kaku
-
Posts
41 -
Joined
-
Last visited
Everything posted by kaku
-
Now I went back to TCRP and using fresh serial. Now atleast DSM boots. But now i am in a recoverable loop. Any idea how to get out of it? Sent from my SM-G998B using Tapatalk
-
Yes, volume1 had all the packages abd was the first pool. DSM dont boot if Using only volume1 disk . No IP but led blinks. Using ONLY Volume2, DSM boots. Now if i connect disks of volime1 while DSM IS running then all packages are displayed and are marked to repair. I do all the package repair, and then reboot. Then again DSM FAILS TO boot (no ip) led blinks Volume1 cannot be in system at boot. Also I did a reinstall of DSM ON BOTH volumes by adding all drives(vol1 &vol2) AFTER the dsm booted and showed no drives error. It went ok . But on reboot again no IP. Sent from my SM-G998B using Tapatalk
-
Hey, just out of curiosity. Did you try a fresh install ? Preferably with no volumes. I also dont get ip (but port leds do blink) when i have multiple raid volumes) It works with a fresh install or in an existing raid0 single volume.
-
Ok so reinstalling DSM also didnt work. Data is intact but still volume1 disks will not let me boot if plugged in! Sent from my SM-G998B using Tapatalk
-
Ok so reinstalling DSM also didnt work. Data is intact but still volume1 disks will not let me boot if plugged in!
-
I posted this is ARPL thread, but i think i should post here. I am trying to upgrade my hardware and shift my drives to it. its a B660 chipset board with i5 12400 CPU. I used the SAME SN and mac as before (DS3622xs+) as old HW on (TCRP DSM 7.1 4661 ) It has 2 Volumes Volume 1 main (RAID 5 with all packages, 3 Disk) Volume 2 (1 DISK ) I have successfully Loaded the latest ARPL. Issue is if I Connect Volume 2 (1 DISK to system ) . it boots ok. But if Both volumes are connected (3 + 1 disk ), I get no boot ( no IP). I have connected Vol2 (1 Disk) to all SATA ports one-by-one to check if any port issues, but they all are ok. Something in main Volume1 is giving boot issues. If i HOTPLUG the volume1 disk while DSM is running, the volume gets detected and i can assemble them, and "rapair" all packages. I dont know, where to start to solve this issue. how can certain packages force a No BOOT? Sent from my SM-G998B using Tapatalk
-
Delete
-
I am trying to upgrade my hardware and shift my drives to it. its a B660 chipset board with i5 12400 CPU. I used the SAME SN and mac as before (DS3622xs+) as old HW on (TCRP DSM 7.1 4661 ) It has 2 Volumes Volume 1 main (RAID 5 with all packages, 3 Disk) Volume 2 (1 DISK ) I have successfully Loaded the latest ARPL. Issue is if I Connect Volume 2 (1 DISK to system ) . it boots ok. But if Both volumes are connected (3 + 1 disk ), I get no boot ( no IP). I have connected Vol2 (1 Disk) to all SATA ports one-by-one to check if any port issues, but they all are ok. Something in main Volume1 is giving boot issues. If i HOTPLUG the volume1 disk while DSM is running, the volume gets detected and i can assemble them, and "rapair" all packages. I dont know, where to start to solve this issue. how can certain packages force a No BOOT?
-
I have the data ok. But how to remove readonly and how to repair volume1. I want to learn. @flyride can you help?
-
update I did a fore mount using mdadm -Af ash-4.4# mdadm -Af /dev/md2 /dev/sd[abc]3 mdadm: forcing event count in /dev/sda3(0) from 435242 upto 436965 mdadm: Marking array /dev/md2 as 'clean' mdadm: /dev/md2 has been started with 2 drives (out of 3). And restarted NAS. Now The raid is loaded in read-only mode with Disk 2 as Crashed. (attached). Atleast backup can happen. Still get no output from lvdisplay or vg display. How how to fully restore the RAID Back to original state? ash-4.4# cat /proc/mdstat Personalities : [raid1] [raid6] [raid5] [raid4] [raidF1] md2 : active raid5 sda3[4] sdc3[2] 7804393088 blocks super 1.2 level 5, 64k chunk, algorithm 2 [3/2] [U_U] md3 : active raid1 sdd3[0] 971940544 blocks super 1.2 [1/1] [U] md1 : active raid1 sda2[0] sdd2[3] sdc2[2] 2097088 blocks [12/3] [U_UU________] md0 : active raid1 sda1[0] sdd1[3] sdc1[1] 2490176 blocks [12/3] [UU_U________] unused devices: <none> ash-4.4# cat /etc/fstab none /proc proc defaults 0 0 /dev/root / ext4 defaults 1 1 /dev/mapper/cachedev_0 /volume2 ext4 usrjquota=aquota.user,grpjquota=aquota.group,jqfmt=vfsv0,synoacl,relatime,nodev 0 0 /dev/mapper/cachedev_1 /volume1 btrfs auto_reclaim_space,ssd,synoacl,relatime,nodev,ro,recovery 0 0 ash-4.4# mdadm --examine /dev/md2 mdadm: No md superblock detected on /dev/md2.
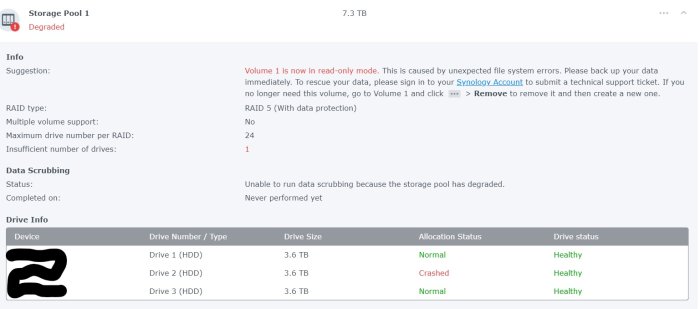
-
Other stats' cat /etc/fstab none /proc proc defaults 0 0 /dev/root / ext4 defaults 1 1 /dev/mapper/cachedev_0 /volume2 ext4 usrjquota=aquota.user,grpjquota=aquota.group,jqfmt=vfsv0,synoacl,relatime,nodev 0 0 lvdisplay -v & vgdisplay -v Using logical volume(s) on command line. No volume groups found.
-
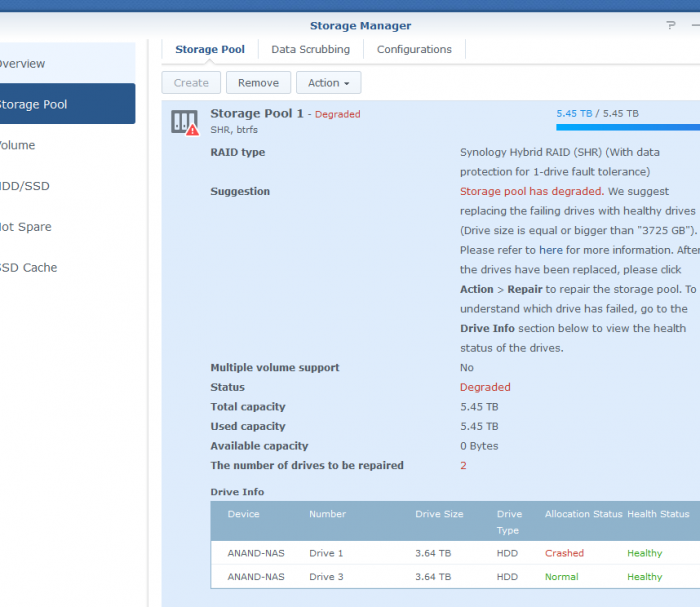
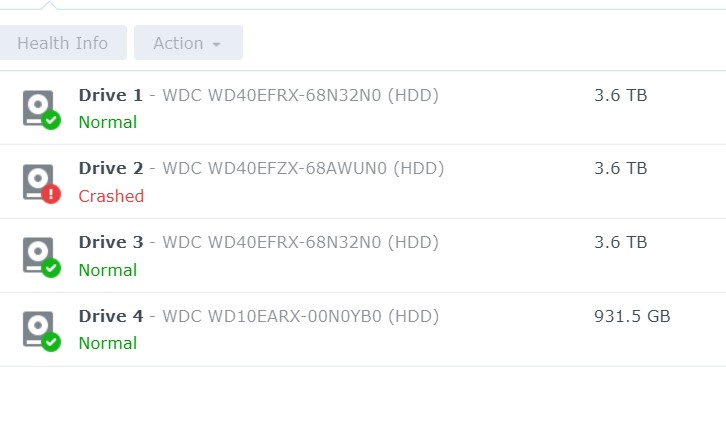
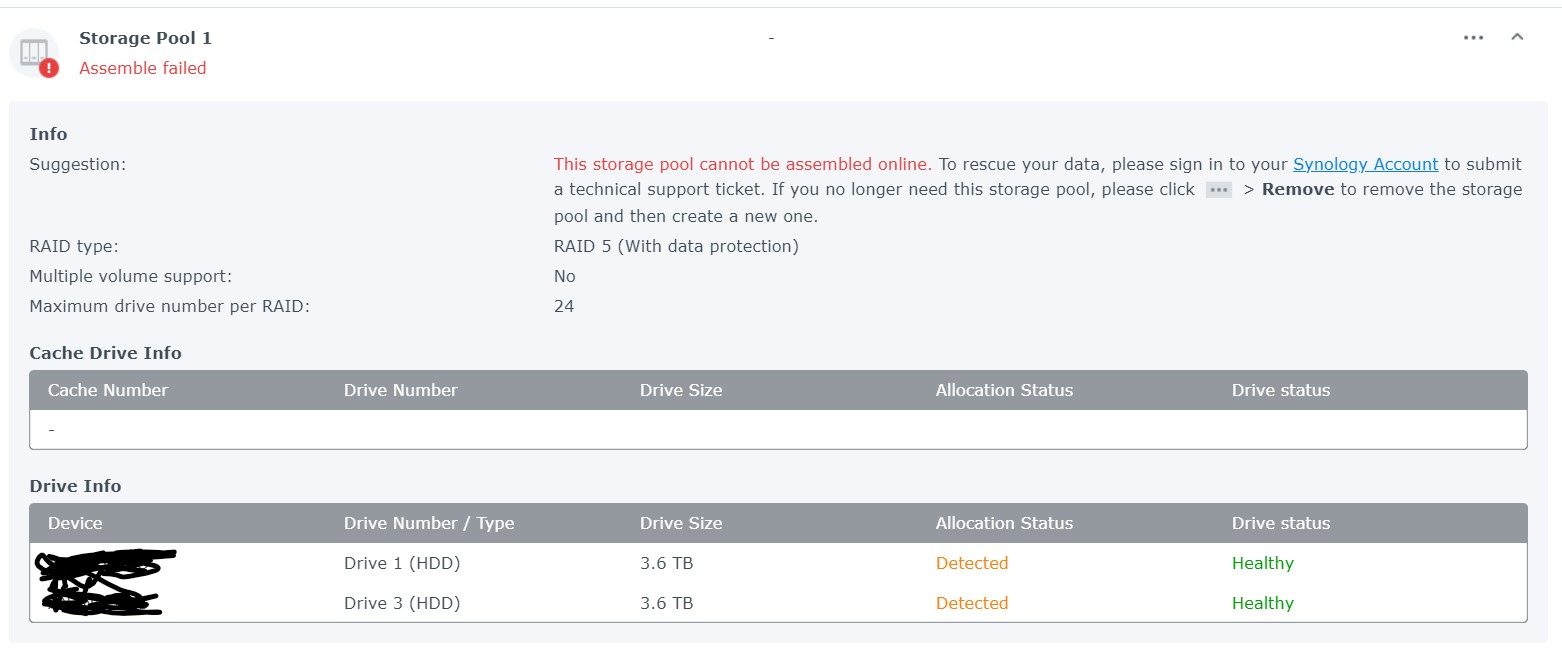
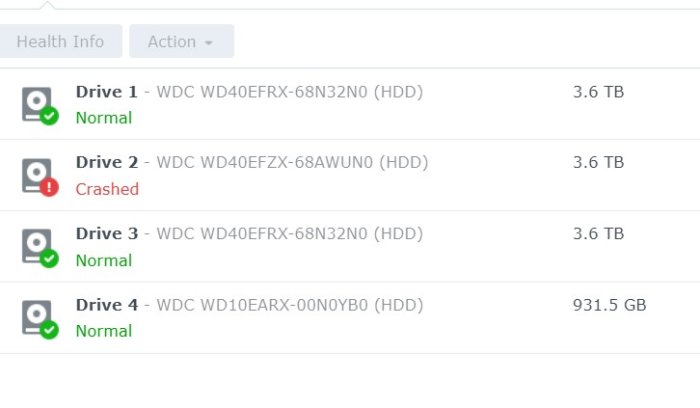
3 Disk 4TB each In raid five . EXt4 (most probably) Volume Crashed. First, Disk 2 was kicked out of the system. Then I tried to repair volume ,In between of repair ,system freeze. Then a force reboot and Now it shows only 2 drives (1 & 3) but no Volume. see pic. System stats as follows. I am afraid , i cant see the md* of RAID5 in this cat /proc/mdstat :/$ cat /proc/mdstat Personalities : [raid1] [raid6] [raid5] [raid4] [raidF1] md3 : active raid1 sdd3[0] 971940544 blocks super 1.2 [1/1] [U] md1 : active raid1 sda2[0] sdd2[3] sdc2[2] 2097088 blocks [12/3] [U_UU________] md0 : active raid1 sda1[0] sdd1[3] sdc1[1] 2490176 blocks [12/3] [UU_U________] unused devices: <none> # ls /dev/sd* &mg* &vg* :/$ ls /dev/sd* /dev/sda /dev/sda2 /dev/sdb /dev/sdb2 /dev/sdc /dev/sdc2 /dev/sdd /dev/sdd2 /dev/sda1 /dev/sda3 /dev/sdb1 /dev/sdb3 /dev/sdc1 /dev/sdc3 /dev/sdd1 /dev/sdd3 ls /dev/md* /dev/md0 /dev/md1 /dev/md3 ls /dev/vg* /dev/vga_arbiter fdisk Disk /dev/sda: 3.7 TiB, 4000787030016 bytes, 7814037168 sectors Disk model: WD40EFRX-68N32N0 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: 4474BB43-A9CA-4DFD-88E8-0BA2B74DAEFA Device Start End Sectors Size Type /dev/sda1 2048 4982527 4980480 2.4G Linux RAID /dev/sda2 4982528 9176831 4194304 2G Linux RAID /dev/sda3 9437184 7813832351 7804395168 3.6T Linux RAID Disk /dev/sdb: 3.7 TiB, 4000787030016 bytes, 7814037168 sectors Disk model: WD40EFZX-68AWUN0 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: F4E61428-D392-4531-BD1D-5627E5B74CE9 Device Start End Sectors Size Type /dev/sdb1 2048 4982527 4980480 2.4G Linux RAID /dev/sdb2 4982528 9176831 4194304 2G Linux RAID /dev/sdb3 9437184 7813832351 7804395168 3.6T Linux RAID Disk /dev/sdc: 3.7 TiB, 4000787030016 bytes, 7814037168 sectors Disk model: WD40EFRX-68N32N0 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: F89224BD-A6CE-4E43-B931-1B27A81851D5 Device Start End Sectors Size Type /dev/sdc1 2048 4982527 4980480 2.4G Linux RAID /dev/sdc2 4982528 9176831 4194304 2G Linux RAID /dev/sdc3 9437184 7813832351 7804395168 3.6T Linux RAID mdadm -E /dev/sd[abc]3 :/$ sudo mdadm -E /dev/sd[abc]3 /dev/sda3: Magic : a92b4efc Version : 1.2 Feature Map : 0x0 Array UUID : 11ce188f:371222c5:8a4761cc:b7dadd5e Name : *******:2 (local to host *******) Creation Time : Sun Oct 10 20:47:44 2021 Raid Level : raid5 Raid Devices : 3 Avail Dev Size : 7804393120 (3721.42 GiB 3995.85 GB) Array Size : 7804393088 (7442.85 GiB 7991.70 GB) Used Dev Size : 7804393088 (3721.42 GiB 3995.85 GB) Data Offset : 2048 sectors Super Offset : 8 sectors Unused Space : before=1968 sectors, after=32 sectors State : active Device UUID : b2d1d339:fe245365:d3cbdc43:500b2530 Update Time : Tue Nov 15 23:54:18 2022 Checksum : 32868cc9 - correct Events : 435242 Layout : left-symmetric Chunk Size : 64K Device Role : Active device 0 Array State : A.A ('A' == active, '.' == missing, 'R' == replacing) /dev/sdb3: Magic : a92b4efc Version : 1.2 Feature Map : 0x2 Array UUID : 11ce188f:371222c5:8a4761cc:b7dadd5e Name : ********:2 (local to host *******) Creation Time : Sun Oct 10 20:47:44 2021 Raid Level : raid5 Raid Devices : 3 Avail Dev Size : 7804393120 (3721.42 GiB 3995.85 GB) Array Size : 7804393088 (7442.85 GiB 7991.70 GB) Used Dev Size : 7804393088 (3721.42 GiB 3995.85 GB) Data Offset : 2048 sectors Super Offset : 8 sectors Recovery Offset : 57125640 sectors Unused Space : before=1968 sectors, after=32 sectors State : active Device UUID : d361e948:90e86d91:74fc12b8:990fe2b9 Update Time : Tue Nov 15 20:57:46 2022 Checksum : 6f148faf - correct Events : 433354 Layout : left-symmetric Chunk Size : 64K Device Role : Active device 1 Array State : AAA ('A' == active, '.' == missing, 'R' == replacing) /dev/sdc3: Magic : a92b4efc Version : 1.2 Feature Map : 0x0 Array UUID : 11ce188f:371222c5:8a4761cc:b7dadd5e Name : *******:2 (local to host *******) Creation Time : Sun Oct 10 20:47:44 2021 Raid Level : raid5 Raid Devices : 3 Avail Dev Size : 7804393120 (3721.42 GiB 3995.85 GB) Array Size : 7804393088 (7442.85 GiB 7991.70 GB) Used Dev Size : 7804393088 (3721.42 GiB 3995.85 GB) Data Offset : 2048 sectors Super Offset : 8 sectors Unused Space : before=1968 sectors, after=32 sectors State : clean Device UUID : 1e7abd48:b47b32d8:bddf08b0:a7f7b166 Update Time : Wed Nov 16 11:39:24 2022 Checksum : 570a3827 - correct Events : 436965 Layout : left-symmetric Chunk Size : 64K Device Role : Active device 2 Array State : ..A ('A' == active, '.' == missing, 'R' == replacing)
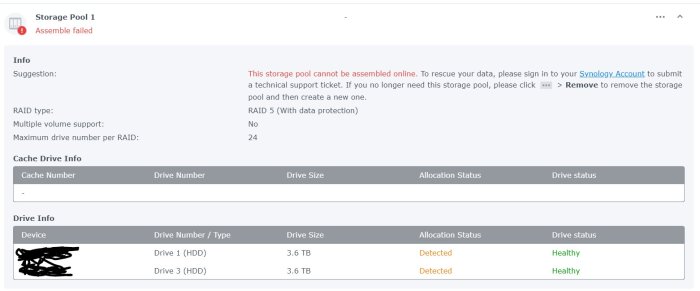
-
Thanks @pocopico This works. FYI depmod -a sudo depmod -a depmod: WARNING: could not open /lib/modules//modules.order: No such file or directory depmod: WARNING: could not open /lib/modules//modules.builtin: No such file or directory
-
I have a bare metal system with following: COU : i5 Ivy Bridge Motherboard : Gigabyte GA-B75M-D3H tc@box:~$ lspci -nnq 00:00.0 Host bridge [0600]: Intel Corporation Xeon E3-1200 v2/3rd Gen Core processor DRAM Controller [8086:0150] (rev 09) 00:02.0 VGA compatible controller [0300]: Intel Corporation Xeon E3-1200 v2/3rd Gen Core processor Graphics Controller [8086:0152] (rev 09) 00:14.0 USB controller [0c03]: Intel Corporation 7 Series/C210 Series Chipset Family USB xHCI Host Controller [8086:1e31] (rev 04) 00:1a.0 USB controller [0c03]: Intel Corporation 7 Series/C216 Chipset Family USB Enhanced Host Controller #2 [8086:1e2d] (rev 04) 00:1b.0 Audio device [0403]: Intel Corporation 7 Series/C216 Chipset Family High Definition Audio Controller [8086:1e20] (rev 04) 00:1c.0 PCI bridge [0604]: Intel Corporation 7 Series/C216 Chipset Family PCI Express Root Port 1 [8086:1e10] (rev c4) 00:1c.4 PCI bridge [0604]: Intel Corporation 7 Series/C210 Series Chipset Family PCI Express Root Port 5 [8086:1e18] (rev c4) 00:1d.0 USB controller [0c03]: Intel Corporation 7 Series/C216 Chipset Family USB Enhanced Host Controller #1 [8086:1e26] (rev 04) 00:1e.0 PCI bridge [0604]: Intel Corporation 82801 PCI Bridge [8086:244e] (rev a4) 00:1f.0 ISA bridge [0601]: Intel Corporation B75 Express Chipset LPC Controller [8086:1e49] (rev 04) 00:1f.2 SATA controller [0106]: Intel Corporation 7 Series/C210 Series Chipset Family 6-port SATA Controller [AHCI mode] [8086:1e02] (rev 04) 00:1f.3 SMBus [0c05]: Intel Corporation 7 Series/C216 Chipset Family SMBus Controller [8086:1e22] (rev 04) 02:00.0 Ethernet controller [0200]: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller [10ec:8168] (rev 06) 03:02.0 Ethernet controller [0200]: Intel Corporation 82540EM Gigabit Ethernet Controller [8086:100e] (rev 02) Building manual with following extensions: tc@box:~$ sudo ./rploader.sh build broadwellnk-7.1.0-42661 manual tc@box:~$ ./rploader.sh ext broadwellnk-7.1.0-42661 info I have tried separately both ACPI extensions below https://raw.githubusercontent.com/jimmyGALLAND/redpill-ext/master/acpid/rpext-index.json https://github.com/pocopico/redpill-load/raw/develop/redpill-acpid/rpext-index.json But still cant shutdown using Power Button. If anybody can help please do. ls -l /etc/systemd/system/multi-user.target.wants/ systemctl status acpid.service ● acpid.service - ACPI Daemon Loaded: loaded (/usr/lib/systemd/system/acpid.service; static; vendor preset: disabled) Active: activating (auto-restart) (Result: exit-code) since Thu 2022-06-16 11:06:32 IST; 16s ago Process: 25601 ExecStartPre=/sbin/modprobe button (code=exited, status=1/FAILURE)
-
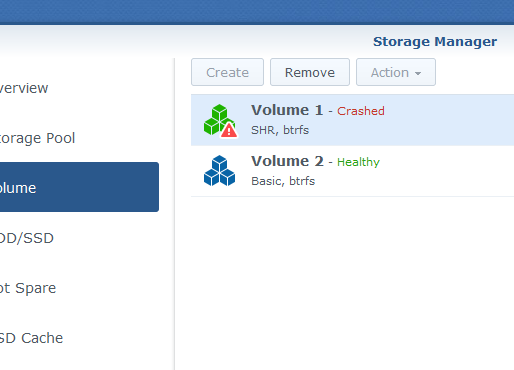
UPDATE: THANK YOU @flyride!!! I AM SAVED. I have copied out my data to another HDD!!!!! I made another storage pool and volume. and copied date off to it. 3TB. I think data is good. How can I check which files were corrupted or not fully restored? Now that Data is back. Should I try repairing the original Volume?
-
Ok found the issue, some how grub got changed From Loadlinux 3617 usb To Loadlinux 3617 sata Now able to boot . I will report back what i find Sent from my SM-G998B using Tapatalk
-
Ok. Before i did that. I could see that DSM stopped loading(no HDD connected error on webpage) . Also on a different local ip then i specified. But they are shown correct in live ubuntu envoinment. I loaded md0 as you suggested. Cleared /root but DSM ISSUE till their. I think its best I do the remaing stuff in ubuntu. As mdstat us exactly same as it showed in DSM. ANY other way boot into DSM. Ssh now shows refused. Sent from my SM-G998B using Tapatalk
-
It just says access denied. On ssh. Now DSM is also not showing. I booted into ubuntu live. I can see md2,3,4,5 and vg1000 , same as in DSM (mdadm -Asf && vgchange -ay). I think i can do tree root stuff from here too. But I cant see md0 to correct /root. How can i rebuild md0? Sent from my SM-G998B using Tapatalk
-
OK Another old post I found which could load me into root is here . Not able to get this to work in grub.cfg Should i just add line in cfg like so? Or do it the way mentioned above? linux $img/$zImage $common_args $bootdev_args $extra_args $@ rw init=/bin/bash
-
@Orphée I did. It says access denied on SSH and the above error on DSM The closest I caan see with my issue is this old post . Reinstall of DSM in out of question for me(due to recovery). I have dug a pretty deep hole for myself. 😕
-
A roadbock. WARNING for a stupid thing I did. I ran the script posted their to find out the best tree root to get. It did show my folder structures intact! But That script ran too long, I inspeected why and sure, it was filling /root dir in GBs! I didnt comprehend that it will fill /root so fast. I should have ran on a USB stick . And now I cant login to DSM or SSH because storage is full!! Is their a Grub/boot loader script i can run to clear the /root folder at startup? Specially the 333* files generated from the script their.

-
I checked . volume1 not mounted. So /volume1 is just a folder. All packages are in "error" mode so, i think its old crons which ran at the time. (doesnt containt anything) i will try this tommorow and post back.
-
Thanksfor stikcing with me!! Oh no I found out that volume1 is mounted but with "blank data". Is this overwritten? on the other hand, Could not find volume1 current mount in cat /etc/mtab (attached) root@ANAND-NAS:/volume1$ ls -lr total 32 -rw-rw---- 1 system log 19621 Aug 28 22:08 @SynoFinder-log drwxr-xr-x 3 root root 4096 Aug 28 22:07 @SynoFinder-LocalShadow drwxr-xr-x 3 root root 4096 Aug 28 22:07 Plex drwxrwxrwx 14 root root 4096 Aug 28 22:07 @eaDir So still good to go ? I did the following and got same error . sudo mount /dev/vg1000/lv /volume1 sudo mount -o clear_cache /dev/vg1000/lv /volume1 sudo mount -o recovery /dev/vg1000/lv /volume1 sudo mount -o recovery,ro /dev/vg1000/lv /volume1 mount: wrong fs type, bad option, bad superblock on /dev/vg1000/lv, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so. dmesg | tail root@ANAND-NAS:~# dmesg | tail [35831.857718] parent transid verify failed on 88007344128 wanted 7582040 found 7582038 [35831.857733] md2: syno_self_heal_is_valid_md_stat(496): md's current state is not suitable for data correction [35831.867644] md2: syno_self_heal_is_valid_md_stat(496): md's current state is not suitable for data correction [35831.877616] parent transid verify failed on 88007344128 wanted 7582040 found 7582038 [35831.877641] parent transid verify failed on 88007344128 wanted 7582040 found 7582038 [35831.877643] BTRFS error (device dm-0): BTRFS: dm-0 failed to repair parent transid verify failure on 88007344128, mirror = 2 [35831.890418] parent transid verify failed on 88007344128 wanted 7582040 found 7582041 [35831.890476] BTRFS: Failed to read block groups: -5 [35831.915227] BTRFS: open_ctree failed Now tried sudo btrfs rescue super /dev/vg1000/lv root@ANAND-NAS:~# sudo btrfs rescue super /dev/vg1000/lv All supers are valid, no need to recover sudo btrfs-find-root /dev/vg1000/lv Dump is big , so showing first fwe lines and attaching full dump. root@ANAND-NAS:~# sudo btrfs-find-root /dev/vg1000/lv parent transid verify failed on 88007344128 wanted 7582040 found 7582041 parent transid verify failed on 88007344128 wanted 7582040 found 7582041 parent transid verify failed on 88007344128 wanted 7582040 found 7582038 parent transid verify failed on 88007344128 wanted 7582040 found 7582041 Ignoring transid failure incorrect offsets 15625 135 Superblock thinks the generation is 7582040 Superblock thinks the level is 1 Found tree root at 88006344704 gen 7582040 level 1 Well block 87994417152(gen: 7582033 level: 0) seems good, but generation/level doesn't match, want gen: 7582040 level: 1 Well block 87992172544(gen: 7582032 level: 0) seems good, but generation/level doesn't match, want gen: 7582040 level: 1 Well block 87981391872(gen: 7582029 level: 0) seems good, but generation/level doesn't match, want gen: 7582040 level: 1 Well block 87975280640(gen: 7582028 level: 1) seems good, but generation/level doesn't match, want gen: 7582040 level: 1 Well block 87968268288(gen: 7582024 level: 1) seems good, but generation/level doesn't match, want gen: 7582040 level: 1 Well block 87966810112(gen: 7582020 level: 0) seems good, but generation/level doesn't match, want gen: 7582040 level: 1 Finally sudo btrfs insp dump-s -f /dev/vg1000/lv root@ANAND-NAS:~# sudo btrfs insp dump-s -f /dev/vg1000/lv superblock: bytenr=65536, device=/dev/vg1000/lv --------------------------------------------------------- csum 0x812b0015 [match] bytenr 65536 flags 0x1 ( WRITTEN ) magic _BHRfS_M [match] fsid 8ae2592d-0773-4a58-86cd-9be492d7cabe label 2017.02.11-14:42:46 v8451 generation 7582040 root 88006344704 sys_array_size 226 chunk_root_generation 6970521 root_level 1 chunk_root 21037056 chunk_root_level 1 log_root 88008196096 log_root_transid 0 log_root_level 0 total_bytes 5991257079808 bytes_used 3380737892352 sectorsize 4096 nodesize 16384 leafsize 16384 stripesize 4096 root_dir 6 num_devices 1 compat_flags 0x0 compat_ro_flags 0x0 incompat_flags 0x16b ( MIXED_BACKREF | DEFAULT_SUBVOL | COMPRESS_LZO | BIG_METADATA | EXTENDED_IREF | SKINNY_METADATA ) csum_type 0 csum_size 4 cache_generation 312768 uuid_tree_generation 7582040 dev_item.uuid 4e64f8b3-55a5-4625-82b1-926c902a62e0 dev_item.fsid 8ae2592d-0773-4a58-86cd-9be492d7cabe [match] dev_item.type 0 dev_item.total_bytes 5991257079808 dev_item.bytes_used 3528353382400 dev_item.io_align 4096 dev_item.io_width 4096 dev_item.sector_size 4096 dev_item.devid 1 dev_item.dev_group 0 dev_item.seek_speed 0 dev_item.bandwidth 0 dev_item.generation 0 sys_chunk_array[2048]: item 0 key (FIRST_CHUNK_TREE CHUNK_ITEM 0) chunk length 4194304 owner 2 stripe_len 65536 type SYSTEM num_stripes 1 stripe 0 devid 1 offset 0 dev uuid: 4e64f8b3-55a5-4625-82b1-926c902a62e0 item 1 key (FIRST_CHUNK_TREE CHUNK_ITEM 20971520) chunk length 8388608 owner 2 stripe_len 65536 type SYSTEM|DUP num_stripes 2 stripe 0 devid 1 offset 20971520 dev uuid: 4e64f8b3-55a5-4625-82b1-926c902a62e0 stripe 1 devid 1 offset 29360128 dev uuid: 4e64f8b3-55a5-4625-82b1-926c902a62e0 backup_roots[4]: backup 0: backup_tree_root: 88006344704 gen: 7582040 level: 1 backup_chunk_root: 21037056 gen: 6970521 level: 1 backup_extent_root: 88004870144 gen: 7582040 level: 2 backup_fs_root: 29556736 gen: 6 level: 0 backup_dev_root: 88006639616 gen: 7582040 level: 1 backup_csum_root: 88007917568 gen: 7582041 level: 3 backup_total_bytes: 5991257079808 backup_bytes_used: 3380737892352 backup_num_devices: 1 backup 1: backup_tree_root: 88004640768 gen: 7582037 level: 1 backup_chunk_root: 21037056 gen: 6970521 level: 1 backup_extent_root: 88002723840 gen: 7582037 level: 2 backup_fs_root: 29556736 gen: 6 level: 0 backup_dev_root: 29802496 gen: 7581039 level: 1 backup_csum_root: 87998988288 gen: 7582038 level: 3 backup_total_bytes: 5991257079808 backup_bytes_used: 3380737863680 backup_num_devices: 1 backup 2: backup_tree_root: 88009687040 gen: 7582038 level: 1 backup_chunk_root: 21037056 gen: 6970521 level: 1 backup_extent_root: 88004018176 gen: 7582039 level: 2 backup_fs_root: 29556736 gen: 6 level: 0 backup_dev_root: 29802496 gen: 7581039 level: 1 backup_csum_root: 88001593344 gen: 7582039 level: 3 backup_total_bytes: 5991257079808 backup_bytes_used: 3380737896448 backup_num_devices: 1 backup 3: backup_tree_root: 88013193216 gen: 7582039 level: 1 backup_chunk_root: 21037056 gen: 6970521 level: 1 backup_extent_root: 88004018176 gen: 7582039 level: 2 backup_fs_root: 29556736 gen: 6 level: 0 backup_dev_root: 29802496 gen: 7581039 level: 1 backup_csum_root: 88001593344 gen: 7582039 level: 3 backup_total_bytes: 5991257079808 backup_bytes_used: 3380737949696 backup_num_devices: 1 If I want to restore to a new HDD . Its size should be of the USED volume/storage pool space size (6TB) or of the actual used volume space(i think it was less than 4TB, I checked the other post and git my answer, but how can i know how much data size was ACTUALLY present? Can it be checked from the dumps above?) Next I want to do sudo btrfs check --init-extent-tree /dev/vg1000/lv sudo btrfs check --init-csum-tree /dev/vg1000/lv sudo btrfs check --repair /dev/vg1000/lv Holding off for now, any suggestions? btrfs-find-root.txt mtab.txt
-
OK, I will check it out
-
Correct. Drive 4 is just another storage pool with volume2 with no RAID which contains non important data. We can ignore it. I did mdadm --misc -o /dev/md2 from your comment here . I think i did it on md2 . but does this carry over after a reboot? Didnt want to keep NAS runnig to avoid more damage to disks. Well, volume1 was accessible in degraded mode even after Drive 2 was kicked out due to bad sectors. Its when Drive1 "crashed"(Its a relatively new drive), then volume crashed. There is also loss of config for shared folders. then my brother installed photoshation app again thinking that it my have some error(I know i shouldn't have given him this much power in NAS, but he had physical access, so I thought it may be usefull ). Thats the last thing we did and shutdown for good. Current state: Storage pool is degraded, Volume1 is crashed. Data could not be accessible. cat /proc/mdstat root@ANAND-NAS:~# cat /proc/mdstat Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [raidF1] md5 : active raid1 sdc7[1] 1953494912 blocks super 1.2 [2/1] [_U] md2 : active raid5 sdc5[3] sda5[5] 1943862912 blocks super 1.2 level 5, 64k chunk, algorithm 2 [3/2] [_UU] md3 : active raid5 sda6[5] sdc6[4] 1953485824 blocks super 1.2 level 5, 64k chunk, algorithm 2 [3/2] [_UU] md4 : active raid1 sdd3[0] 971940544 blocks super 1.2 [1/1] [U] md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3] 2097088 blocks [12/4] [UUUU________] md0 : active raid1 sdb1[2] sdc1[1] sdd1[3] 2490176 blocks [12/3] [_UUU________] unused devices: <none>