

Bibbleq
-
Posts
11 -
Joined
-
Last visited
Posts posted by Bibbleq
-
-
Will do,
I don't quite follow why mine is trying to mount against "/dev/mapper/cachedev_0"
Is that just a DSM version quirk or something else?
-
Yup agreed that it needs cleaning up and starting over, just trying to get it read-only so I can recover some bits first if at all possilbe.
That mount gives me:
:/$ sudo mount -v /dev/mapper/cachedev_0 /volume1 Password: mount: /volume1: wrong fs type, bad option, bad superblock on /dev/mapper/cachedev_0, missing codepage or helper program, or other error.So either it wasn't BRFS or it's fully hosed?
Would it have been working okay in read-only pre a reboot because something was loaded in memory/cache?
-
I believe it was btrfs
:/$ cat /etc/fstab none /proc proc defaults 0 0 /dev/root / ext4 defaults 1 1 /dev/mapper/cachedev_0 /volume1 btrfs auto_reclaim_space,ssd,synoacl,relatime,ro,nodev 0 0 -
Hmm so DF gives:
:/$ df Filesystem 1K-blocks Used Available Use% Mounted on /dev/md0 2385528 1256236 1010508 56% / devtmpfs 6049532 0 6049532 0% /dev tmpfs 6052968 4 6052964 1% /dev/shm tmpfs 6052968 27980 6024988 1% /run tmpfs 6052968 0 6052968 0% /sys/fs/cgroup tmpfs 6052968 1264 6051704 1% /tmpAnd yet
:/$ sudo mount /dev/vg1/volume_1 /volume1 mount: /volume1: /dev/vg1/volume_1 already mounted or mount point busy.I've done a couple of reboots (one I regret because when this first happened I read read-only access to teh FS and after the reboot lost it!), I've also now got a drive out the 4 drive SHR array (again bad idea that didn't help), so have the array degraded atm too.
-
First up, thank you
However this gives me a
# sudo umount /volume_1
umount: /volume_1: no mount point specified.So is it stuck in some kind of limbo?
-
Looking to mount the filesystem using a couple of the recover options per:
but getting an issue with it already thinking the volume is mounted. I see some different ways to unmount volumes depending on the version (this was DSM 6, now 7.0). Any pointers to what the right way to unmount Volume_1 would be to try bringing it back up?
Thanks
-
1 hour ago, Peter Suh said:
Are you a genuine DS918+ user?
If you have 4 disks of the same capacity, RAID 5 is more advantageous than SHR.SHR takes a longer rebuild time for recovery compared to RAID 5.
If Volume 1 is readable, you need to make a separate backup.Yes I'm on genuine hardware now but dabbled with xpenology previously and used it to help do drive upgrades before
I'm on shr but vol1 isn't readable at the moment
-
12 hours ago, IG-88 said:
i exchanged the sata cables to get rid of this
use dmesg to check the log if there is anything unusual or related in the time to the failure of the raid
Thanks, I've done a full SMART scan on the drives and no increment of the error counter so they seem okay for the time binging. Now concentrating on how to rebuild / rescue the file system info.
Any pointers or places to start?
Would the file system info be recoverable if I can identy what bit might have corrupted?
-
So apparently two of the drives have a "reconnection count" (seems to be source of udbm_crc_error_count in the SMART stats) of 5. Running a full SMART scan against them now (24 hrs to complete) and will physically remove/reinsert.
It looks like whatever caused the "bad connection" for want of a better word happened on two drives at the same time. I'm hopefull that that means there has just been some small corruption in a file table somewhere that might be recoverable. The stats for the drives otherwise look fine.
Slightly suspicious to get two occuring at the same time
-
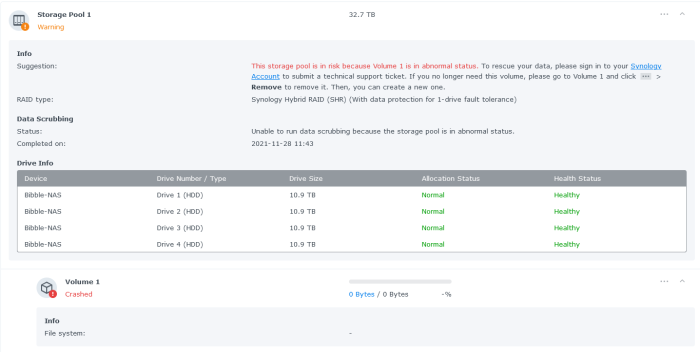
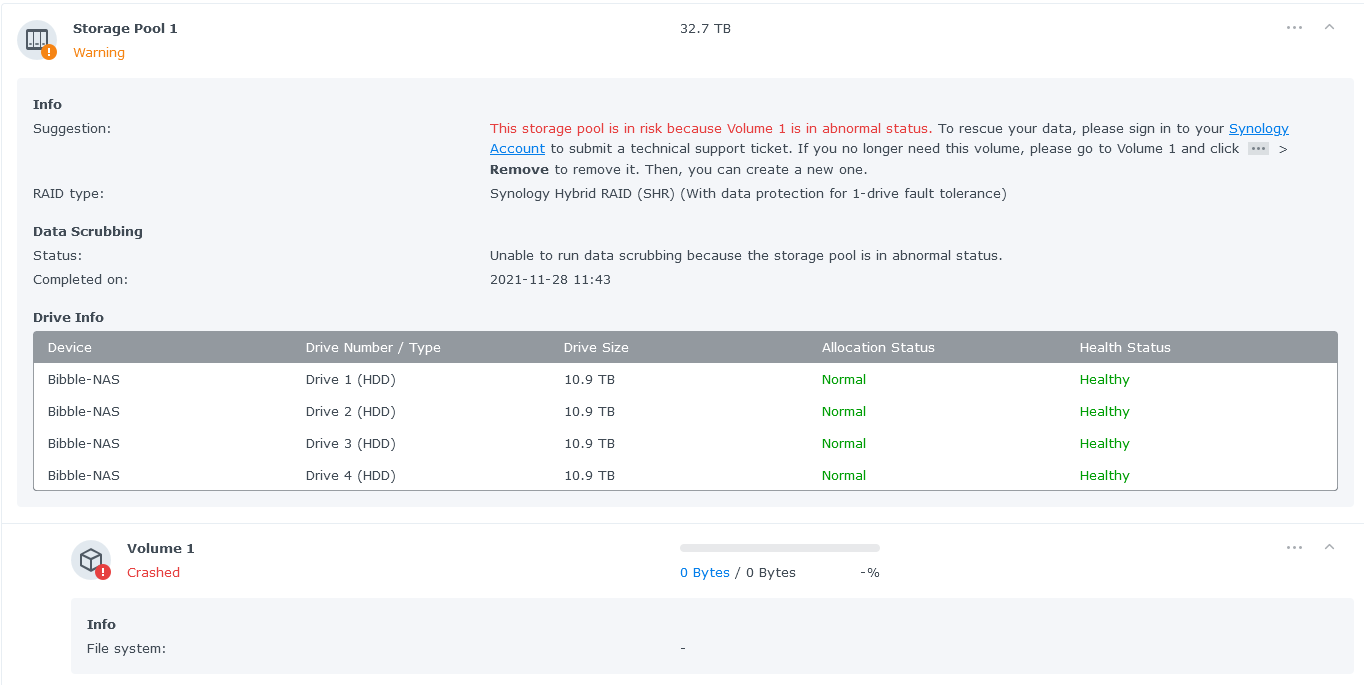
Would really appreciate some help with unpicking what might have happened here. I have a 4 drive (12TB) array that all of a sudden went read-only & has now "crashed" so that it isn't mouting any file system.
Device was running DSM 6 when the volume was created and migrated to DSM 7 successfully a few months ago.
While I have backups of the critical bits I'd like to work through what might be possible to bring it back to at least a read-only state to take more complete backups.
Given that there hasn't been a drive failure (all seem happy in SMART - but know that isn't perfect) or a PSU/power failure issue to spark corruption I'm hoping I might be able to kick things a bit back into life.
I've opened a ticket to Synology but as I have a background in computer stuff wanted to try and understand what might have happened. I'm also being cautious after a Qnap failure years ago where I made things worse!
Any pointers for picking through what might be wrong much appreciated.
VGDisplay::/$ sudo vgdisplay --verbose Using volume group(s) on command line. --- Volume group --- VG Name vg1 System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 8 VG Access read/write VG Status resizable MAX LV 0 Cur LV 2 Open LV 1 Max PV 0 Cur PV 1 Act PV 1 VG Size 32.73 TiB PE Size 4.00 MiB Total PE 8579626 Alloc PE / Size 8579587 / 32.73 TiB Free PE / Size 39 / 156.00 MiB VG UUID ox16tw-smba-XftF-ckPN-7aO6-tPaz-OFKU35 --- Logical volume --- LV Path /dev/vg1/syno_vg_reserved_area LV Name syno_vg_reserved_area VG Name vg1 LV UUID 15s7wM-Mp1w-o2qw-UV95-qp3u-8NKX-MZlNK2 LV Write Access read/write LV Creation host, time , LV Status available # open 0 LV Size 12.00 MiB Current LE 3 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 252:0 --- Logical volume --- LV Path /dev/vg1/volume_1 LV Name volume_1 VG Name vg1 LV UUID FpSGKA-76kU-3RsJ-rfwx-pona-3ydg-I4pII1 LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 32.73 TiB Current LE 8579584 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 252:1 --- Physical volumes --- PV Name /dev/md2 PV UUID d55Kcs-wujY-TVXZ-Fcyz-8jqd-J2ts-Id5iFv PV Status allocatable Total PE / Free PE 8579626 / 39LVDisplay:
:/$ sudo lvdisplay --verbose Using logical volume(s) on command line. --- Logical volume --- LV Path /dev/vg1/syno_vg_reserved_area LV Name syno_vg_reserved_area VG Name vg1 LV UUID 15s7wM-Mp1w-o2qw-UV95-qp3u-8NKX-MZlNK2 LV Write Access read/write LV Creation host, time , LV Status available # open 0 LV Size 12.00 MiB Current LE 3 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 252:0 --- Logical volume --- LV Path /dev/vg1/volume_1 LV Name volume_1 VG Name vg1 LV UUID FpSGKA-76kU-3RsJ-rfwx-pona-3ydg-I4pII1 LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 32.73 TiB Current LE 8579584 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 252:1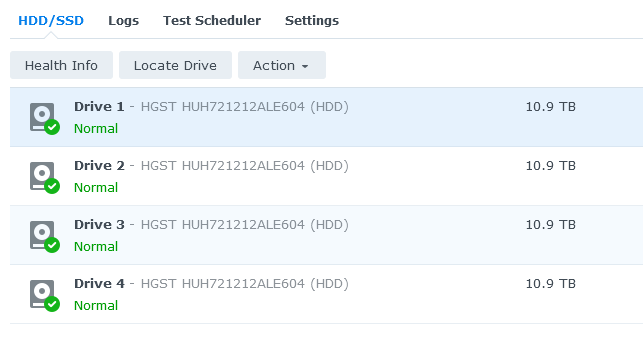
DSM 7 on DS918+, healthy drives but crashed volume
in General Questions
Posted · Edited by Bibbleq
For anyone following along in future (and indeed myself) I didn't have any success mounting the FS using any of:
sudo mount -o clear_cache /dev/mapper/cachedev_0 /volume1
sudo mount -o recovery /dev/mapper/cachedev_0 /volume1
sudo mount -o recovery,ro /dev/mapper/cachedev_0 /volume1
However I did attach a USB HDD (as /volumeUSB1 - and I made a share on it so I could see stuff coming back) and was able to do a file recovery using:
sudo btrfs restore /dev/mapper/cachedev_0 /volumeUSB1/usbshare
I didn't run it with any other switches at this point because I just wanted to see if I could rescue / pull files out. During the run I did get a few warning messages but nothing fatal. The contents came out but all the timestamps etc.. were "fresh".
I then took 1 drive out of my 4 drive array & created a seperate volume (/volume2) and ran another recovery but this time using -x and -m to restore date/file stamps and other file metadata:
sudo btrfs restore -x -m /dev/mapper/cachedev_0 /volume2/Recovery
I then removed /volume1 and have re-created it and am copying everything back onto it.
Future steps will be to then remove volume2 & re-add to the volume1 storage pool & get the RAID fixed back up.
Thanks all involved for helping me navigate my way though this & fingers crossed for the last few steps.