

jj-lolo
-
Posts
22 -
Joined
-
Last visited
Posts posted by jj-lolo
-
-
I had to shutdown my server, so I shutdown DSM waited for it to power off then shut down esxi.
I restarted the server, esxi came on, the XPE VM came on (got the boot loader message) but in the browser DSM doesn't start up. Tried find.synology.com and it can't find anything.
HELP!
-
I'm having issues with tinycore-redpill.v0.4.6
I've booted tiny core and ssh'd into the vm
When I run /rploader.sh update now I see an update but get
There is a newer version of the script on the repo should we use that ? [yY/nN]y
OK, updating, please re-run after updating
cp: cannot stat '/home/tc/latestrploader.sh': No such file or directory
Updating tinycore loader with latest updates
Backing up files to /mnt/sda3//mydata.tgz
Done.I rerun it again and get the same error.
I then continue with ./rploader.sh serialgen DS3615xs and ./rploader.sh satamap now and ./rploader.sh backup now but when I get to ./rploader.sh build bromolow-7.0.1-42218 I get the following
tc@box:~$ ./rploader.sh build bromolow-7.0.1-42218
Loader source : https://github.com/jumkey/redpill-load.git Loader Branch : develop
Redpill module source : https://github.com/RedPill-TTG/redpill-lkm.git : Redpill module branch : master
Extensions :
Extensions URL :
TOOLKIT_URL : https://sourceforge.net/projects/dsgpl/files/toolkit/DSM7.0/ds.bromolow-7.0.dev.txz/download
TOOLKIT_SHA : a5fbc3019ae8787988c2e64191549bfc665a5a9a4cdddb5ee44c10a48ff96cdd
SYNOKERNEL_URL : https://sourceforge.net/projects/dsgpl/files/Synology NAS GPL Source/25426branch/bromolow-source/linux-3.10.x.txz/download
SYNOKERNEL_SHA : 18aecead760526d652a731121d5b8eae5d6e45087efede0da057413af0b489ed
COMPILE_METHOD : toolkit_dev
TARGET_PLATFORM : bromolow
TARGET_VERSION : 7.0.1
TARGET_REVISION : 42218
REDPILL_LKM_MAKE_TARGET : dev-v7
KERNEL_MAJOR : 3
MODULE_ALIAS_FILE= modules.alias.3.json
Checking Internet Access -> OK
Checking if a newer version exists on the repo -> gzip: modules.alias.3.json.gz: No such file or directory
gzip: modules.alias.4.json.gz: No such file or directory
sha256sum: latestrploader.sh: No such file or directory
There is a newer version of the script on the repo should we use that ? [yY/nN]n
Cloning into 'redpill-lkm'...
fatal: unable to access 'https://github.com/RedPill-TTG/redpill-lkm.git/': SSL certificate problem: certificate is not yet valid
Loader sources already downloaded, pulling latest
fatal: not a git repository (or any of the parent directories): .git
Using static compiled redpill extension
Looking for redpill for : ds3615xs_42218
modinfo: module '/lib/modules/5.10.3-tinycore64/redpill.ko' not found
cp: cannot stat '/home/tc/redpill.ko': No such file or directory
Got redpill-linux-v.ko
Testing modules.alias.3.json -> File OK
------------------------------------------------------------------------------------------------
It looks that you will need the following modules :
Found IDE Controller : pciid 8086d00007111 Required Extension :
No matching extension
Found VGA Controller : pciid 15add00000405 Required Extension :
No matching extension
Found SATA Controller : pciid 15add000007e0 Required Extension :
No matching extension
Found SATA Controller : pciid 15add000007e0 Required Extension :
No matching extension
Found Ethernet Interface : pciid 8086d000010d3 Required Extension : e1000e.ko
Searching for matching extension for e1000e.ko
------------------------------------------------------------------------------------------------
Starting loader creation
Checking user_config.json : Done
tar: /home/tc/bsdiff.txz: Cannot open: No such file or directory
tar: Error is not recoverable: exiting now
mkdir: cannot create directory 'cache': Permission denied
sudo: ./build-loader.sh: command not found
FAILED : Loader creation failed check the output for any errorsAny suggestions would be appreciated!
-
On 2/1/2020 at 5:37 PM, jitesh_88 said:
Yep same for me. I used my mac instead to mount and edit the file using dd.
Having this issue too on an .img I've edited before (trying to change a serial number). Using Windows 11.
How did you do it in DD?
-
I'm currently running a gen 8 with a Xeon E3-1265L V2 and DSM 6.2.3/esxi 7 but considering changing it to a bare metal machine due to issues shutting it down automatically without corruption
1. By reading this thread, is this the best config for me? I do use plex etc.
1.03b
3615XS
DSM 6.2.3-25426 Update 32. Can I install to an SD card and use the onboard reader? i.e. does this cause issues reading VID/PID?
3. Any other tips for first time baremetal config?Thanks!
-
Ok, bad news. I finally got done with the restore, and before going at it hard again, I hooked up my UPS via USB (passthrough) to shut down the DSM the first time I tested it it worked fine, shut down DSM but I had accidentally ticked shut down UPS as well, so it shut that down once DSM shut down, so I removed that switch and restarted everything.
I then tested the UPS again by unplugging it, and this time, DSM shut down (saw ups message, then couldn't access it via web) but didn't shut down the UPS. Success I thought. WRONG. When I plugged the UPS in again, I waited for everything to boot then when I went into the web interface, I had a message saying the DSM had been reset and I had to re-install DSM, so I did BUT the new raid 5 volume crashed again 😕
I wasn't accessing the shared drives from anywhere else, but on synology I had plex server running (but no clients running), as well as under docker, open-vm-tools, pi-hole, portainer, and crashplan
Ugh- what am I doing wrong?
-
I recently had a volume crash since I didn't configure my UPS to shutdown the server during a power outage.
I have a Cyberpower CP1500AVRLCD UPS (one USB output and one Serial output) and use an HP Microserver gen 8 running ESXi-7.0U3-18644231-standard (booting from SD card) using an SSD for the datastore, and the 4 HDD slots on raid 5 and DSM 6.2.2-24922 Update 3.
I've just connected the UPS to the Server via usb, and have configured the USB port on the XPE VM as a passthrough, and configured DSM to shutdown after 10 seconds of power outage. So I guess my XPE is protected, but I have the following questions:
1. Is there better way to do this where everything shutdown?
2. I intend on creating a new server for backup, can I configure with just one USB cable for everything to shutdown (via software?) If so how?
Thanks!
-
12 hours ago, pocopico said:
I have the impression that the NAND media is not intended for that purpose. Its mainly used to store internal iLO stuff and boot the Inteligent Provisioning tool.
You can though install a very inexpensive MicroSD card in the MicroSD Slot.
I was able to find the format and that unfortunately didn't work for me.
I wasn't sure if the microsd would stop working if the nand degraded more since in the instructions it says not to have an SD card in there.
Not sure I understand your SD card comment?
-
21 hours ago, Orphée said:
Actually the ILO hacked release is 2.73 :
But you are on your own, I won't help on this
")
Thanks.
Thanks, found the format option, I had to press iLO Health twice.
Unfortunately, pressing formatting the NAND and resetting 4 times with unplugging for a minutes in between didn't work.
I also tried upgrading/downgrading ILO firmware versions and that didn't work.
-
Thanks so much!
-
thanks for the tip. any idea where to get the hacked version?
-
Update: in case this is useful to anyone I went ahead and broke the raid by taking a drive out and it still read (albeit it slowly) and was able to backup what was missing and went ahead and recreated the volumes in RAID 5/BTFRS and am now restoring (at around 90MB/s) from my old synology DS1511 so it's going to take a while!
I am also creating a new XPennology server to act more as a long term backup.
Thanks for your help.
Two final questions:
- for your docker do you use the synology docker package or something else (to make sure I backup everything)
- I'd like my new backup synology to be "hot swappable" with my main one; what's the best way to backup to it so that it's a mirror image of my primary NAS that can be used as my main NAS in case it fails again?
Thanks!
-
I'm setting up a HP Microserver Gen 8 as a backup NAS. Server hasn't been used in a while so I upgraded it to to iLO Firmware Version 2.78, I noticed this error:
Controller firmware revision 2.10.00 NAND read failure: Media is in a WRITE-PROTECTED state
After some research I found this:
https://support.hpe.com/hpesc/public/docDisplay?docId=a00048622en_us
Basically, it says to format the NAND.
I tried to do it within ILO (Option 1) but I don't have the format option as in the screenshot.
So I tried option 3- From Windows OS (using the HPQLOCFG.exe utility but I got the following error
QuoteCPQLOCFG.exe: ERROR: Malformed RIB response: (30):
HTTP/1.1 501 Not Implemented
CPQLOCFG.exe: Script succeeded on "192.168.200.21:443"
Has anyone solved this problem? I intend to use my SD slot to boot ESXi
-
Thanks for all the help.
What throughput should I be getting backing up data on a recovery mount to another synology box over a wired network?
Basically using rsync, I've only copied 130GB in 5 hours. Here is some detail:
I just installed a brand new 14TB Seagate exos on my old Synology 213j and I'm using rsync -avux (also tried with -z) from my XPe I'm trying to backup over a wired 1Gb network to my old Synology 213J and I seem to be only getting ~10MB/s (network download speed - I was able to get at least 60+ on the Xpe over the network before the volume crash).
Is it the 213J or the NAS that's in recovery mode that’s causing this? I haven’t used the 213 in 3 years and updated it before trying the restore and never remembered testing the throughput on it as I only used it for a regular backup
UPDATE: I did a test from a wireless laptop to the 213J and I got a throughput peak of over 30MB/s so I'm guessing it's the way things are mounted? Anything I can try to speed up the backup as at this speed it will take weeks to backup 14TB at 10MB/s.
Unfortunately, I don't have any more bays on my HP Microserver to insert another drive, so I also tried to mount a USB SSD directly the the esxi host and pass it through to the XPenology VM, but when I do an fdisk -l it doesn't show up.
Another thought if I can't get the speed up higher- I have another server I can install Xpenology to but 14TB HDDs are expensive... I do have a partial backup on another synology. Can I "break the raid 6" and take two disks out and use those to configure a new machine and restore the partial to them and then still be able to access the broken raid on the original xpenology (the one in recovery) or is that too much risk?
Your thoughts as to what I should try next would be appreciated!
-
Thanks so much for the tip to ignore the lv stuff as that was confusing me!
I was able to do a recovery mount (sudo mount -o recovery /dev/md2 /volume1)
A few questions if you don't mind:
1. What do you think happened and is there anything I can do to avoid in the future? (I have a UPS but it failed, so I need to order a new battery and figure out how to get ESXI to shut down XPEnology automatically)
2. I am assuming the volume can't be fixed and I need to backup/recreate the volume. Is this correct?
3. I have another (real, but old) synology NAS where most (because I don't have enough HDD space) the data is backed up to and I want to make sure everything is backed up. If I backup /volume1/@appstore will all the data for plex, docker, and hyperbackup be backed up or do they store info elsewhere?
4. Since it seems I need to do a restore, this may be a good time to upgrade my DSM to 7.0.1; Would you recommend this and is there a better guide than this? https://www.tsunati.com/blog/xpenology-7-0-1-on-esxi-7-x I use RawDataMappings so I'll need to remember how I did that a while back
5. Any recommendations on how to set up the new volume (e.g. SHR-2, write cache off)
Thanks so much for your time and knowledge!
-
-
6 hours ago, flyride said:
Doesn't look like you're using an lv, just a plain RAID6.
You need to know if you are using btrfs or ext4.
Post the output of cat /etc/fstab
none /proc proc defaults 0 0
/dev/root / ext4 defaults 1 1
/dev/md2 /volume1 btrfs auto_reclaim_space,synoacl,relatime 0 0
-
-
when I follow the steps in the recovery, command like vgdisplay return no info and
# lvdisplay -v returns
Using logical volume(s) on command line.
No volume groups found.
Help!
-
49 minutes ago, blue-label1989 said:
Maybe you Will find something usefull in one of these sites:
https://www.vsam.pro/crashed-synology-volume-and-how-to-restore-ds415-play/
Or
BTRFS Restore
goodluck.
Thanks, I had found the first article but when I do the lvm vgscan it doesn't find any volumes (file system corruption?) so I think his issue is more of a disk issue.
I'll try to follow the second article and see what's useful
-
1 hour ago, blue-label1989 said:
Very strange, in ESXI did you make RawDataMappings off your disks? Or did you just connected the disks?
Raw data mappings
-
Running DSM 6.2.2-24922 Update 3 under esxi 7 on an hp microserver 8. Lost power today and got a volume crashed upon reboot.
Would appreciate any help in recreating volume/recovering data. I do have a partial backup in case I have to go that route.
Here are some screenshots/info. Not sure what would help.
root@XPE_1:/# ls -l
total 52
lrwxrwxrwx 1 root root 7 Oct 12 2019 bin -> usr/bin
drwxr-xr-x 7 root root 0 Mar 1 10:24 config
drwxr-xr-x 10 root root 18840 Mar 1 12:24 dev
drwxr-xr-x 48 root root 4096 Mar 1 10:24 etc
drwxr-xr-x 43 root root 4096 Oct 12 2019 etc.defaults
drwxr-xr-x 2 root root 4096 May 9 2019 initrd
lrwxrwxrwx 1 root root 7 Oct 12 2019 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Oct 12 2019 lib32 -> usr/lib32
lrwxrwxrwx 1 root root 7 Oct 12 2019 lib64 -> usr/lib
drwx------ 2 root root 4096 May 9 2019 lost+found
drwxr-xr-x 2 root root 4096 May 9 2019 mnt
drwx--x--x 3 root root 4096 Oct 17 2019 opt
dr-xr-xr-x 376 root root 0 Mar 1 10:24 proc
drwx------ 3 root root 4096 Feb 27 2021 root
drwxr-xr-x 25 root root 1280 Mar 1 16:00 run
lrwxrwxrwx 1 root root 8 Oct 12 2019 sbin -> usr/sbin
dr-xr-xr-x 12 root root 0 Mar 1 10:24 sys
drwxrwxrwt 12 root root 1280 Mar 1 16:07 tmp
drwxr-xr-x 2 root root 4096 Oct 12 2019 tmpRoot
drwxr-xr-x 11 root root 4096 May 9 2019 usr
drwxr-xr-x 17 root root 4096 Mar 1 10:24 var
drwxr-xr-x 14 root root 4096 Oct 12 2019 var.defaults
drwxr-xr-x 3 root root 4096 Mar 1 09:58 volume1
drwxr-xr-x 5 root root 4096 Mar 1 10:24 volumeSATA1
root@XPE_1:/# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1]
md2 : active raid6 sdb3[0] sde3[3] sdd3[2] sdc3[1]
27335120896 blocks super 1.2 level 6, 64k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sdb2[0] sdc2[1] sdd2[2] sde2[3]
2097088 blocks [12/4] [UUUU________]
md0 : active raid1 sdb1[0] sdc1[1] sdd1[2] sde1[3]
2490176 blocks [12/4] [UUUU________]
unused devices: <none>
root@XPE_1:/# mdadm --detail /dev/md0
/dev/md0:
Version : 0.90
Creation Time : Sat Oct 12 01:49:00 2019
Raid Level : raid1
Array Size : 2490176 (2.37 GiB 2.55 GB)
Used Dev Size : 2490176 (2.37 GiB 2.55 GB)
Raid Devices : 12
Total Devices : 4
Preferred Minor : 0
Persistence : Superblock is persistentUpdate Time : Tue Mar 1 16:09:16 2022
State : clean, degraded
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0UUID : affa3cf2:4bc1be17:3017a5a8:c86610be
Events : 0.22852208Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 33 1 active sync /dev/sdc1
2 8 49 2 active sync /dev/sdd1
3 8 65 3 active sync /dev/sde1
- 0 0 4 removed
- 0 0 5 removed
- 0 0 6 removed
- 0 0 7 removed
- 0 0 8 removed
- 0 0 9 removed
- 0 0 10 removed
- 0 0 11 removed
root@XPE_1:/# mdadm --detail /dev/md1
/dev/md1:
Version : 0.90
Creation Time : Sat Oct 12 01:49:03 2019
Raid Level : raid1
Array Size : 2097088 (2047.94 MiB 2147.42 MB)
Used Dev Size : 2097088 (2047.94 MiB 2147.42 MB)
Raid Devices : 12
Total Devices : 4
Preferred Minor : 1
Persistence : Superblock is persistentUpdate Time : Tue Mar 1 10:24:12 2022
State : clean, degraded
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0UUID : d913496f:3d84522e:3017a5a8:c86610be
Events : 0.162375Number Major Minor RaidDevice State
0 8 18 0 active sync /dev/sdb2
1 8 34 1 active sync /dev/sdc2
2 8 50 2 active sync /dev/sdd2
3 8 66 3 active sync /dev/sde2
- 0 0 4 removed
- 0 0 5 removed
- 0 0 6 removed
- 0 0 7 removed
- 0 0 8 removed
- 0 0 9 removed
- 0 0 10 removed
- 0 0 11 removed
root@XPE_1:/# mdadm --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Fri Oct 11 19:29:34 2019
Raid Level : raid6
Array Size : 27335120896 (26068.80 GiB 27991.16 GB)
Used Dev Size : 13667560448 (13034.40 GiB 13995.58 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistentUpdate Time : Tue Mar 1 10:24:21 2022
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0Layout : left-symmetric
Chunk Size : 64KName : XPE1:2
UUID : 683881bb:0c6fecad:dc5ac778:4d0d9d2c
Events : 4591Number Major Minor RaidDevice State
0 8 19 0 active sync /dev/sdb3
1 8 35 1 active sync /dev/sdc3
2 8 51 2 active sync /dev/sdd3
3 8 67 3 active sync /dev/sde3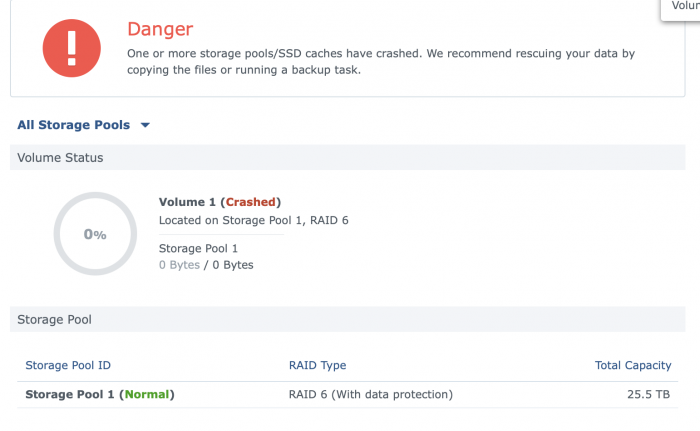
-
were you able to find a solution? my volume crashed but my storage pool is normal
-
were you able to find a solution? my volume crashed but my storage pool is normal

DSM_DS3615xs ERROR after trying to install DSM after power loss- The file is probably corrupt. (13)
in DSM 6.x
Posted
I'm running an esxi install of DSM_DS3615.
I just had several concurrent power losses where the DSM wasn't shut down properly so instead of DSM I got a "welcome back" message with it prompting me to migrate and install DSM. I was on 6.2.3U3 so I tried DSM_DS3615xs_25426.pat and got "The file is probably corrupt. (13)" error
I tried an older version and it's asking for 25426 minimum.
HELP!