

jpbaril
-
Posts
32 -
Joined
-
Last visited
-
Days Won
1
Posts posted by jpbaril
-
-
@WiteWulf You are my hero! I got access back to my system and files!
I did not had ssh access but was able to use the console from Hypervisor.
Indeed, I had forgotten to say that DSM was on a VM, I don't know if it had any relevance to the issue.
-
 1
1
-
-
11 hours ago, WiteWulf said:
synogroup -addmember administrators temp
BTW, again a mistake
")
It's rather:synogroup -memberadd administrators temp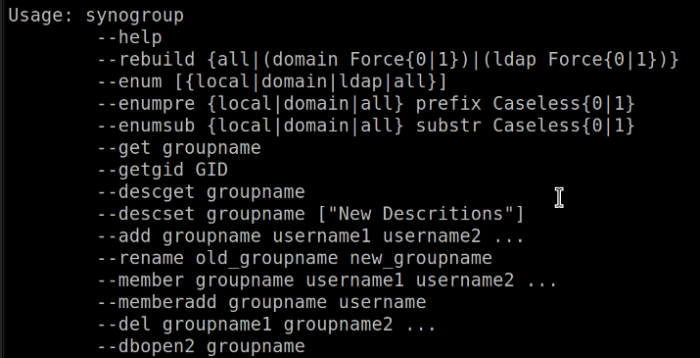
-
2
-
-
I just noticed that while I can access files of most Samba shares, I cannot access files from my home share.
So could my problem be something related to my user specifically? Like my home directory being corrupted or something?
Thanks again.
-
The TCRP image was new, the DSM install is not.
As stated I upgraded from 7.1.0.
-
Hi,
After upgrading to latest 7.1.1 using TCRP v0.9.2.9 I cannot login through webui or SSH anymore.I first tried to boot TCRP and update to latest version but that seemed to not work, so I just started a new image from scratch.
Before the upgrade I was on 7.1.0 and used TCRP 0.8.After entering 2FA code I get a message that says something like "Impossible to connect because of configuration errors. Contact your administrator to reinitialize 2FA or reinitialize the NAS".
(See screenshot attached. It's in French)
And through SSH I get an error that I never saw before.$ ssh -vvv jpbaril@192.168.1.50 OpenSSH_8.9p1 Ubuntu-3, OpenSSL 3.0.2 15 Mar 2022 debug1: Reading configuration data /home/jpbaril/.ssh/config debug1: /home/jpbaril/.ssh/config line 5: Applying options for 192.168.1.50 debug1: Reading configuration data /etc/ssh/ssh_config debug1: /etc/ssh/ssh_config line 19: include /etc/ssh/ssh_config.d/*.conf matched no files debug1: /etc/ssh/ssh_config line 21: Applying options for * debug2: resolve_canonicalize: hostname 192.168.1.50 is address debug3: expanded UserKnownHostsFile '~/.ssh/known_hosts' -> '/home/jpbaril/.ssh/known_hosts' debug3: expanded UserKnownHostsFile '~/.ssh/known_hosts2' -> '/home/jpbaril/.ssh/known_hosts2' debug3: ssh_connect_direct: entering debug1: Connecting to 192.168.1.50 [192.168.1.50] port 22. debug3: set_sock_tos: set socket 3 IP_TOS 0x10 debug1: Connection established. debug1: identity file /home/jpbaril/.ssh/id_ed25519 type 3 debug1: identity file /home/jpbaril/.ssh/id_ed25519-cert type -1 debug1: Local version string SSH-2.0-OpenSSH_8.9p1 Ubuntu-3 kex_exchange_identification: read: Connection reset by peer Connection reset by 192.168.1.50 port 22Thanks for your help.
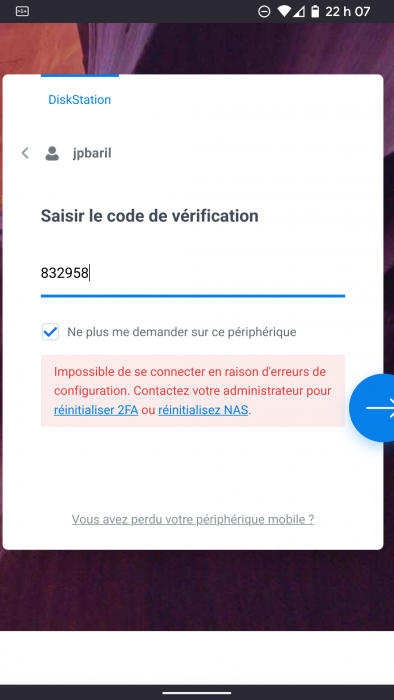
-
22 hours ago, flyride said:
You are using SATABOOT on Proxmox. You should not attach your data disks to the same controller. It plainly tells you this.
Move your data drives to the SCSI controller, or if you would rather keep using the SATA controller for your data disks, switch your loader to a USB image. After this is complete rerun satamap and build the loader again.
"not attach your data disks to the same controller" ???
"SCSI controller" ???I don't understand.
BTW, I just upgraded from 7.0.1 to 7.1u2 as a DS918+ in a KVM VM.
I have 6 drives, all as SATA drives:
- 1 TC .img file
- 4 passthrough physical hard drives
- 1 virtual drive
Before upgrade all drives were recognized.
After upgrade DSM says the virtual drive is not found.
Also, my physical and the virtual drives are listed as drives # 12, 13, 14, 15, 16 in DSM...Here is the part related to drives in Virt-Manager xml:
<disk type="file" device="disk"> <driver name="qemu" type="raw"/> <source file="/var/lib/libvirt/images/tinycore-redpill-uefi.v0.8.0.0.img"/> <target dev="sda" bus="sata"/> <address type="drive" controller="0" bus="0" target="0" unit="0"/> </disk> <disk type="block" device="disk"> <driver name="qemu" type="raw" cache="none" io="native"/> <source dev="/dev/disk/by-id/ata-WDC_WD60EFZX-68B3FN0_WD-C80JZ76G"/> <target dev="sdb" bus="sata"/> <address type="drive" controller="0" bus="0" target="0" unit="1"/> </disk> <disk type="block" device="disk"> <driver name="qemu" type="raw" cache="none" io="native"/> <source dev="/dev/disk/by-id/ata-WDC_WD60EFZX-68B3FN0_WD-CA0JXUUK"/> <target dev="sdc" bus="sata"/> <address type="drive" controller="0" bus="0" target="0" unit="2"/> </disk> <disk type="block" device="disk"> <driver name="qemu" type="raw" cache="none" io="native"/> <source dev="/dev/disk/by-id/ata-ST3000VN000-1HJ166_W6A04AVT"/> <target dev="sdd" bus="sata"/> <address type="drive" controller="0" bus="0" target="0" unit="3"/> </disk> <disk type="block" device="disk"> <driver name="qemu" type="raw" cache="none" io="native"/> <source dev="/dev/disk/by-id/ata-ST3000VN007-2E4166_Z6A0FLNR"/> <target dev="sde" bus="sata"/> <address type="drive" controller="0" bus="0" target="0" unit="4"/> </disk> <disk type="file" device="disk"> <driver name="qemu" type="qcow2"/> <source file="/var/lib/libvirt/images/Synology-Volume3-Docker.qcow2"/> <target dev="sdf" bus="sata"/> <address type="drive" controller="0" bus="0" target="0" unit="5"/> </disk>
Should I change all drives to use "SCISI" bus ? Or should I just put all drives after the first TC drive on a different controller (i.e. 1 instead of 0) ?When I upgraded I restarted my TC image from scratch but added back my old user_config file and also added ACPI and VirtIO extensions.
Here is my user_config.json:{ "extra_cmdline": { "pid": "0xa4a5", "vid": "0x0525", "sn": "123XXXXXXXXXX", "mac1": "00XXXXXXXXXX", "SataPortMap": "58", "DiskIdxMap": "0A00" }, "synoinfo": { "internalportcfg" : "0xffff", "maxdisks" : "16", "support_bde_internal_10g" : "no", "support_disk_compatibility" : "no", "support_memory_compatibility" : "no" }, "ramdisk_copy": {} }Thank you
-
7 hours ago, hendry said:
@pocopico how to compile redpill loader into smaller .img size ?
I myself converted the raw .img file into a .qcow2 and it seems to work fine.
As a .qcow2 file it's then only around 120 MB.
-
I run DSM7 as a KVM VM.
Redpill is built with VirtIO drivers.
On of the disks in that VM will actually be a virtual disk image.
For that virtual disk instead of using the "SATA" bus, I first tried "VirtIO" but DSM7 did not see the disk.
I then chose the "SCSI" bus to which Virt-Manager automatically added a "VirtIO SCSI" controller. With that DSM could see the disk.
Is using "SCSI" bus with "VirtIO SCSI" controller the way to go?
Will I see performance improvements compared to regular SATA bus emulation ?Thank you
-
Hi,
I'm still on the latest 6.2.3 update that can work with jun loader.
So it means my DSM has not been updated in more than a year.
Is it safe to run the OpenVPN server from that OS version now in 2022 ?
Is there any vulnerability discovered in the last year that would make doing so inadvisable?
(I'm still waiting for RedPill to be more stable and a safe bet to make the update to DSM7)
Thank you.
-
1
-
-
Sorry to join the bandwagon of asking for help in a thread that should be development-focused.
Is anybody using RedPill TinyCore as a virtual machine through Virt-Manager/Libvirt ?
I can't succeed in installing the .pat file on first boot. Infamous error at 56 %.
I built TinyCore based on Apollolake 7.0.1-42218.
I updated user_config.json with the values from haydibe first page post and simply changed the serial number and mac address.
I added acpid extension then built.
No red errors.
tinycore-redpill.v0.4.4.img configured as a usb device.
When booting I both tried USB and SATA boot.
I tried creating the vm as uefi based then also as bios based vm, always as a q35 chipset machine. Same results.
(BTW: when first booting tinycore as uefi to create "image" it was not booting, I was brought to efi "console" and had to cd into dirs to finally boot core.efi)
I also added to the vm a virtual disk of 10 GB.
When faced with the error at 56%, I connected to the vm with telnet.
fsdisk results when booting as uefi based:
DiskStation> fdisk -l Disk /dev/sdh: 10 GB, 10737418240 bytes, 20971520 sectors 1305 cylinders, 255 heads, 63 sectors/track Units: sectors of 1 * 512 = 512 bytes Device Boot StartCHS EndCHS StartLBA EndLBA Sectors Size Id Type /dev/sdh1 0,32,33 310,37,47 2048 4982527 4980480 2431M fd Linux raid autodetect /dev/sdh2 310,37,48 571,58,63 4982528 9176831 4194304 2048M fd Linux raid autodetect Disk /dev/md0: 2431 MB, 2549940224 bytes, 4980352 sectors 622544 cylinders, 2 heads, 4 sectors/track Units: sectors of 1 * 512 = 512 bytes Disk /dev/md0 doesn't contain a valid partition table Disk /dev/md1: 2047 MB, 2147418112 bytes, 4194176 sectors 524272 cylinders, 2 heads, 4 sectors/track Units: sectors of 1 * 512 = 512 bytes Disk /dev/md1 doesn't contain a valid partition tableLogs when booting as bios based:
DiskStation> [ 125.397657] md1: detected capacity change from 2147418112 to 0 [ 125.398386] md: md1: set sdh2 to auto_remap [0] [ 125.398928] md: md1 stopped. [ 125.399353] md: unbind<sdh2> [ 125.405037] md: export_rdev(sdh2) [ 128.443213] md: bind<sdh1> [ 128.444195] md/raid1:md0: active with 1 out of 16 mirrors [ 128.445431] md0: detected capacity change from 0 to 2549940224 [ 131.458293] md: bind<sdh2> [ 131.459524] md/raid1:md1: active with 1 out of 16 mirrors [ 131.460842] md1: detected capacity change from 0 to 2147418112 [ 131.749896] EXT4-fs (md0): couldn't mount as ext3 due to feature incompatibilities [ 131.752160] EXT4-fs (md0): mounted filesystem with ordered data mode. Opts: (null) [ 132.084506] EXT4-fs (md0): couldn't mount as ext3 due to feature incompatibilities
(Yeah sorry I forgot to get both outputs for each booting)Any idea of what's wrong?
Thank you! -
On 12/11/2021 at 7:37 AM, IG-88 said:
what was the last dsm version you had?
I have 6.2.3-25426 update 3 since a year. No special extra.lzma used.
On 12/11/2021 at 7:37 AM, IG-88 said:you might add a virtual com port to the vm and connect a console to it, that way you can see what happens when dsm loads after the loader, might give you a hint about the problem
Do you happen to know how to do that in Virt-Manager/LibVirt?
Thank you -
10 minutes ago, flyride said:
Error 13 usually means a bad VID/PID setting.
OP didn't mention how the loader was configured.
If USB loader is used (even if virtualized/emulated), VID/PID must be set correctly in grub.cfg.
If IMG file is used, i.e. vdisk connected to a virtual SATA controller, the correct boot "ESXi" option must be selected during the actual boot process.
Always best to burn a clean loader if running into problems installing, which includes re-installs and migrations.
It's an .img file attached as a sata disk (not usb device as it used to be few years ago on dsm 5).
I had a look to my img file, grub.cfg file in it, last modified time did not change in a year.
-
4 hours ago, billat29 said:
One question: What version of DSM were you running before the crash? The same?
Yes, same.
-
Hi,
Yesterday my NAS began making noise then some time after I received an email my "volume 1" had crashed.That RAID1 (not SHR) volume is composed of a sole disk. I also have another RAID1 volume called "volume 3" which is composed of two disks and is my main volume where apps are installed.
So I shutdown the machine, removed the sole disk of faulty volume 1, and rebooted the NAS.
The problem: now my NAS boot in installation/migration mode with a dynamic IP (normally it's on a fixed IP).
My installed DSM version is recognized.
I tried to simply migrate using manually uploaded .pat file (both the base 6.2.3-25426 and 6.2.3-25426 update 3) but I end up with an Error 13.
I have been using Xpenology since 6 years now. First time I see such weird behavior.
My setup:
- Virtualized with Linux KVM
- Simulated machine: DS918+
- Loader: 1.04b
- DSM Version: 6.2.3-25426 update 3
- All volumes are BTRFS formated
I ran SMART long test on each 3 disks from my Linux host. In the cryptic message I seem to understand they all work fine.
What can I do?
Thanks.
-
Hi,
First, my setup: DSM 6.2.3-25426 Update 3 with loader 1.04b DS918+ running as a KVM/QEMU VM on Ubuntu 20.04 host.
Hard drives are individually passed through to the VM.
I'm running Xpenology in this setup since 6 years.
A few months ago I bought a new 6TB WD Red Plus hard-drive to have a second volume. I already had two 3 TB drives I had in a Raid 1 array from 6 six years ago as my main volume.
When I initialized the new drive I first chose to format it using SHR array with BTRFS.
I then tried to move some shared folders from old volume to the new one.A few minutes going on in that process the move would fail and the VM would get suspended.
In fact, the new drive would not only disappear from the VM but also from the Linux host!
I tried to do a long SMART test and other disk check from the host and everything seemed normal.
So I decided to reformat the drive and instead use regular RAID 1 as I had on the other volume.
Partitioning in Raid 1 seemed to have done the trick as I was then able to move the shared folder to the new volume on the 6TB drive.
This seems to have worked since then for many months.
Last week I then decided to move another shared folder to that 6 TB drive.
Again that failed and the disk again disappeared from the host.
Worst, now if I try to boot Xpenology with that 6TB drive associated to the VM, in a matter of minutes the VM will get suspended and the drive will again disappear from the host.
Is it the drive?
As I said, from the host everything looked ok and it even worked ok for a few months.
I'm clueless.
Any idea on how to resolve this or just to diagnose the real culprit.
-
On 2018-02-09 at 8:11 AM, arkilee said:
For those who are interested to be able to power off DSM 6.1.x VM via ACPI and get the shutdown working through Proxmox Virtual Environment,
I have recompiled the button.ko and evdev.ko from the poweroff package of this post in order to get this working on dsm 6.1.x/DS3615xs.I updated to latest dsm versio some time ago and now I noticed that the power button function is not working anymore.
I also found this thread and simple to install package:
Would that also work instead of manually installing files like in your case?
Thanks.
-
57 minutes ago, arkilee said:
Nothing's wrong, It means that you already have "button" and "evdev" modules already loaded in the kernel.
Maybe your bootloader has it already or you have run "s30acpid.sh start" several times.
Try to reboot your xpenology then try to shut it down with Proxmox VE web interface to see if it works.
Yeah it indeed works. I had to restart. I have your synoboot with virtio drivers.
Thanks then. -
On 2018-02-09 at 8:11 AM, arkilee said:
For those who are interested to be able to power off DSM 6.1.x VM via ACPI and get the shutdown working through Proxmox Virtual Environment,
I have recompiled the button.ko and evdev.ko from the poweroff package of this post in order to get this working on dsm 6.1.x/DS3615xs.Thanks for that.
When I do:
sudo /usr/local/etc/rc.d/S30acpid.sh start
I get:
insmod: ERROR: could not insert module /lib/modules/button.ko: File exists insmod: ERROR: could not insert module /lib/modules/evdev.ko: File exists start acpid
I copied every files in the archive to its corresponding directory.
What's wrong?
Thanks.
-
I used Proxmox in the past (really loved it) but then switched to Virtual-manager/libvirt in an Ubuntu installation. Both use KVM in the end.
They performed well and were easy to setup and manage. But I never used baremetal, so cannot compare.
I used these solutions as at that time there was no webui for ESXi and the management app was only available on Windows, which I don't have.
The other reason is that I prefer to use standard Linux solutions rather than proprietary solutions, even if they are open-source.
-
I previously ran DSM 5.2 on Proxmox. I had a Hasswell 3.3 Ghz quadcore of which I allocated 1 core and 1Gb of memory. It worked great. For your other questions, I cannot help.
-
Hi,
I got a new disk I passed-through to the DSM VM running on KVM. When initializing the new disk DSM is offering me to check the health/parity (searching for bad sectors) of the disk.
Is it safe to let DSM do that as it does not really have direct access to the real physical drive?
Would it be better to fsck the disk on the Linux host?
Thanks.
-
Hi,
I'm running 5.2 with latest Xpenoboot. I would like to upgrade to 6.
I'm on Linux and running Xpenology in a KVM virtual machine. In 5.2 it was dead simple: use the provided ISO file as first boot device and add other drives for storage. All done and ready.
I'm very confused how I could accomplish this with this new loader as everything explained here is either for bare metal or for vmware exsi virtualization.
From my experience with 5.2, I would be looking for an ISO file. Maybe I would need to create it myself by converting another file attached here in this thread, but really I don't know which one it would be.
Any indications please?
Also, would I need to changes config files? I never did that with 5.2 (I don't use Synology's Diskconnect, I use my own dyndns).
Thanks
-
Well, I don't know what happened with my Ubuntu host, but apparently, the network bridge I had for months stopped working. I removed it and recreated it, which makes the connection to work correctly again. I would not have thought. (well, I did, but again, strange...)
-
Thanks, but I already did all that.
I'm clueless.

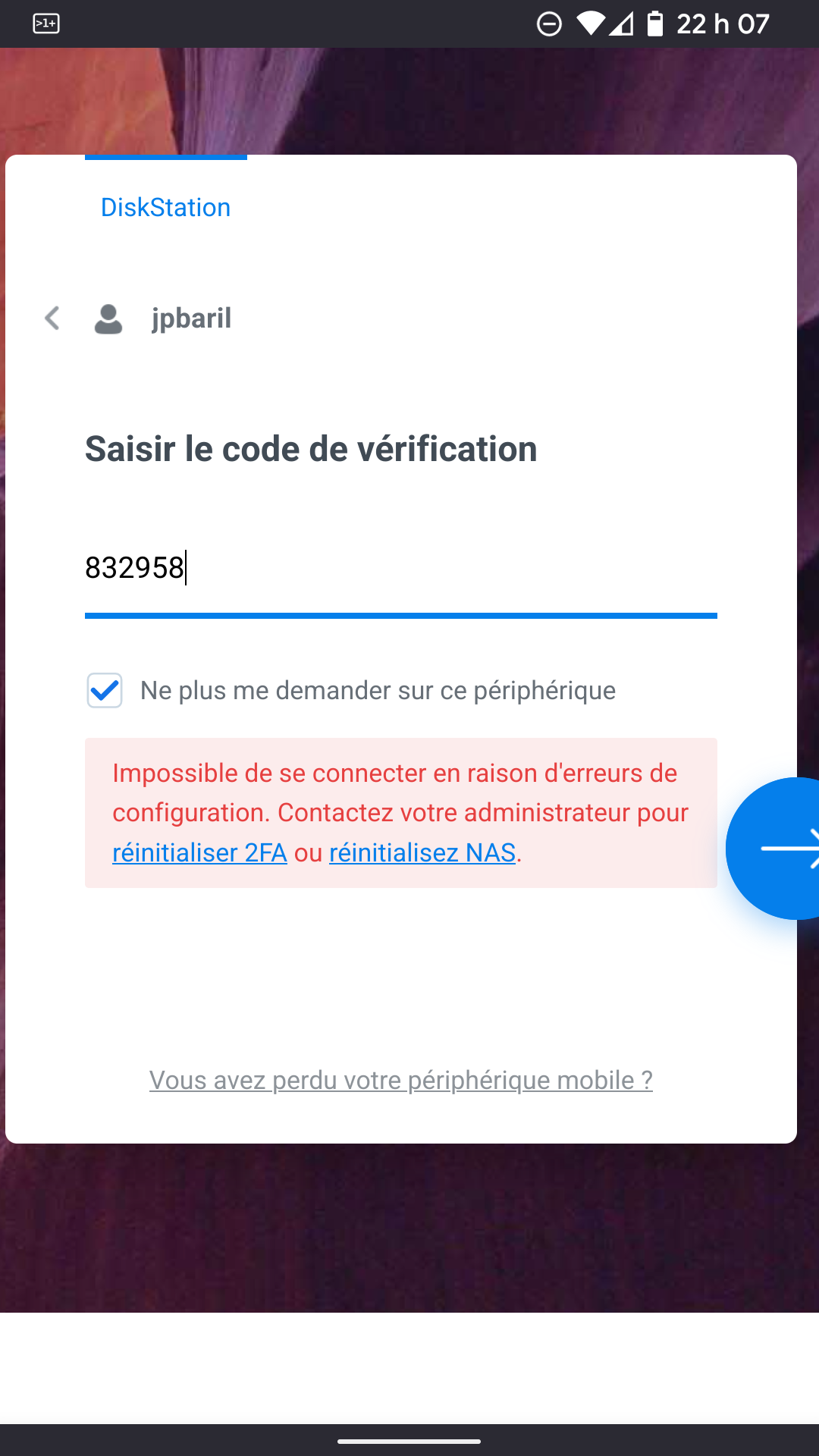
Cannot login because of broken 2FA
in General Post-Installation Questions/Discussions (non-hardware specific)
Posted · Edited by jpbaril
Hi,
I cannot login anymore into DSM because 2FA code is not accepted. Yet date+time is perfect to the very second.
As suggested by many people, I first tried to delete the file /usr/syno/etc/preference/username/google_authenticator but DSM still ask me for 2FA code, it then just throws me a different error message.
I tried an old trick of creating a new administrator user to then be able to disable 2FA for the first user, but 2FA seems to now be enforced for all new users on my DSM and it's also broken there. It basically says "Cannot save settings", which is weird and worrisome. So I cannot even set 2FA for that new temporary user... I'm going into circles and crazy...!!!
I searched for a command line (I have ssh access) that could at least as a starting point disable the "enforce 2fa" setting but nothing.
I'm clueless and stuck...
Any idea ?
Thank you