

TemplarB
-
Posts
37 -
Joined
-
Last visited
-
Days Won
1
Everything posted by TemplarB
-
It is reported that pre-2.92 version Transmission has a serious vulnerability: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-5702 Current version of Download station uses 2.84 as its base. Is there a way to update Transmission and still run Download station? Or only shift to Docker's transmission will do?
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: DSM 6.1.5-15254 - Loader version and model: Jun's Loader v1.02b - DS3617xs - Installation type: Baremetal (HPE Microserver Gen8) - Additional comments: No reboot required
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: DSM 6.1.4 15217 Update 5 - Loader version and model: Jun's Loader v1.02b - DS3617xs - Installation type: Baremetal (HPE Gen8) - Additional comments: Requires reboot
-
- Outcome of the update: SUCCESSFUL - DSM version prior update: DSM 6.1.4 15217 Update 3 - Loader version and model: Jun's Loader v1.02b - DS3617xs - Installation type: Baremetal (HPE Proliant MicroServer Gen8) - Additional comments: Requires reboot
-
HP ProLiant MicroServer Gen8 DS3617xs Jun's Mod V1.02b baremetal update ok
-
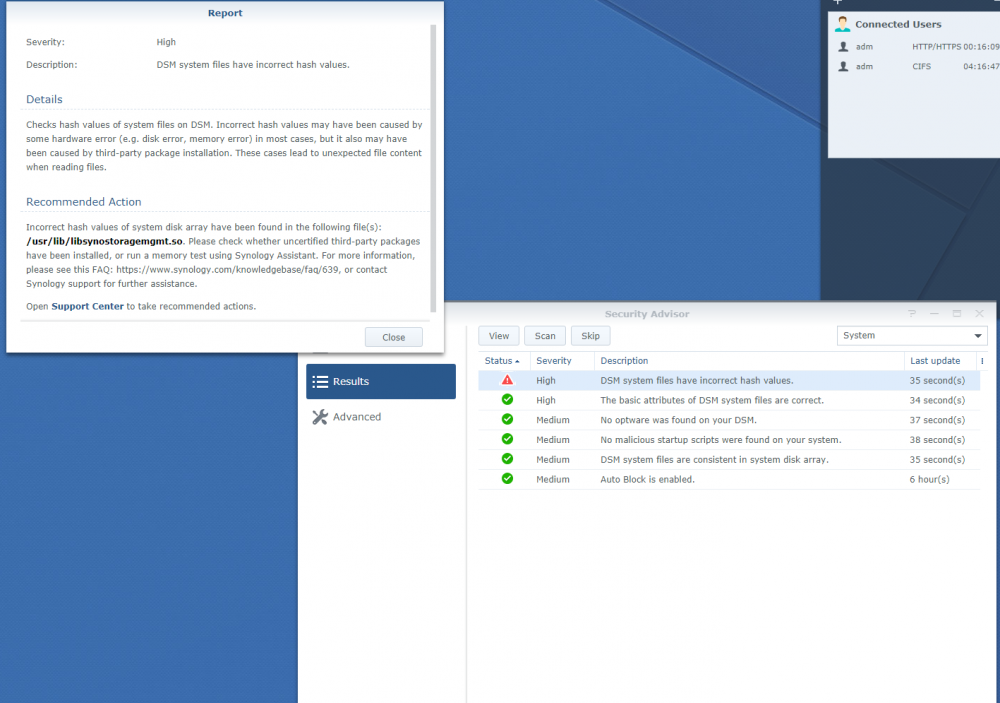
Problem solved! Ok, what happened and what people should try. Because while I had problems described in the first post, the system kinda worked, so I planned to migrate it on weekend. Thus on Friday I got a warning from the Security Advisor that DSM system files have incorrect hash values, more precisely, libsynostoragemgmt.so The file had the same size and date as in other, perfectly working server, namely: However, when I replaced it with a version from the working server, the system was able to reboot normally (previously only hard reboot helped) and is ok ever since. So, if you have a similar problem 1. Scan your system with the Security Advisor 2. If there are wrong hashes, replace the mentioned files, check that their attributes are correct 3. reboot
-
After I experienced some problems with my HP Gen8 baremetal Jun 1.02b installation of ds3617 [which described here - https://xpenology.com/forum/topic/9276-hp-gen-8-problems-with-‘system-health’-etc/?tab=comments] I plan to try to repair the situation by migration. On this site I read that people migrated successfully e.g. from 3617 to 3615, but I want to know whether it is possible to migrate [and safely transfer all data] from 3617 to 3617 by using reinstall option in GRUB loading menu that is present in the current installation. Or will this destroy/wipe/corrupt the data? Or the only way to have 3617 at the end is to migrate twice?
-
Update on the topic. As was mentioned above, similar problem occurred more than once after critical updates on HP Gen8 [supposedly with ds3617, but maybe 3615 too]. I have a pet theory of mine that the problem is not caused by a specific update but by server’s consequent reboot: people most likely reboot their servers rarely, thus while updates that led to the failure are different (it was 4, 5, 7 and 8 according to the forum history and it happened only for some, not all) the reboot is the common thing. Possibly that an update changes some config files or the like, I’m too much not a tech person to see the exact reason. However, I assume that the problem starts when the system decides after reboot to autodet RAID arrays. According to linux manuals this is an old feature that shouldn’t be used. It can detect only 0.9 superblock, but I have 1.2 superblock according to this: cat cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1] md2 : active raid5 sda3[0] sdd3[3] sdc3[2] sdb3[1] 4380946368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU] md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3] 2097088 blocks [12/4] [UUUU________] md0 : active raid1 sda1[0] sdb1[1] sdc1[2] sdd1[3] 2490176 blocks [12/4] [UUUU________] unused devices: <none> Hide so, it is not surprising it says in log sda3 does not have a valid v0.90 superblock, not importing! Any thoughts?
-
it seems possible that the problem is specific to HPE Gen8 The relevant part of dmesg log [ 8.332102] scsi 6:0:0:0: Direct-Access HP iLO Internal SD-CARD 2.10 PQ: 0 ANSI: 0 [ 8.333991] sd 6:0:0:0: [synoboot] 7862272 512-byte logical blocks: (4.02 GB/ 3.74 GiB) [ 8.335357] sd 6:0:0:0: [synoboot] Write Protect is off [ 8.335361] sd 6:0:0:0: [synoboot] Mode Sense: 23 00 00 00 [ 8.336618] sd 6:0:0:0: [synoboot] No Caching mode page found [ 8.336762] sd 6:0:0:0: [synoboot] Assuming drive cache: write through [ 8.342635] sd 6:0:0:0: [synoboot] No Caching mode page found [ 8.342779] sd 6:0:0:0: [synoboot] Assuming drive cache: write through [ 8.358119] synoboot: synoboot1 synoboot2 synoboot3 [ 8.364334] sd 6:0:0:0: [synoboot] No Caching mode page found [ 8.364495] sd 6:0:0:0: [synoboot] Assuming drive cache: write through [ 8.364656] sd 6:0:0:0: [synoboot] Attached SCSI disk [ 11.059264] md: Autodetecting RAID arrays. [ 11.097858] md: invalid raid superblock magic on sda3 [ 11.097990] md: sda3 does not have a valid v0.90 superblock, not importing! [ 11.127825] md: invalid raid superblock magic on sdb3 [ 11.127951] md: sdb3 does not have a valid v0.90 superblock, not importing! [ 11.166628] md: invalid raid superblock magic on sdc3 [ 11.166753] md: sdc3 does not have a valid v0.90 superblock, not importing! [ 11.227293] md: invalid raid superblock magic on sdd3 [ 11.227417] md: sdd3 does not have a valid v0.90 superblock, not importing! [ 11.227422] md: Scanned 12 and added 8 devices. [ 11.227423] md: autorun ... [ 11.227425] md: considering sda1 ... [ 11.227429] md: adding sda1 ... [ 11.227432] md: sda2 has different UUID to sda1 [ 11.227435] md: adding sdb1 ... [ 11.227437] md: sdb2 has different UUID to sda1 [ 11.227440] md: adding sdc1 ... [ 11.227443] md: sdc2 has different UUID to sda1 [ 11.227446] md: adding sdd1 ... [ 11.227448] md: sdd2 has different UUID to sda1 [ 11.227459] md: created md0 [ 11.227461] md: bind<sdd1> [ 11.227477] md: bind<sdc1> [ 11.227486] md: bind<sdb1> [ 11.227494] md: bind<sda1> [ 11.227501] md: running: <sda1><sdb1><sdc1><sdd1> [ 11.227687] md/raid1:md0: active with 4 out of 12 mirrors Hide
-
U7 for a week or so, w/o visible problems
-
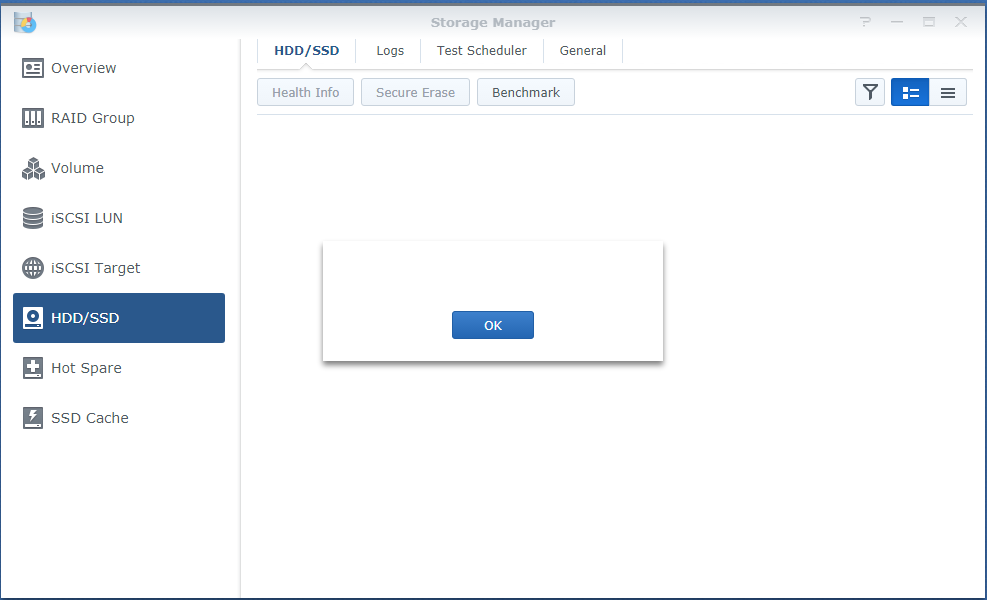
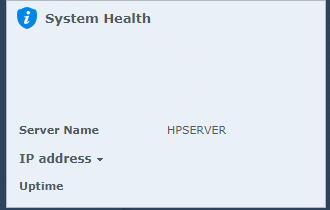
I’m a noob to NASes and thus what I’ll write below may sound stupid or inconsistent, but keep reading I have HP Gen8 with baremetal installation of DSM_RS3617xs_15152 and all critical updates up to DSM 6.1.3-15152 Update 8. The system has 4x 1.5Tb Samsung disk in Raid5, all SMART diagnostics showing healthy. I installed the latest critical update yesterday and the system restarted normally (or at least w/o informing me of any errors or warnings in the log). After about 12 hours of the system running smoothly I tried to open download station, but received a request to set it up (give default folders for files etc). At the same time, it was seeding torrents (I checked the trackers), so I decided just to reboot the system. The system hasn’t rebooted properly in 10 min, so hard reboot was used. After this the DSM started w/o complaint (except for the warning ‘System booted up from an improper shutdown.’). Download station started properly and without issues. However, ‘System health’ widget shows no info and when I try to open ‘Storage Manager’ it doesn’t show me any disks and auto-closes (crashes?) in a few secs after showing a small msg window w/o any text and ‘ok’ button. See screenshots below. Another reboot hasn’t helped, still had to be done in hard way and still no info on ‘System health’, etc. I can still access files and folders with Windows Explorer, disk station, audio and video station, so it seems there is no corruption. Logs are clear. Physically there are also no warning signs like whining HDDs. What can it be and what can be done? pics Hide
-
HP gen8, baremetal, update successful, but some problems started the next day, not likely to be caused by the update

