

Tibag
-
Posts
67 -
Joined
-
Last visited
-
Days Won
1
Posts posted by Tibag
-
-
Well, I think my DSM is now properly destroyed. I attempted to mount my disk on Magic Parted to try to explain the disk space problem, to no avail. Then, after starting again TCRP it's now not finding my disk anymore. So... the disk is probably unusable anymore. I can't tell anymore what's caused the whole thing but if I could drop myself a message 1 week ago I would convince myself to never upgrade anymore! I strongly suspect that when there is an error during the upgrade DSM keeps uploaded file on the system partition. So actually if you try multiple times you get closer to a fully bricked system.
Current status for reference:
QuoteExit on error [1] DISK NOT INSTALLED...
Fri Jan 12 23:55:52 UTC 2024
:: Loading kernel modules from extensions ...
:: Loading kernel modules from extensions ... [ OK ]
:: Executing "on_jrExit" "jrExit" custom scripts ...
:: Executing "on_jrExit" custom scripts ... [ OK ]
Extensions processed
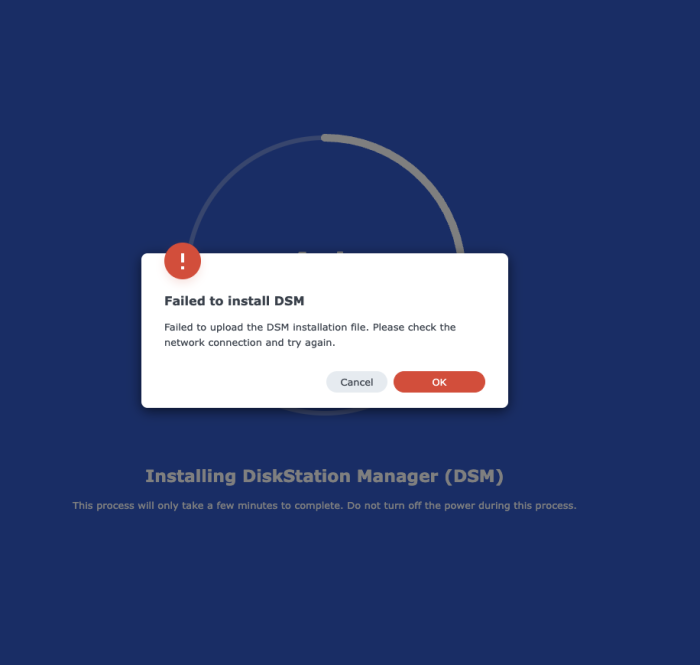
none /sys/kernel/debug debugfs rw,relatime 0 0I suppose the next option is to start an install from scratch and try to add my disks back if DSM can restore them?
-
I also tried ARPL just in case. Same error about disk space with all drives in, then with a single drive I get a new one (yay!):
Also tried ARC, same result.
-
14 minutes ago, Peter Suh said:
Currently, only Junior is available, so there doesn't seem to be a way to clean up /root directly.
I think you should follow the latter method by dividing the group into groups and trying to upgrade with only one volume.
So I tried to load volume by volume...
- tried with my volume1 disk only: stopped at the 55% mark with the "file is probably corrupted"
- tried with my volume2 3 disks: stopped at 0% with the system space error
I am not sure what other options I now have! 🤔
-
8 minutes ago, Peter Suh said:
There is no need to despair too much.
Your data disk is still safe.
Are there separate backups?
This is a message I also experienced some time ago.
This was a case where there were too many files in the /root path of the already installed DSM system partition.
When updating DSM, use this /root path.
You need to access the /root path of the system partition and organize its contents.
Of your two volumes, which disk is /root located on?
I think you need to try installing the two groups of volumes separately.
The remaining groups will be automatically migrated even if they are equipped later.
Would you like to try this method?Well, thanks for still helping!
If my memory doesn't fail me it's:
* volume1, made of the 2.73TB disk. It was the first installed so I am thinking this is where the /root is
* volume2 is a RAID of the other 3 disks
How can I access the data on the volume to clean them?
QuoteI think you need to try installing the two groups of volumes separately.
The remaining groups will be automatically migrated even if they are equipped later.
Would you like to try this method?Yes something I can try, I guess I run the loader with only my 2.73 disk (volume1) in? And hopefully the upgrade passes and I can add back the other three?
-
@Peter Suh I tried to use DS920+, find attached logs, and this time I am getting another error bout some missing disk space:

I start to wonder if my data is recoverable at all!
-
6 minutes ago, Peter Suh said:
Assemble args: -u 0074c5b5:808d4c6e:3017a5a8:c86610be /dev/sda1 /dev/sdc1 /dev/sdd1 /dev/sde1 mdadm: /dev/md0 has been started with 3 drives (out of 12). Partition Version=8 Checking ext4 rootfs on /dev/md0 return value: 0 sdc, part of md0, has obsolete partition layout 8. Detected data partition on sda. Must not be fresh installation. ForceNewestLayout: Skipped Mounting /dev/md0 /tmpRootI saw the log you provided.
Are there only 4 discs in total?
It is also strange that disk mdadm started on only 3 of the 12 disks.
The sdc that is part of md0 has the deprecated partition layout 8.
Data partition detected by SDA. Do not do a fresh install.It looks like the system partitions between disks are mixed up.
If DS3622xs+ does not recognize all disks
In order to recognize all disks, it would be a good idea to first complete the DSM version upgrade to the Device-Tree-based DS920+.
After the system partition's mdadm is stabilized, it would not be a bad idea to change the model again and migrate.Yes 4 disks in total:
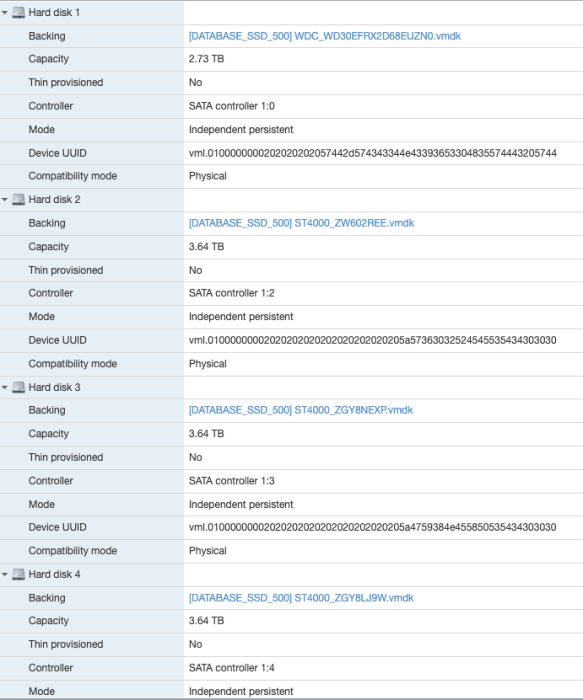
Essentially I had disk as 1 volume and the other 3 as another.
Could it be the face that I have no disks on SATA controller 1:1 as it does 1:0 -> 1:2 -> 1:3 -> 1:4?
Also, do you think trying a different loader like arpl-rr has chances of working better?
-
9 hours ago, Peter Suh said:
If connection to Junior is successful, can you send me the command log as below?
cat /var/log/*rc*
There we go, find attached. Does that help @Peter Suh?
-
21 minutes ago, Peter Suh said:
I tried building the DS3622xs+ loader in SATA mode on my ESXI 7.0 Update 3 system.
I expected a 10 second timeout from my boot-wait and automount addons, but that wasn't the case.
The loader's three FAT partitions were successfully mounted on time.
The log below is part of Junior's linuxrc.syno.log.
Ran "boot-wait.sh" for thethorgroup.boot-wait->on_boot->modules - exit=0 :: Executing "on_boot" custom scripts ... [ OK ] ... :: Executing "on_patches" "patches" custom scripts ... Running "install.sh" for automount->on_patches->patches Found synoboot / synoboot1 / synoboot2 Ran "install.sh" for automount->on_patches->patches - exit=0 Running "boot-wait.sh" for thethorgroup.boot-wait->on_patches->patches Ran "boot-wait.sh" for thethorgroup.boot-wait->on_patches->patches - exit=0 :: Executing "on_patches" custom scripts ... [ OK ]The cause seems to lie elsewhere.
Is it possible to access port 7681 through a web browser?
This method is called a TTYD connection.
Log in as root without a password.
If connection to Junior is successful, can you send me the command log as below?
cat /var/log/*rc*
Yes I could connect to TTYD yesterday when it was failing - I am only at home later tonight so I will post the cat output later.
Am I right in thinking that Junior should only kick in for a new installation? Like if my disks have a previous DSM version installed it shouldn't use Junior?
14 minutes ago, Orphée said:May I ask how the IMG was built for ESXi ?
While I was still using ESXI, I personnally always took default IMG and used V2V starwind converter to convert it to FLAT ESXi VMDK file.
Never had any issues with loaders on ESXi with this method.
I used the vmdk from Peter's repo and cloned it with vmkfstools on ESXI. Could that be the problem? It's a method I used before, I think!
-
6 hours ago, Peter Suh said:
I was mistaken.
A tgz file should have been used here, not a gz file.
Only the sha256 content should not be changed.
The tgz file must have been recompressed and uploaded with new content.
The content has already been taken action.
Please withdraw your Pull Request.
Thanks, I closed the PR.
6 hours ago, Peter Suh said:Are you by any chance building a loader on a VM like Proxmox?
The Pat file corruption message is directly related to the failure to mount three partitions on the loader disk.
This occurs especially frequently in SATA mode used by VMs.
If it is Proxmox, there is also a way to convert it to USB mode instead of SATA mode.
Please tell me exactly what your situation is.
Yeah I am on ESXI using SATA controller... I can't really move to Proxmox as I have various other VMs running on my ESXI.
Do you know any workaround?
-
8 minutes ago, Trabalhador Anonimo said:
I´m not linux expert. How can I forked?
Pretty sure Peter will fix it once he is back online - I wouldn't bother if you can wait. Once the repo is forked you need to manually fudge the various scripts and it's a PITA.
-
So I forked the repo and managed to build - the above PR will fix it.
So I am now on my next challenge. After the build it starts and suggests to migrate my disks. I upload my pat and during the process it fails with a corruption message. I check my logs and see:
QuoteDetected data partition on sdag. Must not be fresh installation.
ForceNewestLayout: Skipped
Mounting /dev/md0 /tmpRoot
------------upgrade
Begin upgrade procedure
Failed to found any patch
No upgrade file found
End upgrade procedure
============upgrade
------------bootup-smallupdate
Failed to AssertFileKeyValueEqual
value1: /etc.defaults/VERSION:buildnumber -> 69057
value2: /tmpRoot/etc.defaults/VERSION:buildnumber => 64570
Skip bootup smallupdate, because root is not matched to junior
============bootup-smallupdate
Failed to AssertFileKeyValueEqual
value1: /etc.defaults/VERSION:buildnumber -> 69057
value2: /tmpRoot/etc.defaults/VERSION:buildnumber => 64570
Exit on error [7] root not matched with junior...
Wed Jan 10 21:24:03 UTC 2024
/dev/md0 /tmpRoot ext4 rw,noatime,data=ordered 0 0
none /sys/kernel/debug debugfs rw,relatime 0There is a few posts about that but none makes sense. Any idea?
-
3 hours ago, Tibag said:
Thanks for helping!
The error is from the menu:
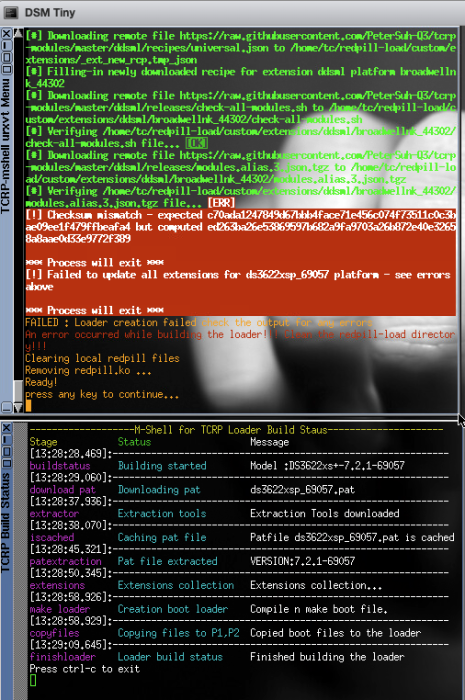
I suspect this may be related to your latest commit @Peter Suh? https://github.com/PeterSuh-Q3/tinycore-redpill/commit/708116888de6d9bb08b5b2fc1850c22fbba2011a
I can see the file was changed so the md5 must have too. I am just not sure what is used to compare the md5s.
Edit: nevermind, the issus is with the gz file which didn't change in 2 years...
Actually there was a commit after which changed the gz file - I suspect this is our culprit! https://github.com/PeterSuh-Q3/tinycore-redpill/commit/a97eb8527c416dfd17cb7f788f5245936ae03e41
@Peter Suh I created a PR for your repo: https://github.com/PeterSuh-Q3/tcrp-modules/pull/1
-
 1
1
-
-
1 hour ago, Peter Suh said:
Do not use the build command directly.
The menu method below corresponds to the above error.
Please use the menu.
./menu.sh
Thanks for helping!
The error is from the menu:
I suspect this may be related to your latest commit @Peter Suh? https://github.com/PeterSuh-Q3/tinycore-redpill/commit/708116888de6d9bb08b5b2fc1850c22fbba2011a
I can see the file was changed so the md5 must have too. I am just not sure what is used to compare the md5s.
Edit: nevermind, the issus is with the gz file which didn't change in 2 years...
-
 1
1
-
-
Hi @Peter Suh
I've been trying your build for the first time, using ESXI, with the latest version (v1.0.1.0.m-shell) and when building ds3622xsp_64570 (or later) I get:
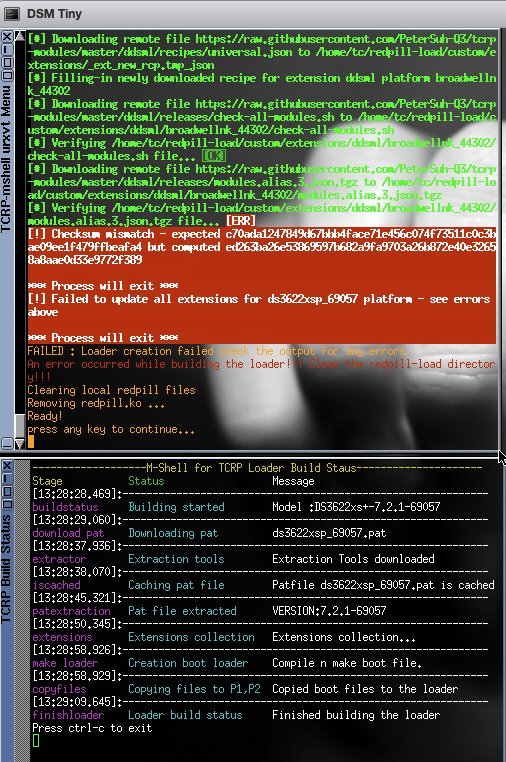
Quote[#] Downloading remote file https://raw.githubusercontent.com/PeterSuh-Q3/tcrp-modules/master/ddsml/releases/modules.alias.3.json.tgz to /home/tc/redpill-load/custom/extensions/ddsml/broadwellnk_44302/modules.alias.3.json.tgz
[#] Verifying /home/tc/redpill-load/custom/extensions/ddsml/broadwellnk_44302/modules.alias.3.json.tgz file... [ERR]
[!] Checksum mismatch - expected c70ada1247849d67bbb4face71e456c074f73511c0c3bae09ee1f479ffbeafa4 but computed ed263ba26e53869597b682a9fa9703a26b872e40e32658a8aae0d33e9772f389*** Process will exit ***
[!] Failed to update all extensions for ds3622xsp_64570 platform - see errors above*** Process will exit ***
I couldn't find someone else with the same issue... any idea?
-
1
-
-
Hi all!
I am currently running DSM 7.1.1-42962 Update 5 with 0.9.4.6 as a DS3622xs+ via ESXI.
I first through about manually upgrading with the package for DSM 7.2-64561, then doing the others, but I can't find it on http://download.synology.com/download/DSM/criticalupdate/update_pack/.
What's your recommended path to DSM 7.2.1 69057-Update 3?
-
On 3/17/2023 at 10:19 AM, Tibag said:
Hi all,
I think I might have messed up my DSM (running on ESXI). I was on 5.10.3tinycore64, installed DSM 42218 and I wanted to upgrade to the latest version. So I picked the update pack to 42218-6, updated via the UI and run the "sudo ./rploader.sh postupdate broadwellnk-7.1.0-42661" command (no error, I think).
After a reboot it's now killing the VM. Do you have any clues on how to identify the issue / resolve it?
Cheers
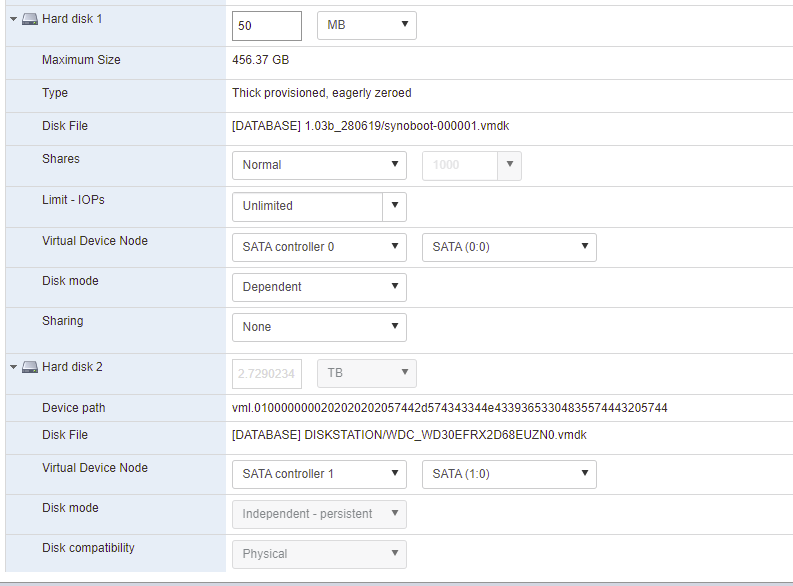
So I ended up starting a new image from scratch as nothing else would bring it back. And I jumped straight to DSM 7.1.1-42962 Update 1. Problem is that most of the disks came back either "crashed" or "System partition failed". Currently restoring one volume but not sure how the other will be so as it's a single disk volume. Essentially currently showing:

And Volume 1 is made of

Still looking for how to solve it but if anyone has any suggestion! What a rollercoaster!
-
Hi all,
I think I might have messed up my DSM (running on ESXI). I was on 5.10.3tinycore64, installed DSM 42218 and I wanted to upgrade to the latest version. So I picked the update pack to 42218-6, updated via the UI and run the "sudo ./rploader.sh postupdate broadwellnk-7.1.0-42661" command (no error, I think).
After a reboot it's now killing the VM. Do you have any clues on how to identify the issue / resolve it?
Cheers
-
Hey all,
I am slowly progressing with my first installation of the loader. I followed the instruction down to the build (used broadwellnk / 3622) on my ESXi VM and after the reboot (and selecting SATA boot) it gets stuck on "Starting kernel with SATA boot" then nothing happens. I used SataPortMap=1 and DiskIdxMap=00.
Anyone with a similar setup can help?
")
EDIT: okay it's expected, I can see DSM on my network!
Thanks
-
13 hours ago, Orphée said:
If you don't want to use linux command lines at all, go to ESXi. It is easier to manage disk / img upload and deployment with ESXi GUI.
If you don't fear command lines, ssh, etc... Proxmox VE is free and has a better serial port handling for our Xpenology needs. (Actually serial port from network/telnet access is not available without enterprise license on ESXi.)
Proxmox has some usefull features like Let's Encrypt certificates, MFA availability. I did not see it on ESXi.
It is my personnal experience with only one week of Proxmox usage.
Thanks! I am quite comfortable with bashing stuff but more experienced with esxi.
You've used esxi right? I couldn't get my VM to boot with the vdmk from Redpill, did you do anything specific with the image?
-
I see a bunch of you using Proxmox. As I am setting up a new machine I was going to go for esxi but is there any advantage to Proxmox vs esxi?
-
On 2/22/2022 at 3:13 PM, Orphée said:
Hi All,
So I finally made the big jump.
I migrated my prod ESXi DS3615xs 6.2.3 jun's to ESXi DS3622xs+ 7.0.1 RP.
All went very smooth, all apps were migrated successfully, only those not available on DSM7 were "stopped/incompatible"
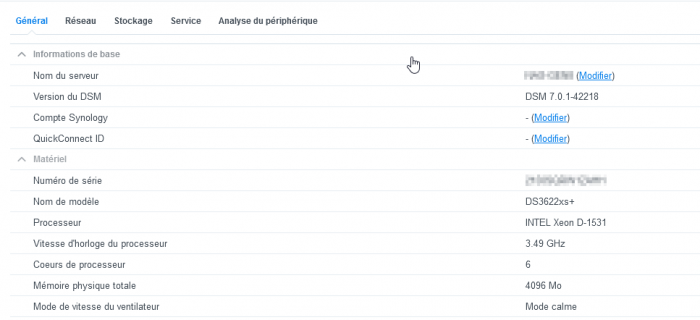
All my shares are here, docker migrated without any manual action.
As I reminder i'm using a LSI HBA IT card to passthrough my 4x4Tb disks
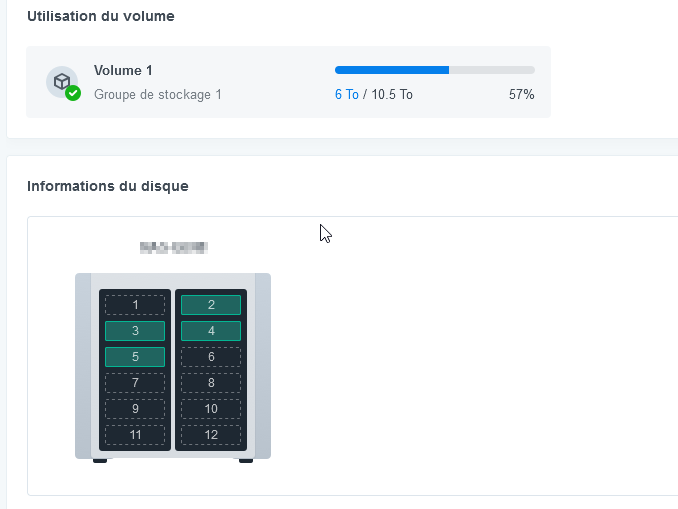
All good exept disk starting in position 2 (strange behavior with LSI HBA passthrough)
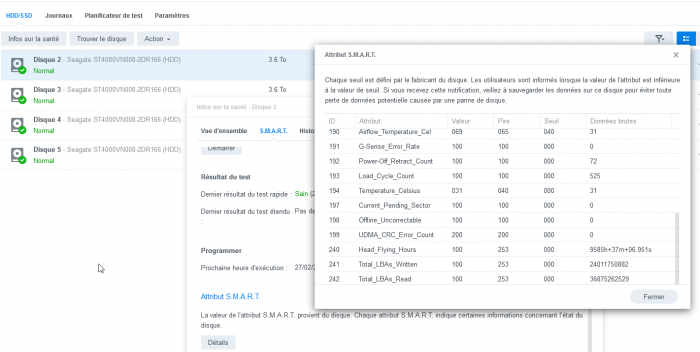
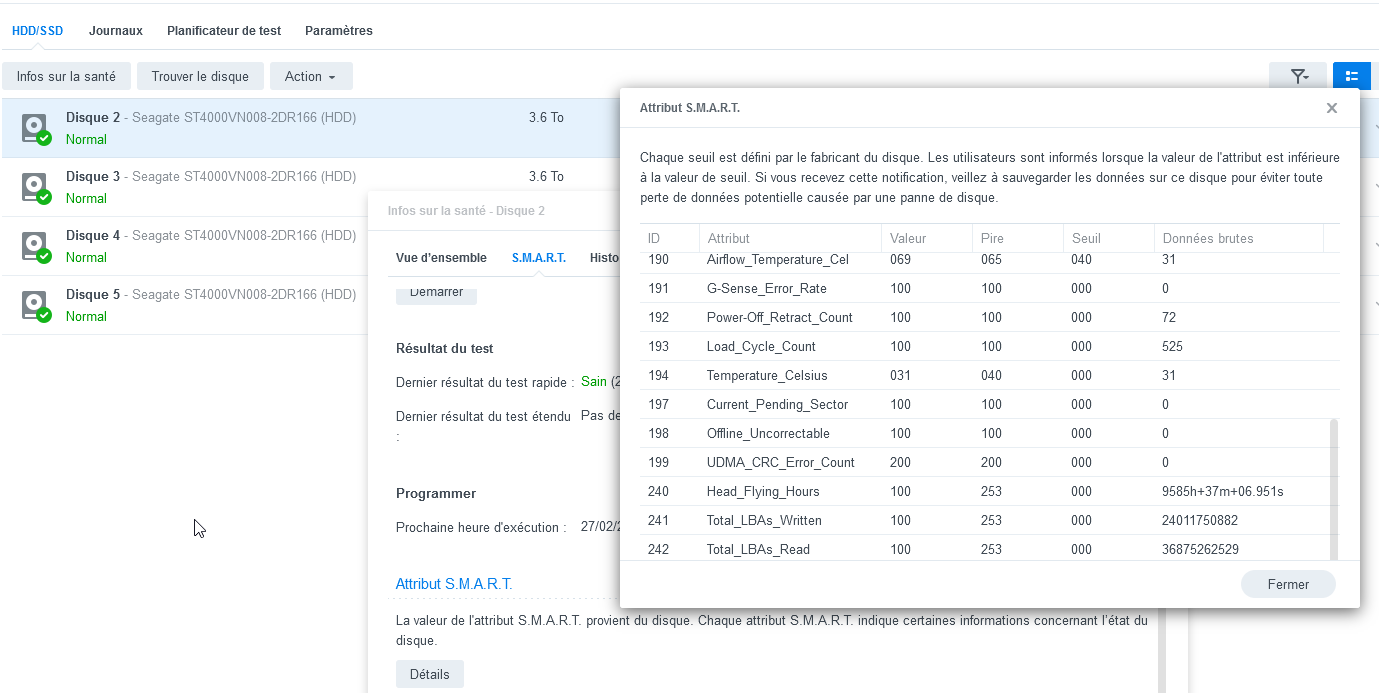
All my SMART info are there :
Synology Moments migrated to Synology Photos and is currently indexing all photos.
A big thanks to @pocopico @yanjun @haydibe @IG-88 and all others I probably forget too.
tagging @scoobdriver for info
")
Hey! I am trying to do something similar. Right now I took the vdmk and img file, created as an IDE drive but the VM doesn't start the boot loader. Are you able to explain how to attached the boot loader image to your VM?
-
Hi,
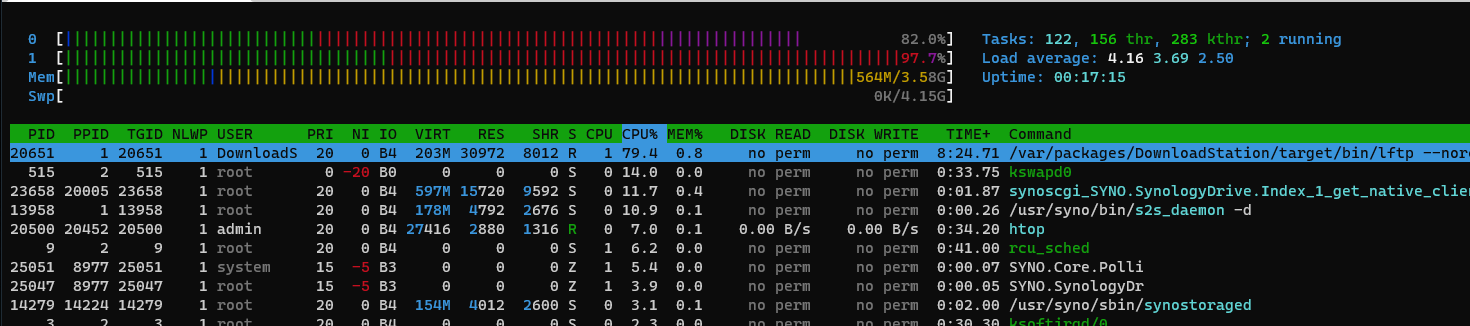
I started to have perf issues, or realise these, on my DSM 6.2.3-25426 U3 with Download Station and Samba file service. When downloading with DS I can see the CPU is hammered and it often looks like:
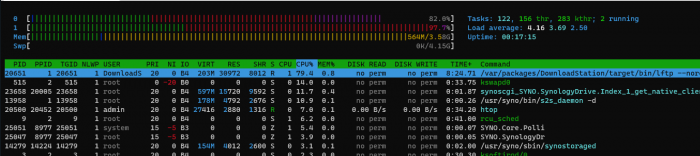
ie we can see DS sucking 100%, RAM fully allocated (mostly by rsyslog) but unused, some kswap process here and there. End result is DS is stuck at 5 Mb/s when my Internet allows 100 Mb/s (1 G provider).
I realised Samba shares are equally slow, if not worst. When I am copying a file to my Windows machine, all on a 1G switch, the speed will vary between 20Mb and 100kb/s. When this happens I can see smb process swallowing the CPU.
I can't tell if these two are related! I checked the Disk speed via DSM tool and it looked fine. I am using ESXI 6.5 VM for DSM.
Any idea guys?
-
Hi all,
I currently have a running N45L with DSM via ESXI. It's running with one drive used as my datastore for the VMs (500G) + one data drive (3TB). My DSM VM is like:
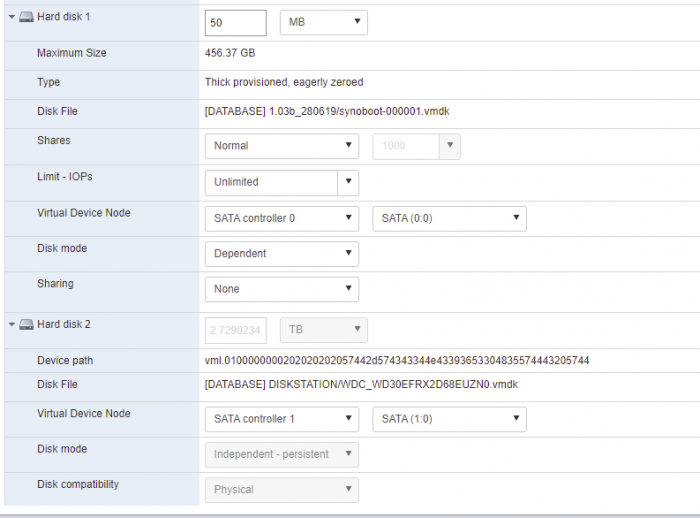
The first drive is synoboot and the second my data drive.
Now I am trying to add 2 more disks to the VM to extend the DSM volume. I'm trying to do a direct mapping so I am trying a passthrough as RDMs. I created my 2 vmdk with vmkfstools then I am trying to add them via a new SCSI controller (SCSI 0:0 and SCSI 0:1).
But when I do that DSM is mapping the drives on some obscure slots (like 33). I suspect the issue is with having 2 SATA controllers + the SCSI one.
I honestly can't remember why I used a SATA controller for my initial data drive. If I use my existing SATA controller then it's all mapped correctly.
So a few questions:
- Would a SATA controller not allow an actual passthrough? I've read only an SCSI controller will allow that
- If an SCSI is the only option for the pass though, how can I get it to be mapped by DSM? Should I delete my SATA 2 controller and use an SCSI one instead for the three drives? Will it not confuse DSM with my existing disk that contains data?
Cheers
-
On 6/28/2019 at 10:33 PM, Tibag said:
Nope, it still doesn't work.

I tried to upgrade my ESXi, moved to 6.5 U2, then tried again to boot the VM using 1.03b (Mac updated) and it doesn't find my DSM. It doesn't seem like it's able to get an IP. Do I have any way to debug it?
EDIT: okay I ended up recreating a VM, mounting back my existing disks and so. Then I realised the old VM was configured with a "E1000" instead of "E1000e". It seems to be a limitation on that old VM as I can't select E1000e so I suspect a legacy stuff from ESXi 5.5. My DSM is being recovered now, with 6.2.1.
Question: is 6.2.2 safe to upgrade? It seems like people are going for it but I remember it used to be a problem back in Jan?
Finally: Polanskiman thanks for the massive hint on the network adapter!
Auto-quote: yes, it works directly via an auto-update.






TinyCore RedPill Loader Build Support Tool ( M-Shell )
in Software Modding
Posted
Oh that I am 100% sure, I did something wrong at some point. I am always lost in the few options at our hands when it comes to upgrade. Last time I did jump to 7.1 I also spent hours to get it back to normal.
Yes I still my old TCRP and I just tried it. I built DSM 7.2.0-64570 with all the disk in and it detected it as recoverable. The recovery process just started, let's see. 🤞
If it does recover, what do you suggest to move to 69057?