

Peter Suh
-
Posts
2,646 -
Joined
-
Last visited
-
Days Won
139
Posts posted by Peter Suh
-
-
1 hour ago, Trabalhador Anonimo said:
Most like yes, but yesterday I rebuild from zero and get corrupted again. Shell I re-download m-shell VMDK?
Changing the subject: I try to connect via port 7681, but did not work. I get disconnected immediately. I could only connect via terminal after enable it on control panel.
It seems like you don't remember exactly what happened at the time? I think the same goes for me.
Does rebuilding from zero mean formatting the volume disk and starting from scratch?
SAN MANAGER corruption cannot be repaired by rebuilding only the loader.Sorry, but there is no solution right now.
It seems to be a problem even for genuine users that SAN MANAGER will suffer loss even if SHR's RAID is destroyed.
I hope that one of the genuine users will come forward and get help from Synology.
DSM no longer uses port 7681 during normal booting.
This is the same for RR. -
5 minutes ago, Tibag said:
Well, mine was installed this week so well after it and SAN Manager is un-repairable.
Does it make Storage Manager unable to start too?
That doesn't seem to be the case. It can be operated separately.
I'm not sure why Storage Manager fails to start.
Is there any problem with the free space in the /root path?
-
7 hours ago, Trabalhador Anonimo said:
Hi, I got SAN manager corrupted too. See it at this post.
Have you rebuilt and used the TCRP-mshell loader between December 28 and January 2 ?
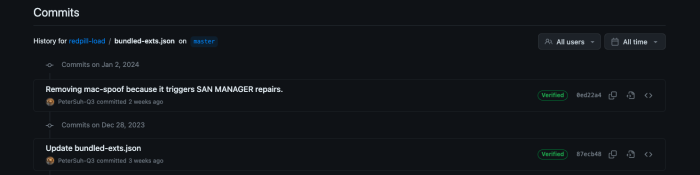
There was an issue with SAN MANAGER being corrupted only if the loader was built during these 5 days.
However, my Mac-Spoof addon may not necessarily be the cause.
Recently, I experienced SAN Manager being damaged for several reasons.
For example, if the SHR raid is compromised, the SAN MANAGER is also compromised.I think Synology should take some action.
The SAN MANAGER seems to be damaged too easily. -
1 hour ago, Trabalhador Anonimo said:
I have a disk that show itself on every boot, but few minutes later it disappear, so I cannot do a thing with it. Is there a way to solve this problem on a 3622xs+ bare metal?
Do not use sataportmap/diskidxmap without accurate information. You can also refer to the instructions that result from ./rploader.sh satamap .
-
3 hours ago, Tibag said:
To switch to mshell you mean switching back to your fork? Build a new loader? I don't think it allows me to pick 64570.
If so, proceed as you see fit. All you need to do is run the ramdisk patch (postupdate) no matter what loader you use.
-
9 minutes ago, Tibag said:
Well, because I am back to my previous loader it's the old one (Version : 0.10.0.0) not using your own build. So Friend doesn't load automatically, I think?
Do I need to do a postupdate maybe? Or use the Friend entry from my Grub?
Thanks for keeping up the help!
pocopico's friend is an old version. The ramdisk patch, which means automatic postupdate, may not be desired. Try changing to mshell.
-
12 minutes ago, Tibag said:
Yes it does always bring the recovery when it comes back.
Find attached the logs, hopefully it shows something useful!
Oddly, on the find synology I get:
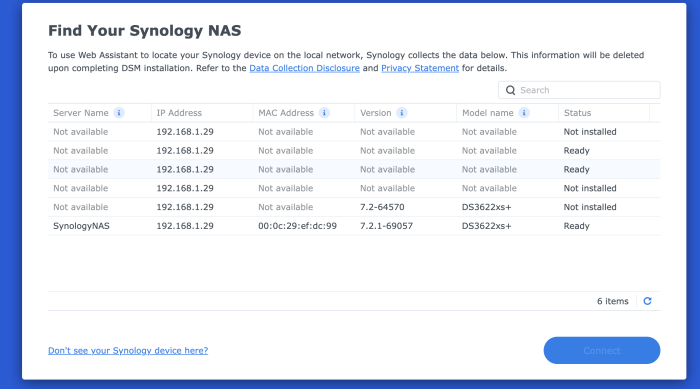
junior_1301.log
At the very end of this log, you can see that a smallfixnumber mismatch has been detected. This is a completely normal detection. Now, normal ramdisk patching should proceed on the Friend kernel. It appears in yellow letters. Can you take a screenshot of this screen and show me?
Sent from my iPhone using Tapatalk -
3 minutes ago, Tibag said:
Thanks, will do. Regarding backups I have cloud backup of the data, settings too, so no risk here (apart from more time wasted).
Actually the recovery doesn't work, oddly. I get that screen:
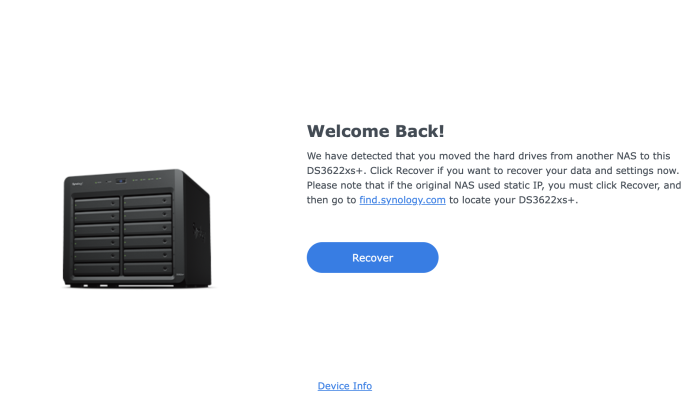
Then after the restart (I can see it reboots) then nothing happens.
Any idea why?
In a recovery action, essentially nothing happens.
Does the recovery happen over and over again?If so, please upload the junior log like you did yesterday.
-
5 minutes ago, Tibag said:
Oh that I am 100% sure, I did something wrong at some point. I am always lost in the few options at our hands when it comes to upgrade. Last time I did jump to 7.1 I also spent hours to get it back to normal.
Yes I still my old TCRP and I just tried it. I built DSM 7.2.0-64570 with all the disk in and it detected it as recoverable. The recovery process just started, let's see. 🤞
If it does recover, what do you suggest to move to 69057?
Please check the parts that were problematic yesterday.
Is the /root directory really full?
And above all, back up your DSM settings separately.
If full backup is not possible, at least perform a selective backup of only packages using hyperbackup.
I make these backups every day on Google Drive.
It can be used for recovery if the DSM of the system partition is initialized due to an unexpected accident.
I think you should focus more on preparing in advance rather than upgrading. -
6 hours ago, Tibag said:
Well, I think my DSM is now properly destroyed. I attempted to mount my disk on Magic Parted to try to explain the disk space problem, to no avail. Then, after starting again TCRP it's now not finding my disk anymore. So... the disk is probably unusable anymore. I can't tell anymore what's caused the whole thing but if I could drop myself a message 1 week ago I would convince myself to never upgrade anymore! I strongly suspect that when there is an error during the upgrade DSM keeps uploaded file on the system partition. So actually if you try multiple times you get closer to a fully bricked system.
Current status for reference:
I suppose the next option is to start an install from scratch and try to add my disks back if DSM can restore them?
Although no work was done on the first volume disk, it is a little strange that the disk is not visible.
Is the number of disks displayed as ll /sys/block in tinycore linux always 4?If you don't see 4, you may need to recheck the cable connection.
The last method I would like to suggest is
DS3622xs+ is going back to DSM 7.2.0-64570.
Do you keep the original loader separately?
If not, you can rebuild it.I think it would be a good idea to go back to the original version, 64570, correct the problems, and try upgrading again.
If you rebuild the loader, recovery may be requested due to a smallfixversion mismatch, but this process is normal.
It should only be requested once. -
6 minutes ago, Tibag said:
Well, thanks for still helping!
If my memory doesn't fail me it's:
* volume1, made of the 2.73TB disk. It was the first installed so I am thinking this is where the /root is
* volume2 is a RAID of the other 3 disks
How can I access the data on the volume to clean them?
Yes something I can try, I guess I run the loader with only my 2.73 disk (volume1) in? And hopefully the upgrade passes and I can add back the other three?
Currently, only Junior is available, so there doesn't seem to be a way to clean up /root directly.
I think you should follow the latter method by dividing the group into groups and trying to upgrade with only one volume.
However, migration should be possible with only sata1. Never attempt NEW Install. Installed packages will be corrupted.
-
35 minutes ago, Tibag said:
@Peter Suh I tried to use DS920+, find attached logs, and this time I am getting another error bout some missing disk space:

I start to wonder if my data is recoverable at all!
There is no need to despair too much.
Your data disk is still safe.
Are there separate backups?
This is a message I also experienced some time ago.
This was a case where there were too many files in the /root path of the already installed DSM system partition.
When updating DSM, use this /root path.
You need to access the /root path of the system partition and organize its contents.
Of your two volumes, which disk is /root located on?
I think you need to try installing the two groups of volumes separately.
The remaining groups will be automatically migrated even if they are equipped later.
Would you like to try this method? -
11 minutes ago, Tibag said:
Yes 4 disks in total:
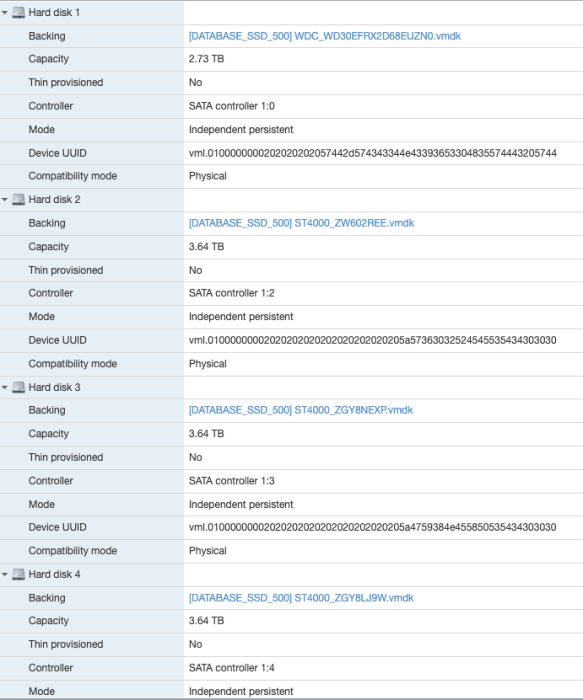
Essentially I had disk as 1 volume and the other 3 as another.
Could it be the face that I have no disks on SATA controller 1:1 as it does 1:0 -> 1:2 -> 1:3 -> 1:4?
Also, do you think trying a different loader like arpl-rr has chances of working better?
Without proper mapping, the disk may disappear and become invisible, especially on Non Device-Tree based models such as DS3622xs+.
However, since you can see all disks, I think your settings are fine.I know that rr is handled using a slightly different disk mapping method, but I don't know the details.
I'm not sure exactly how rr can help since all disks are already well recognized. -
On 1/11/2024 at 7:27 AM, Tibag said:
So I forked the repo and managed to build - the above PR will fix it.
So I am now on my next challenge. After the build it starts and suggests to migrate my disks. I upload my pat and during the process it fails with a corruption message. I check my logs and see:
There is a few posts about that but none makes sense. Any idea?
Assemble args: -u 0074c5b5:808d4c6e:3017a5a8:c86610be /dev/sda1 /dev/sdc1 /dev/sdd1 /dev/sde1 mdadm: /dev/md0 has been started with 3 drives (out of 12). Partition Version=8 Checking ext4 rootfs on /dev/md0 return value: 0 sdc, part of md0, has obsolete partition layout 8. Detected data partition on sda. Must not be fresh installation. ForceNewestLayout: Skipped Mounting /dev/md0 /tmpRootI saw the log you provided.
Are there only 4 discs in total?
It is also strange that disk mdadm started on only 3 of the 12 disks.
The sdc that is part of md0 has the deprecated partition layout 8.
Data partition detected by SDA. Do not do a fresh install.It looks like the system partitions between disks are mixed up.
If DS3622xs+ does not recognize all disks
In order to recognize all disks, it would be a good idea to first complete the DSM version upgrade to the Device-Tree-based DS920+.
After the system partition's mdadm is stabilized, it would not be a bad idea to change the model again and migrate. -
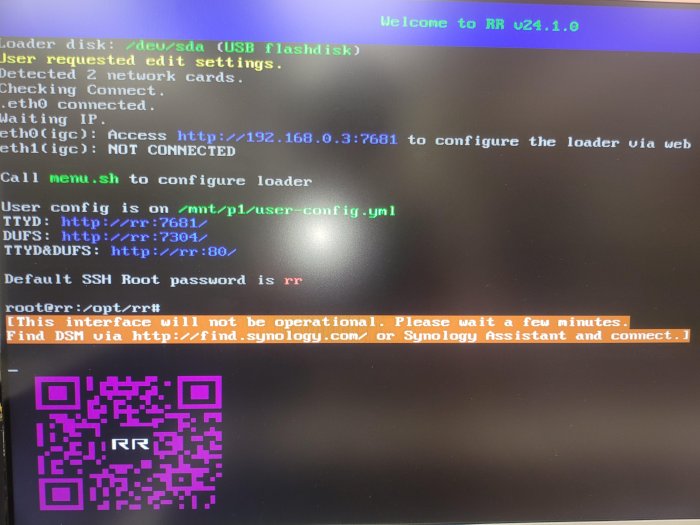
This motherboard uses dual IGC NIC, but the cable is not connected to the second NIC.
It is reported that junior did not appear at all,
Is this possible? -
3 hours ago, Tibag said:
May I ask how the IMG was built for ESXi ?
While I was still using ESXI, I personnally always took default IMG and used V2V starwind converter to convert it to FLAT ESXi VMDK file.
Never had any issues with loaders on ESXi with this method.
3 hours ago, Tibag said:I used the vmdk from Peter's repo and cloned it with vmkfstools on ESXI. Could that be the problem? It's a method I used before, I think!
My thoughts are a bit different.
proxmox uses img directly as a loader, but creates it as a Sata disk as if using SATA dom. Here, TCRP's ATA mode operates.
Synology's original bootloader is known to be SATA DOM, not USB.
I am not directly involved in the TTG group, so I do not know the exact mechanism of redpill.ko.However, based on the results of analysis and experience so far, it seems that the part that activates this SATA DOM in redpill is still unstable.
Rather, USB mode shows more stability as a result.
I don't know if USB mode is also internally connected to SATA DOM emulation again.
Currently, TTG members are not active.
Is there anyone who can explain this part clearly? -
1 hour ago, Tibag said:
Am I right in thinking that Junior should only kick in for a new installation? Like if my disks have a previous DSM version installed it shouldn't use Junior?
Junior is used for both new installations and migrations.
Junior determines whether a new installation or migration is possible by comparing the DSM version installed on the disk system partition with the DSM version to be installed. -
2 hours ago, Tibag said:
Thanks, I closed the PR.
Yeah I am on ESXI using SATA controller... I can't really move to Proxmox as I have various other VMs running on my ESXI.
Do you know any workaround?
I tried building the DS3622xs+ loader in SATA mode on my ESXI 7.0 Update 3 system.
I expected a 10 second timeout from my boot-wait and automount addons, but that wasn't the case.
The loader's three FAT partitions were successfully mounted on time.
The log below is part of Junior's linuxrc.syno.log.
Ran "boot-wait.sh" for thethorgroup.boot-wait->on_boot->modules - exit=0 :: Executing "on_boot" custom scripts ... [ OK ] ... :: Executing "on_patches" "patches" custom scripts ... Running "install.sh" for automount->on_patches->patches Found synoboot / synoboot1 / synoboot2 Ran "install.sh" for automount->on_patches->patches - exit=0 Running "boot-wait.sh" for thethorgroup.boot-wait->on_patches->patches Ran "boot-wait.sh" for thethorgroup.boot-wait->on_patches->patches - exit=0 :: Executing "on_patches" custom scripts ... [ OK ]The cause seems to lie elsewhere.
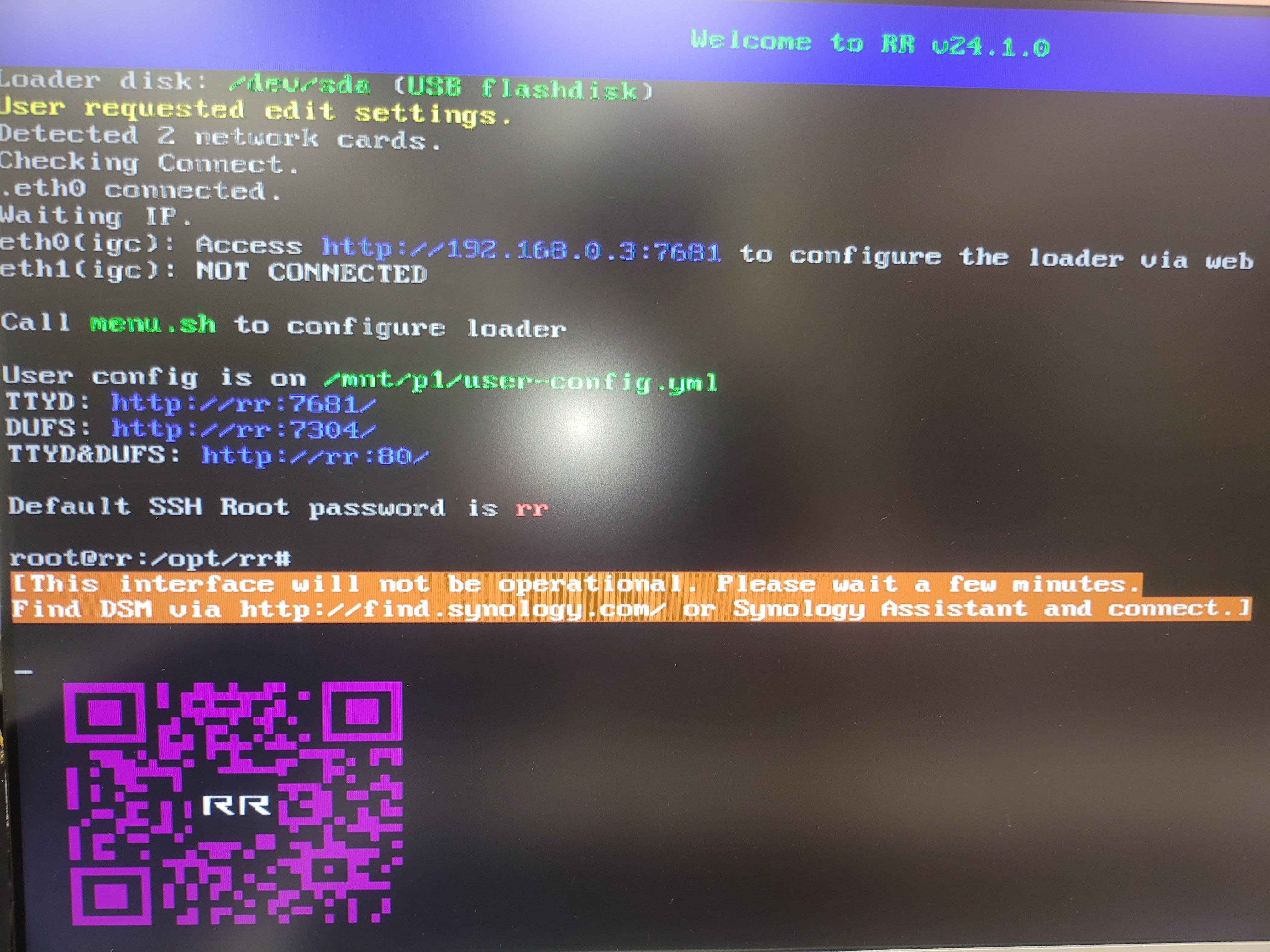
Is it possible to access port 7681 through a web browser?
This method is called a TTYD connection.
Log in as root without a password.
If connection to Junior is successful, can you send me the command log as below?
cat /var/log/*rc*
-
I'm sorry.
I found the cause of the error and took action.
Please try again.
-
 1
1
-
-
2 hours ago, Tibag said:
So I forked the repo and managed to build - the above PR will fix it.
So I am now on my next challenge. After the build it starts and suggests to migrate my disks. I upload my pat and during the process it fails with a corruption message. I check my logs and see:
There is a few posts about that but none makes sense. Any idea?
Are you by any chance building a loader on a VM like Proxmox?
The Pat file corruption message is directly related to the failure to mount three partitions on the loader disk.
This occurs especially frequently in SATA mode used by VMs.
If it is Proxmox, there is also a way to convert it to USB mode instead of SATA mode.
Please tell me exactly what your situation is.
-
8 hours ago, Tibag said:
Actually there was a commit after which changed the gz file - I suspect this is our culprit! https://github.com/PeterSuh-Q3/tinycore-redpill/commit/a97eb8527c416dfd17cb7f788f5245936ae03e41
@Peter Suh I created a PR for your repo: https://github.com/PeterSuh-Q3/tcrp-modules/pull/1
I was mistaken.
A tgz file should have been used here, not a gz file.
Only the sha256 content should not be changed.
The tgz file must have been recompressed and uploaded with new content.
The content has already been taken action.
Please withdraw your Pull Request.
-
I'm sorry.
I found the cause of the error and took action.
Please try again.
-
6 minutes ago, Trabalhador Anonimo said:
I´m having the same problem.
Do not use the build command directly.
The menu method below corresponds to the above error.
Please use the menu.
./menu.sh
-
1 hour ago, Tibag said:
Hi @Peter Suh
I've been trying your build for the first time, using ESXI, with the latest version (v1.0.1.0.m-shell) and when building ds3622xsp_64570 (or later) I get:
I couldn't find someone else with the same issue... any idea?
Do not use the build command directly.
The menu method below corresponds to the above error.
Please use the menu.
./menu.sh


TinyCore RedPill Loader Build Support Tool ( M-Shell )
in Software Modding
Posted
There is too little space.
First, to update DSM, a Pat file larger than 300Mbytes is written to /root, which may cause a file corruption error.
The file download stops in the middle.
Search for ways to secure space in Synology /dev/md0 on the Internet and apply them.