

voidru
-
Posts
3 -
Joined
-
Last visited
Posts posted by voidru
-
-
3 часа назад, flyride сказал:
Is data still accessible now?
Yes it is.
3 часа назад, flyride сказал:Let the RAID transformation finish, then replace the crashed drive.
Decided to follow your suggestion. Conversion will end in 24 hours. Fortunately I've made a full backup.
-
 1
1
-
-
Hi,
I have the following configuration:
- ESXi 6.7.0 Update 2.
- Xpenology DSM 6.1.5-15254 (DS3615xs).
- WD RED 2 x 3Tb added to VM using vmkfstools -z (RDM).
- RAID1, btfrs
I was running low on DSM, so I decided to add an additional WD Red 3 Tb (same WD model, but 4 years newer) to my VM and migrate from RAID1 to RAID5.
I made a full backup and started the migration.
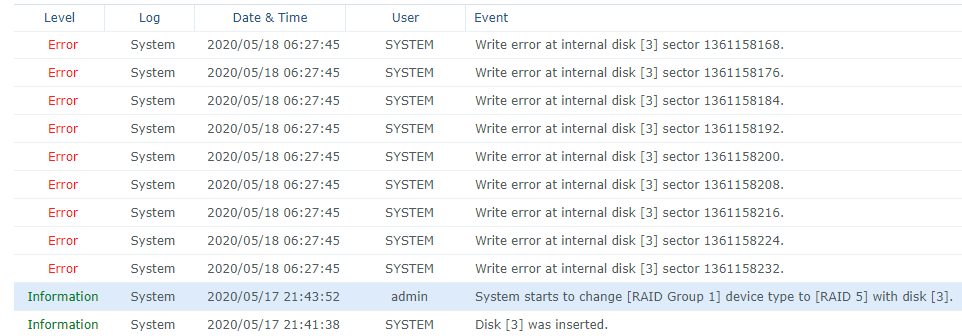
The progress bar shows me that the migration will finish within 48 hours. But after several hours I got the following in the Log Center:
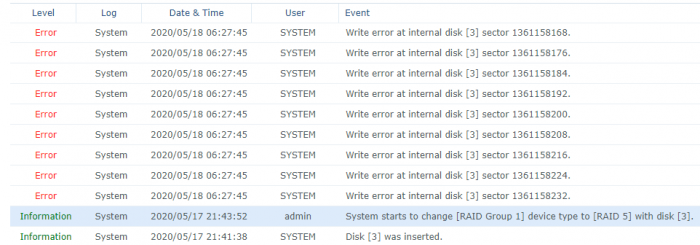
Disk 3 (the new one) is marked as "Crashed" but RAID is coninuining changing.
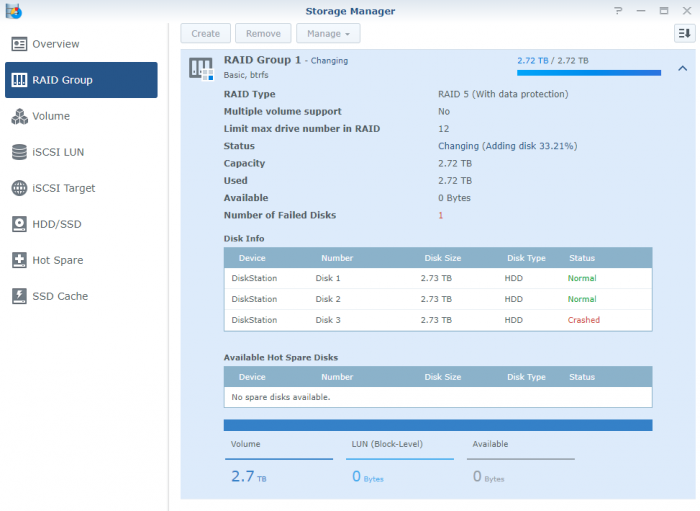
Here is what I have in /var/log/messages:
Скрытый текст2020-05-17T21:44:29+03:00 DiskStation kernel: [355764.641350] md: md2: current auto_remap = 0
2020-05-17T21:44:55+03:00 DiskStation kernel: [355790.967915] md: md2: flushing inflight I/O
2020-05-17T21:44:55+03:00 DiskStation kernel: [355790.972967] md: reshape of RAID array md2
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855550] write error, md2, sdc3 index [2], sector 1361158280 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855557] write error, md2, sdc3 index [2], sector 1361158288 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855558] write error, md2, sdc3 index [2], sector 1361158296 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855559] write error, md2, sdc3 index [2], sector 1361158304 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855560] write error, md2, sdc3 index [2], sector 1361158312 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855561] write error, md2, sdc3 index [2], sector 1361158320 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855562] write error, md2, sdc3 index [2], sector 1361158328 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855563] write error, md2, sdc3 index [2], sector 1361158336 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855564] write error, md2, sdc3 index [2], sector 1361158344 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855565] write error, md2, sdc3 index [2], sector 1361158352 [raid5_end_write_request]
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855651] md/raid:md2: Disk failure on sdc3, disabling device.
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.855651] md/raid:md2: Operation continuing on 2 devices.
2020-05-18T06:27:39+03:00 DiskStation kernel: [387162.858124] md: md2: reshape stop due to MD_RECOVERY_INTR set.
2020-05-18T06:27:44+03:00 DiskStation synostoraged: hotspare_log_repair_err.c:20 [INFO] Space [/dev/md2] is actioning, skip repairing with hotspare disks
2020-05-18T06:27:45+03:00 DiskStation kernel: [387166.590787] md: md2: current auto_remap = 0
2020-05-18T06:27:45+03:00 DiskStation kernel: [387166.599042] md: md2: set sdc3 to auto_remap [1]
2020-05-18T06:27:45+03:00 DiskStation kernel: [387166.599044] md: md2: set sda3 to auto_remap [1]
2020-05-18T06:27:45+03:00 DiskStation kernel: [387166.599044] md: md2: set sdb3 to auto_remap [1]
2020-05-18T06:27:45+03:00 DiskStation kernel: [387166.599045] md: md2: flushing inflight I/O
2020-05-18T06:27:45+03:00 DiskStation kernel: [387166.604954] md: reshape of RAID array md2
and /proc/mdstat:Скрытый текстash-4.3# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1]
md2 : active raid5 sdc3[2](F) sda3[0] sdb3[1]
2925444544 blocks super 1.2 level 5, 64k chunk, algorithm 2 [3/2] [UU_]
[======>..............] reshape = 33.3% (975902464/2925444544) finish=1803.7min speed=18012K/secmd1 : active raid1 sdc2[2] sda2[0] sdb2[1]
2097088 blocks [12/3] [UUU_________]md0 : active raid1 sdc1[12](F) sda1[0] sdb1[1]
2490176 blocks [12/2] [UU__________]unused devices: <none>
S.M.A.R.T on ESXi shown no errors:Скрытый текст[root@localhost:~] esxcli storage core device smart get -d t10.ATA_____WDC_WD30EFRX2D68EUZN0_________________________WD2DWCC4N4XTV79V
Parameter Value Threshold Worst
---------------------------- ----- --------- -----
Health Status OK N/A N/A
Media Wearout Indicator N/A N/A N/A
Write Error Count 0 0 N/A
Read Error Count 0 51 N/A
Power-on Hours 110 0 N/A
Power Cycle Count 3 0 N/A
Reallocated Sector Count 0 140 N/A
Raw Read Error Rate 0 51 N/A
Drive Temperature 46 0 N/A
Driver Rated Max Temperature N/A N/A N/A
Write Sectors TOT Count N/A N/A N/A
Read Sectors TOT Count N/A N/A N/A
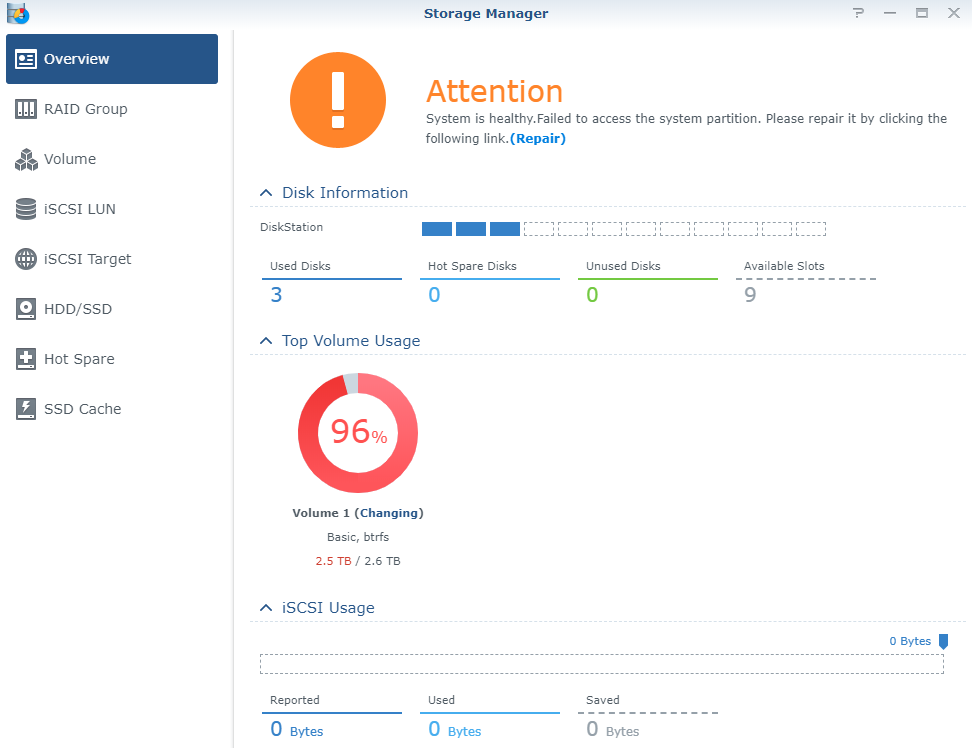
Initial Bad Block Count N/A N/A N/ANevertheless the volume is mounted and my files are accessible over SMB, but the lattency is high due to the migration.
I believe that something is wrong with the new HDD, and I will never feel safe knowing that there were errors during RAID migration.
Any suggestions?
Thanks.
UPD: The new disk shows 0 write\read rate in ESXi monitor:
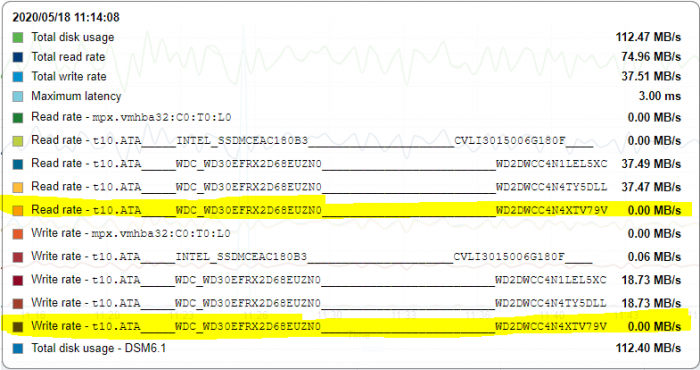
So I guess, in the end I will get RAID5 with only 2 disks (and one is missing).


RAID1->RAID5, disk failed during migration.
in Answered Questions
Posted
When RAID transformation is finished I got degraded RAID5 (2 of 3 disks).
The new disk was marked 'crashed' so I plugged it out and made SMART check and a surface test -- no errors.
Then plugged in the disk to another SATA port and started RAID5 rebuild process.
The rebuild finished successfully and now my DSM is healthy:
Thanks everyone!
The thread can be closed.