

George
-
Posts
114 -
Joined
-
Last visited
Posts posted by George
-
-
-
Guys
With xPenology under Power Management I'm able to push the NAS into a suspend/sleep mode, and then wake up a pre determined time again.
Any chance anyone has access to the code that does this, how is it accomplished, mean the actual talking to the HW.
Need to replicate on another machine.
G
-
don't have another DSM.
G
-
Hi all,
busy with some serious rebuild of my NAS, as some might have noticed things went seriously south.
MY docker repository sits on Volumegroup 1 (I run Unify Controller as a docker deployment, thats probably the most important, new is Plex serve thats just a install, but need to figure out how to backup that indexed files also, in case I need to totally wipe/rebuild).
looking at everything that needs to be done, how can I backup my containers, and offload them (backups) to a off system, so that in case I need to, they can be restored after a complete rebuild, which might include a loader upgrade and complete new DSM build.
Haven't done this before
G
-
did some re-reading after 2 cups of coffee, things clearing up a bit, hazy
")
with my older 1.02b loader on the usb. - see how you say move HDD's and USB together,
where are my apps installed, where is the configuration all saved.
and then the 2 VG's Volume 1 (which does contain data I don't want to loose) based on a M.2 and the 5 problematic drives in volume 2, which it looks like I will destroy and rebuild.
is there a how to do the loader / DSM upgrade, without loosing vg1.. and my apps installed.
G
-
... TMI ...
if i can break it down, for myself, if it's a compatible MB, as long as drives goes back into same SATA slots numbers, and I use the same USB, all should just work ?
changing loader, well that starts sounding like a complete rebuild then, and "probably" loosing everything on my current setup which is something I really don't want.
but at the same time now might be the best time to get the loader and DSM upgraded, while wishing not to loose anything on my volume 1 DG.
G😅
-
ok.
just a crap load of copying, took we good part of 4 days to get data off.
G
-
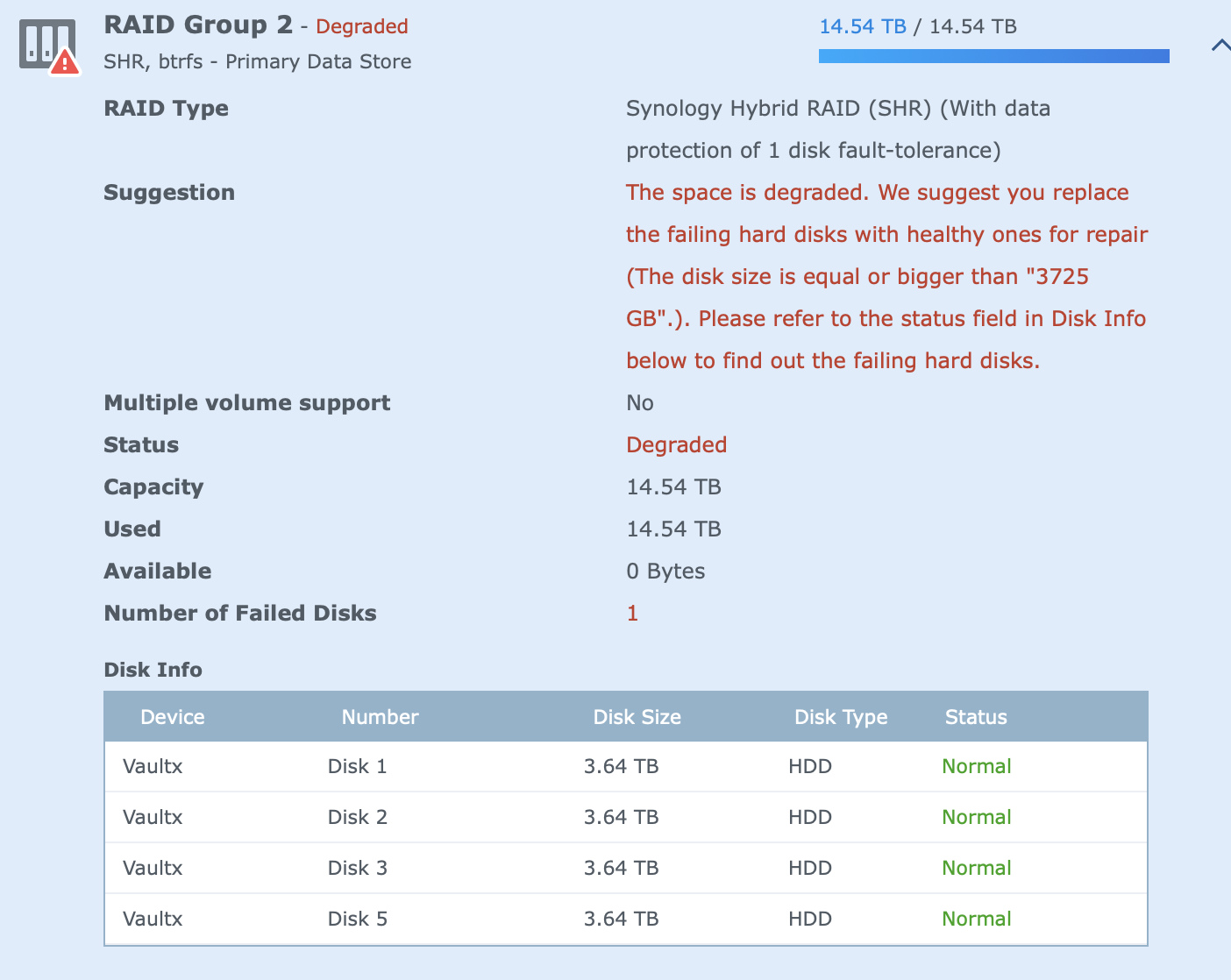
"You can't repair a RAID5 array with less than the full complement of drives. You must have 5 drives to rebuild, period." this have to have 5 drives in Raid 5 would be a DSM impose minimum as it's not a Raid5 technology limitation. With this 5 drive Raid 5 limit, it sort of then puts a stop to my idea to rather re-create the disk into to VG's. one as a mirror pair and the 2nd as a 4 disk VG.
OR... are you saying as this VG was originally 5 drives, it now has to stay 5 drives, I can't have it reconfigure/rebalance itself into a 4 drive Rad 5 VG.
ok, going to pull this drive out, zero the original drive and see if i can get it to rebuild.
G
-
so if I click Raid Group, Manage, Repair, it then only allows me to pick the one drive currently not being used, when that drive (used drive 4) is not there, then the entire manage and repair is grey'd out.
On Overview, I can see repair, and this is what is then shown, with no further options.
The volume group was 5 drives, last time I hit repair it went crashed right after, It's as if I need to get the VG rebuild with the 4 good drives, remove the 1 drive, and once healthy... then extend it by adding the 5th drive back.
G
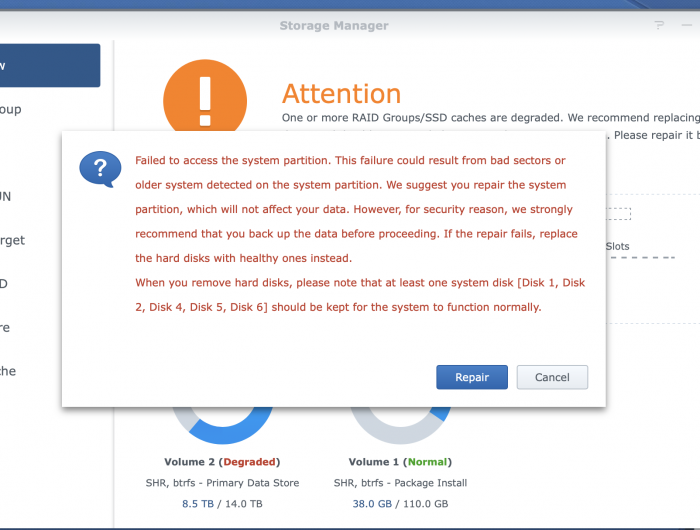
-
guys. please confirm.
My understanding below is that drive 4 is unused, I can remove it from the machine ?
issue... my 14.54TB size, that was based on the 5 drive configuration, how do I then tell DSM to rebuild based on the 4 drives ?
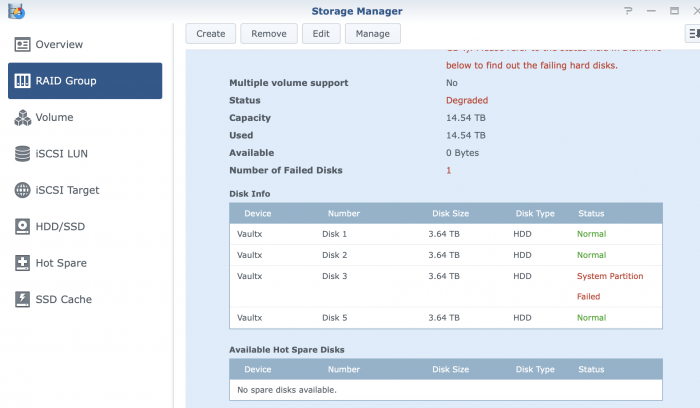
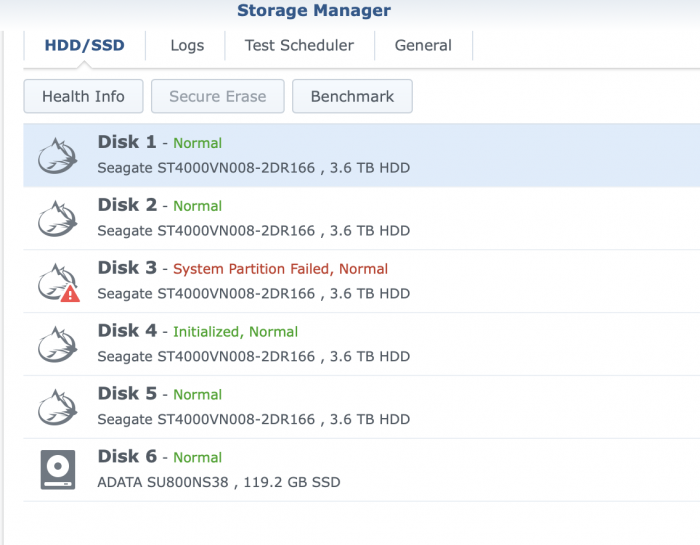
G
-
... Update...
So I've been able to copy all my data off the NAS. can either now try and fix the Volumegroup as it is/inplace. by removing reading the problem drive... or destroy and rebuild volume group into the 2 above Volume groups.
Although to do the above proper I'm going to move the one VG onto a separate pic based controller, which I need to order and have a 2-3 day lead time.
Thinking a 2 HDD group and a 4 HDD group,
comments.
G
-
thanks thanks.
know Raid 5 well.
so in essence it's a SW based Raid 5 with this smallest disk (run per physical disk) usage. ending in creating multiple raid 5 groups, the groups then added together into a volume group.
As for is something else maybe wrong, been wondering that way also. thinking is first thing is possible the data ports...
It was really mis behaving last night when I was trying to copy the photos, volume would crash, I would restart unit, and it come back degraded, as soon as I started trying to copy again it would crash. leading curious me click on logs for driving crashing and it was showing plug in plug out plug in plug out... resulting m taking unit down from where it normally stand, opening up and reseating all cables. it's been running stable since then. firs priority for now is to copy all media off the unit. Will then go into how to fix it.
Adding some new data controllers is low impact, I only have 2 volumes, Volume 1 is a cache volume located on a M.2, Volume 2, this one is the problem, so if rebuilding it's easy to move this one... my docker builds, Plex cache/library it's all on V1, unaffected.
If this is deeper, like the MB... then worried, how do I replace the MB and keep my build/My NAS configuration. This is where I'm stick my hand up and hope someone can assist.
Still wondering about the better drive configuration to go for, V2 at the moment was build with 5 x 4TB drives, I had the 6th drive space, in waiting, allot help it was
thinking of future rather going with 2 Raid5 groups, one as a mirror, ye thats really Raid 1 out of 2 x 4TB -> for documents/photos etc, as a new volume3 and then the remaining 3 (or 4 if I get an data controller) all reconfigured as Raid 5 into Volume 2 so that all the programs still find that media where it was expected. Moving the photos/documents is a low impact change that won't touch anyone, its just SMB shared out to one machine from where we copy onto the NAS.
the media is shared via the Plex and iTunes server so don't want to go reconfigured that, and have to re-index everything. (indexes are save on V1).
I'm just talking... still nervous, only had 4 hours sleep. working on this, and that included fighting with mosquito's and my son crawling into our bed mid night.
G
-
for my education.
2 x 6TB drives will give me 6TB useable,
3 x 4TB drives will give me 8TB, as the 3rd is used as parity/block copies on a round robin fashion ?
4 x 4TB will give me 12TB ? approx
5 x 4TB will give me 16TB ? approx
thinking about the rebuild, to contain the blast radius if something happens again, will rather go with 2 volume groups, one for documents and photos, the amount of space required is approx 2 TB, so 2 x 4TB will be good enough, at the moment that leaves me with 3 IO slits into which I can fit 3 x 4TB drives, will need to get a pic card with additional ports, but looking at the doing a 3 - 5 drive volume.
G
-
... took system off rack where it was, opened up, reseated allot of the cables, for now stable... still degraded state, but not going to touch that now.
busy copying as much as fast as I can.
G
-
... so system is seriously not happy.
Was busy copying data off, volume crashed again.
I'm restarting it and seeing how much I can continue copying before anything needs to be tried.
after restart. volume back, in degraded state, but it's back... make that it was back, immediately upon trying to start copying it crashed again, this is not looking good.
G
-
Power supply was replaced on Monday after the system repeatedly just shut down a couple of weeks, during the open /work /close it (volume group) would come back degraded (assume it was me bumping a cable), resulting in me initiating a rebuild, which then left it all good. But then it started doing this, on the same drive, drive 4 without me having been close to the unit which set of the alarm bells.
Last rebuild like that was last night, and it ended good, and well this morning when I got to the machine it (drive) was dead again, same drive, every time. so this time decided can't continue like this, replace the drive before we go further... I had a space 4TB drive, brand new, same model, but as you can see above what should be a easy stop out and repair has not gone to well.
My concern is my volume group was based on 5 drives, I've now had repeated problem with drive 4, which I ws trying to fix... and ye I could live with that, knowing I need to get it fixed, what scared me was during the last attempt drive 3 also failed, with drive 4 being a problem already, which then crashed the volume, luckily after a reboot it came back,
it's now switched off, going to stay off until I get a temporary off system backup drive to copy the most important media onto, before I try anything more with this volume group.
As it was also my Plex media server volume, would like to rebuild it, get it back to being volume group 2 and then copy all the media back onto it, into the same directory structures so that Plex does not have a fit.
it was also my Time Machine backup, but to reduce the volume from a odd 10TB down I deleted that, have some more directories I can delete to get the total volume under 8TB.
Also have a 2 TB drive onto which I can offload some docs/folders so that I can fit in on a 8TB drive.
Will start that copy tomorrow. (photos and documents first)
G
-
The volume is already SHR... but then also the volume is current fck'd... had a single drive problem, tried to repair it, kept on initialising the replacement drive, then kicked if out and said drive crashed (brand new drive) eventually out of the blue the volume crashed, luckily it came back degraded after a reboot,
busy looking at what drives to order, to switch unit back on, and copy the data off. and then try and repair it.
at the moment looking at either a cheaper Baracuda, 8TB drive or 2 higher end Ironwolfs. but the logic atm says go with the cheaper and use to as a off line cold backup rather and rebuild the volume group 2 out what I think is 5 good drives. and remove that one drive that kept on causing a degrade.
G
-
Hi all
Currently have a volume group based on 4TB HDD, having some serious problems... off topic, to backup the data I'm about to buy some additional drives to backup to.
I require 8TB so easy is 2 more 4TB drives. other option is a 4TB and a 6TB.
Once I'm done with the backup/restore etc etc. I won't mind being able to add say the 6TB drive into the unit. how will this be handled though?
aka 4 x 4TB + 1 x 6B drive. = using SHR
G
-
Update...
I rebooted the NAS and when it came back up... the Volume 2 was back, I can see it... at this point I'm stopping, going to buy a 8-10TB drive on Monday, copy everything off, before I loose data... and then take this from there.
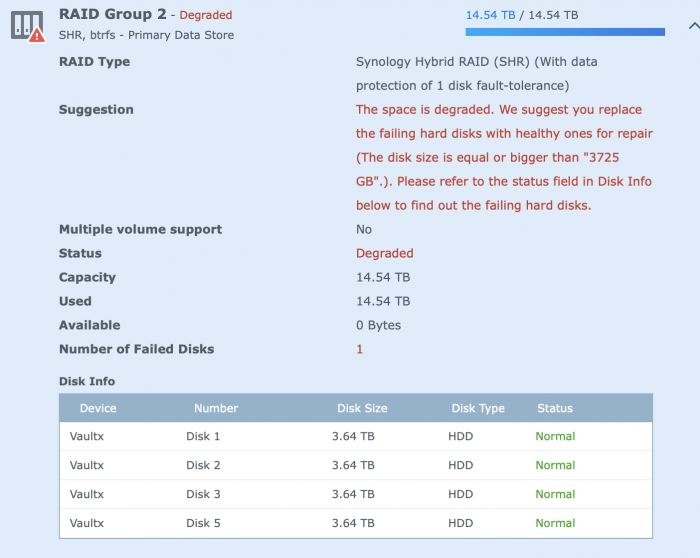
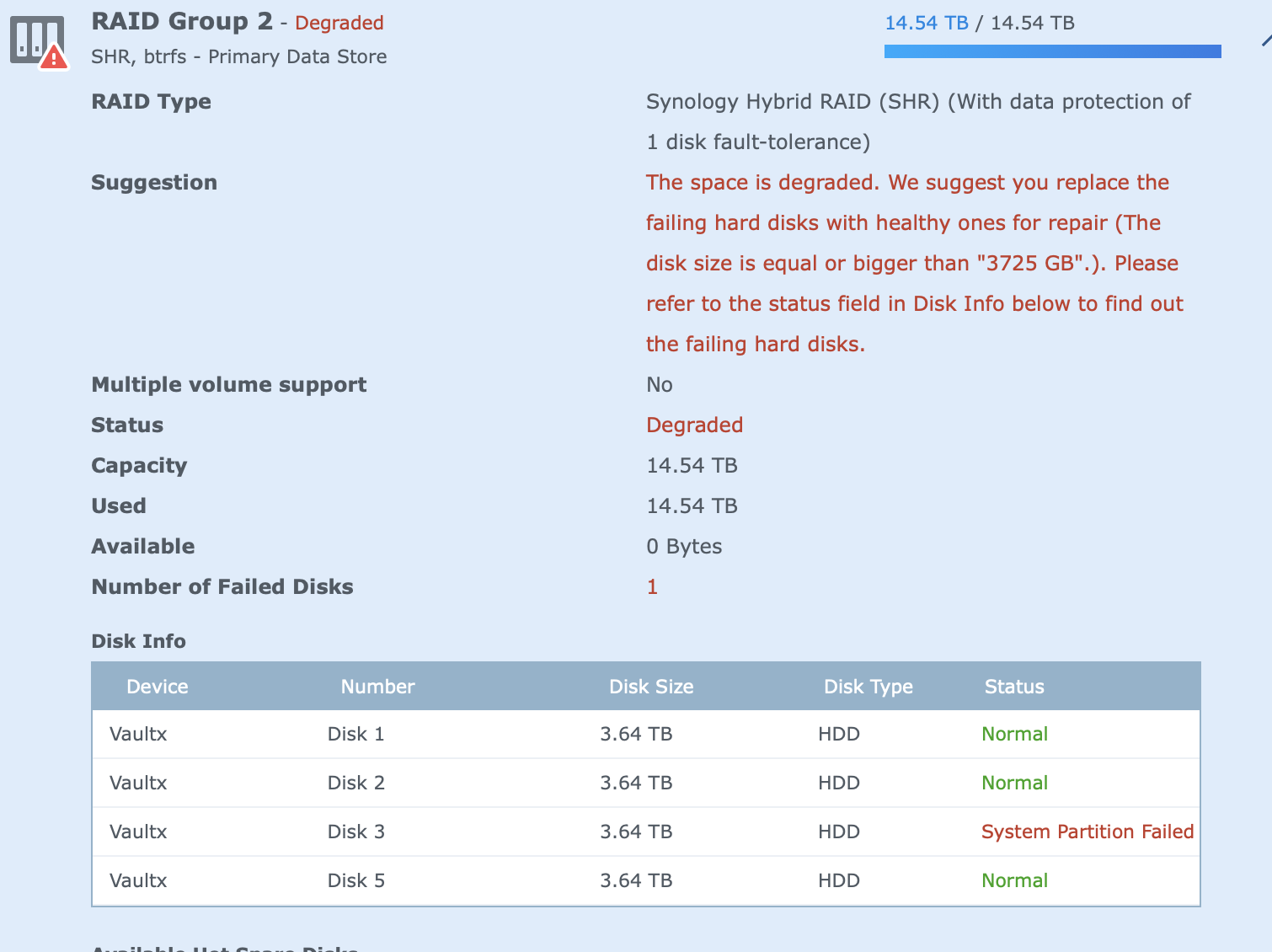
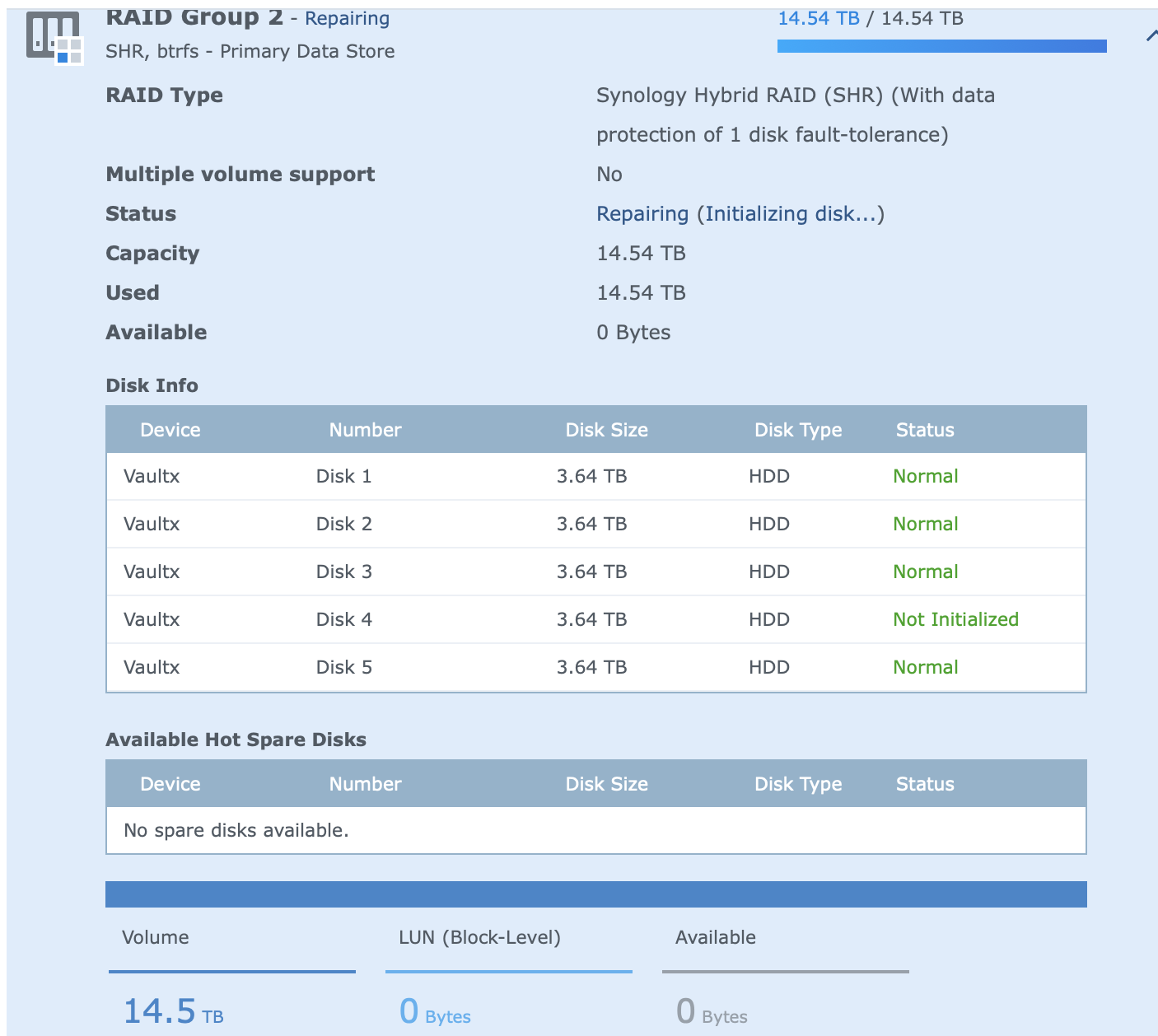
See attached, Drive 4 is still gone, with drive 3 now showing problem.
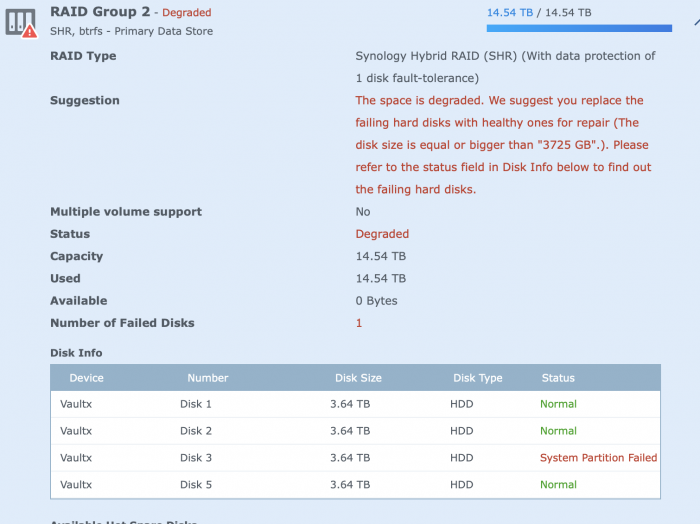
-
F F F F
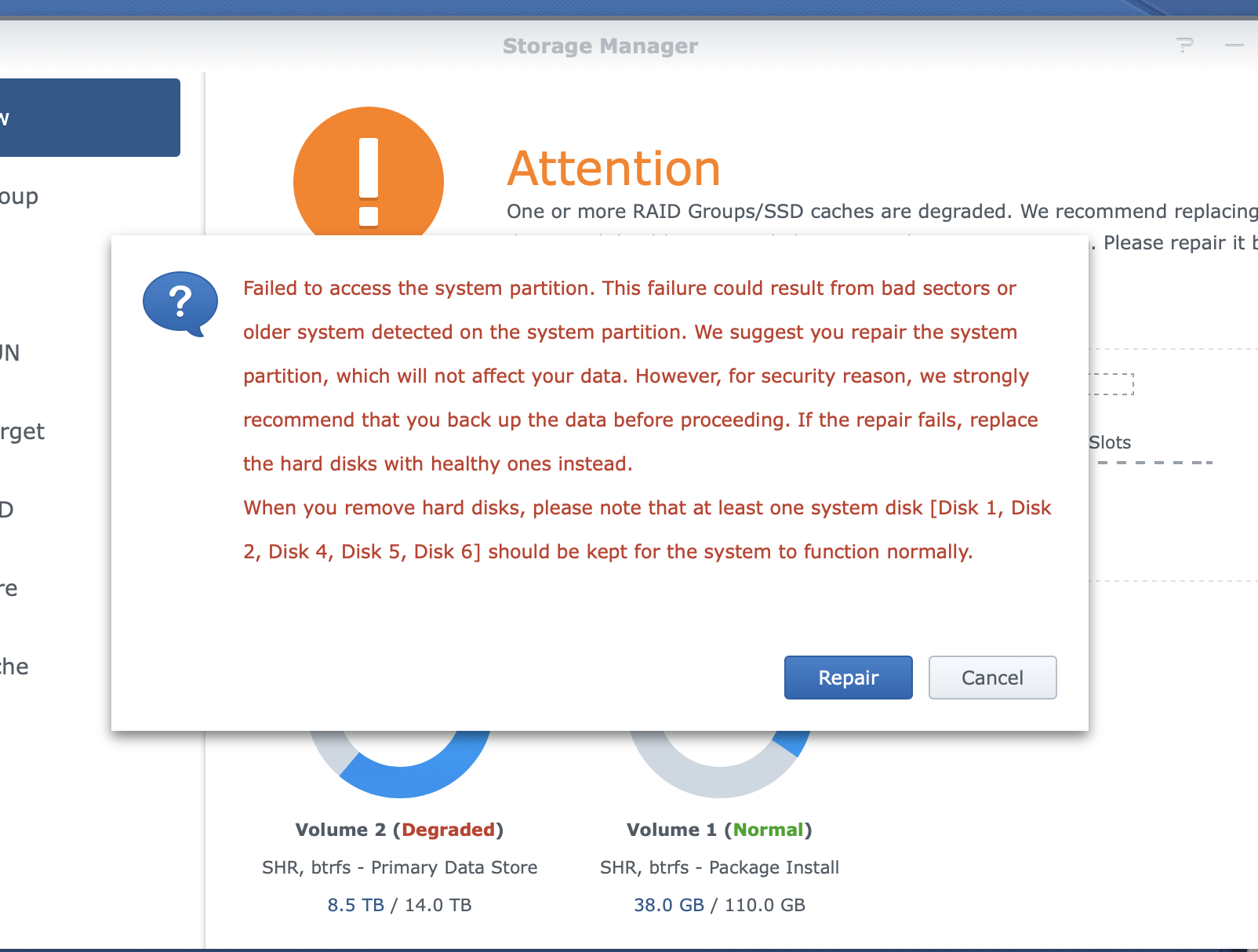
PLASE Help, tried to remove the faulty drive again, by doing a secure delete on it, it was available, not initialised, see attached, went manage/repair, and not I've go trouble.
the volume crashed, it seems to have now kicked out another drive. a this point I'm not touching it.
please HELP.
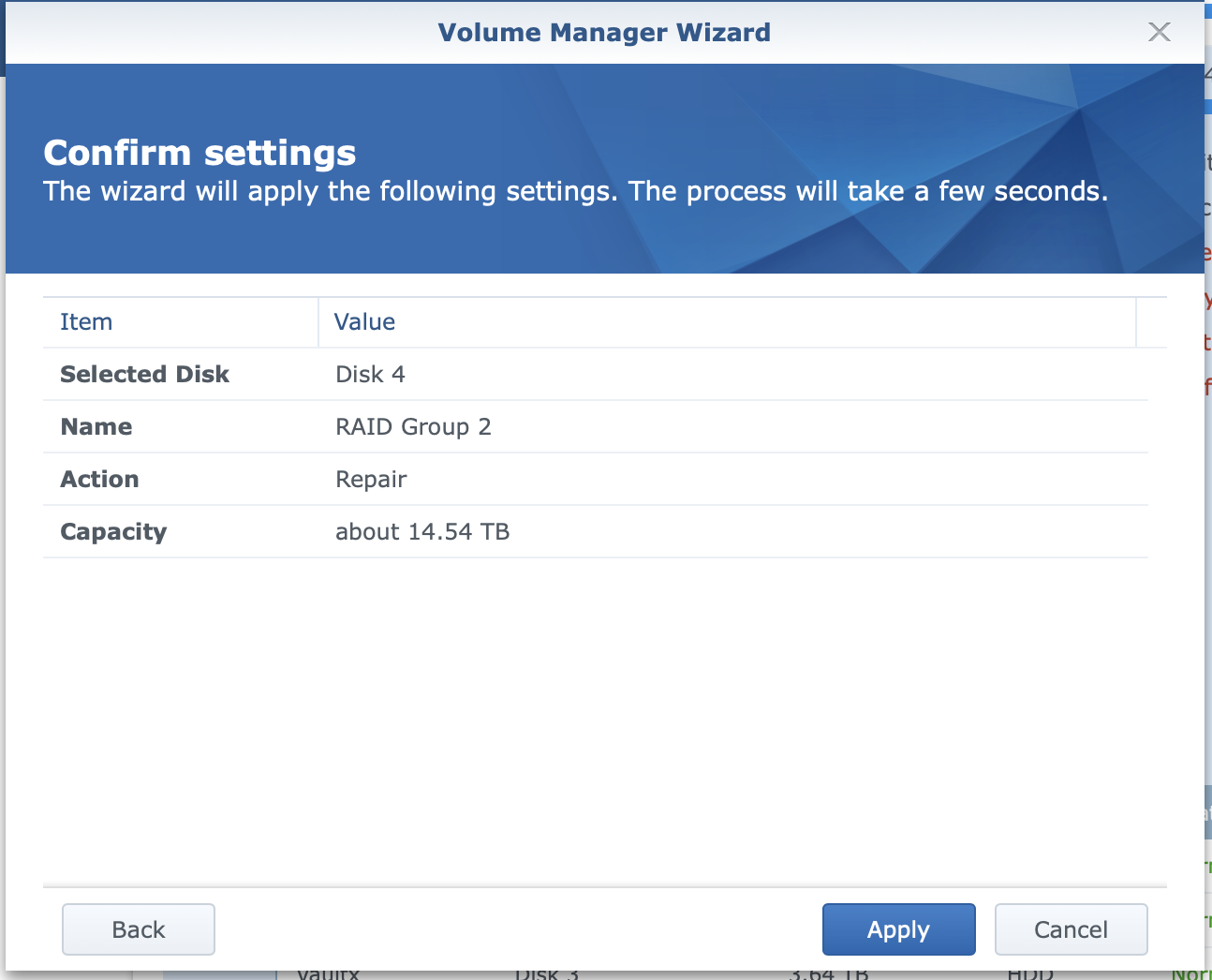
This was before the attempted re-add
This was was as I was adding the drive back.
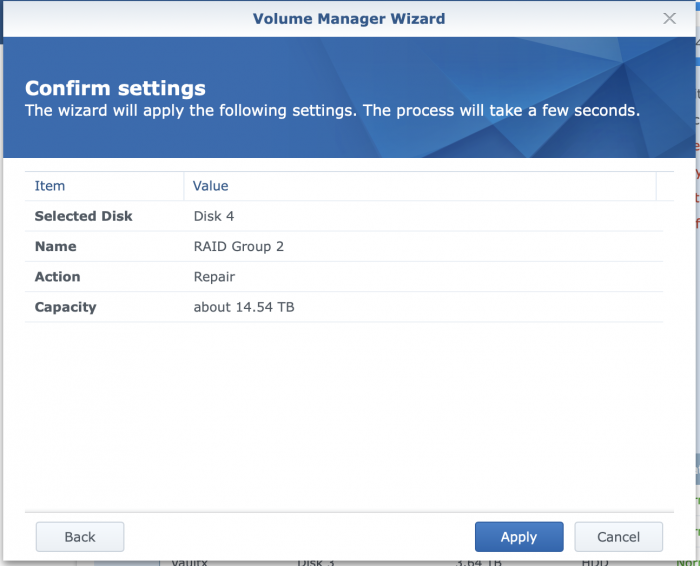
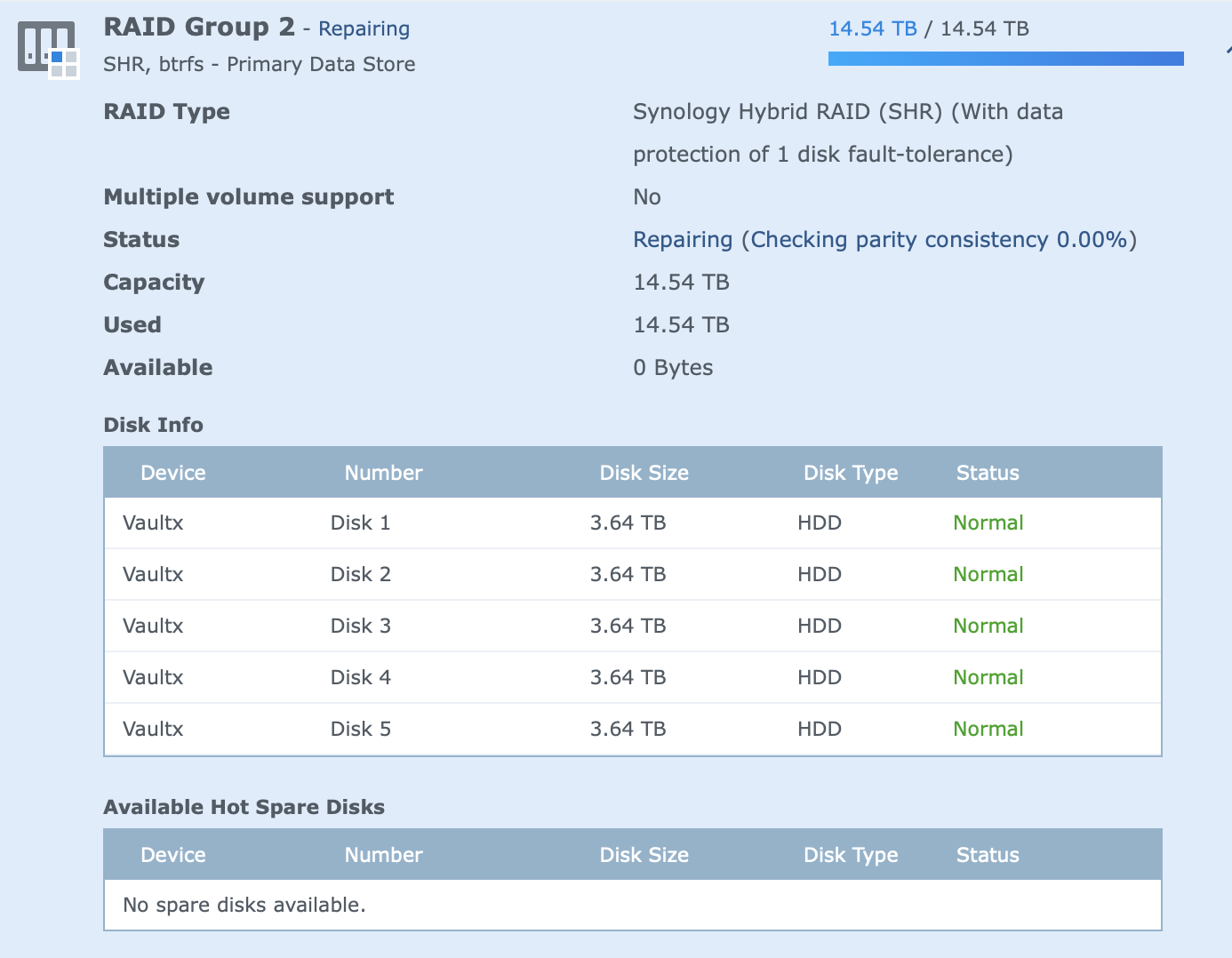
this was immediately after the add, after the apply, you can see the "repairing"
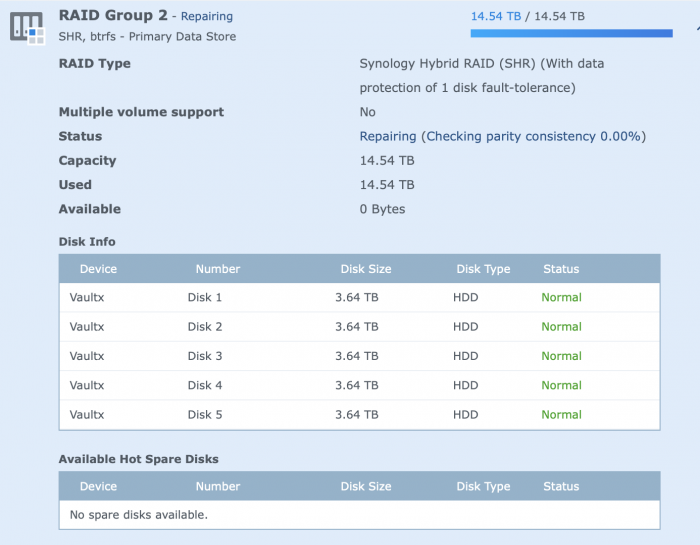
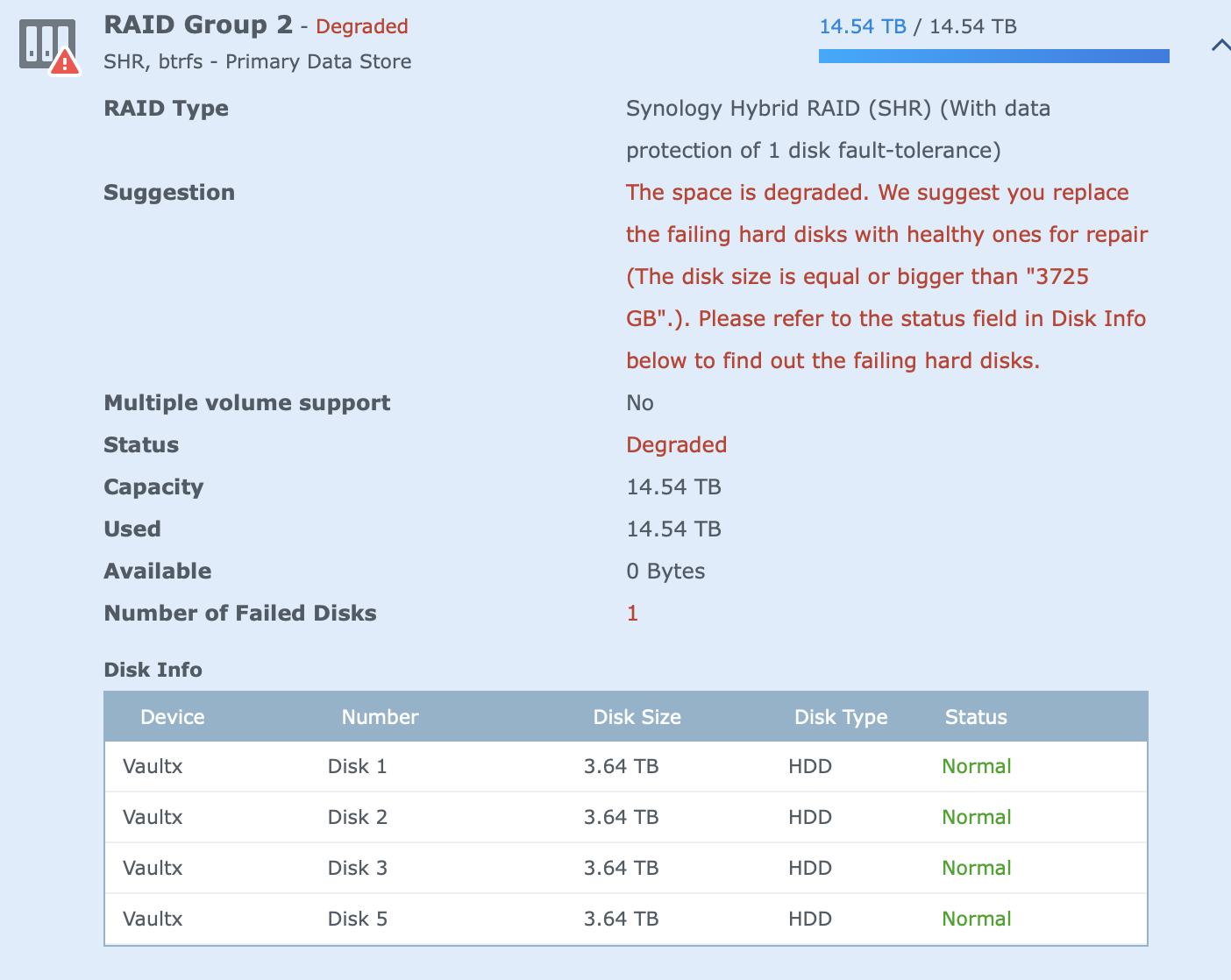
this immediately resulted in this...


If I click on HDD I see this now.
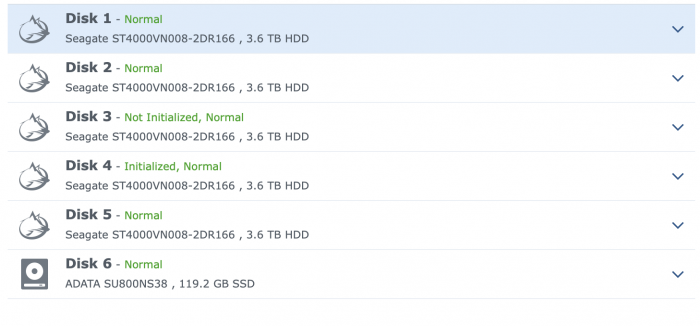
I'm to scared to touch anything, I believe all my data is still there, BUT...
If I go File Station all my directories with media/music/photos etc is gone, aka volume Group 2 located.
G
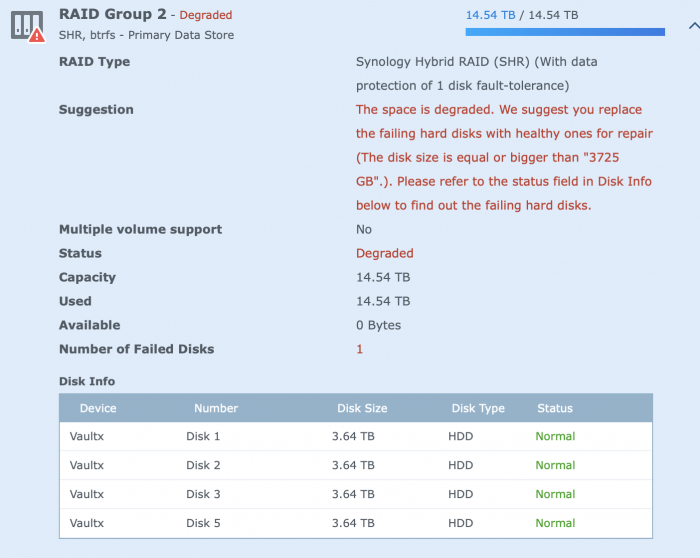
-
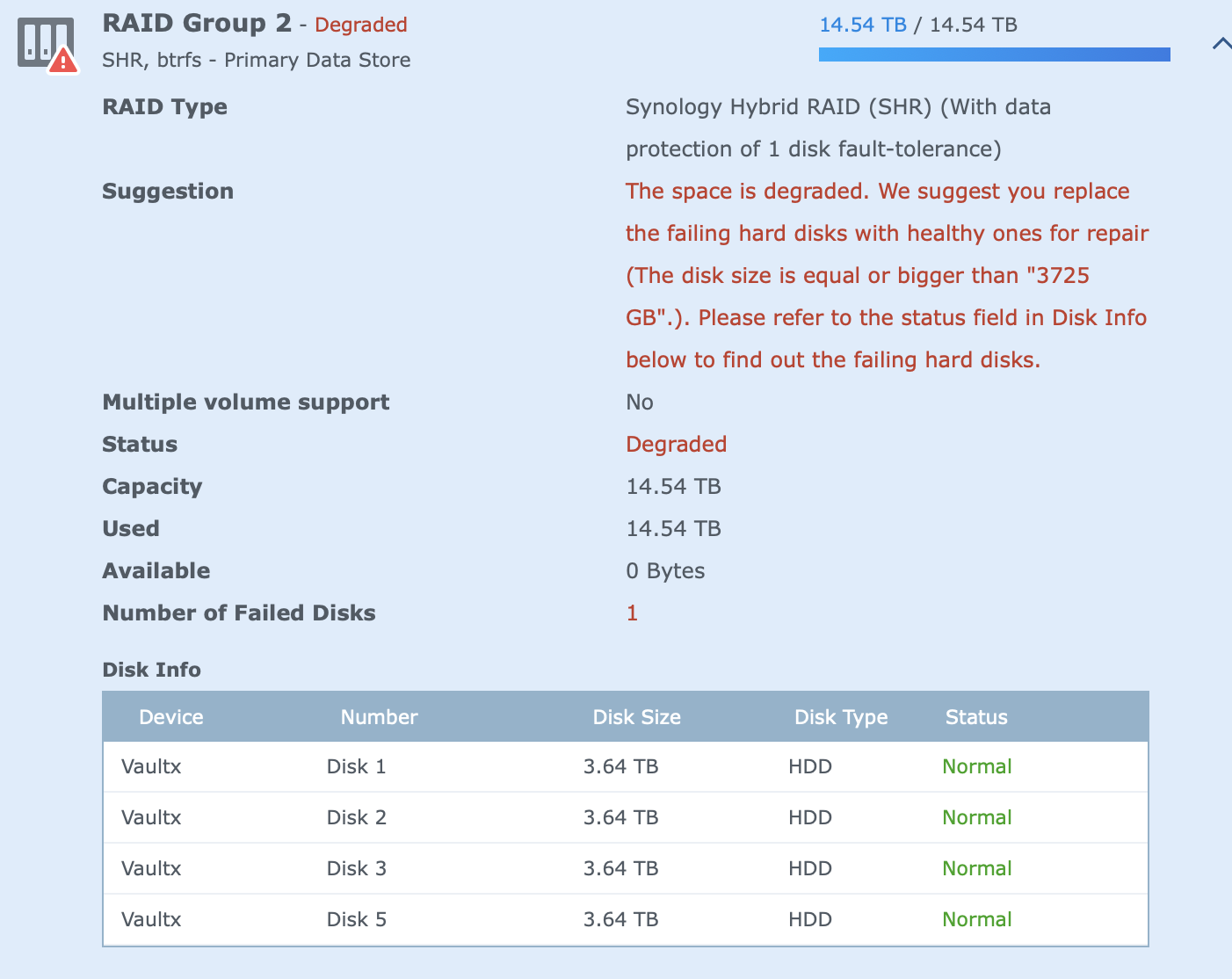
... wondering... if I looked at current space used 10.4TB... and it's still reporting the 5 drive configuration of 14TB, assuming that the 5th failed drive added 4TB, that might mean it's refusing me to remove the 5th failed drive, demanding I replace it as the space used currently is more than what will be available if that drive is removed,
comment ?
Adding, I see the drive itself is shown as 3.6TB useable.
G
-
See attached
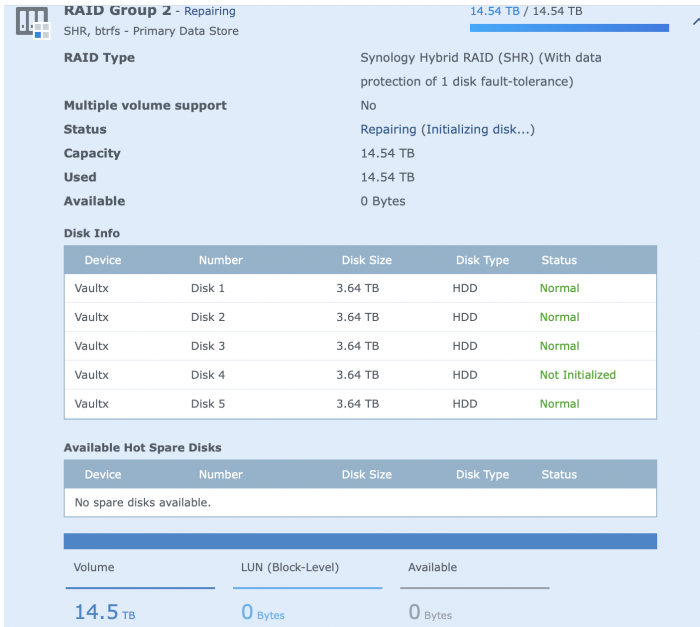

-
so zero'd the disk, re-inserted it, went Raid Group, Manage -> Repair, selected the now zero'd drive and not long, under minute of starting the initilize phased it failed again.
My primary wish now is to remove the failed drive from the volume group, aka reduce the group from 5 to 4 drives,
please assist?
G
-
so I placed the original drive 4 back... had it complete a rebuild, figuring once rebuild might b easier to then instruct the volume to remove the drive from the group, btw the insert/rebuild all ended good, finished yesterday afternoon,
I was logging in now, figured I'd configure email notification for if/when it fails again, and well as I logged din, same drive causing degraded availability...
ok, how do I remove the drive from the SHR group. I'm asking as the manage button is grey'd out at the moment and well the previous attempt to simply remove it and insert another drive/brand new drive did not end with expected results.
This is now concerning, any more failures will cause data loss.
G
PS: I'm looking at how I can delete all partitions from that other "new" drive in preparation. Got hold of a external case, so will insert it there, and then delete the partition via the MAC disk manager.




placing NAS into suspend mode, and waking up again.
in General Questions
Posted · Edited by George
1: MB: Gigabyte+GA-B250M-D3H
2: Linux/Debian to be specific.
3: D@mmmm hot.
at the moment, xPenology allows me to configure a "suspend" time and then some how injects a "wakeup" time, which I assume is actually talking to the BIOS via some generic/industry standard calls. (I would not assume xPenology had HW specific calls, very every MB).
When xPenology was doing this I can confirm my machine was in suspend mode, it was "dead" no fan or anything moving or turning, and powered itself back up at the scheduled time.
G