NeoID
-
Posts
224 -
Joined
-
Last visited
-
Days Won
2
Everything posted by NeoID
-
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
Features: https://www.synology.com/en-global/DSM70 The biggest change is Synology Photos which is a bastard child between two perfectly good apps (moments+dsphotos). It's extremely lacking in a lot of ways as of yet. -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
1) Yes it's "abandoned" like Juns, but this time it's open source 2) To be honest... If you don't want to read the 144+ pages you should invest into a real Synology that just works. Here there will be dragons (and lots of) 3) Most/all people use this for testing only and it's not as stable as Juns loader 4) If you are happy with Juns loader I recommend you to stay on it, especially if you use it for "production". Redpill is not ready for production. If you have hardware to spare you should look into the amazing TinyCore project to get up and running quickly. Synology will also launch DSM 7.1 sometimes Q1, so the grand question is if that will be supported/stable at all going forward -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
Redpill as in the project isn't gone, but the core developer(s) @ThorGroup is. No, unfortunately there is no additional information information available regarding. Thanks to the developers being awesome and making the project open source anyone can contribute this time. You should not use this project if you depend on future updates or intend to make this a production system/make it available on the Internet. As mentioned before, it's only for testing purposes and that will probably always be the case. I wouldn't recommend running Plex on DSM if you are highly dependent on performance. It's way better on a Linux VM with a later kernel and a GPU in passthrough. Some have also reported DSM 7 to be unstable when stressed, not sure thats only tied to Docker or also the Plex package though. I've never been able to get sleep to work, but honestly it's not recommened either as it most likely will decrease the life expectancy of your drives depending on how often you wake them up. Spinning up/down is what kills most drives, not spinning 24/7. I was also looking into this for a long time, but concluded with spindown being a silly thing unless you are pretty sure that the disks can be spinned down for at least a day at a time, preferable over several days. QuickConnect and face recognition is only working for real devices as it requires a real serial/mac. There are ways to get around those limitations, but at that point I would highly recommend to buy a real Synology. Especially if you want something that just works and doesn't waste energy. They are great devices, low power consumption and rock solid. Without the use of docker the performance is also not that bad given the dated hardware they use. There is no such thing as robust or stable branch. Everything is done in development branches that might break tomorrow, but a good starting point is the config used by TinyCore: https://github.com/pocopico/tinycore-redpill/blob/main/global_config.json You need to play around with SataPortMap in order to get the disk order correct. Havent tried TinyCore much myself, but it has a auto-detect feature that might help you. I also recommend to read through the other link with very easy to understand information on how SataPortMap and DiskIdxMap works. -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
Do you use virtual disks or passthrough? -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
Not yet no... as far as I know it's not stable at all. -
Redpill - extension driver/modules request
NeoID replied to pocopico's topic in Developer Discussion Room
I was pretty sure ESXi also sent ACPI requests on shutdown since you can do it from it's command line.... that's really a bummer you can't configure it as the default way of shutting down a given VM... 😕 -
Redpill - extension driver/modules request
NeoID replied to pocopico's topic in Developer Discussion Room
Just use this, it works great. Gives you support for shutdown/restart. IP should be static so it never changes. Don't think there are any other benefits of open-vm-tools. Most important for me was the shutdown/restart support: https://github.com/jumkey/redpill-load/raw/develop/redpill-acpid/rpext-index.json -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
bromolow_user_config.json: { "extra_cmdline": { "vid": "0x46f4", "pid": "0x0001", "sn": "*******", "mac1": "xxxxxxxxxxxx", "mac2": "xxxxxxxxxxxx", "mac3": "xxxxxxxxxxxx", "netif_num": 3 }, "synoinfo": {}, "ramdisk_copy": {} } bundled-exts.json: { "thethorgroup.virtio": "https://github.com/jumkey/redpill-load/raw/develop/redpill-virtio/rpext-index.json", "thethorgroup.boot-wait": "https://github.com/jumkey/redpill-load/raw/develop/redpill-boot-wait/rpext-index.json" } unRAID xml: ... <interface type='bridge'> <mac address='xx:xx:xx:xx:xx:xx'/> <source bridge='br0'/> <model type='e1000e'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </interface> <interface type='bridge'> <mac address='xx:xx:xx:xx:xx:xx'/> <source bridge='br0'/> <model type='virtio-net'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </interface> <interface type='bridge'> <mac address='xx:xx:xx:xx:xx:xx'/> <source bridge='br0'/> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </interface> ... lsmod: virtio_balloon 4629 0 virtio_scsi 9753 0 virtio_net 18933 0 virtio_blk 8528 0 virtio_pci 6925 0 virtio_mmio 3984 0 virtio_ring 8912 6 virtio_blk,virtio_net,virtio_pci,virtio_balloon, virtio_mmio,virtio_scsi virtio 3602 6 virtio_blk,virtio_net,virtio_pci,virtio_balloon, virtio_mmio,virtio_scsi dmesg: https://pastebin.com/BS0Br3nD I can see that only the first vNIC works (e1000e), the other two do not show up in DSM and there is nothing in the dmesg-logs as far as I can tell. lspci lists them: 0000:03:00.0 Class 0200: Device 8086:10d3 0000:04:00.0 Class 0200: Device 1af4:1041 (rev 01) 0000:05:00.0 Class 00ff: Device 1af4:1045 (rev 01) 0000:06:00.0 Class 0200: Device 1af4:1041 (rev 01) 0000:07:00.0 Class 0780: Device 1af4:1043 (rev 01) 0001:07:00.0 Class 0106: Device 1b4b:9235 (rev 11) -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
I'll look into dmesg and other logs to see if I can spot anything. I'm just testing out unRAID and I haven't found any way of getting serial output from it yet for easier debugging -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
I've build RedPill and everything it running as intended, but I can't get any other vNIC to work except e1000e. Both virtio and virtio-net aren't recognized. Anyone else tried this on UnRAID and gotten them to work? Would be nice to test higher speeds then 1Gbps. -
RedPill - the new loader for 6.2.4 - Discussion
NeoID replied to ThorGroup's topic in Developer Discussion Room
That discussion should probably be posted in: At this point its unlikely that ThorGroup returns. Most likely due to personal reasons given that the repository is still active and the rather sudden silence after spending so much time responding to comments and giving long and incredible intriguing changelogs. I'm sure someone knows more, but nothing has been posted as of yet. Whether or not it's dead or just on hold all depends if someone else takes over the project. -
Well... Not really reassuring that their last post contains "issue" and "Chinese firewall" before going silent. 😋
-
Well yes... either someone takes over or it or it dies.... All depends if anyone else is skilled enough and willing to put time and effort into this. I have my doubts "they" will be back, makes no sense to disappear in order to focus on a beta-version. My bet is that something personal happened. I really hope "they" will manage and continue on this project. It's nice to see how much more active the forum had become since.
-
Oh thanks a ton for the links! I thought I was the only one having these issues. I've encountered this as well after going to v7u2 (installed on a USB device) and have been pulling my hairs out of frustration. I've since upgraded to u3 and haven't yet encountered the issue again so hope this one is true...
-
- Outcome of the installation/update: UNSUCCESSFUL - DSM version prior update: DSM 6.2.3 25426 Update 2 - Loader version and model: JUN'S LOADER v1.03b - DS3617xs - Using custom extra.lzma: NO - Installation type: VM - ESXi 6.7 - Additional comments: Same as all other people who use ESXi and a PCI/LSI card in passthrough mode. After the upgrade the NAS cannot be found on the network anymore. The only way I got access again was to temporarily switch to the DS3615xs loader and reinstall DSM and then migrate back to DS3617xs again. If you use a PCI card in passthrough DO NOT UPDATE to this version.
-
I've by mistake figured out that the DS Photo app (at least on Android) by default overwrites images with the same name when moving them from one album to another. So if you move test.jpg from album A to B and album B already has test.jpg (even if it isn't the same photo), it's overwritten WITHOUT notice. There is supposed to be a setting to change the default behaviour from overwrite to keep, but I can't find it anywhere. Anyone else familiar with this?
-
Not that I know of. I have not used snapshots or quotas before. Enable shared folder quota is off for every shared folder i have... User quota in the profiles are all set to "No Limit"
-
I've searched around the web, but can't seem to find any information on this. Anyone seen these errors in "/var/log/messages" before and know what they mean? 2019-12-11T11:15:53+01:00 x kernel: [13651.708876] BTRFS error (device md2): cannot find qgroup item, qgroupid=15084 ! 2019-12-11T11:15:53+01:00 x kernel: [13651.708876] 2019-12-11T11:15:53+01:00 x kernel: [13651.944144] BTRFS error (device md2): cannot find qgroup item, qgroupid=14903 ! 2019-12-11T11:15:53+01:00 x kernel: [13651.944144] 2019-12-11T11:15:54+01:00 x kernel: [13652.795072] BTRFS error (device md2): cannot find qgroup item, qgroupid=14897 ! 2019-12-11T11:15:54+01:00 x kernel: [13652.795072] 2019-12-11T11:15:54+01:00 x kernel: [13652.796348] BTRFS error (device md2): cannot find qgroup item, qgroupid=14894 !
-
I'm running ESXI, HBA in passthrough mode and Jun's Loader v1.03b DS3617xs without any customization. I use a INTEL Xeon D-1527, 4 cores and 25 GB with ECC RAM. I also use a Intel X540-T2 network card in passthrough. My Xpenology server feels a bit sluggish, but I have a hard time to pinpoint the issue. I run quite a few Docker images, but there is hardly any CPU utilization. Disk and Volume utilization stays around 50% each and I/O wait at ~25%. I'm not sure, but doesn't that sound much? Does anyone have any tips on how to get to the bottom of this? I've read some people suggesting to enable disk write cache, but that only yields "Operation failed". Not sure if that's possible when using a LSI card in passthrough?
-
Anyone struggling with SMART with the DS918 image on ESXI? I'm using a LSI00244 9201-16i with 3615 and 3617 and everything works great, but when trying 918 I get the following message when trying to get the SMART data from any hard drive in the storage manager. Since SHR and vmxnet3 works in 918 it would be awesome to continue to use that image. Edit: Is missing kernel support the reason for this?
-
As mentioned before, when using the following sata_args, the system crashes after a little while. I have given my VM a serial port so I could see what's going on, but I have a hard time understanding the issue. Anyone who could explain to me what's going on here and how I can get the sata_args to work? I mean everything looks right from DSM/Storage Manager.... set sata_args='DiskIdxMap=1F SasIdxMap=0xfffffffe'
-
I know this is only a cosmetic thing, but no matter how I try to hide the boot drive using DiskIdxMap in the sata_args, DSM stopps working after a few hours. After a while it stops working and I'm only presented with a white page when trying to login, but after a while I get the message saying that the disk space is full when trying to login. Any ideas? I guess the best choice is to stick to the default "set sata_args='SataPortMap=4'" and just ignore the bootloader and the four spaces between the PCI card. This way you still get to use 12 drives.
-
Anyone seen this before? Occurs after 5-10 hours and requires a reboot to get past. I can't see anything in dmesg or logs and can't get access to SSH either once the error arises.
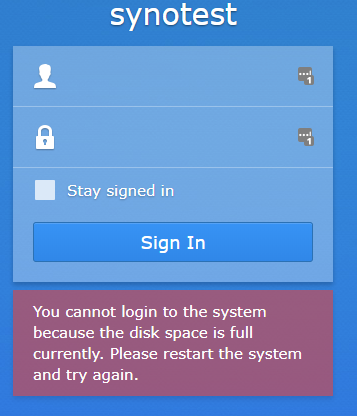
-
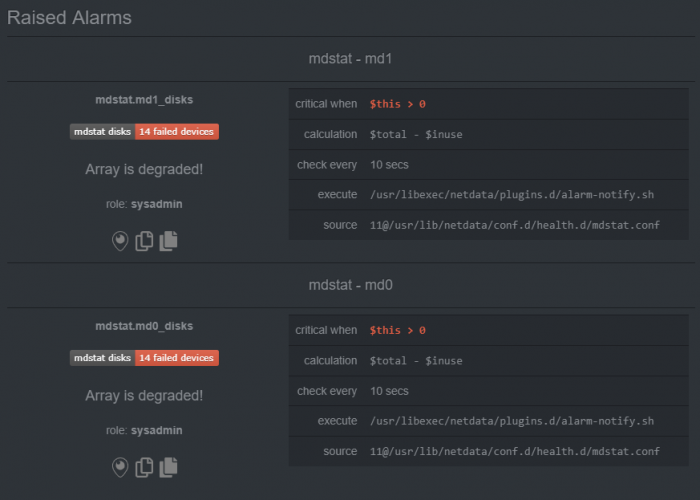
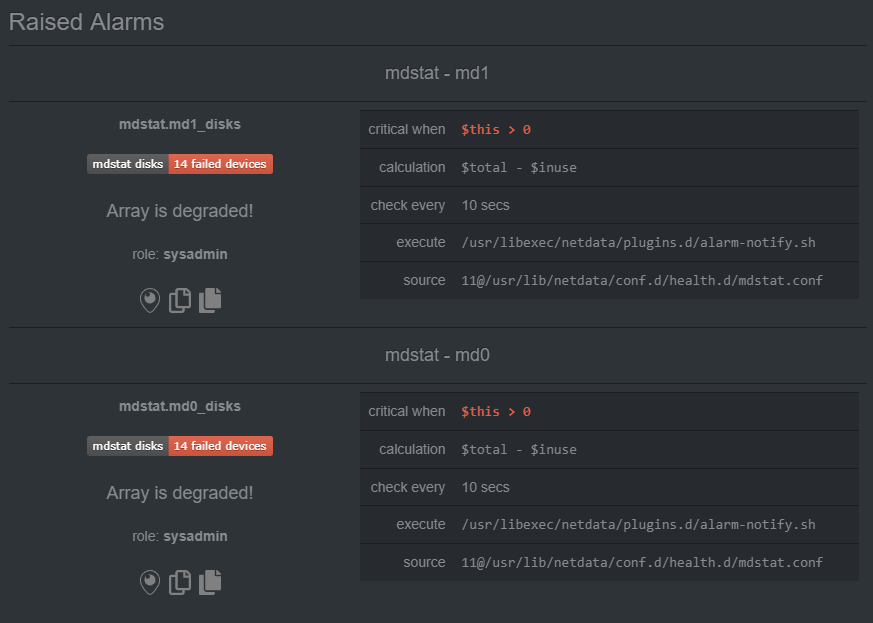
Apparently the lastest bootloader or version of DSM does something silly. When doing cat /proc/mdstat I get: md1 : active raid1 sda2[0] sdb2[1] 2097088 blocks [16/2] [UU______________] But that doesn't seem right.. a RAID 1 on the previous loader looked like this: md3 : active raid1 sdi3[0] sdj3[1] 483564544 blocks super 1.2 [2/2] [UU] Netdata doesn't like the 16/2 status as it assumes drives are missing from the array and therefore degraded. DSM doesn't seem to care though, but still not perfect.
-
I may have found a bug. I'm using netdata for system monitoring on both my "production" and test xpenology (see storage manager screenshot in my previous post). Using synoboot 1.03b/ds3615xs everything is fine, but using 1.04b with two drives it tells me that my array is degraded. DSM on the other hand says everything is normal. As mentioned, this isn't an issue on the previous loader.