module named "elevator-iosched". There's nothing special in that name - it can be anything as long as the userspace and cmdline agree on the name. Our [fake `modprobe`](config/_common/iosched-trampoline.sh) checks (very loosely) if the requested module is `elevator-iosched` and triggers the standard force-insmod, then deletes itself. Keep in mind that our "modprobe" isn't actually overriding anything - preboot environment contains no `modprobe`as it has no concept of depmods (=modprobe would be useless).
Using I/O scheduler loading method over insmod-ing it in init allows us to load the LKM much earlier. While by itself it has advantages of simply being faster, it also carries another **very important** advantage: I/O scheduler, as mentioned earlier, is loaded during init stage. This means we can safely call methods which are marked with `__init` and potentially removed after init finishes.
So, you just added a file, right with a correct name?
Well, not quite, but this is the exact question someone asked internally seeing the commit in the load repo
Many things actually exploded as we assumed they are available. So the majority of the changes were actually in the kernel module itself. We described them below.========================================================================
All changes below were a direct prerequisite to make the module load as I/O scheduler, and this is why it took a significant amount of time:
Kernel cmdline/boot params rewrite
From the beginning the cmdline sanitization functionality relied more-or-less on /proc subsystem. We already had issues with /proc not being mounted and had to switch to internal VFS lookup during https://github.com/RedPill-TTG/redpill-lkm/issues/11 but loading as I/O scheduler opened a different can of worms. While /proc/cmdline is considered to be "always available", it is only true in the user space. Cmdline entry is initialized.... just after the I/O scheduler. Because of this we had to completely change how we replace the cmdline. It's less pretty but as robust as before.
SATA boot device shimming
Addressing VMWare folks we developed the SATA boot shim. It's much simpler than the USB one but it has many more edge cases. Loading the LKM as I/O scheduler uncovered another one: we're most likely loaded before SCSI sd driver. This is literally the first driver in the system which is loaded (as it's required on most of the systems to access the rootfs disk). However, now the module loads so early that we are there quicker than the driver itself. We added another edge case to it to listen for the driver loading and intercept it as it loads (which is actually cleaner and faster).
Of course, we kept all 3 methods (loading before driver, loading after driver but before disks, loading after driver and after disks). We can highly recommend reading the file comment for https://github.com/RedPill-TTG/redpill-lkm/blob/master/shim/boot_dev/sata_boot_shim.c
Fix mfgBIOS disk LED control race condition on 918+
Normally LEDs are controlled by sending an ioctl to mfgBIOS (if it exists). We replace the methods in synobios to capture and respond to these request. However, there's another edge case which happens only when the drives load just milliseconds slower than expected and land squarely DURING our mfgBIOS shimming. This will break a very special case in the mods syno did to the kernel.On some platforms the kernel is used as a middle man to "translate" /dev/sdX entries to SCSI channels/hosts. In essence only the kernel knows which sdX is which physical SATA port. During disk detection the modified driver attempts to set LEDs state from WITHIN the kernel and forces an ioctl to mfgBIOS. If it's not ready yet it will end up a kernel panic half of the time. We fixed that by additionally shimming the custom syno kernel API. Since this doesn't always happen on our test systems don't be surprised if the LED shimming log entries appear in your log only sometimes.
========================================================================
Smaller yet noteworthy changes:
Single serial port operation on 918+!
Yes, finally! Since the horrible issue 10 https://github.com/RedPill-TTG/redpill-lkm/issues/10 is now fixed we are confident to switch the 918+ platform to always use ttyS0. This means two things: 1) you can boot with a single serial port and not deal with switching, and 2) we will be able to debug on bare metal (because even a single COM is a luxury now).execve() shimming is considered stable
After many iterations and multiple people reporting crashes in https://github.com/RedPill-TTG/redpill-lkm/issues/3 we can say that part of the module is now stable. We know as soon as we put this in writing someone is gonna break it If that happens we will have to rewrite a part of it in assembler and we want to avoid it like fire.
If that happens we will have to rewrite a part of it in assembler and we want to avoid it like fire.
Fix RTC proxy for "some" days of the month
It turns out the RTC proxy was working reliably ONLY during the last day of each month. See https://github.com/RedPill-TTG/redpill-lkm/issues/15Dynamic version string
To make communication with people testing RedPill easier we decided to add a pseudo-version string to the kernel module. Now when the code is compiled it will check the last commit in the repo and embed its hash in the code. This means that you can see the version in at least four places:- modinfo redpill.ko
- During initialization (e.g. RedPill v0.5-git-abcdef loading...)
- When it crashes (e.g. RedPill v0.5-git-beefaa cannot be loaded...)
- During unloading (e.g. RedPill v0.5-git-faaff unloading...)
Automatic panic on error
The loader will now deliberately halt the system when a serious error occurs. This should significantly improve debugging and bug reporting where something didn't work but it was missed as there were more logs covering it and the system "seemed" to work. Along with this we also increased the dmesg/printk buffer so that more logs are available in verbose boot mode (which was especially a problem in Linux v4 where syno set a smaller-than-default buffer).Dev tools
We shared some dev tools which weren't previously in the repo (but as random files on our servers). They're ugly and most likely buggy but hey, they work (probably). These include, as of now, three utilities:- make_all in LKM repo - let's you mass-build the LKM for all variants we have now
- inject_rp_ko in LKM repo - automates injection of RP LKM to an already built image
- rebuild_all in LOAD repo - rebuilds all versions (usually we call it after make_all)
These utilities have no guarantees and may break any moment. They should not be used for any automation.
Documentation update
- RTC docs are now available
- More details about PMU<>kernel interaction
- Serial muting (e.g. on 918+) has now its own page
========================================================================
We saw on GH that it's fixed now. Thank you for testing!
That is a very strange bug. Can you confirm what version of the LKM you're running (it should print "RedPill v0.5-git-"
somewhere in the dmesg).We can definitely attest to that. Virtualization came a long way. We remember the times when it got that bad rep of being a performance killer. Nowadays, it's in the single digits percent points and sometimes may even be faster and utilize the hardware more (optimize memory paging, transparent compression, pages sharing etc). When paired with VirtIO drivers and a Linux OS it's amazing (less so with Windows but it's getting better as well).
From our perspective a passthrough controller + a good resources reservation is much more flexible than bare metal (especially when running on non-server hardware without IPMI).
You can pass pretty much any external (and even some internal) devices connected over PCI(e). From our experience, ESPECIALLY if you're running on non-server or dated hardware, Proxmox has a way superior support for that in comparison to ESXi. If you prefer unRAID it's nice as well and uses a similar tech to Proxmox.
There are SOME platforms where you can "split" devices and share a part of it. But if you didn't buy it specifically for that or/and it isn't a server-grade equipment it's almost certain it will not work. If you want to google around it's called SR-IOV.
Adding to that: 918+, despite the graphics showing 4, supports 10 drives no problem. We didn't test more but up to 12 should be safe.
We were able to replicate that when we reset the VM instead of shutting down. On normal reboot it does work... this is very strange. Just to confirm: are you using ESXi? If you can can you drop an issue in the redpill-load repo?
https://github.com/RedPill-TTG/redpill-loadTeeechnicallly it can be added straight to the ramdisk and loaded. However, this isn't a sustainable solution as ramdisk has significant memory constrains (and boot time).
What we are planning is to allow loading of driver simply from a folder of .ko's with a user-defined list in user_config to not load literally everything. That way we can have a common repo with all drivers and their binary versions and a quick script downloading some/all of them. This way the community doesn't need to prepare 55 driver packs but rather we can have a simple JSON file listing files to download and put into loader image (but not the ramdisk).
Someone is surely brave
It's more stable now than even a week before but still we wouldn't recommend daily-driving it. At least not before the PMU is fully emulated because stuff like GPIO shim are just "nice to have" rather than "it must be there".
The new Ryzen's are beasts and are great for poking around. When we stabilize the loader we will for sure look at something from the v1000 lineup.
We will need a full log from dmesg and /var/log/messages. The error you have in the snippet isn't significant (it's fixed anyway) as your time updated from the internet.
Do you have anything in dmesg? This looks like a binary crash due to CPU instructions. If that happened it will be logged in dmesg for sure.
It's recommended to use q35 for everything (not just here). It's a much newer platform and support a proper PCIe passthrough.
I see you're recommending changing VirtIO to e1000e - is the VirtIO broken on unRAID?
Are you sure it's not indexing anything? scemd is a catch-all for various operations in DSM.
If you have any problems with passthru make sure you're using q35. If you're on something from HP you may have a problem with RMRR. Shoot us a PM if something - we went through good and bad with Proxmox many times
But you gonna be happy with the switch and the freedom of Debian base.
tried the new loader just now.
It wont boot nor no serial out.
Serial0 stopped at the same place and serial2 has no output as well.
[ 1.067248] Serial: 8250/16550 driver, 4 ports, IRQ sharing enabled
[ 1.114879] serial8250: ttyS1 at I/O 0x2f8 (irq = 3, base_baud = 115200) is a 16550A
[ 1.115803] console [ttyS0] enabled
[ 1.116471] bootconsole [uart0] disabled
-
module loading is asynchronous (some things may overstep actions we take, especially on fast multicore CPUs)
-
Serial muting (e.g. on 918+) has now its own page
May I know if this is related to serial number or other? the major difference between redpill and jun's loader is redpill prohitbited many of the synology service.
I used to have a correct 918 serial number to use with 6.2.3. Is it reccommend or not to use the real serial (regardless of using quickconnect, etc) in redpill?
-
53 minutes ago, renyi said:
dou you have a link
see this but it will not work as DSM 7.0 photo is a new app and requires new library
-
58 minutes ago, gadreel said:
Definitely,
find attached...
The key areas for me are, change bios to sea bios, machine (Q35 ~ if u choose i440fx I do not think there is difference), USB Controller to 3.0 (XHCI), the 1st disk is red pill image as usb and 2nd disk as a SATA, edit the virtio ethernet to e1000e and you can add 2 aditional serials (total 3) like mine to monitor the console using "virsh console (name of VM) serial2"
AFAIK, no need to use e1000e which has less performance. latest loader is capable of doing virtio.
-
32 minutes ago, renyi said:
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: /source/synophoto-plugin-face/src/face_plugin/lib/face_detection.cpp:214 Error: (face plugin) load network failed
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: uncaught thread task exception /source/synofoto/src/daemon/plugin/plugin_worker.cpp:90 plugin init failed: /var/packages/SynologyPhotos/target/usr/lib/libsynophoto-plugin-face.so
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: /source/synophoto-plugin-face/src/face_plugin/lib/face_detection.cpp:214 Error: (face plugin) load network failed
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: uncaught thread task exception /source/synofoto/src/daemon/plugin/plugin_worker.cpp:90 plugin init failed: /var/packages/SynologyPhotos/target/usr/lib/libsynophoto-plugin-face.so
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: /source/synophoto-plugin-face/src/face_plugin/lib/face_detection.cpp:214 Error: (face plugin) load network failed
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: uncaught thread task exception /source/synofoto/src/daemon/plugin/plugin_worker.cpp:90 plugin init failed: /var/packages/SynologyPhotos/target/usr/lib/libsynophoto-plugin-face.so
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: /source/synophoto-plugin-face/src/face_plugin/lib/face_detection.cpp:214 Error: (face plugin) load network failed
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: uncaught thread task exception /source/synofoto/src/daemon/plugin/plugin_worker.cpp:90 plugin init failed: /var/packages/SynologyPhotos/target/usr/lib/libsynophoto-plugin-face.so
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: /source/synophoto-plugin-face/src/face_plugin/lib/face_detection.cpp:214 Error: (face plugin) load network failed
2021-08-19T12:57:25+08:00 U820 synofoto-face-extraction[5952]: uncaught thread task exception /source/synofoto/src/daemon/plugin/plugin_worker.cpp:90 plugin init failed: /var/packages/SynologyPhotos/target/usr/lib/libsynophoto-plugin-face.sodid you use intel platform with igpu? And if you are using hypervisor did you passthrough the gpu?
the library should require intel opencv. Which is also the same in 6.2.3
-
1 hour ago, loomes said:
No its to early. And i found that the new Photos App Face Detection is not working (Some checks for real Syno Hardware or something?!)
In old jun's loader, it is also related to cpu instruction set and cpu core assignment after a specific version.
i.e. intel gpu is required. Since I am using AMD it will NOT work anyway.
My hope is to support AMD machine type, e.g. DS1621+
-
I can hardly find any major issue on the new loader under proxmox.
Anyone starts using this as daily driver?
-
I installed 918+ DSM7.0, and added 6 SATA disks (virtual), and successful migrated a basic disk to 6 disks raid 5.
32GB x 6 = 131.5GB
-
1
-
RedPill - the new loader for 6.2.4 - Discussion
in Developer Discussion Room
Posted
map should be prurely software based. But it will take sometimes to scan the photo tags