vasiliy_gr
-
Posts
69 -
Joined
-
Last visited
-
Days Won
4
vasiliy_gr's Achievements
Regular Member (3/7)
8
Reputation
-
Here are few words on testing 1.1-beta-1/2 on my four NAS-es. On beta1 I had one big issue. It did not work with LSI 9400-16i at least in fresh install mode of ARPL (while LSI 9300-8i worked). And while I decided if I will test it in update menu mode - it changed to beta2... On beta2 there were no problems with 9400 in both update menu and fresh install variants. So on beta2 I do not have any issues for now. But I have one question. What happened with maxdisks entry in Synoinfo menu? In both betas 1.1. It has a practical value for me for one NAS from four. And for that NAS I chose update by menu mode (where this setting was done previously). In this mode there were no errors really. I got all my 16 hdd-s plus one fake hdd from QEMU. But what about install from scratch?.. And one more thing... 'Direct boot' menu entry is only available when loader is already made. So to see or change this setting one needs to build loader and then go above to advanced menu and then go below twice to boot loader entry. It is some sort of distortion of ARPL menu logic... So 'direct boot' situated not in place... Or it should not be hidden before first loader's build.
-
How to make ARPL's last beta-s work for those (as me) for whom it doesn't work. I mean those of us who says that the last working beta was beta3 or beta5 or more seldom beta6-7... At least this method helped me on my four NAS-es. I had only once exception during DSM boot on 9-10 boots. There were more boots that the number of NAS-es mostly in testing purposes, and only once because of the exception. It is not the answer for "why" and is not a solution. It's just a sort of know-how... Anyway I am not responsible if this method will be unuseful for some or most number of configurations. First of all - it works both with update installation by menu and clean install. Shutdown DSM if it is running. Change boot method from CSM to UEFI. In Proxmox - change SeaBIOS to OVMF (UEFI). It is mandatory to update by menu method but I think it is necessary for both ways. But I didn't tested clean install without UEFI today. Then boot in configure mode. As usual - update ARPL, reboot, update everything else. Build loader and boot it as ever. But before building loader check one thing... I will say about it later here. The method above I checked only once. It works for me. But history of my arpl.img is too complicated, and I even don't remember what version of loader on every certain NAS... So I used the second method... I began with the same. I shudowned DSM and changed SeaBIOS to OVMF. Then I dowloaded beta13 and replaced arpl.img with it. And then booted it and started menu.sh. Then usual actions with configuration of everything. But before building loader do the following. Go to Advanced menu. Switch LKM from default 'dev' to 'prod'. That is all. And finally - build loader, boot loader. In this method on all four installations I received DSM restrore screen on DHCP address. I pressed button 'restore' and DSM rebooted in few seconds. The browser page with 'restoration' may be closed, as the next boot was on static address as usual. And finally I received working DSM... So... My several thoughts on it. The problem grew up when dev/prod from high menu level went to sub-menu with dev value as default. It is a sort of psychology... As for the explanation on this effect - I think that there is some sort of incompatibility with latest redpill version. Or - between redpill and arpl...
-
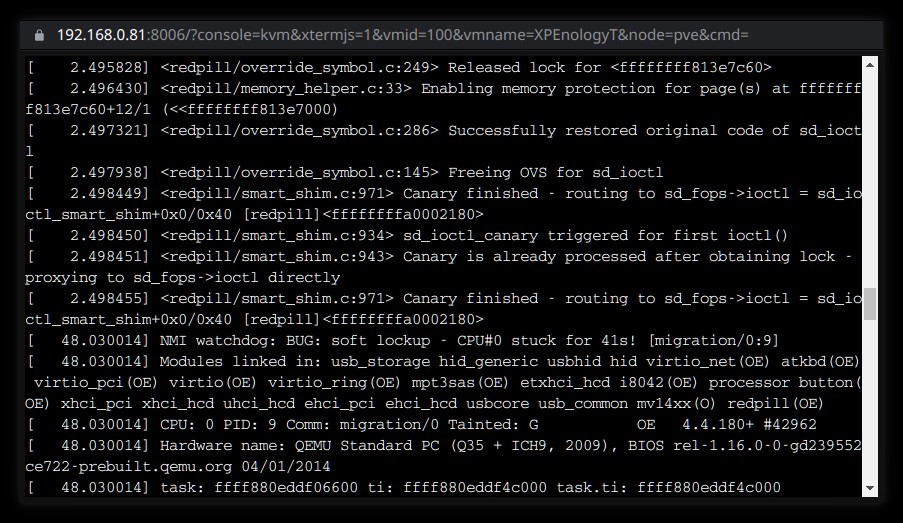
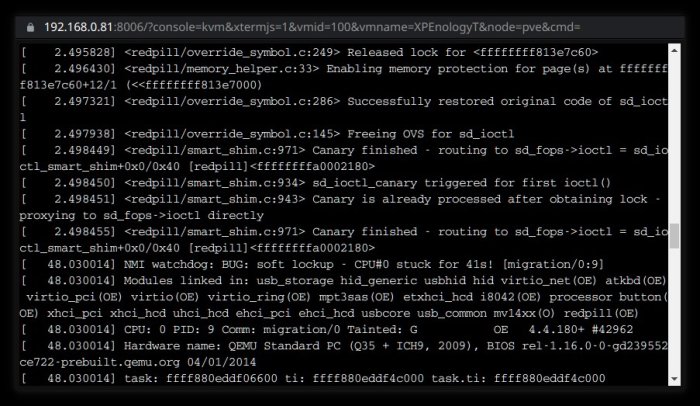
Some additional info to previous. Right after SAS HBA detection and HDD-s on it detection there is a big pause in unworking versions (at least beta13 but also most previous ones) and short pause in working version. Unworking version: Working version: It is difficult to show the same lines here... But unworking version ends on 2.49s or so on HDD-s on SAS HBA, then come many lines from redpill module, then pause up to 48s and watchdog finally... There is also pause for 0.5s in working version, but it doesn't make a problem.
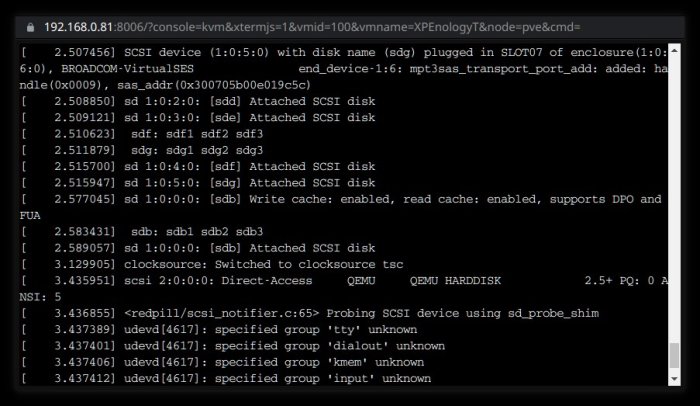
-
Beta13 testing. 1. Working image with update menu. After update arpl I got unworking image as with beta12. Grub does not start. I missed console addon or anything new - my goal was to load DSM... 2. Downloaded image from github. Made all config changes. Built loader and booted it... System panic / exception. 3. Again rebooted in configure mode with (2). Deselected two bnx2* entries in modules. Built loader and booted it... System panic / exception. But now it seemed to me that something changed... So I waited more time. And the following appeared: I do not know exactly if the same can be in (2) without bnx2* modules removed, may be I don't waited enough. Anyway DSM does not boot. And I can't use beta13 also.
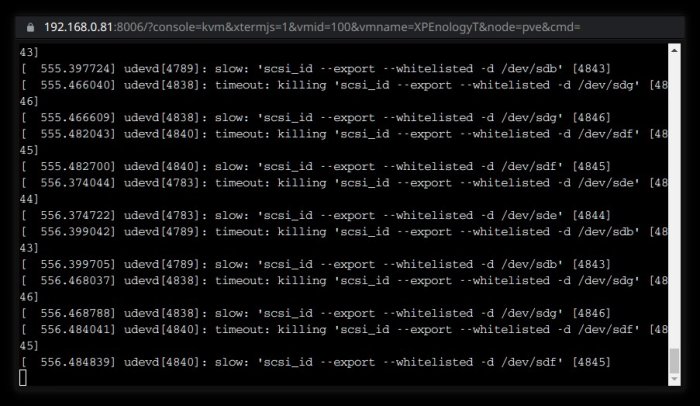
-
Tested beta12 on the only one NAS. 1. Loaded image of ARPL beta11a (without new modules) in configure mode. Updated ARPL through menu. Rebooted. Without success - grub declined to start, nothing about kernel as it hangs earlier before the kernel. 2. Downloaded full image of beta12. Loaded it - no problems with grub, so previously it was a problem of wrong update... Reconfigured everthing as ever. Added also console addon (I really don't know what is it, but decided to test). Build kernel and boot it. Result - system panic / exception, no boot. 3. Reloaded (2) in configure mode. Deleted console addon. Build and boot - result the same as (2). 4. The same as (2) from the beginning but now I didn't add/deleted console addon. Result the same - exception. So summing up - beta12 is unusable for me, console addon untestable for me. And I still don't know what is it...
-
Tests on beta11a (latest for this moment). Remind: LSI 9400, Proxmox, SATA and SAS hdd-s. 1. Download image. Configure it as usual. Result - DSM boots but without LSI 9400 and without hdd-s. 2. Took the last working for me arpl.img. Updated everything by menu. Build loader. Try to boot... Result the same as previous. 3. Took the last working for me arpl.img. Updated: ARPL, addons, LKMs. Not updated modules. Build loader. Try to boot... Ok now, DSM boot completed. So... What happens with virtual SAS controller module or 9p addon? Anyway now it looks better then previously - no exception during boot.
-
Yes, I can. But how?.. I can easily find messages here, but attachment is limited to 10 MB. As for github I can't find private messages there (but may be I simply do not know github structure). PS: Sent mail with yandex-disk link.
-
And I tried a second NAS... May be this information may be useful in determining what is wrong... There I had problems with Proxmox (unrelated to ARPL and DSM). So I decided to reinstall Proxmox. And I did it. But how to receive now working ARPL?.. I thought that beta3 should work. And it can be upgrade to beta10a without modules. Attempt 1. I decided to speed up the process. So I downloaded beta3, boot it configure mode and upgaraded arpl, addons, LKMs. Then I configured it - ds3622xs+, last DSM and so on. And builded loader. Result - exception during boot, DSM could not be loaded. Attempt 2. Again beta3, configure it, build loader. Result - DSM is loaded (through some intermediate phase - where ip from DHCP, and it writes something quickly then reboots). Again go to configure of ARPL. Upgrade: ARPL, addons, LKMs. Rebuild loader, boot. Result - no network (virtual from Proxmox). Ok, again configure... Upgrade the last point - modules. Rebuild loader, boot. Exception. DSM not booted. Attempt 3. Copied arpl.img from previous NAS to network. And from there copied to this NAS. Configure. Changed mac address to real mac, and generated random serial. Rebuild loader, boot. And now - ok, DSM booted.
-
Tested a little new beta10a. If I download it as the image and make all reconfiguration - the same as with all last betas - exceptions, DSM does not boot. And if I make upgrade with internal menu from beta7 (that was previously obtained by full upgrade beta3-beta6-beta7) now without upgrading modules (everything else - ARPL itself, reboot, addons, LKMs) - everything ok, DSM boots. I only tested on 1 NAS, but I am sure that 3 others will behave the same way, as they all have similar configuration: Proxmox, 12th generation of Intel CPUs, LSI 9400 or 9300, ds3622xs+, DSM 7.1.1u2.
-
...And finally I found a way how to revert my test NAS back to beta7. I will not repeat again all this long story... Only outline. At first stage I installed successfully beta3 on four NAS-es. On second stage I upgraded all of them internally in ARPL from beta3 to beta6 and from beta6 to beta7. And the third stage was a disaster: I upgraded from beta7 to beta8, also beta9, also tried direct image download from github - and I received kernel panic (or other way of unworking DSM) on all the beta-s above beta3. And beta3 has absolutely unworking hibernation. And the only one NAS where I can study hibernation was stuck on beta3... But I have other NAS-es with beta7! So I copied good image of beta7 from one of the other NAS-es, copied it over the network and run instead of beta3. At least you should change in this variant two things - SN and MAC. New SN can be generated randomly. MAC i took from the previous value of MAC on this NAS. More than that ARPL starts even in "configure" variant not with hardware MAC but DSM MAC. So two NAS-es have the same MAC... It is not good for network activity on both of them. So it is better not to run NAS-donor before reconfiguring NAS-patient (at least new/old MAC should be entered). After these two changes (SN and MAC) make other changes if needed (I changed maxdisks). Build loader, boot loader. And everything is working... It take me a lot of time because at first I forgot about MAC. Then it was surprise for me that ARPL starts "configure" with MAC of the other NAS - so I had two NAS-es with equal MAC-s on network. And after understanding and solving this problem - everything was fine. Anyway... Now I have again beta7 on four NAS-es. But I tried previously beta7 on the same NAS - it was kernel panic... So these two beta7 are different.
-
New investigation. Sorry - without pictures. Lets start with history. I installed beta3 (previously was tcrp). No problems except hibernation. And on beta3 I can't force my hdd-s hibernate at all. So later I installed from internal arpl upgrade menu version beta6. There were some issues with kernel panic, but they could be solved by DSM reboot. Soon I got beta7, so I don't know much on beta6. I installed beta7 from beta6 (that was installed from beta3) internally through menu. And all above I did on four NAS-es wih very similar characteristics. All of them have Proxmox, 12th generation of Intel CPU-s and Z690 m/b-s from Asus with 64 or 128 GB of RAM (minus something for Proxmox), disabled SATA controller, 9300 or 9400 SAS HBA instead. Also all of them are DS3622xs+ with the latest DSM. And historicaly they had finally beta7. The new part is only about one NAS. At first I tried to install new versions internally. After bad results with upgrade procedure, I downloaded images from github, made some settings and tried DSM. My settings: 9p, lsutil - in Addon menu, SataPortMap=18 and DiskIdxMap=1B00 in Cmdline menu. And of course previously - DS3622xs+, latest/upper DSM, random SN. Then - build loader - boot. beta3 - no problems at all. But no hibernation at all. beta4 - no network, only localhost available. beta5 - no "Boot" item in menu.sh after building DSM kernel. So I did exit and reboot manually. I saw grub menu but it refused to boot beyond red lines. So no DSM here too. beta6 - it was the second best result after beta3... It loaded DSM as restore session. I did restore. It rebooted. And - kernel panic... beta7 - kernel panic. beta8 - kernel panic. beta9 - kernel panic. To some up: the last working loader in my configuration is beta3. All loaders above produce unbootable DSM. There may be some way to produce good ARPL above beta3 - using upgrade menu. For example, I managed to do upgade from beta3 to beta6 and later to beta7. But i can't reproduce it, as upgrade menu only upgrades to latest version. And beta8/beta9 produce kernel panic after upgade from beta3 and beta6. So now I have beta3 on only one NAS where I can study hibernate problem (as I have SAS hdd-s there with inverted led logic). And I have beta7 on other NAS-es - but I can't reproduce the way I got this version.
-
I do not have spare hdd-s now. So I can't make 'fresh install' or use raid0. But I don't have multiple raid volumes.
-
Thank you, it helps. But finally I got on beta6 kernel panic also... I will write about it later.
-
So is it possible to install beta7 in DS3622xs+ mode? I ask because I want make some experiments with hibernation, but beta8 and beta9 both make kernel panic in DSM (and I do not know why - may be because of Proxmox, may be because of i5-12400 or may be because of something else). I can't install beta7 from downloaded image (because size error while making DSM kernel). And as for beta3 - there I can't use hibernation at all. The question is - can I download beta7 image, make some settings, try to make DSM kernel - obtain error, exit, some commands in command-line, again menu.sh and build kernel without error?..
-
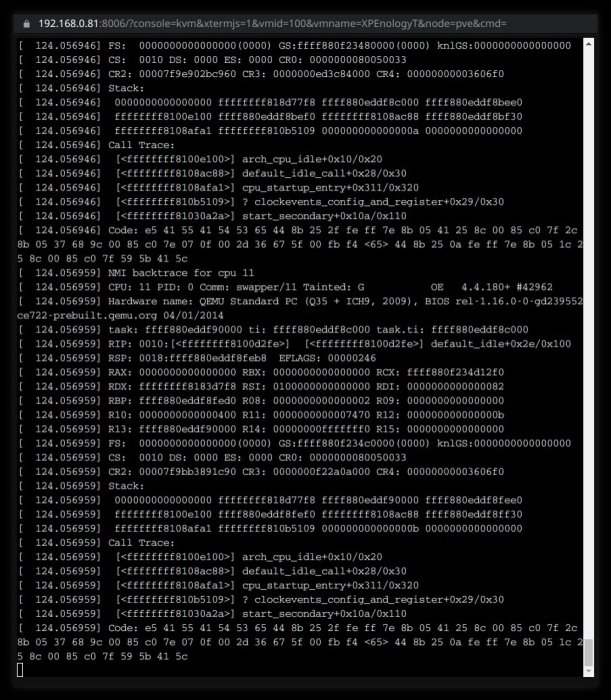
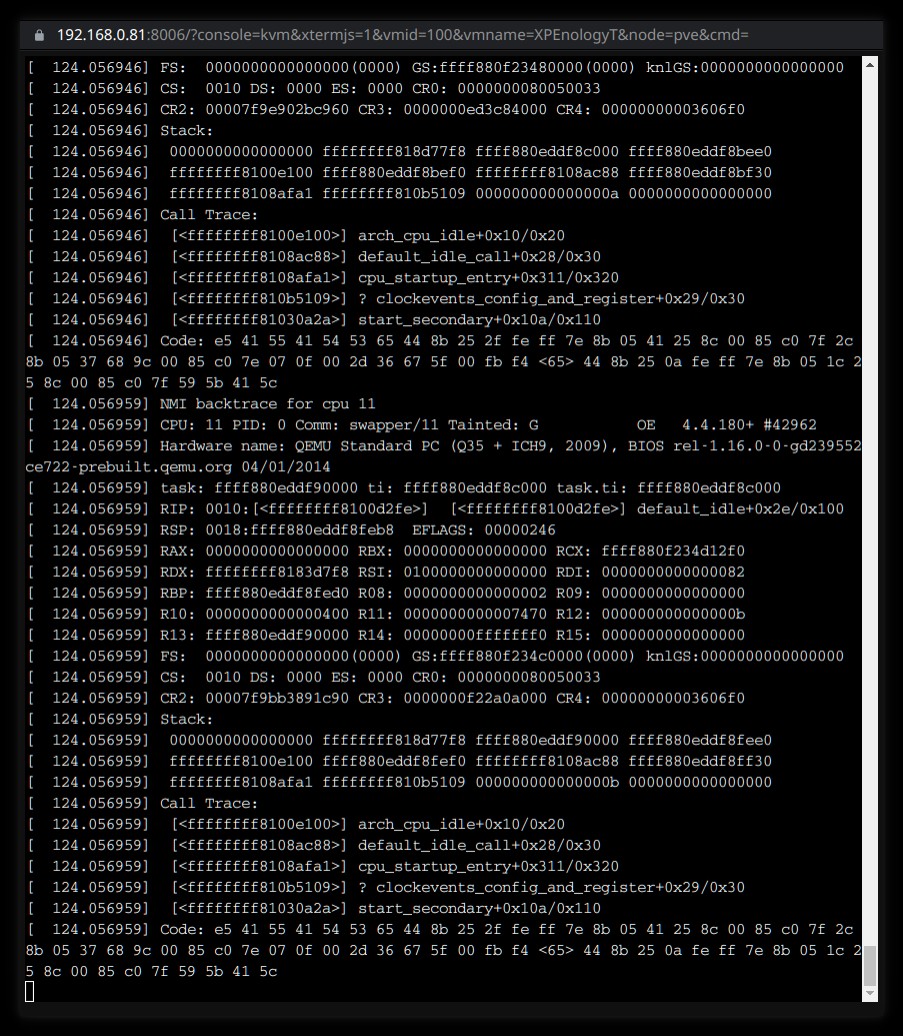
About beta9. The same. Also - kernel panic. But now I made screenshot. It is when I upgraded beta3 to beta9 with internal menu. Later I also tried beta9 from downloaded image (and settings from the begining (no update). On the second try the call stack was twice longer but I can make only one screenshot before I make this NAS again functional. (That is because I call it "test NAS" for simplicity only. Really it is used as ordinary NAS - and have attached NFS-shares on client. And on client where I can make screenshots - I have Plasma/KDE. So "save file" dialog is blocked before this NAS becomes functional again.) So I tried beta9, made screenshot and returned to beta3.