flyride
-
Posts
2,438 -
Joined
-
Last visited
-
Days Won
127
Everything posted by flyride
-
Best answer I have is that Synology DSM doesn't use mdadm.conf Arrays are assembled dynamically at boot time using the embedded metadata from each array member, and managed via Synology's own metadata manager called "space" What are you trying to accomplish?
-
Tutorial/Reference: 6.x Loaders and Platforms
flyride replied to flyride's topic in Tutorials and Guides
My thoughts on DSM 7.x on RedPill, as pertaining to this thread, are here: https://xpenology.com/forum/topic/58662-redpill-loader-information-thread/?tab=comments#comment-270478 With regard to hyperthreading, the only reason to disable hyperthreading is if the platform you are trying to run does not support all your possible threads. Using the example of the E3-1240 (I think that is what you are referring to) there are 8 possible threads - all currently available platforms can handle it. -
Set up email notificaiton when system powers on and about to shut down
flyride replied to BigKjju's topic in The Noob Lounge
Task Manager has startup and shutdown triggers. It can also run a custom script. You can install sendmail using Synology packages here: https://geektank.net/2022/01/29/sending-email-from-synology-via-cli-ssh-on-dsm-6/ Put the two together, and voila -
Cloned USB boot drive and now neither will boot XPenology
flyride replied to Badger's topic in The Noob Lounge
There isn't really any need to do such a thing. Keep your configured IMG file and burn a new loader just like you are doing now should you need to recover for any reason. If you must save off your loader image, the Win32 Disk Imager software referred to in the main FAQ works fine. -
Cloned USB boot drive and now neither will boot XPenology
flyride replied to Badger's topic in The Noob Lounge
You should be able to burn a new clean Jun 1.03b loader and it will recover your DSM installation. -
A simple bad sector won't cause the problems you seem to be having. I think you have a power problem or a cable problem. Please try and resolve this first before trying to restart the array again. The information you need to investigate and recover the array just like we have done is in this thread now. Post if you need help.
-
If there is a drive retrying a bad sector for a long time, the transfer rate will be slow while those sectors are being encountered. That is what you want (the drive trying to recover the data). Usually DSM will retry and then fail a particular file. But it might decide to crash the array if the drive error is significant enough. Are all the member drives still visible or has one or more disks gone offline? If drives are offline, that means you have some sort of continued hardware problem. Either a cable, controller or drive is failing. Nobody can diagnose the issue without you posting more information about the crash and circumstances. This needs to be fixed before trying anything again. If a drive is unusable at this point, your data is incomplete. You could send the array to a forensic recovery specialist at great cost, and they will retrieve some data from the array, but not all of it. "All the data is rubbish." Based on the signatures of the drives, this should not be the case, unless you modified one or more of the drives while DSM was not in control of them. I can't advise you on that. There will be some minor corruption based on the stale drive I talked about earlier but it should only be a few files if any.
-
Ok. So this is good news. You should be able to access your shares on /volume2 normally via the network, or via File Station. BUT, your nas is not in good shape. The /dev/md3 aka /volume2 array is critical (no redundancy). Any disturbance could cause loss of some or all of your data. So please consider the following data recovery process going forward: 1. Do not reboot 2. Do not attempt to fix anything in Storage Manager 3. Copy ALL your data off the nas 4. Delete your Volume2/Storage Pool 2 5. Replace any disks with bad sectors 6. Fix the System Partition using the button in Storage Manager 7. Build a new Storage Pool (array), testing the integrity of the drives 8. Build a new btrfs volume 9. Copy your files back onto the nas Please note that none of this does anything for your SSD, which I think is /dev/sde and normally mapped to /volume1. I don't know what is wrong with it, or if you have any important data on it. DSM doesn't even believe it exists at the moment. However, it isn't really affected by what is happening with your main data array.
-
mount -v /dev/md3 /volume2
-
ls -la /
-
Don't worry about what Storage Manager says right now. mount and df -v
-
That I don't understand at all. Try this: mdadm --assemble --scan cat /proc/mdstat
-
One more variant: mdadm --assemble /dev/md3 cat /proc/mdstat
-
Let's try a normal array start. mdadm --run /dev/md3 and cat /proc/mdstat
-
Interesting, DSM doesn't think your SSD has anything useful on it at all. Again, we'll ignore it for now. Current status: You have 8 members of a 10-member array that are functioning. RAID5 needs 9 to work in "critical" (i.e. non-redundant) mode. You have one more member that is accessible but is slightly out of date. The next step is to try and force that member back into the array in hopes that your data will be accessible. If it works, there will be a slight amount of corruption due to the stale array member. This may or may not be important. If that corruption is manifested in file data, btrfs will report it as a checksum error, but will not be able to correct it due to the lack of the 10th drive for redundancy. There are several methods of restarting the array with the stale member. The first one we will try is a non-destructive method - just resetting the stale flag. mdadm --stop /dev/md3 then mdadm --assemble --force /dev/md3 /dev/sda3 /dev/sdb3 /dev/sdc3 /dev/sdd3 /dev/sdf3 /dev/sdg3 /dev/sdj3 /dev/sdk3 /dev/sdl3 then cat /proc/mdstat Post output, including error messages from each of these.
-
Still no /dev/sde. I guess we will ignore that for now. We need a little more information before trying to force the array online: cat /etc/fstab and df -v
-
Anything different in Storage Manager?
-
We don't want the drive popping in and out. Maybe replace the SATA cables for all three devices encountering problems before proceeding?
-
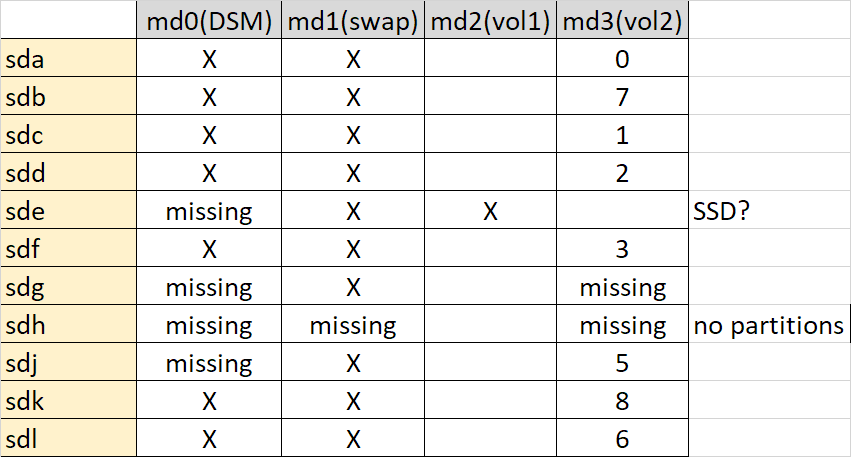
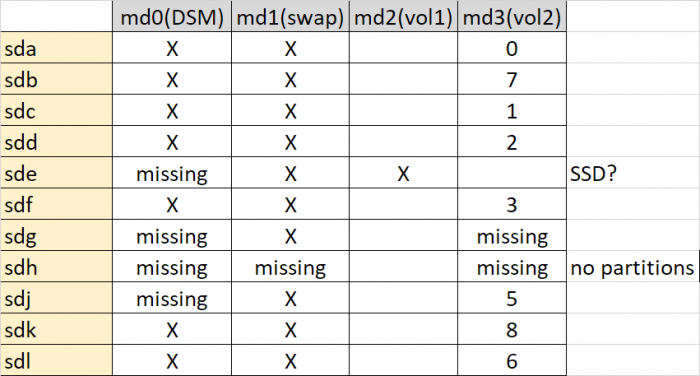
Do you know why /dev/sde was not online, then online, and now offline again? If there is an unresolved problem, we need it sorted before we start trying to fix arrays. Please advise on what is happening here. Now, in regard to your lost /dev/md3 array - the bad news is it looks like somehow the partitions have been deleted on /dev/sdh, which I think is one of the two missing members. This isn't a corruption as a new partition has been created in place. Maybe the /dev/sdh device got put into a Windows machine and accidentally overwrite the existing partitions that would not have been recognized there? Please advise on what may have happened here. Since /dev/sdh is kaput, that means the only possibility of recovering your /dev/md3 is /dev/sdg3. It seems intact but is out of date (about 600 writes). We can theoretically force it back into the array and it should work, but there will be a small amount of corrupted files that were affected by the missing writes.
-
/dev/sde is missing again. Is there a reason for this or did it go offline? Also, is that the SSD you are speaking of? /dev/sdh is probably our missing /dev/md2 array member. It isn't showing any partitions so it may be completely trashed. But let's confirm this: mdadm --examine /dev/sdh
-
-
I'm trying to noodle out how your system is configured vs. the mdadm reports. You say you have 10x 4TB disks. Your RAID5 array thinks it has 10 members, but it can only find 8. Later you report an SSD. Can you tell me for certain which device the SSD is? I assume it is /dev/sde /dev/sdh and /dev/sdi are missing, but that could be because you have multiple controllers and you didn't resolve a "gap" between them, or it could be that the drive(s) isn't reporting any usable partitions We need to figure out more information. Please post results of this command: ls /dev/sd* We also can see if we can get any corroborating information from the array members about the construction of the /dev/md3 array: mdadm --examine /dev/sd[abcdfgjkl]3 That last command will report a lot of data. It looked like you accidentally pasted the previous results back into DSM and it tried to execute the results as commands. Please use care to make sure the copy/paste is accurate.
-
Dude. Please don't change your historical posts. I can't tell what has changed now since the original pic is gone. The only way to get data back is to deliberately work through a validation process until something actionable is found. If things change midstream, the process will either start over (at best) or destroy your data beyond recovery (at worst). You also seem to be typing in commands without understanding what they are for. I suggest you stop doing that. Your data is at risk.
-
To orient you a bit on what is being reported: /dev/md0 is a RAID1 array and is the DSM "system" spanning all your disks. This array is working but some members have failed. /dev/md1 is a RAID1 array and is the Linux swap partition spanning all your disks. This array is working but some members have failed. /dev/md3 is a RAID5 array and is probably what you called /volume2 - this is currently crashed. Since you think you have a /volume1, it would make sense that it was /dev/md2 but at the moment the system isn't recognizing it at all. What to do next: 1. Generally it would be easier if you cut and pasted text from TELNET instead of picture screenshots as you gather information. 2. Get more information about the possibility of /dev/md2's existence by querying one of the disks for partitions. Post the results of this command: fdisk -l /dev/sda 3. Get more information about /dev/md3 by querying the array for its members. Post the results of this command: mdadm --detail /dev/md3
-
DSM system is on ALL drives. What was on Volume 1 that makes you think that it's the "system" installation? Now that you have restored your disks to DSM, you could start by posting a current mdstat so we have some idea about what the system thinks about the configuration of your arrays and their statuses.