WiteWulf
-
Posts
423 -
Joined
-
Last visited
-
Days Won
25
Everything posted by WiteWulf
-

RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Sounds like your system isn't bringing up the network, then. Check that your hardware is supported. If you post full details of your system people here can probably let you know what's supported or not. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
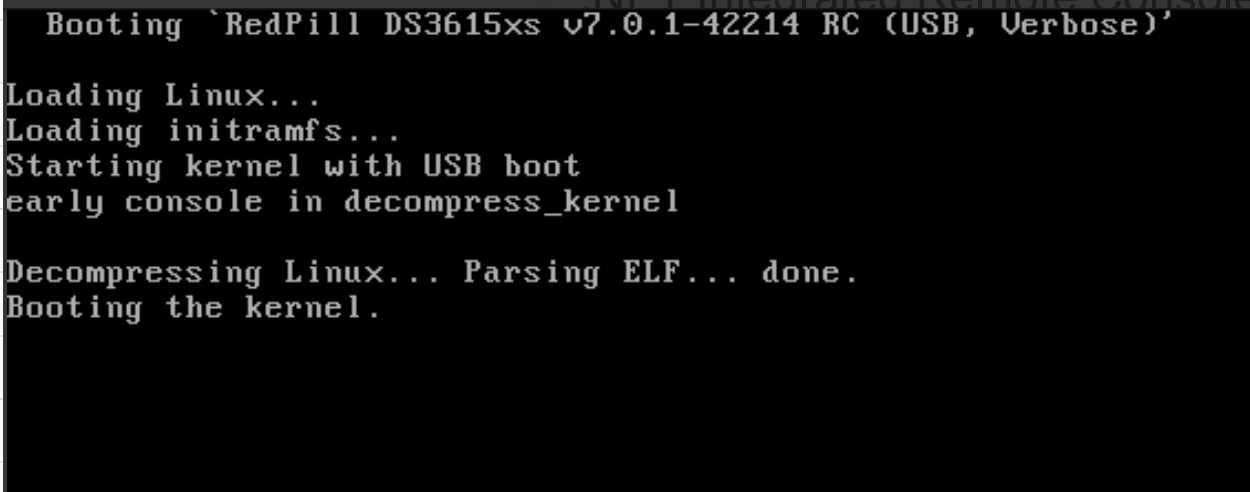
You seeing something like this? If so it's not hanging, it's just there's no more output to the screen from that point as there's no frame buffer driver in the Synology kernel. Jun's bootloader used to put a message on screen to this effect, something that would be quite helpful in redpill, too, I think. Further boot information is output to the serial port. If you're on a machine with a physical serial port you can view it there. If you're using ESXi or proxmox you'll need to attach a virtual serial port. If you're using some server-grade hardware with lights-out management you may be able to attach to it via ssh or web UI. You should be able to connect to the server's web UI once it boots and gets a DHCP lease, though. Have a look in your DHCP server logs to find it's IP address, or use the Synology Assistant tool to find it.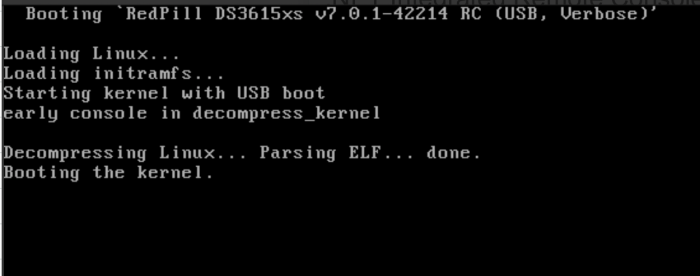
-
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
The docker crash behaviour seems to be quite specific to individuals' set up. A few people here have tried to run influxdb, at my suggestion, with no problems, while it crashes my system each time. Others are having repeated problems with jdownloader2, which I tried and was completely stable. Since we're all running with different data, I think this may be influenced by the load generated by the docker containers causing ppl problems (Java and database containers seem particularly problematic) 🤔 Likewise, while influxdb causes me problems, I've several other docker containers that continue to run on my system without problems. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Everyone that's contacted me so far has been using either Xeon or Celeron CPUs, I've not heard from anyone with non-Intel CPU so far. Also, I (and others) extensively used docker on 6.2.3 and earlier versions on Jun's boot loader. These problems have only been observed on DSM 6.2.4 and 7.x since moving to redpill, and only on DS3615xs. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Hey people, please don’t share loader images 🙏🏻 They contain software that is the property of Synology and is not open source. ThorGroup specifically designed the toolchain and build process to download the freely available software from Synology’s own servers to build the images with. This way no one can be accused of redistributing Synology’s intellectual property, and potentially get the project and the forums shut down. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Simplez! -
docker causing kernel panics after move to 6.2.4 on redpill
WiteWulf replied to WiteWulf's topic in Developer Discussion Room
https://github.com/RedPill-TTG/redpill-lkm/issues/21 -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
https://github.com/RedPill-TTG/redpill-lkm/issues/21 -
docker causing kernel panics after move to 6.2.4 on redpill
WiteWulf replied to WiteWulf's topic in Developer Discussion Room
Quick update as no one in the main redpill thread seemed to want to move the discussion here As more people move to running redpill on their on their systems there have been additional reports of docker either kernel panic'ing on baremetal installs, or locking up the VM on proxmox and ESXi installs. A commonality seems to be that those running ds3615xs images are seeing crashes, while those running ds918+ images are stable. One user has run both 918+ and 3615xs images in the same hardware and observed crashes with the 3615xs image but not the 918+. Reports from owners of genuine Synology hardware suggest that docker is very stable under DSM7.x The captured output from a docker-related kernel panic was observed to be very similar to that in this Redhat open issue: https://access.redhat.com/solutions/1354963 Redhat indicates the problem was fixed in later kernel versions, although the kernel on DSM 7.0.1-RC1 appears to be later than the one referenced by RH. I think I've got enough to log an issue against redpill-lkm on GitHub now, so I'll do that and report back with any updates. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
@Orphée @nemesis122 @pocopico @erkify @dodo-dk You've all said you're seeing docker-related crashes on your systems. Some of you are on baremetal, some using proxmox or ESXi. Can you please confirm whether you are running 3615xs or 918 images? The trend (as spotted by abesus) seems to be that 3615xs setups are crashing while 918 are not. Please confirm and I'll log an issue on the redpill-lkm GitHub repo. It would also be handy to know exactly what CPU you have in your machines. (Some other people also mentioned they're seeing docker-related crashes, but I know they're on either HP Gen8 or Gen7 baremetal, so I know they're using ds3615xs images) -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Great feedback @abesus, I think we've got enough to log an issue on github now. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
I'm running: - domoticz - librenms - mysql - ubooquity (big Java app) ...containers with 100% stability now. It was just the influxdb one that was causing me problems. There was also a Grafana container that used the influxdb as a datasource, that I'm not using now, but that was always stable, too. That Redhat issue @abesuslinked to looks very much like what we're seeing. Shame it hasn't been updated for 5 years 😬 FWIW, feedback online from genuine Synology owners on DSM7 suggests that docker is operating perfectly for them. More evidence that this is somehow related to redpill. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Great, thanks for that. It's almost identical to what I was seeing with my influxdb container. It's good to see this happening across a variety of setups. So far I think I've had reports of it on: - baremetal Gen8 - baremetal Gen7 - Proxmox - ESXi -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
It's a database, that's all. I ran it for years on 6.x firmwares with Jun's bootloader and had no problems with it at all, but it crashes the same hardware with redpill (running 6.2.4 or 7.0.1-RC1) 100% of the time. Thanks very much for confirming that this isn't unique to my set up. Now I just need to figure out *why* it's causing so many problems. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Just out of curiosity: could those of you having docker problems (or even if you're running docker and not having problems) install an influxdb container and see what happens? It kernel panics my machine every time I run it, across multiple versions of the image. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
@Orphée I'm not seeing excessive CPU usage on my baremetal install, fwiw. Can you have a look at the output of 'top' and see what process(es) are responsible? -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Thanks for grabbing the console output 👍 This actually looks a little different to what I've been seeing (crashes with containerd-shim). Yours is indicating a problem with 'runs', and seems related to a thread I found while searching this morning: https://github.com/opencontainers/runc/issues/2530 This still manifests as problems with containerd. Some people are seeing reboots, some are simply seeing lockups. You really ought to update the BIOS on your Gen8, by the way , and check out whatever other firmware updates are available for it... -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
I saw these crashes when I first migrated to 6.2.4 and they persisted into 7.0.1-RC1 -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
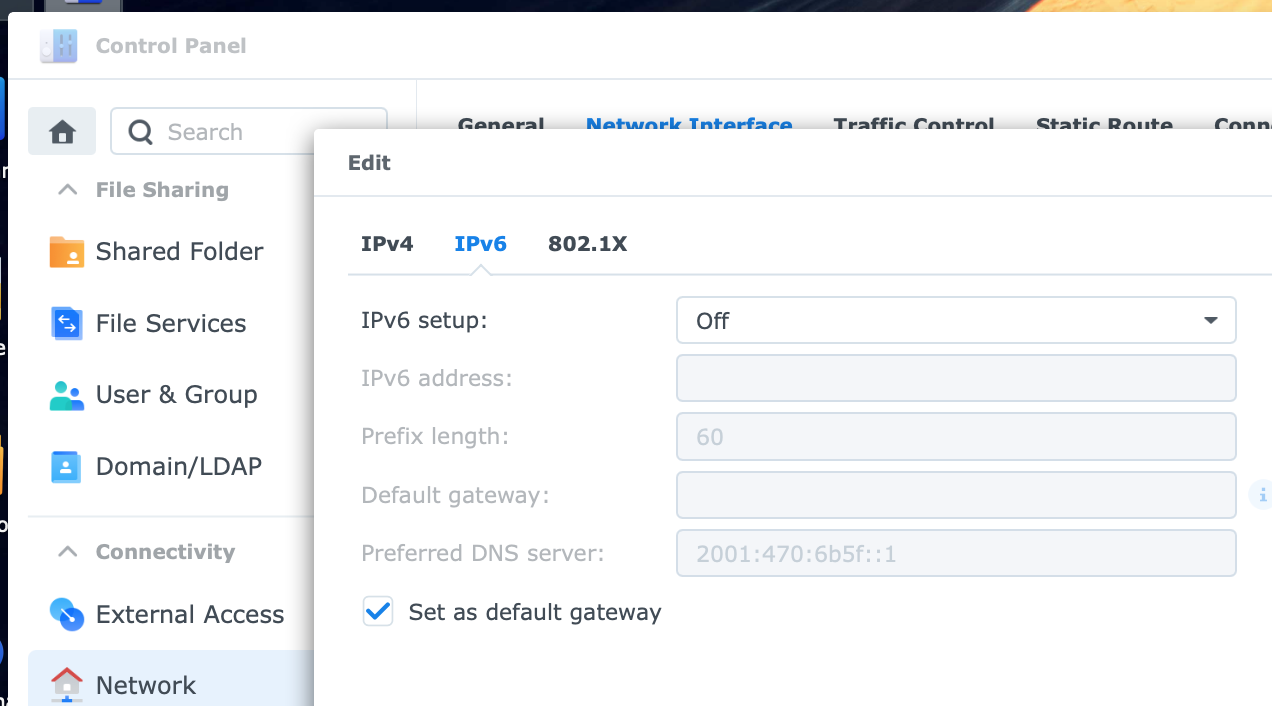
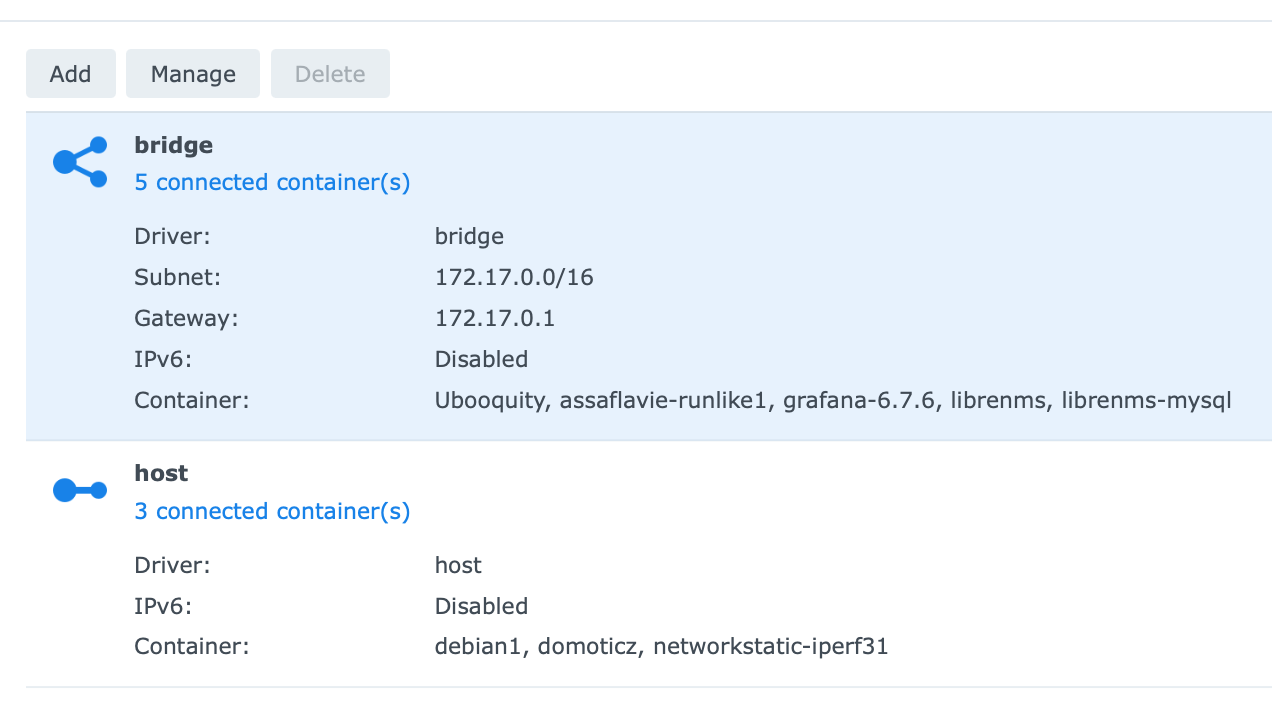
IPv6 is disabled in control panel on my system: ...but docker still tries to setup IPv6 networking for some or all containers when they start. IPv6 is also disabled on the docker networks on my setup: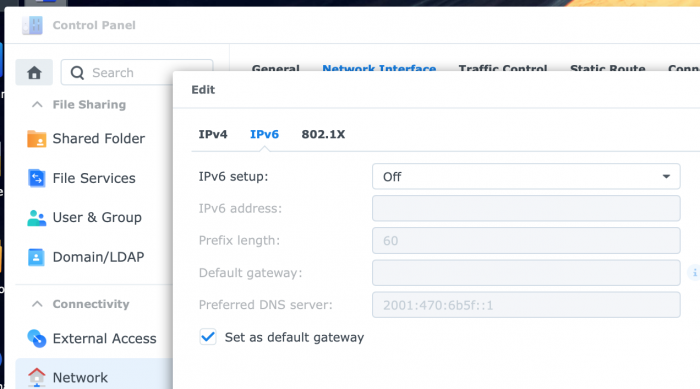
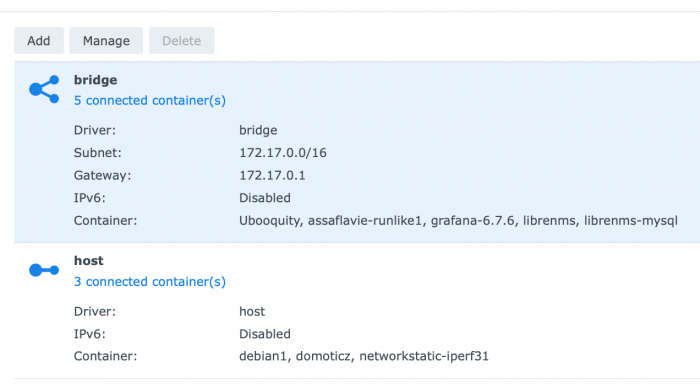
-
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
You need to build the apollolake target to get 918, bromolow builds 3615xs. Also, make sure your hardware (CPU and chipset) is compatible with apollolake. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Interesting that you're seeing this in ESXi, others have only reported it on baremetal so far. Are those messages from ESXi, or the xpenolgy guest? What are you seeing on the serial output from the xpenology guest? FWIW I was seeing output like this each time my system kernel panic'd and rebooted: [ 194.017549] Kernel panic - not syncing: Watchdog detected hard LOCKUP on cpu 2 [ 194.052575] CPU: 2 PID: 19580 Comm: containerd-shim Tainted: PF O 3.10.105 #25556 [ 194.094270] Hardware name: HP ProLiant MicroServer Gen8, BIOS J06 04/04/2019 [ 194.128400] ffffffff814c904d ffffffff814c8121 0000000000000010 ffff880109a88d58 [ 194.164811] ffff880109a88cf0 0000000000000000 0000000000000002 000000000000002b [ 194.201332] 0000000000000002 ffffffff80000001 0000000000000010 ffff880103ee5c00 [ 194.238138] Call Trace: [ 194.250471] <NMI> [<ffffffff814c904d>] ? dump_stack+0xc/0x15 [ 194.279225] [<ffffffff814c8121>] ? panic+0xbb/0x1ce [ 194.304100] [<ffffffff810a0922>] ? watchdog_overflow_callback+0xb2/0xc0 [ 194.337400] [<ffffffff810b152b>] ? __perf_event_overflow+0x8b/0x240 [ 194.368795] [<ffffffff810b02d4>] ? perf_event_update_userpage+0x14/0xf0 [ 194.401338] [<ffffffff81015411>] ? intel_pmu_handle_irq+0x1d1/0x360 [ 194.432957] [<ffffffff81010026>] ? perf_event_nmi_handler+0x26/0x40 [ 194.464708] [<ffffffff81005fa8>] ? do_nmi+0xf8/0x3e0 [ 194.488902] [<ffffffff814cfa53>] ? end_repeat_nmi+0x1e/0x7e [ 194.517219] <<EOE>> [ 195.556746] Shutting down cpus with NMI [ 195.576047] Rebooting in 3 seconds.. Most of the time is was containerd-shim that was named in the messaging, but sometimes it was the specific process within the container, influxdb. It was always my influxdb container causing the crashes, and my system has been very stable since I stopped trying to run it. I have done a lot of searching on the internet and can find no mention of influxdb in docker causing kernel panics, therefore I'm almost certain that this is unique to redpill. I used influxdb for years on xpenology using Jun's bootloader and have only seen this moving to redpill, on 6.2.4 and 7.0.1-RC1. Can we move this to the other topic I started, though? We're cluttering up the thread here... https://xpenology.com/forum/topic/47970-docker-causing-kernel-panics-after-move-to-624-on-redpill/ -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
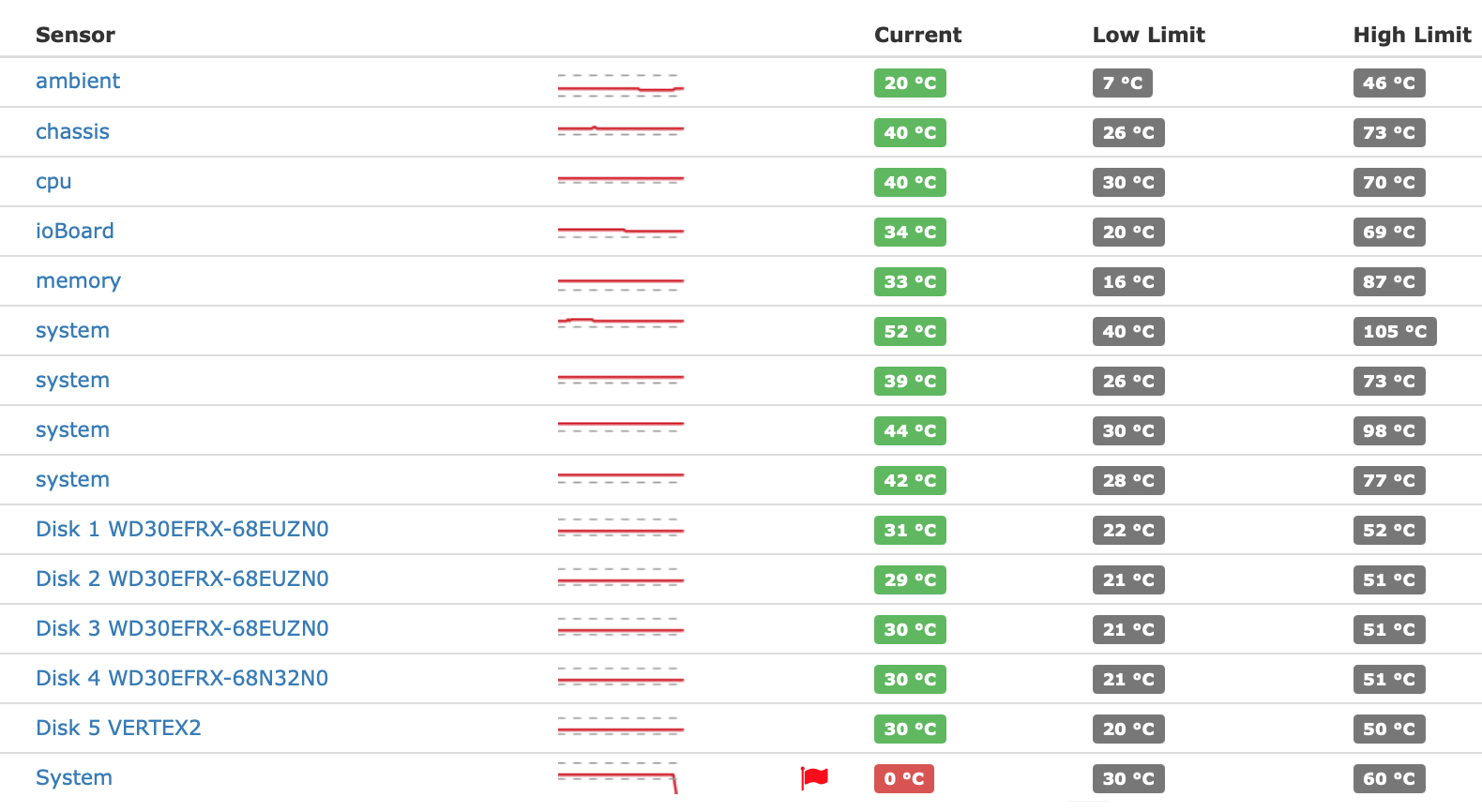
When I do this (or the command line equivalent previously mentioned), it fixes the empty General tab problem, but also seems to stop the system from polling the 'System' temperature, as I'm now getting alerts from my SNMP monitoring platform (LibreNMS) that the 'System' temperature is below the configured minimum: It seems the DSM is polling the temperature properly from the hardware sensors (as it was exposing them via SNMP, and the measurements match what I can see on the iLO), but it's apparently not parsing the value correctly, leading to the blank tab in General. On balance I'd rather have the correct data in my monitoring platform than the General information page in Control Panel, so I'll leave put it back as it was now, with 'supportsystemperature' and 'supportsystempwarning' set to 'yes'.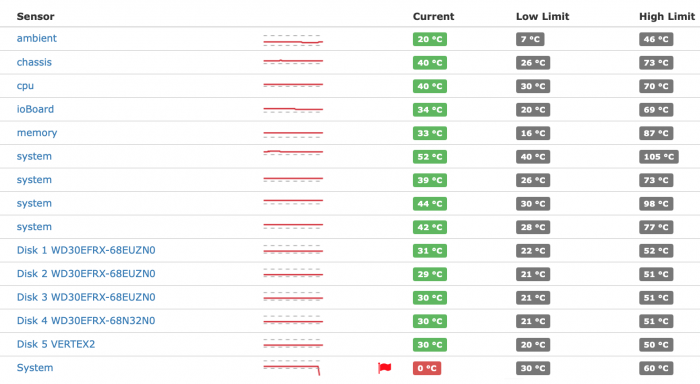
-
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Yeah, my fault, autocorrect on my initial post changed it to asp, but I went back and changed it to vsp. -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
You need to configure the iLO4 monitoring and management card that's built in to your Gen8. Here's a very brief overview: - connect the iLO port on the rear of your Gen8 to the LAN, it should DHCP and get an IP address - configure the iLO (outside the scope of this post, look it up online) - ssh into the iLO and run the command 'vsp', this will connect your ssh session to a virtual serial console There is plenty of information online about configuring the iLO as the Gen8 is so commonly used by hobbyists and for home labs. It's an invaluable resource to have on such a cheap home server and you should really learn how to use it 👍 NB. some people with Gen8s have observed the uart_switcher component of redpill incorrectly redirecting the serial console to a different tty, so you don't see any output after a relatively early part of the boot process. I'm not sure how to fix this -
RedPill - the new loader for 6.2.4 - Discussion
WiteWulf replied to ThorGroup's topic in Developer Discussion Room
Yeah, good point, only had one coffee so far today and hadn't thought of that I'll add it next time I do a boot stick rebuild. Of course it would be nice if the redpill shim could actually allow access to the monitoring hardware in the server and provide the temperature stats. I would have thought DSM was simply calling lm-sensors, but those tools don't appear to be on the system 🤔