

mandgeo
-
Posts
5 -
Joined
-
Last visited
mandgeo's Achievements
Newbie (1/7)
0
Reputation
-
I've solved my problem...switched to Synology. Sorry but i don't remember if fresh dsm solved the problem.
-
Machine... HP Microserver gen8 Loader...arpl-i18n-23.6.0 The story.. I've updated to DSM 7.2, from DSM 7.1.1 42962 release 5 (never saw there was a release 6). After that, every container was running fine, except wireguard. I've uninstalled the spk, because there are different from 7.1 to 7.2. Removing the container got me with some btrfs error so I had to erase it manually. I've installed again the 7.2 version of the Wireguard spk, installed the container, but the container doesn't start. Wireguard package is running fine, but the container gives me this error..."failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: exec: "docker-entrypoint.sh": executable file not found in $PATH: unknown". I've removed and reinstalled every part of wireguard, tried different images, erased manually, tried to install from portainer, with docker-compose, did docker system prune...same error. Other containers are installing & reinstalling just fine. I'm using docker image from here... https://github.com/wg-easy/wg-easy Installed by this tutorial... https://www.blackvoid.club/wireguard-spk-for-your-synology-nas/ Does anybody have any idea how to solve this problem?
-
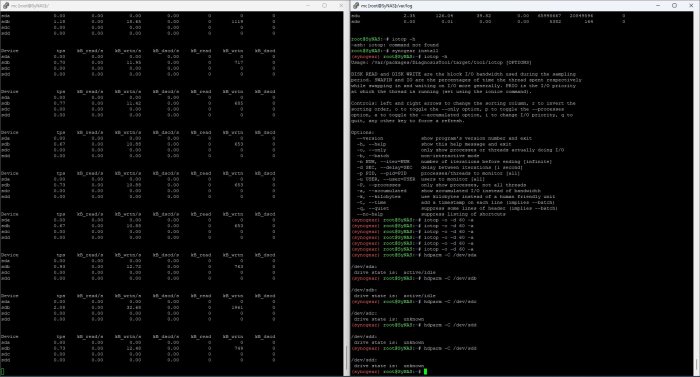
No solution. I've managed to stop loging oob errors in message, but drives doesn't sleep. Test made today. Hibernation set to 10 minutes. iostat from 60 to 60 seconds and believe me that i have mode than 10 readings showing zero activity on sda, sdc &sdd. The result is active status, zero hibernation. If I remember well, sdc&sdd are part of raid 1 array. External hard drives are showing stanby. So, after this test, I can only conclude that the problem is not related with logs.
-
I sure think i've posted my configuration on title. The problem ... scemd generates alot of errors, that are written on log file. File located on DSM partition. As far as I understand, DSM is replicated on every drive on system, so my hard drives doesn't get the chance to sleep. There is also docker who writes something at regular interval, but it's a baby compared to scemd. What have I done so far? I've managed to stop generating the scemd log file, by editing /etc.defaults/syslog-ng/patterndb.d/scemd.conf. The problem is that the messges are also written in /var/log/messages file. I've tried to create a filter, so that error messages could not be generated, but with no effect. What's the approach should i take in this case? Where are this messages coming from? I saw DSM 6 users complaining about this problem. I've also tried to play with TCRP user_config.json. I've changed maxdrives and internal sata parameters (maybe not the exact names), with no effect. Thank you!
-
Where you able to find any solution? My logs are full of ... Hard drives doesn't spindown/hibernate. jbd2 writes logs on all internal drives. Other than that, everything works great. Using DSM 7.1.1-42962 / DS3622xs+ on Hp microserver gen8. I have two external drives connected on USB3. They are going to sleep as they should. :))
