Donkey545
-
Posts
10 -
Joined
-
Last visited
1 Follower

Donkey545's Achievements
Newbie (1/7)
1
Reputation
-
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
I was able to recover my data with a Restore. None of the repair options worked as you expected and each yielded the incompatibility flag you spoke of. With the recovery, I configured my other NAS with a large enough volume for all of the data and mounted it as a NFS. For any future googlers, the destination Volume for a BTRFS Recover does not need to be the size of the source Volume, but rather only the size of the data to be recovered. Furthermore, you do not need to worry too much about doing the recovery process in a single shot. I had several network changed during my recovery processes that caused my NFS to unmount from the Xpenology system. Luckily, the restore process has options to scan the destination for files and will only back up the files that have not been transferred yet. My total recovery time was about 3 Days including disconnections because I did it over a gigabit network. Most of the time the transfer would saturate the network, but a good portion of the time, I was only seeing 45MB/s. If you need to perform this operation over a gigabit network, Id say a reasonable estimate for average speed was 65MB/s keeping in mind that I had very large files for the most part. -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
Hey flyride, I really appreciate the help. I have not gone through any of these last options just yet, but I will be attempting a restore to my other NAS soon. I think at this point making a new OS drive wouldn't be too much more work if it yields better results than the Synology system. I will investigate this option and follow up if I use it. Again, I really appreciate your help. Your method of investigating the issue has taught me a great deal about how issues like these can be addressed, and even more about how I can be more diligent in troubleshooting my own issues in the future. You rock! -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
First, attempt one more mount: sudo mount -o recovery,ro /dev/vg1000/lv /volume1 /$ sudo mount -o recovery,ro /dev/vg1000/lv /volume1 mount: wrong fs type, bad option, bad superblock on /dev/vg1000/lv, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so. Excerpt of dmesg: dmesg [249007.103992] BTRFS: error (device dm-0) in convert_free_space_to_extents:456: errno=-5 IO failure [249007.112998] BTRFS: error (device dm-0) in add_to_free_space_tree:1049: errno=-5 IO failure [249007.121572] BTRFS: error (device dm-0) in __btrfs_free_extent:6829: errno=-5 IO failure [249007.129829] BTRFS: error (device dm-0) in btrfs_run_delayed_refs:2970: errno=-5 IO failure [249007.138445] BTRFS: error (device dm-0) in open_ctree:3576: errno=-5 IO failure (Failed to recover log tree) [249007.148704] BTRFS error (device dm-0): cleaner transaction attach returned -30 [249007.181327] BTRFS: open_ctree failed With the superblock rescue, we actually get some good news! Well maybe haha sudo btrfs rescue super /dev/vg1000/lv sudo btrfs rescue super /dev/vg1000/lv All supers are valid, no need to recover I am attaching the result of the find root as a text file due to the length of the output. The first few lines is included below: sudo btrfs-find-root /dev/vg1000/lv /$ sudo btrfs-find-root /dev/vg1000/lv Superblock thinks the generation is 781165 Superblock thinks the level is 1 Found tree root at 5739883905024 gen 781165 level 1 Well block 5739820105728(gen: 781164 level: 1) seems good, but generation/level doesn't match, want gen: 781165 level: 1 Well block 5739770773504(gen: 781163 level: 1) seems good, but generation/level doesn't match, want gen: 781165 level: 1 Well block 5739769020416(gen: 781155 level: 0) seems good, but generation/level doesn't match, want gen: 781165 level: 1 Well block 5739768217600(gen: 781155 level: 0) seems good, but generation/level doesn't match, want gen: 781165 level: 1 Well block 5739782979584(gen: 781108 level: 0) seems good, but generation/level doesn't match, want gen: 781165 level: 1 Well block 5739817582592(gen: 781091 level: 1) seems good, but generation/level doesn't match, want gen: 781165 level: 1 Well block 5739819106304(gen: 781071 level: 1) seems good, but generation/level doesn't match, want gen: 781165 level: 1 Well block 5739787206656(gen: 781069 level: 1) seems good, but generation/level doesn't match, want gen: 781165 level: 1 When I try to run your dump command I got back an error on the file open: sudo btrfs insp dump-s -f /dev/vg1000/lv ERROR: cannot open /dev/vg1000/lv: No such file or directory So I ran what I think is the same command just written differently: sudo btrfs inspect-internal dump-super -f /dev/vg1000/lv sudo btrfs inspect-internal dump-super -f /dev/vg1000/lv superblock: bytenr=65536, device=/dev/vg1000/lv --------------------------------------------------------- csum 0xb6222977 [match] bytenr 65536 flags 0x1 ( WRITTEN ) magic _BHRfS_M [match] fsid b27120c9-a2af-45d6-8e3b-05e2f31ba568 label 2018.11.24-06:48:51 v23739 generation 781165 root 5739883905024 sys_array_size 129 chunk_root_generation 779376 root_level 1 chunk_root 20987904 chunk_root_level 1 log_root 5739948392448 log_root_transid 0 log_root_level 0 total_bytes 21988319952896 bytes_used 5651223941120 sectorsize 4096 nodesize 16384 leafsize 16384 stripesize 4096 root_dir 6 num_devices 1 compat_flags 0x8000000000000000 compat_ro_flags 0x3 ( FREE_SPACE_TREE | FREE_SPACE_TREE_VALID ) incompat_flags 0x16b ( MIXED_BACKREF | DEFAULT_SUBVOL | COMPRESS_LZO | BIG_METADATA | EXTENDED_IREF | SKINNY_METADATA ) csum_type 0 csum_size 4 cache_generation 18446744073709551615 uuid_tree_generation 781165 dev_item.uuid c0444440-b78e-4432-aa99-15d7d6d43e5b dev_item.fsid b27120c9-a2af-45d6-8e3b-05e2f31ba568 [match] dev_item.type 0 dev_item.total_bytes 21988319952896 dev_item.bytes_used 5857278427136 dev_item.io_align 4096 dev_item.io_width 4096 dev_item.sector_size 4096 dev_item.devid 1 dev_item.dev_group 0 dev_item.seek_speed 0 dev_item.bandwidth 0 dev_item.generation 0 sys_chunk_array[2048]: item 0 key (FIRST_CHUNK_TREE CHUNK_ITEM 20971520) chunk length 8388608 owner 2 stripe_len 65536 type SYSTEM|DUP num_stripes 2 stripe 0 devid 1 offset 20971520 dev uuid: c0444440-b78e-4432-aa99-15d7d6d43e5b stripe 1 devid 1 offset 29360128 dev uuid: c0444440-b78e-4432-aa99-15d7d6d43e5b backup_roots[4]: backup 0: backup_tree_root: 5739770773504 gen: 781163 level: 1 backup_chunk_root: 20987904 gen: 779376 level: 1 backup_extent_root: 5739782307840 gen: 781164 level: 2 backup_fs_root: 29638656 gen: 8 level: 0 backup_dev_root: 5728600883200 gen: 779376 level: 1 backup_csum_root: 5739776557056 gen: 781164 level: 3 backup_total_bytes: 21988319952896 backup_bytes_used: 5651224502272 backup_num_devices: 1 backup 1: backup_tree_root: 5739820105728 gen: 781164 level: 1 backup_chunk_root: 20987904 gen: 779376 level: 1 backup_extent_root: 5739782307840 gen: 781164 level: 2 backup_fs_root: 29638656 gen: 8 level: 0 backup_dev_root: 5728600883200 gen: 779376 level: 1 backup_csum_root: 5739820466176 gen: 781165 level: 3 backup_total_bytes: 21988319952896 backup_bytes_used: 5651223916544 backup_num_devices: 1 backup 2: backup_tree_root: 5739883905024 gen: 781165 level: 1 backup_chunk_root: 20987904 gen: 779376 level: 1 backup_extent_root: 5739912200192 gen: 781166 level: 2 backup_fs_root: 29638656 gen: 8 level: 0 backup_dev_root: 5728600883200 gen: 779376 level: 1 backup_csum_root: 5739903025152 gen: 781166 level: 3 backup_total_bytes: 21988319952896 backup_bytes_used: 5651222638592 backup_num_devices: 1 backup 3: backup_tree_root: 5739986468864 gen: 781162 level: 1 backup_chunk_root: 20987904 gen: 779376 level: 1 backup_extent_root: 5739981111296 gen: 781162 level: 2 backup_fs_root: 29638656 gen: 8 level: 0 backup_dev_root: 5728600883200 gen: 779376 level: 1 backup_csum_root: 5739997544448 gen: 781163 level: 3 backup_total_bytes: 21988319952896 backup_bytes_used: 5651223896064 backup_num_devices: 1 Now this may be a dumb question, but what is my best method for backing up the data? should I connect directly to SATA, USB to Sata, or Configure my other NAS and use my network? Xpenology btrfs-find-root.txt -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
I will be testing out these options later today. I have four more 6tb drives that I had purchased to do a backup of this NAS, so I have the space available. Thanks for the help! -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
It looks like I still have some issues. The mounting fails with each of these option. First I do the vchange -ay: sudo vgchange -ay 1 logical volume(s) in volume group "vg1000" now active Then a normal mount: sudo mount /dev/vg1000/lv /volume1 mount: wrong fs type, bad option, bad superblock on /dev/vg1000/lv, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so. Then a clear cache: sudo mount -o clear_cache /dev/vg1000/lv /volume1 mount: wrong fs type, bad option, bad superblock on /dev/vg1000/lv, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so. Then a recovery: sudo mount -o recovery /dev/vg1000/lv /volume1 mount: wrong fs type, bad option, bad superblock on /dev/vg1000/lv, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so. I have included the dmesg text as an attachment. I am seeing some errors like: BTRFS error (device dm-0): incorrect extent count for 5705893412864; counted 619, expected 618 Xpenology dmesg.txt -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
Here is some check info on the volume: sudo btrfs check /dev/vg1000/lv Password: Syno caseless feature on. Checking filesystem on /dev/vg1000/lv UUID: b27120c9-a2af-45d6-8e3b-05e2f31ba568 checking extents checking free space tree free space info recorded 619 extents, counted 620 Wanted bytes 999424, found 303104 for off 5706027515904 Wanted bytes 402767872, found 303104 for off 5706027515904 cache appears valid but isnt 5705893412864 found 5651223941120 bytes used err is -22 total csum bytes: 5313860548 total tree bytes: 6601883648 total fs tree bytes: 703512576 total extent tree bytes: 105283584 btree space waste bytes: 532066391 file data blocks allocated: 97865400832000 referenced 5644258041856 -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
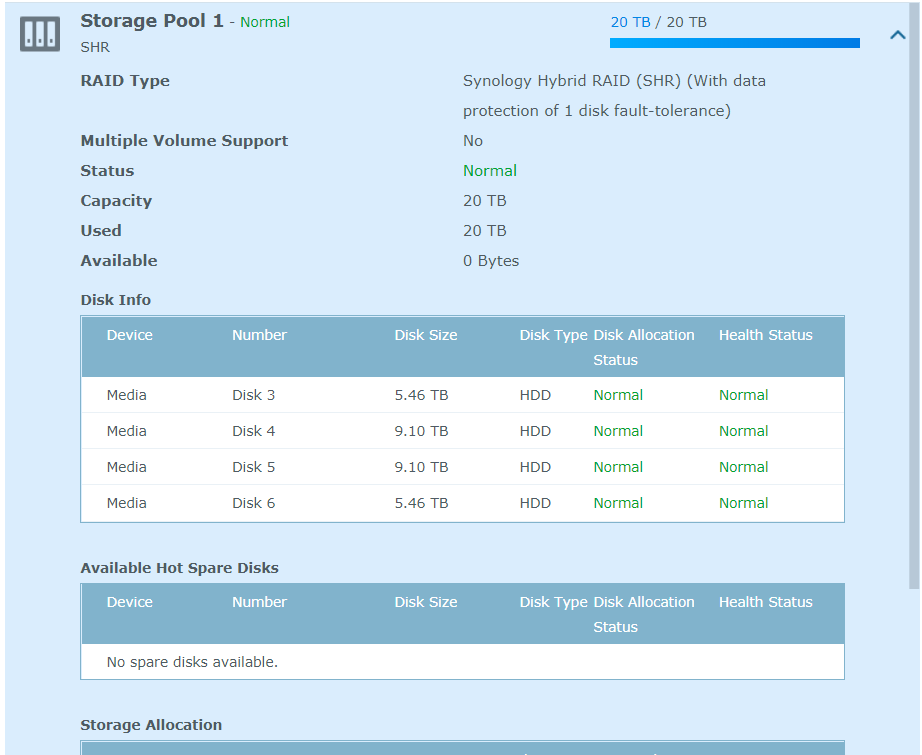
That is interesting, and it explains why I could create the volume in the first place. I think that it was BTRFS, but I am not sure honestly. For some reason in my research I neglected to make sure I was looking for that detail. This suggests that btrfs is correct: cat /etc/fstab /$ cat /etc/fstab none /proc proc defaults 0 0 /dev/root / ext4 defaults 1 1 /dev/vg1000/lv /volume1 btrfs auto_reclaim_space,synoacl,relatime 0 0 lvdisplay -v $ sudo lvdisplay -v Using logical volume(s) on command line. --- Logical volume --- LV Path /dev/vg1000/lv LV Name lv VG Name vg1000 LV UUID D0NEYj-yD1r-CGw0-AKW2-nSFa-Mu72-WLZKYj LV Write Access read/write LV Creation host, time , LV Status available # open 0 LV Size 20.00 TiB Current LE 5242424 Segments 3 Allocation inherit Read ahead sectors auto - currently set to 4096 Block device 253:0 vgdisplay -v $ sudo vgdisplay -v Using volume group(s) on command line. --- Volume group --- VG Name vg1000 System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 5 VG Access read/write VG Status resizable MAX LV 0 Cur LV 1 Open LV 0 Max PV 0 Cur PV 2 Act PV 2 VG Size 20.00 TiB PE Size 4.00 MiB Total PE 5242424 Alloc PE / Size 5242424 / 20.00 TiB Free PE / Size 0 / 0 VG UUID uhqTDU-bBfp-Qkj0-BF2r-Hxru-XojL-ZwKdkW --- Logical volume --- LV Path /dev/vg1000/lv LV Name lv VG Name vg1000 LV UUID D0NEYj-yD1r-CGw0-AKW2-nSFa-Mu72-WLZKYj LV Write Access read/write LV Creation host, time , LV Status available # open 0 LV Size 20.00 TiB Current LE 5242424 Segments 3 Allocation inherit Read ahead sectors auto - currently set to 4096 Block device 253:0 --- Physical volumes --- PV Name /dev/md2 PV UUID Fosmy0-AkIR-naPA-Ez51-3yId-2AXZ-YxGJdy PV Status allocatable Total PE / Free PE 4288836 / 0 PV Name /dev/md3 PV UUID jxYbss-ZVGK-RhTc-z4b5-QAc7-qCie-bH250G PV Status allocatable Total PE / Free PE 953588 / 0 Thanks for helping me through this, I really appreciate it. Is there a reason that you think the missing LV is the issue? -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
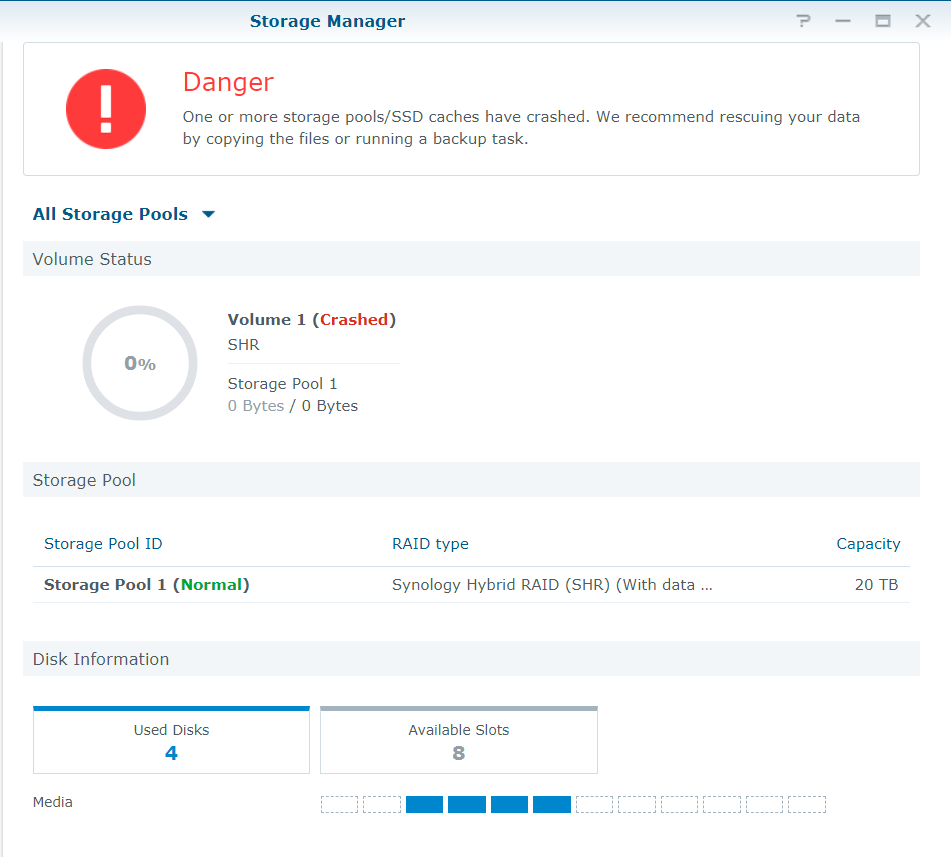
Here are the results of the vgdisplay: /$ sudo vgdisplay --- Volume group --- VG Name vg1000 System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 5 VG Access read/write VG Status resizable MAX LV 0 Cur LV 1 Open LV 0 Max PV 0 Cur PV 2 Act PV 2 VG Size 20.00 TiB PE Size 4.00 MiB Total PE 5242424 Alloc PE / Size 5242424 / 20.00 TiB Free PE / Size 0 / 0 VG UUID uhqTDU-bBfp-Qkj0-BF2r-Hxru-XojL-ZwKdkW On my system, I had a few docker images running, plex, and I had recently copied a large file (25+gb) to a folder on the volume. I have since removed docker and most additional packages as part of the debugging process. The only thing that I saw out of the ordinary was a message about a bad checksum on a file about three days before the crash. I had planned to delete the file and replace it. Here is an excerpt from the log. Personal details redacted Information System 2019/03/05 20:28:43 SYSTEM Local UPS was plugged in. Information System 2019/03/05 20:23:49 Donkey545 System started counting down to reboot. Error System 2019/03/05 20:05:04 SYSTEM Volume [1] was crashed. Information System 2019/03/05 00:35:10 SYSTEM Rotate Mail Log. Information System 2019/03/04 20:56:17 SYSTEM System successfully registered [redacted] to [redacted.org] in DDNS server [USER_dynu.com]. Information System 2019/03/04 20:56:17 SYSTEM System successfully registered [redacted] to [redacted] in DDNS server [USER_duckdns]. Information System 2019/03/04 00:35:09 SYSTEM Rotate Mail Log. Information System 2019/03/03 20:56:17 SYSTEM System successfully registered [redacted] to [redacted.org] in DDNS server [USER_dynu.com]. Information System 2019/03/03 20:56:17 SYSTEM System successfully registered [redacted] to [redacted] in DDNS server [USER_duckdns]. Warning System 2019/03/03 03:25:20 SYSTEM Checksum mismatch on file [/volume1/Media/Media_Archive/1080p/redacted]. Information System 2019/03/03 00:35:09 SYSTEM Rotate Mail Log. Yes, the volume is unmounted. That is what I meant when I said it shows up as 0bytes. -
Volume Crash after 4 months of stability
Donkey545 replied to Donkey545's question in Answered Questions
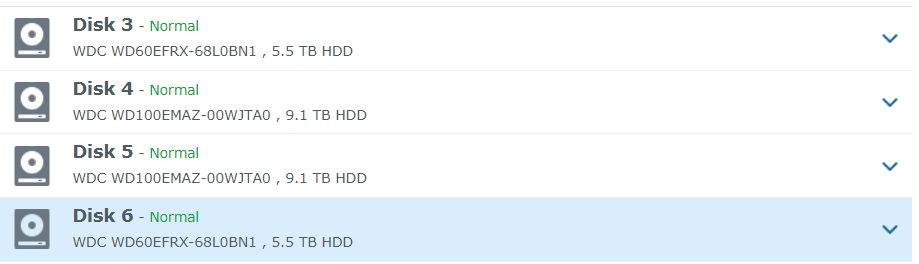
Hi, Thanks for the response, I appreciate the pointer on the direction to go with this. I am quite inexperienced with this type of troubleshooting. In my original post I had posted the cat /proc/mdstat results but there were numbers in there that flagged the content filter as phone numbers or something. I will try it again. All of my disks are healthy. Unfortunately I went to back up the data while the volume was still showing its original mounted size and it has populated it with an empty volume after the reboot with my spare drive. I have since disconnected my spare. $ cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1] md2 : active raid5 sdc5[0] sdf5[3] sde5[2] sdd5[1] 17567074368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU] md3 : active raid1 sdd6[0] sde6[1] 3905898432 blocks super 1.2 [2/2] [UU] md1 : active raid1 sdc2[0] sdd2[1] sde2[2] sdf2[3] 2097088 blocks [12/4] [UUUU________] md0 : active raid1 sdc1[0] sdd1[1] sde1[2] sdf1[3] 2490176 blocks [12/4] [UUUU________] unused devices: <none>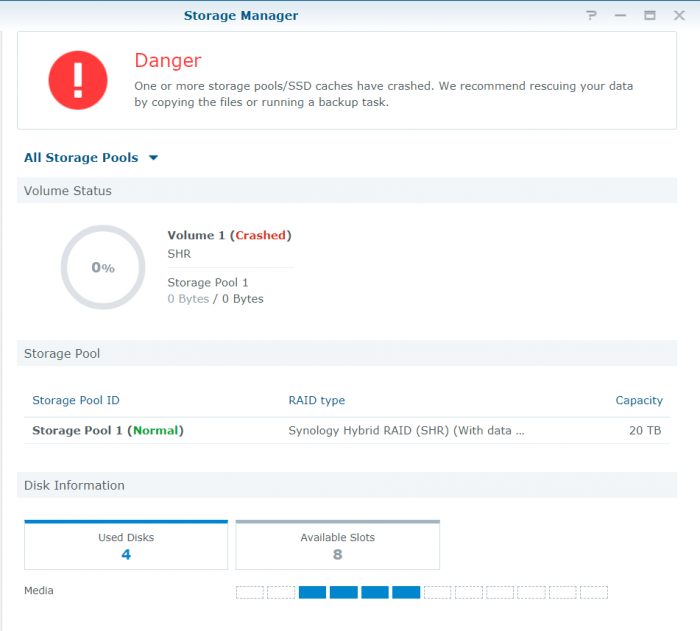
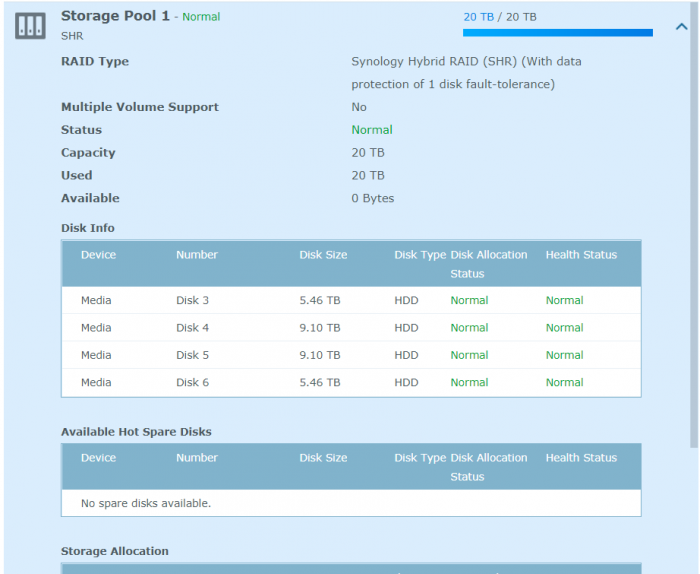
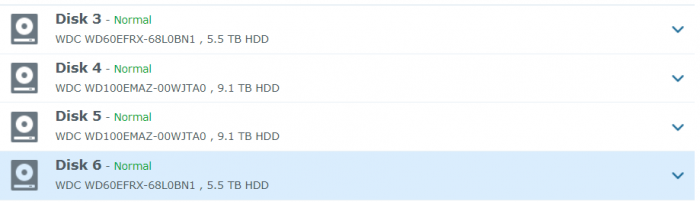

-
Hello, I am trying to recover about 5tb of data off of a 20tb volume on my xpenology system. The volume crashed while the system was under normal operating conditions. I have the system on battery backup, so power failure is not a likely cause. I have done a fair bit of research on how to accomplish the recovery, but I am running into a roadblock on what I expect is my potential solution. If I can get so pointers in the right direction I would really appreciate it. So I'll just drop some details here: fdisk -l cat /proc/mdstat mdadm --assemble --scan -v *These results contain numbers that get caught up in the forum filter so I removed them. If there is a way to post the results without it being flagged I will* I have one volume with the default name of "volume1" located at /dev/mapper/vg1000-lv or /dev/vg1000/lv I am not super familiar with how all of this works, but my research tells me that I can be using some repair options on the volume to correct the errors that caused the system to crash in the first place. These repair options are where I run into my trouble. Here is what I am talking about: fsck.ext4 -v /dev/vg1000/lv $ sudo fsck.ext4 -v /dev/vg1000/lv e2fsck 1.42.6 (21-Sep-2012) ext2fs_open2: Bad magic number in super-block fsck.ext4: Superblock invalid, trying backup blocks... fsck.ext4: Bad magic number in super-block while trying to open /dev/vg1000/lv The superblock could not be read or does not describe a correct ext2 filesystem. If the device is valid and it really contains an ext2 filesystem (and not swap or ufs or something else), then the superblock is corrupt, and you might try running e2fsck with an alternate superblock: e2fsck -b 8193 <device> I think this is telling me that I have a bad super-block. When it goes to repair with a backup super-block it has some trouble. This could mean that I am dead in the water, but I think the method of finding some alternative blocks for repair is as follows: mke2fs -n /dev/vg1000/lv sudo mke2fs -n /dev/vg1000/lv mke2fs 1.42.6 (21-Sep-2012) mke2fs: Size of device (0x13ff8e000 blocks) /dev/vg1000/lv too big to be expressed in 32 bits using a blocksize of 4096. On a typical system this lists out some blocks that are suitable replacements, but I have a 20tb volume! When I created the volume, I did not know that there was a pseudo 16tb limit on the ext4 system. Now I do. This is where my predicament is. I think there is a way to run this if I do some stuff I don't quite understand. For instance, this post (redacted because spam filter) Can anyone comment on whether this is a possibility? Am I going in the right direction? Any help would be greatly appreciated! Dom