

vbz14216
-
Posts
24 -
Joined
-
Last visited
Everything posted by vbz14216
-

new sata/ahci cards with more then 4 ports (and no sata multiplexer)
vbz14216 replied to IG-88's topic in Hardware Modding
Well well well, the WD drives mentioned a few months ago are still ok. But 1 out of my 2x HGST 7K1000 without noncq which ran fine for around year suddenly got kicked out of its own RAID1 array(within its own storage volume), degrading the volume. During that time I was testing Hyper Backup to another NAS, the HB ended without issues so I still have a known good backup in case if anything went wrong. dmesg and /var/log/messages listed some (READ) FPDMA QUEUED error and the ATA link was reset twice before md decided to kick the partitions out. I powered down the NAS, used another PC to make sure the drive was all good(no bad sectors) and erased the data preparing for a clean array repair. Before loading the kernel I added more noncq parameter to libata for all remaining SATA ports. Deactivate the drive, then a power cycle to make it recognized as an unused drive. The array was successfully repaired after some time, followed by a good BTRFS scrub. Analysis: This drive simply went "Critical" without any I/O error or bad sector notice from log center. /proc/mdstat showed the drive(sdfX) got kicked out from md0(system partition) and md3(my 2nd storage array, mdX at whichever your array was). Interestingly enough md1(SWAP) was still going, indicating the disk was still recognized by the system(instead of a dead drive). root@NAS:~# cat /proc/mdstat Personalities : [raid1] md3 : active raid1 sdd3[0] sdf3[1](F) 966038208 blocks super 1.2 [2/1] [U_] md2 : active raid1 sde3[3] sdc3[2] 1942790208 blocks super 1.2 [2/2] [UU] md1 : active raid1 sdf2[0] sdd2[3] sde2[2] sdc2[1] 2097088 blocks [12/4] [UUUU________] md0 : active raid1 sde1[0] sdc1[3] sdd1[2] sdf1[12](F) 2490176 blocks [12/3] [U_UU________] The other drive with identical model in the same R1 array has a different firmware and fortunately didn't suffer from this, preventing a complete volume crash. Upon reading /var/log/messages I assume md prioritized the dropped drive for reading data from array, which caused the drive to get kicked out in the first place: Continuing with a BTRFS warning followed by md doing its magic by rescheduling(switch over for redundancy): There's no concrete evidence on what combination of hardware, software and firmware can cause this so there isn't much point in collecting setup data. Boot parameter for disabling NCQ on select ports, or simply libata.force=noncq to rid of NCQ on all ports: libata.force=X.00:noncq,Y.00:noncq dmesg will say NCQ (not used) instead of NCQ (depth XX). This mitigates libata NCQ quirks at the cost of some multitask performance. I only tried RAID 1 with HDDs, not sure if this affects RAID5/6/10 or Hybrid RAID performance. NCQ bugs can also happen on SSDs with queued TRIM, reported as problematic on some SATA SSDs. A bugzilla thread on NCQ bugs affecting several Samsung SATA SSDs: https://bugzilla.kernel.org/show_bug.cgi?id=201693 It's known NCQ does have some effects on TRIM(for SATA SSDs). That's why libata also has noncqtrim for SSDs, which doesn't disable NCQ as a whole but only the queued TRIM. Do note that writing 1 to /sys/block/sdX/device/queue_depth may not be the solution for mitigating queued TRIM bug on SSDs, as someone in that thread stated it doesn't work for them until noncq boot parameter is used. (I suppose noncqtrim should just do the trick, this was the libata quirk for those drives.) Since this option doesn't seem to cause data intergrity issues, maybe can be added as advanced debug option for loader assistant/shell? Dunno which developer to tag. I suspect this is one of the oversights on random array degrades/crashes besides bad cables/backplanes. For researchers: /drivers/ata/libata-core.c is the one to look into. There are some (old) drives applied with mitigation quirks. Still... I do not take responsibility on data corruption, use at your own risk. Perform full backup before committing anything. -
new sata/ahci cards with more then 4 ports (and no sata multiplexer)
vbz14216 replied to IG-88's topic in Hardware Modding
Reporting on disabling NCQ to workaround FPDMA QUEUED error, so far so good. I found a variant of libata kernel cmdline that disables NCQ on individual ports: libata.force=X.00:noncq,Y.00:noncq Wheres X,Y and so on(separated with comma)= the port you're disabling, can be checked from: dmesg | grep -i ATA It's the way to disable NCQ before scheduled tasks can be executed. I prefer this plus writing to queue_depth via power on task just to be safe, though queue_depth should already be 1 if you have done the kernel cmdline. (i.e. you have messed up your system partition or forgot to put the kernel cmdline after rebuilding your loader) I also tested hdparm but as expected, disabling NCQ from hdparm doesn't persist between reboots so it's better to disable via kernel cmdline. As for md* resync I previously mentioned(md1), that seemed to be a quirk with the built in performance benchmark. (I checked performance after disabling NCQ.) It's a false alarm but still a good idea to check if there are other ata errors that kicked your drive(s) out from unrelated errors. -
new sata/ahci cards with more then 4 ports (and no sata multiplexer)
vbz14216 replied to IG-88's topic in Hardware Modding
Recently I got some used WD Red drives(WD20EFRX) and found the same dreaded FPDMA QUEUED error(from /var/log/messages). I can confirm the drives are healthy from Victoria scan and smartctl EXTENDED scan. After googling around I still can't find a definitive answer. The big focus is around WD drives then other branded drives including SSDs and brand new drives. Some physical solutions/speculations are almost snake oil but some point into libata's "somewhat buggy"(don't take my words for it) implementation indicated from this git issue on openzfs: https://github.com/openzfs/zfs/issues/10094 You might want to check if some md* recovers each time you power up(with FPDMA QUEUED error on last boot), I found out one of the partition from a WD Red got kicked out when I investigated in /var/log/messages. I got md1(swap?) recovers but good thing the storage volume didn't degrade from it. Of course the easiest way is to use SAS HBAs that use proprietary drivers like mptsas found on LSI cards, which should bypasses this. But I use Intel onboard SATA ports, don't want to deal with extra heat and power from a SAS card. Disabling NCQ from kernel cmdline is certainly the nuke-it-all solution but I have other drives that doesn't suffer from this problem. So I found out you can "disable" the NCQ on individual drive(s) by setting queue_depth parameter: echo 1 > /sys/block/sdX/device/queue_depth Wheres sdX is your hard drive that you want to disable, the default is 31 and we're lowering it to 1 which effectively disables NCQ. Do keep in mind this gets reset between reboots so you should schedule a power-on task with root privileges. i.e. I wanted to disable NCQ on drive sdc and sdd, just use semicolon to separate the commands: echo 1 > /sys/block/sdc/device/queue_depth ; echo 1 > /sys/block/sdd/device/queue_depth I do not take responsibility on data corruption, use at your own risk. Perform full backup before committing anything. I'm not sure if FPDMA QUEUE errors can cause severe data corruption or not but better safe than sorry. I already did a load of defrag, data scrub and SMART tests to check this. Another way is using hdparm -Q to set it from firmware level but I don't have any experiences with hdparm and some drives might not support it well so there's that(i.e. does not persist after power cycle). I will keep monitoring /var/log/messages and see if FPDMA QUEUED error still pop up. -
https://forums.freebsd.org/threads/patching-igc-driver-to-support-killer-e3100g.86080/#post-577571 It indeed is a realtek NIC in disguise.
-
wjz304 is doing god's work but toxic people ruining devs' hardwork is so common and I hate seeing this again. With fbelavenuto taking a long break it made me fear if the same thing happened to him as well. (not saying it happened, just something that came to my mind) Please ignore the toxic people and keep doing what you're passionate with.(请无视毒瘤,做你喜爱做的事就好) If you're having trouble dealing with toxic people, the community is always at your back.
-
The SCU SAS ports seem to be managed by Intel's RSTe and doesn't use common extensions like AHCI. You need an extension called isci (not to be confused with iscsi) to activate them. See if disabling Option ROM from mobo BIOS can alter RSTe mode or else you need to compile an extension for the platform.
-
DSM4.2 was the final release for 2009 based platforms. 4.2-3259 is the lastest one for DS509+.
-
That looks like a hot mess. I had a feeling that your USB3 enclosure is acting up from the heavy load generated by RAID reshaping. IMO I would stop tampering with the array, imaging the individual drives to raw images and see if the data can be mounted by ordinary Linux distros. Too bad I'm not an mdadm specialist, see if there are other specialists that can help you, good luck.
-
IIRC the reason why it displays high memory usage is caused by VM previously committing that amount of RAM, it's quite interesting as TCRP doesn't exhibit the same phenomenon. The one and the only solution to have accurate memory consumption counter/display on PVE is to have "QEMU Guest Agent" installed in VM, though I haven't seen any implementations in Xpe. It's also the reason why the "memory ballooning" option does nothing.
-
https://www.phoronix.com/news/Intel-i219-LM-Linux-60p-Fix Coincidentally the driver fix has been announced a few days ago, i219-LM and i219-V are pretty much identical(can be modded with EEPROM tricks) and shares the same e1000e driver.
-
Best wishes to you, take care and have a break so you don't get burned out between projects and personal life.
-
TinyCore RedPill loader (TCRP) - Development release 0.9
vbz14216 replied to pocopico's topic in Developer Discussion Room
There's a typo with an action listed from rploader.sh . Usage: ./rploader.sh <action> <platform version> <static or compile module> [extension manager arguments] Actions: build, ext, download, clean, update, fullupgrade, listmod, serialgen, identifyusb, patchdtc, satamap, backup, backuploader, restoreloader, restoresession, mountdsmroot, postupdate, mountshare, version, monitor, getgrubconf, help The <action> listmod is a typo, listmods is the correct one. After trying out ARPL for a week on my Proxmox system I still go back to TCRP, maybe I'm just too used to rebuilding loaders as a confirmation when I reconfigure anything. Though ARPL's GUI interface is a really sweet addition, no hassle with backup/restore actions like in TCRP. -
FYI for those encountering TX problems(slow speed when pulling file from NAS to PC, around 60~95MB/s with high CPU usage) on RTL8111 series NIC, select rtl8168 driver(called module) instead of rtl8169 or vice versa.(Don't select both so you can force the exact one you want.) Double check with 'lspci -knn' from terminal/shell on NAS side, see what driver is loaded. (Found this fix the hard way by debugging betweeen proxmox KVM and baremetal setup all day, with corrupted system configuration and DSM reinstalls in between...) If nothing helps you might need to fiddle around with 'ethtool -K ethX tso off'(X=0/1/2... depending on your NIC number) or turn off different TX features(check with 'ethtool -k ethX') from terminal/shell on NAS side as a workaround. My Intel I219V with e1000e driver seems to be affected by 'TSO on' as well, though I checked this one while debugging with TCRP, I'm too lazy to experiment with that from ARPL again. If the workaround is good, you should be getting consistent ~110MB/s transfer speed from NAS to PC.
-
H81 chipset, right? Both Intel's H61 and H81 had 2 ports hardcoded as disabled. But the disabled ports were still exposed on software side, this can make DSM complain about internal disks being broken. Fortunately they are positioned after the first 2 ports so you can use SataPortMap=1 or 2 to install DSM, then rebuild the loader with SataPortMap=6(should be 6, if not then try 4) and remap the latter 2 working ports into drive 3 and 4.(use sata_remap=4\>2:5\>3 ) There were some motherboards where the first ports are disabled(usually mapped into M.2 ports), making it almost impossible to get baremetal working, unless you use Device Tree platforms. Method from @ikky_phoenix:
-
Tough one since Synology removed the VGA port on newer models. Your only hope would be hooking up a UART adapter from the debug header and see if anything fun comes up on the serial console. But you might just see GRUB boot prompt(no BIOS menu), dmesg and that's it. I'm always curious if you can gain complete access to the system if you try to hook up a graphics card from the M.2 slots or PCI-E slots(intended for NIC) on new models. DVA3221 also has a GTX1650 but the display outputs weren't intended to be accessed by the user and were blocked off by the case. Do not plug PCIe cards on the "looks like PCI-E slots" for HDD and eSATA backplane, it's very possible those weren't wired with normal PCIe lanes. Your best bet would be removing the original USB DOM, put a USB drive loaded with TCRP and see if TC boots up so you can SSH into it through LAN. UART connection might be handy to troubleshoot the GRUB boot selection. See if holding RESET button when you press power button does anything different, some headless systems allows you to temporarily override boot device when you do this but you need to check every USB port.(The feature might be programmed to work on a specific USB port.)
-
RedPill - the new loader for 6.2.4 - Discussion
vbz14216 replied to ThorGroup's topic in Developer Discussion Room
Very interesting but also frustrating at the same time. H61 only come with 4 SATA ports. But the problem is that Intel states "SATA ports 2 and 3 are disabled" in the datasheet. It's possible those ports are hardcoded as disabled but still visible from software side(hence bad ports). Try if you can install DSM by overriding SataPortMap=4(and 6 if that doesn't work), if not then you're out of luck for baremetal. H67, H77 and B75 boards are dirt cheap nowadays so it's a good solution.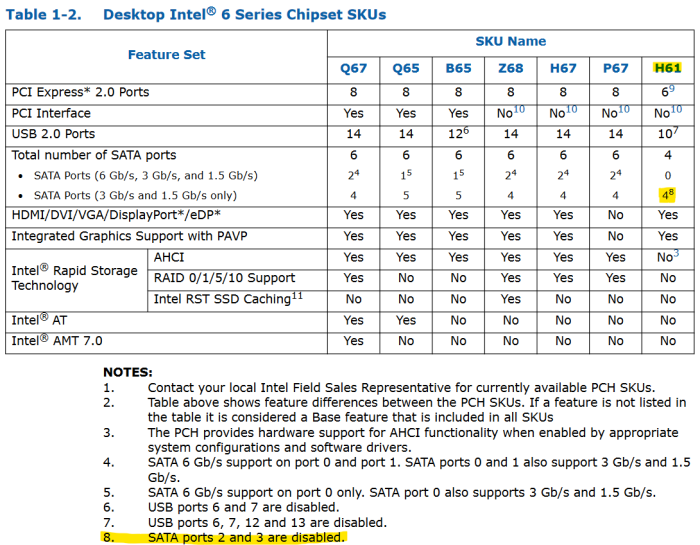
-
The mobo is from one of the hoax/scam mining machines by 蝸牛星際("Space snails"), you're better off looking at baidu and Chinese forums. Some dudes actually soldered 88SE9215 and corresponding parts to enable more SATA ports. https://blog.csdn.net/lun55423/article/details/121513923 A common problem is that the 2 SATA ports from J1900 are getting disk errors while installing DSM, particularly that mSATA slot. The problem was probably caused by mSATA not supporting hotplug(and you can't enable it, unlike the other port). Install drives into the port/slot will mitigate that issue. Changing it from AHCI to IDE, enable it after DSM install might also work. SATA Port multipliers are not supported by DSM and there hasn't been workarounds to crack that limitation. Only Synology's own DX/RX boxes(with port multiplier, SAS expander and possibly custom firmware) are going to work. Phased out(EOL) boxes might give you just individual eSATA disks that cannot be put in any RAID modes. I guess Synology is very serious about data integrity as putting RAID on the external drives+internal drives can be crazy risky, so only their validated solution will work, which is their own design. A little bit out of topic but good read regarding space snails scam: The space snails(蝸牛星際) scam is pretty much about mining digi stuff(IPFS related) with their disk boxes, to lure uninformed people into buying their machines.($700+ each) Think of it as Chia precursor but scammy tactics on steroids and dialed to 11.("passive income", hooray?) The disk boxes were cheaply made but are of incredibe good value for NASes after the scam was collapsed, those were bought as scraps and resold as barebones NAS solution. Good article in Chinese, translate to read some next level scam tactics: https://awtmt.com/articles/3496039
-
If leaving that slot empty doesn't work... Trying an M.2 SATA SSD in M2_2 slot would be your last resort(before going virtualization).Too bad the BIOS doesn't allow you to force device mode on that M.2 slot(e.g. SATA or PCIe mode instead of Auto detect) so you won't have to buy an M.2 SATA SSD. Even then it's still possible the other port(the other unused SATA bus) was hardcoded as DUMMY port. For the portcfg tricks, they were pretty much used for post-install tweaking. It could be used to fix internal SATA ports recognized as eSATA ports by DSM, USB drives recognized as internal disk(vice-versa? haven't seen anyone done this before) or adjust incorrect disk numbering. For advanced uses it can purposely change internal SATA to eSATA for NTFS support and use USB drive as internal disk. But you normally tweak them from /etc/synoinfo.conf and /etc.defaults/synoinfo.conf post-install. The idea at here is DSM won't be installing system files onto eSATA and USB drives so DSM might not be complaining about internal disks being broken. Also DSM isn't able to perform SMART checkups on USB drives, or at least the feature is non-functional. Flyride already tested it but if you want to try(and no important data to lose), here are the attributes. Put them in between "synoinfo" and "maxdisks" lines in user_config.json(change 0x1234 and XYZ for your own configuration) Example: Unfortunately there are very few tutorials on how to properly configure them per-system and some good ones are not in English. https://xpenology.club/fix-xpenology-problems-viewing-internal-hard-drives-esata-hard-drives/ TBH I never properly understand how portcfg workes in-depth other than hex/bin conversion as they can be motherboard specific, might need trial and error even in post-install situation.
-
I see @Deniska has a Kingston A2000 NVMe SSD in there with Windows installed, is that SSD plugged into M2_2 slot?(The one closer to PCI-E x16 slot.) Try taking that SSD out from M2_2 and see if it made any difference. You have a 10th gen CPU so M2_1 slot won't be available, that's why you have to use M2_2 slot. H570M-ITX has 4 SATA ports and 2 M.2 slots: 1 M.2 slot is directly routed from the CPU(M2_1) but only available to 11th gen CPUs, another one is from PCH. There are 6 SATA ports available(max) to H570 according to Intel's specsheet and the board seems to route one of the unused port for M2_2(so SATA SSD can be supported without swapping out from the remaing 4 ports). This, I assume putting devices into that slot will change the state of those unused ports. I'm thinking about the old tricks with internalportcfg, esataportcfg and usbportcfg that allows you to convert the SATA ports into eSATA/USB drives(as recognized by DSM), maybe change the first 2 ports into eSATA/USB then DSM won't be complaining about internal disk as broken? But it's a complex conversion(hex/binary numbering involved and potentially DiskIdxMap attribute?).
-
I just toyed around with DS918+ loader yesterday on 5775C+H97(baremetal, clean install, TCRP v0.8) and same Recoverable state problem occurs when I tried to install DSM7.1 with the nano packed pat file. I assume DSM tries to go directly into the newest update whenever it can. Try disconnecting ethernet connection(WAN) when you're prompted to upload the PAT file, I did that and successfully installed DSM.
-
Just successfully migrated from 7.0.1 DS3615xs(bromolow) to 7.1.0 DS3622xs+(broadwellnk) on my baremetal D510 setup, pretty much a drop-in upgrade without any hitches. Intel Atom D510(i915 driver+e1000 driver, ICH10R with no HBA installed), 2HDDs and 2GB of RAM Seems legacy/non-UEFI systems shouldn't have to worry about compatibility when migrating even if they're on ancient system. Still, I used a spare USB drive and hard disk for testing so no data loss risks are involved.
-
There's a new small DSM update for 7.0.1-42218, Update 3. I just reinstalled DSM on my J1900I-C test system(baremetal) paired with TC v0.4.5 on DS918+ loader(apollolake-7.0.1-42218), result seems to be SUCCESSFUL which updated itself to Update 3 after initial pat install. Also my ancient D510 system(baremetal) works fine(bromolow-7.0.1-42218). Weirdly enough TC loads into desktop without problems on J1900's HD Graphics(Gen 7, device id 8086-0F31) now
-
Toying around with an ASUS J1900I-C that just arrived at my doorsteps, I found that Tinycore desktop doesn't play nice with the HD Graphics(Gen 7,device id 8086-0F31). Which results in "failed in waitforx" error message after the randomart image. Startx doesn't work at here. I plugged in a generic GT610(Fermi) and got into TC desktop, however the auto device detection won't find the HD Graphics.(as the current display adapter is from Nvidia) This means the compiled loader won't contain i915 driver. So I took the dGPU out and proceeded with the HD Graphics under TC's text only mode, the script did bring up i915 driver and compiled the loader without problems. (The i915 driver is required in order to have GPU h/w accelerated apps working e.g. VAAPI encoding for Jellyfin, /dev/dri will show up if you have working iGPU driver.) The DS918+(apollolake) 7.0.1-42218 loader works fine for J1900, even automatically updated to update-2 after installation finished.
-
Just wanted to say thank you for such an amazing project, your automated script is a lifesaver! No need to be a Linux guru to build the RedPill as the automated process made everything a walk in the park. (I had experiences with vanilla hackintosh but building RedPill from scratch is next level stuff.) My setup runs on an ancient Intel Atom D510(i915 driver+e1000 driver, no HBA installed), 1HDD and 2GB of RAM, I originally wanted to have 6.2.4 running on bromolow w/ Legacy boot on baremetal as DSM6 is more mature. Got into 6.2.4 DSM desktop but updating to 6.2.4 update-4 always fails(recovery loop), not sure what the culprit was. Bit the bullet, kept the user_config.json, built bromolow-7.0.1-42218 and update to 42218-2 worked without problem(s). Small tip for anyone encountering "missing files error" when building the bootloader, use "./rploader.sh clean now" and build the bootloader again so all assets can be re-downloaded.

